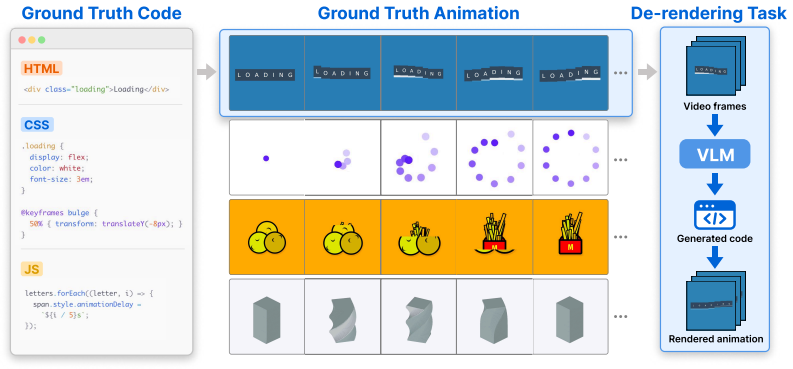
Animation2Code: Evaluating Temporal Visual Reasoning in Video-to-Code Generation
Pith reviewed 2026-06-30 00:51 UTC · model grok-4.3
The pith
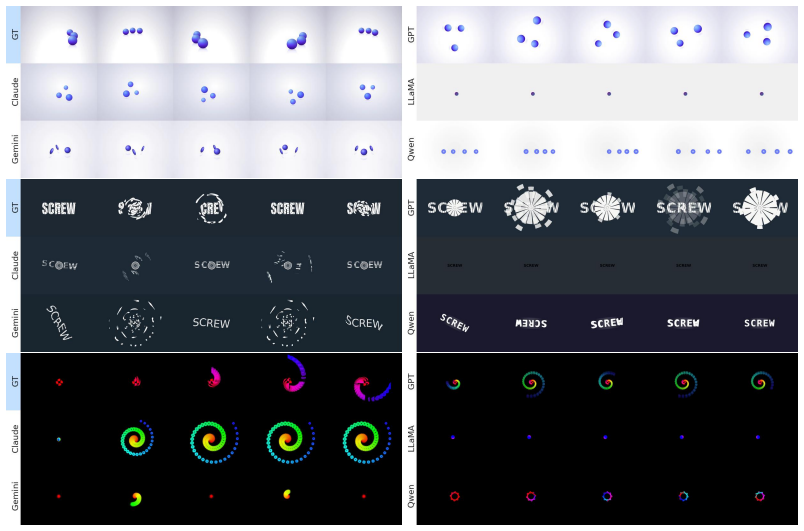
Vision-language models reproduce the look of web animations from video but fail to preserve motion timing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
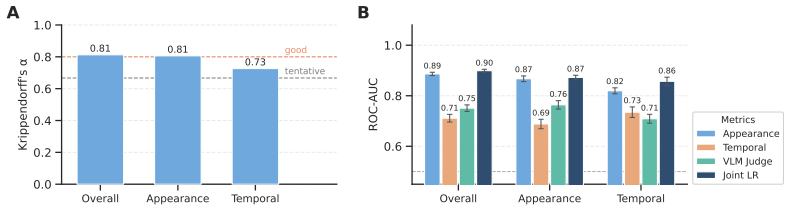
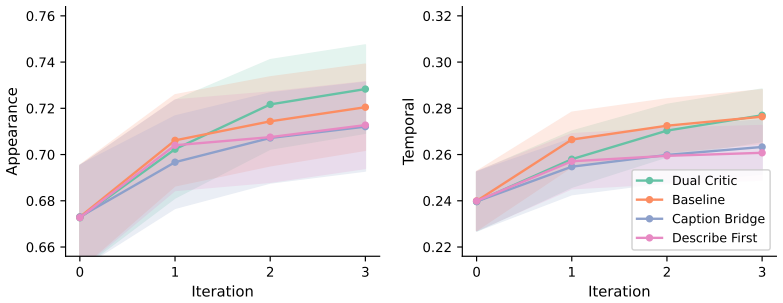
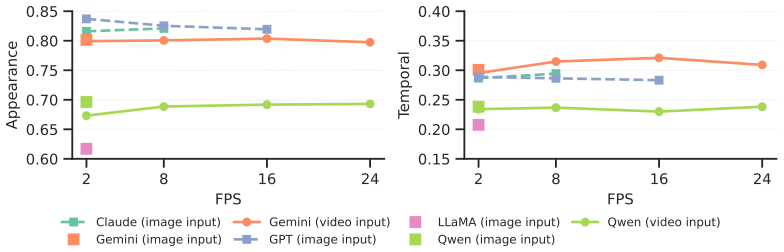
Current VLMs struggle to maintain temporal consistency in reconstruction, even when achieving high appearance similarity, including under finetuning and iterative refinement settings.
