Integrated and Cross-Architecture Interpretation of LLM Reasoning
Pith reviewed 2026-06-29 13:11 UTC · model grok-4.3
The pith
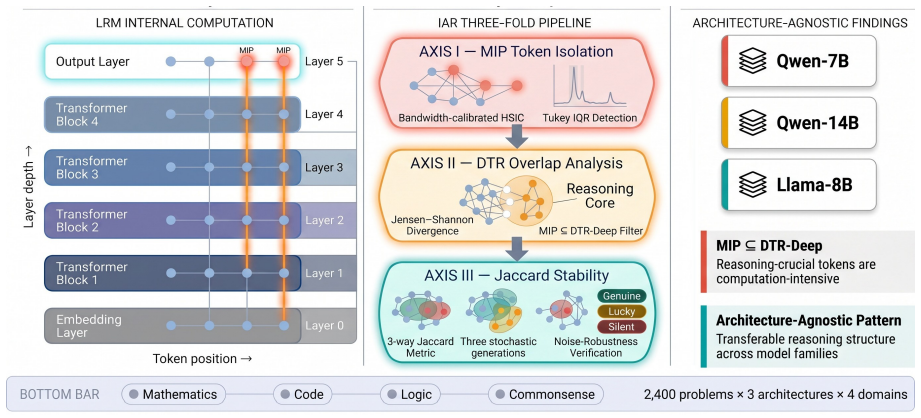
The IAR framework isolates reasoning-crucial tokens at the output layer with calibrated MIP and Tukey IQR then traces their cross-layer paths through DTR overlap and checks stability via Jaccard across domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The IAR framework provides a unified approach to LLM reasoning interpretability by isolating reasoning-crucial tokens at the output layer with bandwidth-calibrated MIP and Tukey IQR, tracing their cross-layer trajectories via overlap with DTR-deep tokens, and verifying stability with Jaccard metric across domains.
What carries the argument
The Integrated, cross-Architecture Reasoning (IAR) framework, which isolates output-layer tokens via MIP plus Tukey IQR, traces trajectories by overlap with DTR-deep tokens, and measures consistency with the Jaccard metric.
If this is right
- Reasoning-crucial tokens can be isolated at the output layer for Qwen-7B, Qwen-14B, and Llama-8B models.
- Overlap analysis shows whether those tokens are computation-intensive and how their patterns change across layers.
- Jaccard stability holds across mathematics, code, logic, and common-sense domains, confirming the tokens support reliable reasoning.
- The combined method yields interpretation that generalizes across different model architectures.
Where Pith is reading between the lines
- If the identified tokens prove causal, targeted editing of those tokens could raise accuracy on multi-step problems without retraining.
- Applying the same isolation-plus-overlap procedure to newer or larger models would test whether the token trajectories remain consistent.
- Pairing IAR token sets with activation patching experiments could check whether the selected tokens are necessary for correct reasoning.
Load-bearing premise
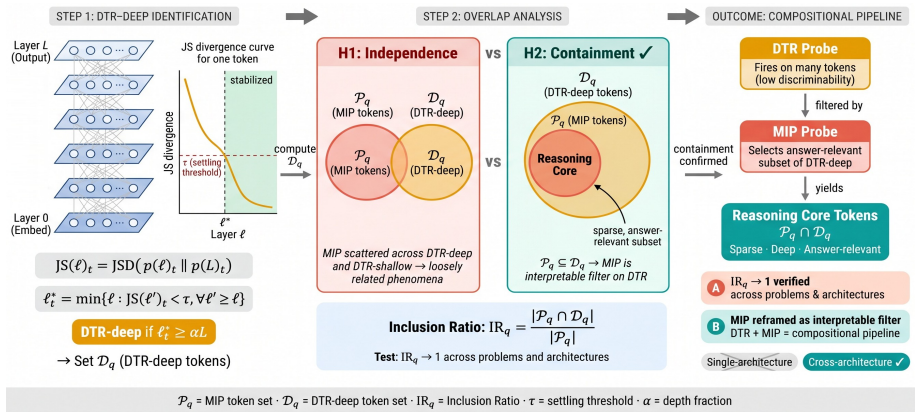
That overlap between MIP-selected tokens and DTR-deep tokens accurately follows genuine reasoning paths rather than surface correlations.
What would settle it
Finding that models with high Jaccard overlap between MIP and DTR tokens still produce incorrect answers on held-out reasoning problems, or that low-overlap tokens better predict correct outputs, would falsify the central claim.
