P-Cast Precision in FP8 Attention: Sink-Induced Collapse and the Optimality of S=2⁸
Pith reviewed 2026-06-28 07:53 UTC · model grok-4.3
The pith
Forward KV iteration causes P-collapse in FP8 attention by underflowing a normal-tail fraction of non-sink probabilities, which reverse iteration with S=256 prevents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
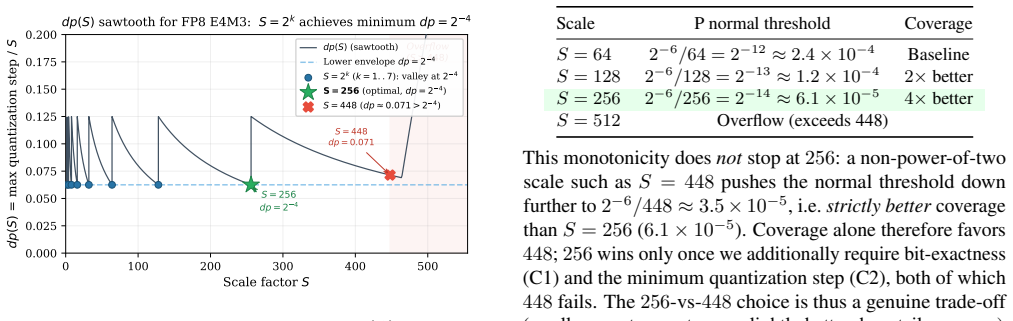
Forward KV iteration causes P-collapse -- to leading order a fraction Φ(Δ + δ_k - 6.93 - ln S) of non-sink P values underflow to zero, where the small shift δ_k ≈ 1 (for k_sink = 4) is the expected within-sink-block score maximum -- and that reverse iteration removes it, with a zero-underflow guarantee when reverse is combined with S=256. S = 256 = 2^8 is the static scale that simultaneously satisfies (i) bit-exact IEEE 754 scaling, (ii) the lower envelope of a sawtooth function dp(S) over the E4M3 number line (dp = 2^{-4}), and (iii) the maximum normal-range coverage among bit-exact (2^k) scales.
What carries the argument
The P-collapse quantified by the normal-tail expression Φ(Δ + δ_k - 6.93 - ln S) under forward KV iteration, together with the three optimality conditions that single out S=256 for FP8 casting of P.
If this is right
- Reverse KV iteration removes P-collapse.
- Reverse iteration combined with S=256 supplies a zero-underflow guarantee.
- S=256 simultaneously satisfies bit-exact IEEE 754 scaling, the lower envelope of dp(S), and maximum normal-range coverage among 2^k scales.
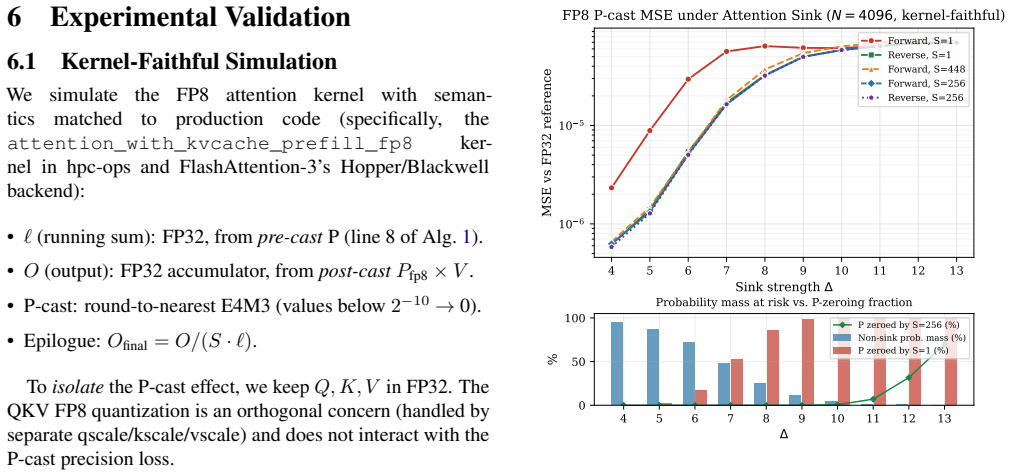
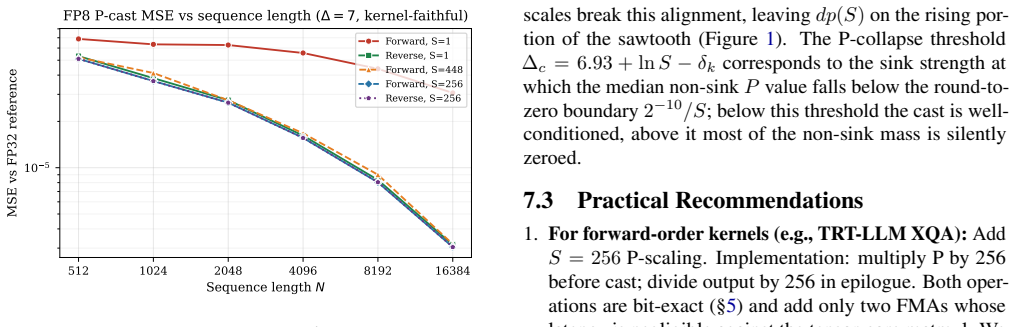
- Kernel-faithful experiments show 3–10× MSE improvement at moderate sink strengths.
- The two fixes together saturate to the same precision floor.
Where Pith is reading between the lines
- The closed-form threshold Δ_c = 6.93 + ln S - δ_k supplies a direct way to predict kernel-level precision loss from sink strength alone.
- Non-bit-exact scales such as 448 attain slightly higher coverage but sacrifice the bit-exact property that S=256 preserves.
- If per-row score distributions deviate from the assumed normal tails, the predicted collapse fraction will no longer match observations.
- The same iteration-order and scale considerations may apply to other low-precision formats when attention sinks are present.
Load-bearing premise
The leading-order underflow model assumes that non-sink attention scores are distributed such that their underflow probability is captured by the normal tail Φ(Δ + δ_k - 6.93 - ln S) with δ_k ≈ 1 for k_sink = 4.
What would settle it
Measure the actual fraction of non-sink P entries that underflow to zero in a controlled kernel run with known Δ, δ_k, and S, then compare the measured fraction against the predicted value of Φ(Δ + δ_k - 6.93 - ln S).