What carries the argument
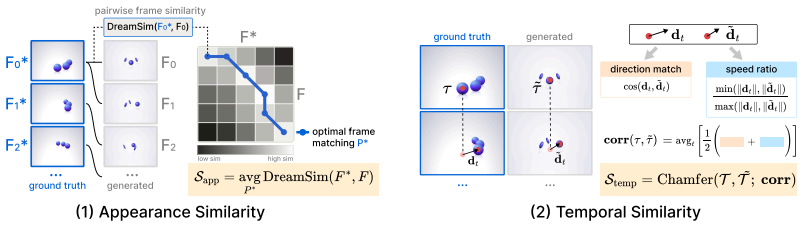
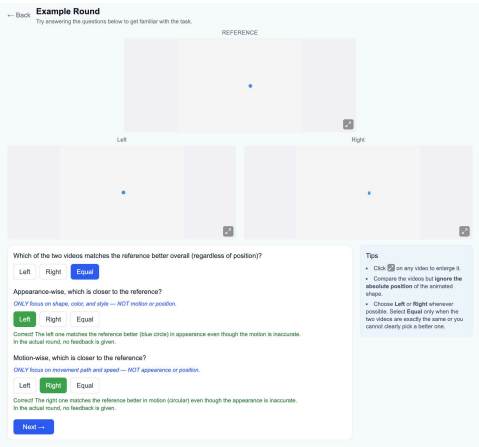
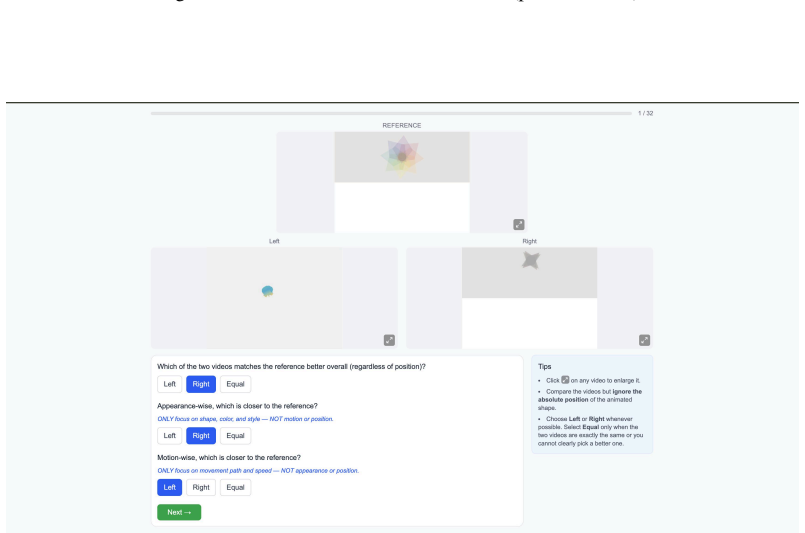
Animation2Code benchmark of video-to-code pairs for web animations, paired with appearance similarity and temporal similarity metrics that disentangle visual fidelity from temporal alignment.
If this is right
- VLMs require explicit mechanisms for tracking motion sequences in video-to-code generation.
- Finetuning on appearance-matched data alone does not close the temporal gap.
- Iterative refinement loops do not reliably correct timing errors in generated animations.
- Evaluation protocols for dynamic visual tasks must separately measure temporal alignment.
Where Pith is reading between the lines
- The temporal failure may arise because training data emphasize static frame matching over change tracking.
- The benchmark could be applied to test whether other modalities like game engines or UI frameworks show the same pattern.
- Improving temporal consistency would directly enable reliable reverse-engineering of timing from example videos.
- The separation of metrics suggests future work should add explicit time-aware loss terms during training.
Load-bearing premise
The two proposed metrics successfully disentangle visual fidelity from temporal alignment in a way that matches human judgment.
What would settle it
A VLM that produces code whose rendered animation scores high on both appearance similarity and temporal similarity metrics across the benchmark set.