Figures
read the original abstract
Understanding how LLMs reason is hindered by a practical asymmetry: while their generated outputs are observable, the underlying reasoning patterns remain opaque. Relying on single probes, such as Mutual Information Peak (MIP) or Deep-Thinking Ratio (DTR), risks underestimating the genuine inferential structure. To response this deficiency, we present an Integrated, cross-Architecture Reasoning (IAR) framework, designed to provide a unified approach to LLM reasoning interpretability. Specifically, we first propose to use bandwidth-calibrated MIP coupled with Tukey IQR peak-detection to isolate reasoning-crucial tokens at the output layer. Second, we performed an overlap analysis between MIP-picked tokens and DTR-deep tokens to trace the cross-layer trajectories of those tokens. This also discloses whether reasoning-crucial tokens are computation-intensive as well, further facilitating to understand how reasoning patterns evolve across model layers. Finally, we apply a Jaccard stability metric over multi-domain problems to verify if the MIP-identified tokens are reasoning quality-guaranteed. Extensive experiments on three models (Qwen-7B, Qwen-14B, and Llama-8B) across four domains (mathematics, code, logic, and common sense) demonstrate IAR's generalizable interpretation capabilities across architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the Integrated and Cross-Architecture Reasoning (IAR) framework for LLM interpretability. It combines bandwidth-calibrated Mutual Information Peak (MIP) with Tukey IQR peak detection to isolate reasoning-crucial tokens at the output layer, conducts overlap analysis between MIP tokens and Deep-Thinking Ratio (DTR) tokens to trace cross-layer trajectories, and applies a Jaccard stability metric across multi-domain problems to verify whether MIP-identified tokens are 'reasoning quality-guaranteed.' Experiments are reported on Qwen-7B, Qwen-14B, and Llama-8B across mathematics, code, logic, and common-sense domains, claiming generalizable capabilities across architectures.
Significance. If the proxy statistics (MIP+IQR, DTR overlap, Jaccard) were shown to correspond to causally relevant reasoning steps and task performance, the framework would supply a practical, multi-probe method for cross-architecture analysis that improves on single-probe approaches. The work is empirical rather than axiomatic and does not claim parameter-free derivations or machine-checked proofs.
major comments (3)
- [Abstract] Abstract (final paragraph): the claim that Jaccard stability 'verifies if the MIP-identified tokens are reasoning quality-guaranteed' is unsupported. Jaccard similarity only quantifies token-set overlap across domains; it supplies no information on correlation with task accuracy, inference correctness, or human-identified reasoning chains.
- [Overlap analysis] Section describing overlap analysis: the assertion that overlap between MIP-picked tokens and DTR-deep tokens 'traces the cross-layer trajectories' and discloses whether tokens are 'computation-intensive' rests on an untested assumption that shared tokens are causally involved in reasoning rather than co-occurring for unrelated reasons. No ablation or causal intervention is described to test this mapping.
- [Experiments] Experiments section: no quantitative results (accuracy deltas, correlation coefficients, or human alignment scores) are referenced that would demonstrate the framework isolates tokens more effectively than MIP or DTR alone, undermining the 'unified approach' and 'generalizable interpretation capabilities' claims.
minor comments (2)
- [Abstract] Abstract: 'To response this deficiency' should read 'To address this deficiency.'
- [Methods] Notation: 'bandwidth-calibrated MIP' and 'Tukey IQR peak-detection' are introduced without explicit formulas or parameter values in the abstract; these should be defined with equations in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating revisions where the concerns are valid and providing clarifications on the scope of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the claim that Jaccard stability 'verifies if the MIP-identified tokens are reasoning quality-guaranteed' is unsupported. Jaccard similarity only quantifies token-set overlap across domains; it supplies no information on correlation with task accuracy, inference correctness, or human-identified reasoning chains.
Authors: We agree that the original phrasing overstates the Jaccard metric's implications. Jaccard stability is used to measure consistency of MIP token sets across domains, which we interpret as supporting generalizability but does not directly correlate with accuracy or human reasoning chains. We will revise the abstract to state that the metric 'assesses the cross-domain stability of MIP-identified tokens' without claiming verification of reasoning quality. revision: yes
-
Referee: [Overlap analysis] Section describing overlap analysis: the assertion that overlap between MIP-picked tokens and DTR-deep tokens 'traces the cross-layer trajectories' and discloses whether tokens are 'computation-intensive' rests on an untested assumption that shared tokens are causally involved in reasoning rather than co-occurring for unrelated reasons. No ablation or causal intervention is described to test this mapping.