Figures
read the original abstract
FP8 (E4M3) acceleration for attention computation offers significant throughput gains, but the 3-bit mantissa introduces precision challenges when the softmax probability matrix~$P$ is cast to FP8 before the $P \cdot V$ matrix multiplication. We analyze two implementation choices that affect output precision under the \emph{Attention Sink} phenomenon: (1)~the KV block iteration order, and (2) the static scaling factor applied to $P$ before casting. We show that forward KV iteration causes \emph{P-collapse} -- to leading order a fraction $\Phi(\Delta + \delta_k - 6.93 - \ln S)$ of non-sink $P$ values underflow to zero, where the small shift $\delta_k \approx 1$ (for $k_{\text{sink}}{=}4$) is the expected within-sink-block score maximum -- and that reverse iteration removes it, with a zero-underflow guarantee when reverse is combined with $S{=}256$. We further give a constructive characterization of $S = 256 = 2^8$ as the static scale that simultaneously satisfies (i)~bit-exact IEEE 754 scaling, (ii) the lower envelope of a sawtooth function $dp(S)$ over the E4M3 number line ($dp = 2^{-4}$, the minimum worst-case quantization step), and (iii)~the maximum normal-range coverage \emph{among bit-exact ($2^k$) scales} (a non-bit-exact scale such as $448$ attains slightly higher coverage; sec.5}). Both optimizations are already deployed in FlashAttention-3/4 on engineering grounds; our contribution is a quantitative account of \emph{why} these choices are good and a closed-form threshold $\Delta_c = 6.93 + \ln S - \delta_k$ for predicting kernel-level precision loss. Kernel-faithful experiments ($Q, K, V$ in FP32 to isolate the P-cast effect) show $3$-$10\times$ MSE improvement at moderate sink strengths, and paired tests confirm both fixes saturate to the same precision floor when combined -- which motivated updating the hpc-ops kernel from $S{=}1$ to $S{=}256$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that forward KV iteration in FP8 (E4M3) attention causes P-collapse, with the fraction of underflowing non-sink P values given to leading order by the normal CDF Φ(Δ + δ_k - 6.93 - ln S) (δ_k ≈ 1 for k_sink = 4), while reverse iteration removes it and guarantees zero underflow when combined with S = 256. It further provides a constructive characterization of S = 256 = 2^8 as the static scale that simultaneously satisfies bit-exact IEEE 754 scaling, the lower envelope of the sawtooth dp(S) (dp = 2^{-4}), and maximum normal-range coverage among bit-exact (2^k) scales. Kernel-faithful experiments (Q, K, V in FP32) report 3–10× MSE improvement at moderate sink strengths and confirm that both fixes saturate to the same precision floor.