Figures



read the original abstract
While recent vision-language models (VLMs) have achieved significant improvements on static visual-to-code tasks such as generating code for webpages, charts, or SVGs, it remains unclear whether they can recover temporal dynamics when motion is present. To this end, we introduce Animation2Code, a benchmark for evaluating temporal visual reasoning via reconstructing executable web animation code from videos. Animation2Code consists of 1,069 web animation videos with diverse visual appearances and motion patterns, paired with corresponding HTML/CSS/JavaScript implementations. We propose two human-aligned metrics, appearance similarity and temporal similarity, which allow us to disentangle visual fidelity from temporal alignment when comparing rendered animations against ground-truth samples. Benchmarking state-of-the-art VLMs on this dataset shows that current VLMs struggle to maintain temporal consistency in reconstruction, even when achieving high appearance similarity, including under finetuning and iterative refinement settings. Code and data are available at https://anya-ji.github.io/animation2code-website .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Animation2Code, a benchmark of 1,069 web animation videos paired with corresponding HTML/CSS/JavaScript code, to assess VLMs' temporal visual reasoning in video-to-code generation. It defines two human-aligned metrics (appearance similarity and temporal similarity) to separate visual fidelity from temporal alignment, and reports that state-of-the-art VLMs fail to maintain temporal consistency even when appearance similarity is high, including after finetuning and iterative refinement. The dataset and code are publicly released.
Significance. If the metrics prove independent and the benchmark construction is reproducible, the work would identify a clear gap in current VLMs for handling temporal dynamics in code reconstruction tasks. The public data release is a concrete strength that supports follow-on research and reproducibility.
major comments (2)
- [Metrics definition and evaluation sections] The central claim that high appearance similarity paired with low temporal similarity indicates a temporal-reasoning failure (rather than metric dependence) rests on the assumption that the two metrics are sufficiently disentangled. No controlled ablation (e.g., injecting appearance noise while holding motion fixed) or empirical correlation between the scores on model outputs is reported, leaving open the possibility of crosstalk through shared rendering or feature pipelines.
- [Benchmark construction] Dataset construction details (collection process, diversity criteria for the 1,069 videos, and any filtering steps) receive only high-level mention; without explicit validation of coverage or inter-annotator agreement on the paired code, it is difficult to assess whether the observed failures generalize beyond the specific animation patterns chosen.
minor comments (2)
- [Metrics] Clarify the exact implementation of the temporal similarity metric (e.g., whether it relies on optical flow, keyframe matching, or frame-wise features) to allow readers to evaluate potential dependence on appearance.
- [Experiments] Add a table or figure showing the correlation between the two similarity scores across model outputs to directly address the independence concern.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive suggestions. We address the major comments point by point below, indicating where revisions will be incorporated to strengthen the manuscript.
read point-by-point responses
-
Referee: [Metrics definition and evaluation sections] The central claim that high appearance similarity paired with low temporal similarity indicates a temporal-reasoning failure (rather than metric dependence) rests on the assumption that the two metrics are sufficiently disentangled. No controlled ablation (e.g., injecting appearance noise while holding motion fixed) or empirical correlation between the scores on model outputs is reported, leaving open the possibility of crosstalk through shared rendering or feature pipelines.
Authors: We agree that providing evidence for the independence of the metrics would better support our claims. The appearance similarity metric is designed to measure visual fidelity on a per-frame basis, while the temporal similarity metric assesses the alignment of animation sequences over time. To address this, we will add an empirical analysis of the correlation between the two metrics computed on the outputs of the evaluated models in the revised version. We will also discuss the design choices that aim to minimize crosstalk. revision: yes
-
Referee: [Benchmark construction] Dataset construction details (collection process, diversity criteria for the 1,069 videos, and any filtering steps) receive only high-level mention; without explicit validation of coverage or inter-annotator agreement on the paired code, it is difficult to assess whether the observed failures generalize beyond the specific animation patterns chosen.
Authors: We acknowledge the need for more detailed documentation of the benchmark construction. The videos were selected to cover a range of visual styles and motion complexities from web animations, with the corresponding code serving as the ground truth. Since the code is directly paired from the source animations rather than through human annotation, inter-annotator agreement does not apply in the traditional sense. We will expand the relevant section to include specific details on the collection process, diversity criteria, and filtering steps to enhance reproducibility and allow better assessment of generalizability. revision: yes
Circularity Check
No significant circularity; benchmark introduces externally verifiable metrics and data release.
full rationale
The paper presents an empirical benchmark evaluation rather than a derivation chain. It defines appearance similarity and temporal similarity as two separate human-aligned metrics on rendered outputs, with public data release at the cited URL. No equations reduce one metric to the other by construction, no parameters are fitted then renamed as predictions, and no self-citations serve as load-bearing uniqueness theorems. The central claim (VLMs fail temporal consistency despite high appearance scores) is an observation on external model outputs against the released dataset, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 1,069 videos cover diverse visual appearances and motion patterns that adequately probe temporal reasoning.
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[2]
pix2code: Generating code from a graphical user interface screenshot
Tony Beltramelli. pix2code: Generating code from a graphical user interface screenshot. In Proceedings of the ACM SIGCHI symposium on engineering interactive computing systems, pages 1–6, 2018
2018
-
[3]
The animation and interactivity principles in multimedia learning.The Cambridge handbook of multimedia learning, pages 287–296, 2005
Mireille Betrancourt. The animation and interactivity principles in multimedia learning.The Cambridge handbook of multimedia learning, pages 287–296, 2005
2005
-
[4]
The use of the area under the roc curve in the evaluation of machine learning algorithms.Pattern recognition, 30(7):1145–1159, 1997
Andrew P Bradley. The use of the area under the roc curve in the evaluation of machine learning algorithms.Pattern recognition, 30(7):1145–1159, 1997
1997
-
[5]
Dynamic dynamic time warping.arXiv preprint arXiv:2310.18128, 2023
Karl Bringmann, Nick Fischer, Ivor van der Hoog, Evangelos Kipouridis, Tomasz Kociumaka, and Eva Rotenberg. Dynamic dynamic time warping.arXiv preprint arXiv:2310.18128, 2023
arXiv 2023
-
[6]
Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, et al. Temporalbench: Benchmarking fine-grained temporal understanding for multimodal video models.arXiv preprint arXiv:2410.10818, 2024
arXiv 2024
-
[7]
Yuhong Dai, Yanlin Lai, Mitt Huang, Hangyu Guo, Dingming Li, Hongbo Peng, Haodong Li, Yingxiu Zhao, Haoran Lyu, Zheng Ge, et al. Webvr: Benchmarking multimodal llms for web- page recreation from videos via human-aligned visual rubrics.arXiv preprint arXiv:2603.13391, 2026
arXiv 2026
-
[8]
Image-to-markup generation with coarse-to-fine attention
Yuntian Deng, Anssi Kanervisto, Jeffrey Ling, and Alexander M Rush. Image-to-markup generation with coarse-to-fine attention. InInternational Conference on Machine Learning, pages 980–989. PMLR, 2017
2017
-
[9]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
2025
-
[10]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023. 10
Pith/arXiv arXiv 2023
-
[11]
Autopresent: Designing structured visuals from scratch
Jiaxin Ge, Zora Zhiruo Wang, Xuhui Zhou, Yi-Hao Peng, Sanjay Subramanian, Qinyue Tan, Maarten Sap, Alane Suhr, Daniel Fried, Graham Neubig, et al. Autopresent: Designing structured visuals from scratch. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2902–2911, 2025
2025
-
[12]
Liger kernel: Efficient triton kernels for llm training.arXiv preprint arXiv:2410.10989, 2024
Pin-Lun Hsu, Yun Dai, Vignesh Kothapalli, Qingquan Song, Shao Tang, Siyu Zhu, Steven Shimizu, Shivam Sahni, Haowen Ning, and Yanning Chen. Liger kernel: Efficient triton kernels for llm training.arXiv preprint arXiv:2410.10989, 2024
arXiv 2024
-
[13]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[14]
Songtao Jiang, Sibo Song, Chenyi Zhou, Yuan Wang, Ruizhe Chen, Tongkun Guan, Ruilin Luo, Yan Zhang, Zhihang Tang, Yuchong Sun, et al. Learning transferable temporal primitives for video reasoning via synthetic videos.arXiv preprint arXiv:2603.17693, 2026
arXiv 2026
-
[15]