Significance. If the results hold, the work supplies a quantitative account of why reverse iteration and S = 256 are effective in FlashAttention-3/4, together with the closed-form threshold Δ_c = 6.93 + ln S - δ_k for predicting kernel-level precision loss. The kernel-faithful experiments that isolate the P-cast effect are a strength, as is the explicit multi-criterion characterization of the optimal scale.
major comments (2)
- [Abstract (Φ expression) and corresponding derivation section] The leading-order underflow model (Abstract, paragraph describing the Φ expression): the fraction Φ(Δ + δ_k - 6.93 - ln S) and the derived threshold Δ_c assume that non-sink attention scores are distributed such that their underflow probability matches the standard normal tail. No histogram, QQ-plot, or Kolmogorov-Smirnov test validating normality in the critical tail region is supplied; the kernel-faithful experiments report only aggregate MSE. This assumption is load-bearing for the claimed collapse fraction and zero-underflow guarantee.
- [Section 5] Section 5 (optimality characterization): the claim that S = 256 simultaneously satisfies the three listed criteria is scoped to bit-exact (2^k) scales, yet the text notes that a non-bit-exact scale such as 448 attains slightly higher coverage. The optimality statement should be restated with explicit scope to avoid implying global optimality.
minor comments (2)
- [Abstract] The parameter δ_k is introduced as the expected within-sink-block score maximum with an approximate value; a precise definition or derivation equation should be given at first use.
- [Experiments section] The paired-test results confirming saturation to the same precision floor would be clearer with a table of MSE values across forward, reverse, and combined configurations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and agree that both points warrant revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract (Φ expression) and corresponding derivation section] The leading-order underflow model (Abstract, paragraph describing the Φ expression): the fraction Φ(Δ + δ_k - 6.93 - ln S) and the derived threshold Δ_c assume that non-sink attention scores are distributed such that their underflow probability matches the standard normal tail. No histogram, QQ-plot, or Kolmogorov-Smirnov test validating normality in the critical tail region is supplied; the kernel-faithful experiments report only aggregate MSE. This assumption is load-bearing for the claimed collapse fraction and zero-underflow guarantee.