Influence of anima- tion on dynamical judgments.Journal of experimental Psychology: Human Perception and performance, 18(3):669, 1992
Mary K Kaiser, Dennis R Proffitt, Susan M Whelan, and Heiko Hecht. Influence of anima- tion on dynamical judgments.Journal of experimental Psychology: Human Perception and performance, 18(3):669, 1992
1992
-
[16]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6013–6022, 2025
2025
-
[17]
Computing krippendorff’s alpha-reliability
Klaus Krippendorff. Computing krippendorff’s alpha-reliability. 2011
2011
-
[18]
Sage publications, 2018
Klaus Krippendorff.Content analysis: An introduction to its methodology. Sage publications, 2018
2018
-
[19]
Hugo Laurençon, Léo Tronchon, and Victor Sanh. Unlocking the conversion of web screenshots into html code with the websight dataset.arXiv preprint arXiv:2403.09029, 2024
arXiv 2024
-
[20]
Baiqi Li, Kangyi Zhao, Ce Zhang, Chancharik Mitra, Jean de Dieu Nyandwi, and Gedas Bertasius. Timeblind: A spatio-temporal compositionality benchmark for video llms.arXiv preprint arXiv:2602.00288, 2026
arXiv 2026
-
[21]
Metal: A multi- agent framework for chart generation with test-time scaling
Bingxuan Li, Yiwei Wang, Jiuxiang Gu, Kai-Wei Chang, and Nanyun Peng. Metal: A multi- agent framework for chart generation with test-time scaling. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 30054–30069, 2025
2025
-
[22]
Unisvg: A unified dataset for vector graphic understanding and generation with multimodal large language models
Jinke Li, Jiarui Yu, Chenxing Wei, Hande Dong, Qiang Lin, Liangjing Yang, Zhicai Wang, and Yanbin Hao. Unisvg: A unified dataset for vector graphic understanding and generation with multimodal large language models. InProceedings of the 33rd ACM International Conference on Multimedia, pages 13156–13163, 2025
2025
-
[23]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
-
[24]
Yunxin Li, Xinyu Chen, Baotian Hu, Longyue Wang, Haoyuan Shi, and Min Zhang. Videovista: A versatile benchmark for video understanding and reasoning.arXiv preprint arXiv:2406.11303, 2024
arXiv 2024
-
[25]
Logomotion: Visually-grounded code synthesis for creating and editing animation
Vivian Liu, Rubaiat Habib Kazi, Li-Yi Wei, Matthew Fisher, Timothy Langlois, Seth Walker, and Lydia Chilton. Logomotion: Visually-grounded code synthesis for creating and editing animation. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–16, 2025. 11
2025
-
[26]
Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
2024
-
[27]
Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
2023
-
[28]
Video-bench: A comprehensive benchmark and toolkit for evaluating video-based large language models.Computational Visual Media, 2025
Munan Ning, Bin Zhu, Yujia Xie, Bin Lin, Jiaxi Cui, Lu Yuan, Dongdong Chen, and Li Yuan. Video-bench: A comprehensive benchmark and toolkit for evaluating video-based large language models.Computational Visual Media, 2025
2025
-
[29]
Chart2code53: A large-scale diverse and complex dataset for enhancing chart-to-code generation
Tianhao Niu, Yiming Cui, Baoxin Wang, Xiao Xu, Xin Yao, Qingfu Zhu, Dayong Wu, Shijin Wang, and Wanxiang Che. Chart2code53: A large-scale diverse and complex dataset for enhancing chart-to-code generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15839–15855, 2025
2025
-
[30]
Jihyeon Park, Jiyoon Myung, Seone Shin, Jungki Son, and Joohyung Han. Decomate: Lever- aging generative models for co-creative svg animation.arXiv preprint arXiv:2511.06297, 2025
arXiv 2025
-
[31]
Prolific: Online participant recruitment platform
Prolific. Prolific: Online participant recruitment platform. https://www.prolific.com, 2026
2026
-
[32]
Tianrun Qiu and Yuxin Ma. Anyani: An interactive system with generative ai for animation effect creation and code understanding in web development.arXiv preprint arXiv:2506.21962, 2025
arXiv 2025
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[34]
Image2struct: Benchmarking structure extraction for vision-language models.Advances in Neural Information Processing Systems, 37:115058–115097, 2024
Josselin S Roberts, Tony Lee, Chi H Wong, Michihiro Yasunaga, Yifan Mai, and Percy Liang. Image2struct: Benchmarking structure extraction for vision-language models.Advances in Neural Information Processing Systems, 37:115058–115097, 2024
2024
-
[35]
Design2code: Benchmarking multimodal code generation for automated front-end engineering
Chenglei Si, Yanzhe Zhang, Ryan Li, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: Benchmarking multimodal code generation for automated front-end engineering. InProceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 3...
2025
-
[36]
Revisit- ing code similarity evaluation with abstract syntax tree edit distance
Yewei Song, Cedric Lothritz, Xunzhu Tang, Tegawendé Bissyandé, and Jacques Klein. Revisit- ing code similarity evaluation with abstract syntax tree edit distance. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers), pages 38–46, 2024
2024
-
[37]
Animation: can it facilitate? International journal of human-computer studies, 57(4):247–262, 2002
Barbara Tversky, Julie Bauer Morrison, and Mireille Betrancourt. Animation: can it facilitate? International journal of human-computer studies, 57(4):247–262, 2002
2002
-
[38]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612,
-
[39]
doi: 10.1109/TIP.2003.819861
-
[40]
Plot2code: A comprehensive benchmark for evaluating multi-modal large language models in code generation from scientific plots
Chengyue Wu, Zhixuan Liang, Yixiao Ge, Qiushan Guo, Zeyu Lu, Jiahao Wang, Ying Shan, and Ping Luo. Plot2code: A comprehensive benchmark for evaluating multi-modal large language models in code generation from scientific plots. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 3006–3028, 2025
2025
-
[41]
Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping
Jingyu Xiao, Yuxuan Wan, Yintong Huo, Zixin Wang, Xinyi Xu, Wenxuan Wang, Zhiyao Xu, Yuhang Wang, and Michael R Lyu. Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 241–253. IEEE, 2025. 12
2025
-
[42]
Chengzhi Xu, Yuyang Wang, Lai Wei, Lichao Sun, and Weiran Huang. Improved iterative refine- ment for chart-to-code generation via structured instruction.arXiv preprint arXiv:2506.14837, 2025
arXiv 2025
-
[43]
Phyt2v: Llm-guided iterative self- refinement for physics-grounded text-to-video generation
Qiyao Xue, Xiangyu Yin, Boyuan Yang, and Wei Gao. Phyt2v: Llm-guided iterative self- refinement for physics-grounded text-to-video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18826–18836, 2025
2025
-
[44]
Yunqiao Yang, Wenbo Li, Houxing Ren, Zimu Lu, Ke Wang, Zhiyuan Huang, Zhuofan Zong, Mingjie Zhan, and Hongsheng Li. Slidesgen-bench: Evaluating slides generation via computa- tional and quantitative metrics.arXiv preprint arXiv:2601.09487, 2026
arXiv 2026
-
[45]
Space-time diffusion features for zero-shot text-driven motion transfer
Danah Yatim, Rafail Fridman, Omer Bar-Tal, Yoni Kasten, and Tali Dekel. Space-time diffusion features for zero-shot text-driven motion transfer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8466–8476, 2024
2024
-
[46]
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442, 2019
Pith/arXiv arXiv 1910
-
[47]
Web2code: A large-scale webpage- to-code dataset and evaluation framework for multimodal llms.Advances in neural information processing systems, 37:112134–112157, 2024
Sukmin Yun, Haokun Lin, Rusiru Thushara, Mohammad Q Bhat, Yongxin Wang, Zutao Jiang, Mingkai Deng, Jinhong Wang, Tianhua Tao, Junbo Li, et al. Web2code: A large-scale webpage- to-code dataset and evaluation framework for multimodal llms.Advances in neural information processing systems, 37:112134–112157, 2024
2024
-
[48]
Chartcoder: Advancing multimodal large language model for chart-to-code generation
Xuanle Zhao, Xianzhen Luo, Qi Shi, Chi Chen, Shuo Wang, Zhiyuan Liu, and Maosong Sun. Chartcoder: Advancing multimodal large language model for chart-to-code generation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 7333–7348, 2025
2025
-
[49]
Animated only
Bocheng Zou, Mu Cai, Jianrui Zhang, and Yong Jae Lee. Vgbench: Evaluating large language models on vector graphics understanding and generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3647–3659, 2024. 13 Appendix The appendix is organized as follows: • Appendix A: Data Processing Details • Appendix ...
2024
-
[50]
OBJECTS: List every visual element (shapes, text, images) with their colors, sizes, and initial positions. 2. MOTION: For each moving element, describe the trajectory, direction, and distance of movement. 3. TIMING: Describe duration, delays, easing functions (linear, ease-in, ease-out, bounce, etc.), and whether animations loop. 4. SEQUENCE: What happens...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.