Authors: We agree that the derivation relies on a normality assumption for non-sink attention scores in the tail region and that this is load-bearing for the closed-form collapse fraction. While the kernel-faithful experiments produce MSE results consistent with the model predictions, we acknowledge the absence of direct statistical validation. In the revised manuscript we will add QQ-plots of the relevant score distributions together with a Kolmogorov-Smirnov test focused on the critical tail to substantiate the assumption. revision: yes
-
Referee: [Section 5] Section 5 (optimality characterization): the claim that S = 256 simultaneously satisfies the three listed criteria is scoped to bit-exact (2^k) scales, yet the text notes that a non-bit-exact scale such as 448 attains slightly higher coverage. The optimality statement should be restated with explicit scope to avoid implying global optimality.
Authors: The abstract already qualifies the optimality claim as holding among bit-exact (2^k) scales and explicitly notes that a non-bit-exact scale such as 448 attains slightly higher coverage. To prevent any ambiguity, we will revise the wording in Section 5 to restate this scope with equal explicitness in the main text. revision: yes
Circularity Check
No circularity: model derives from explicit distributional assumption and constructive characterization, not self-fit or self-citation
full rationale
The leading-order expression Φ(Δ + δ_k - 6.93 - ln S) is presented as following from a normal-tail model of non-sink scores together with the FP8 underflow threshold; the constant 6.93 is introduced as part of that derivation rather than obtained by fitting the target collapse fraction. The optimality claim for S=256 is supported by three independent constructive properties (IEEE bit-exact scaling, sawtooth dp(S) lower envelope, and maximal normal-range coverage among 2^k scales) with no reduction to a fitted parameter or prior self-result. No self-citations appear in the load-bearing steps. The paper explicitly flags the normality assumption as the weakest link, rendering the claim falsifiable rather than tautological by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- δ_k =
~1
axioms (1)
- domain assumption Non-sink attention scores are distributed such that their underflow probability after scaling is given by the normal tail Φ(Δ + δ_k - 6.93 - ln S).
Reference graph
Works this paper leans on
-
[1]
Why do llms attend to the first token?arXiv preprint arXiv:2504.02732,
Federico Barbero, Álvaro Arroyo, Xiangming Gu, Christos Perivolaropoulos, Michael Bronstein, Petar Veli ˇckovi´c, and Razvan Pascanu. Why do LLMs attend to the first token? arXiv preprint arXiv:2504.02732, 2025
-
[2]
FlashAttention-2: Faster attention with better par- allelism and work partitioning.International Conference on Learning Representations, 2024
Tri Dao. FlashAttention-2: Faster attention with better par- allelism and work partitioning.International Conference on Learning Representations, 2024
2024
-
[3]
Fu, Stefano Ermon, Atri Rudra, and Christo- pher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christo- pher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness.Advances in Neural Information Processing Systems, 35, 2022
2022
-
[4]
When Attention Sink Emerges in Language Models: An Empirical View
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, et al. FP8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision.arXiv preprint arXiv:2407.08608, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Massive Activations in Large Language Models
Mingjie Sun, Xinlei Chen, J. Zico Kolter, and Zhuang Liu. Massive activations in large language models.arXiv preprint arXiv:2402.17762, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Efficient streaming language models with atten- tion sinks.International Conference on Learning Representa- tions, 2024
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with atten- tion sinks.International Conference on Learning Representa- tions, 2024
2024
-
[9]
SageAttention2: Efficient attention with thorough outlier smoothing and per-thread INT4 quantization
Jintao Zhang, Haofeng Huang, Pengle Zhang, Jia Wei, Jun Zhu, and Jianfei Chen. SageAttention2: Efficient attention with thorough outlier smoothing and per-thread INT4 quantization. arXiv preprint arXiv:2411.10958, 2024
-
[10]
Jintao Zhang, Xiaoming Xu, Jia Wei, Haofeng Huang, Pengle Zhang, Chendong Xiang, Jun Zhu, and Jianfei Chen. SageAt- tention2++: A more efficient implementation of SageAtten- tion2.arXiv preprint arXiv:2505.21136, 2025. A Completedp(S)Verification We verify Theorem 6 by exhaustive computation over all 126 positive E4M3 values: for each S, take the binade w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.