Authors: The overlap analysis is presented as an observational probe to identify shared tokens between output-layer MIP and deeper DTR layers, suggesting possible trajectories. We acknowledge the correlational nature and lack of causal interventions. We will revise the section to clarify that overlap indicates co-occurrence rather than proven causal involvement in reasoning, and add explicit discussion of this limitation. revision: yes
-
Referee: [Experiments] Experiments section: no quantitative results (accuracy deltas, correlation coefficients, or human alignment scores) are referenced that would demonstrate the framework isolates tokens more effectively than MIP or DTR alone, undermining the 'unified approach' and 'generalizable interpretation capabilities' claims.
Authors: The experiments demonstrate application of the integrated framework across architectures and domains rather than direct benchmarking against single probes via performance metrics. We agree this limits support for superiority claims. We will qualify the 'unified approach' language in the experiments and conclusion sections to focus on complementary insights rather than proven improvement, and add any available correlation statistics if feasible from existing data. revision: partial
Circularity Check
No circularity: empirical framework with no derivation chain
full rationale
The paper describes an empirical IAR framework that proposes bandwidth-calibrated MIP + Tukey IQR for token isolation, overlap analysis with DTR tokens for trajectory tracing, and Jaccard metric for stability verification across models and domains. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the abstract or described methods. All components are presented as direct proposals and experimental applications without any reduction of outputs to inputs by construction. The work is self-contained as an empirical methodology and does not invoke uniqueness theorems or ansatzes from prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shourya Aggarwal, Divyanshu Mandowara, Vishwajeet Agrawal, Dinesh Khandelwal, Parag Singla, and Dinesh Garg. 2021. Explanations for CommonsenseQA : New dataset and models. In Proceedings of ACL-IJCNLP
2021
-
[2]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. 2023. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Feng Chen, Allan Raventos, Nan Cheng, Surya Ganguli, and Shaul Druckmann. 2026 a . Rethinking fine-tuning when scaling test-time compute: Limiting confidence improves mathematical reasoning. Advances in Neural Information Processing Systems, 38:158785--158818
2026
- [5]
-
[6]
Xin Chen, Hanxian Huang, Yanjun Gao, Yi Wang, Jishen Zhao, and Ke Ding. 2024. Learning to maximize mutual information for chain-of-thought distillation. In Findings of the Association for Computational Linguistics: ACL 2024, pages 6857--6868
2024
-
[7]
Yew Ken Chia, Guizhen Chen, Weiwen Xu, Luu Anh Tuan, Soujanya Poria, and Lidong Bing. 2024. Reasoning paths optimization: Learning to reason and explore from diverse paths. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16763--16780
2024
-
[8]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, John Schulman, and 1 others. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
DeepSeek-AI . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. 2026. Scaling up test-time compute with latent reasoning: A recurrent depth approach. Advances in Neural Information Processing Systems, 38:41340--41391
2026
-
[11]
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
2021
-
[12]
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. 2024. Think before you speak: Training language models with pause tokens. In International Conference on Learning Representations
2024
-
[13]
Arthur Gretton, Olivier Bousquet, Alex Smola, and Bernhard Sch \"o lkopf. 2005. Measuring statistical dependence with Hilbert-Schmidt norms. In Algorithmic Learning Theory (ALT), pages 63--77. Springer
2005
-
[14]
Wen-Chao Hu, Wang-Zhou Dai, Yuan Jiang, and Zhi-Hua Zhou. 2025. Efficient rectification of neuro-symbolic reasoning inconsistencies by abductive reflection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17333--17341
2025
-
[15]
Yuichi Inoue, Kou Misaki, Yuki Imajuku, So Kuroki, Taishi Nakamura, and Takuya Akiba. 2026. Wider or deeper? scaling llm inference-time compute with adaptive branching tree search. Advances in Neural Information Processing Systems, 38:35448--35484
2026
-
[16]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others. 2024. Openai o1 system card. arXiv preprint arXiv:2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems, volume 35
2022
-
[18]
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, and 1 others. 2023. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Zhenyu Lei, Zhen Tan, Song Wang, Yaochen Zhu, Zihan Chen, Yushun Dong, and Jundong Li. 2025. Learning from diverse reasoning paths with routing and collaboration. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2832--2845
2025
-
[20]
Wengang Li, Lingqi Zhang, Toshio Endo, and Mohamed Wahib. 2026. Understanding cross-layer contributions to mixture-of-experts routing in llms. In The Fourteenth International Conference on Learning Representations
2026
-
[21]
Weibin Liao, Xu Chu, and Yasha Wang. 2025. Tpo: Aligning large language models with multi-branch & multi-step preference trees. In International Conference on Learning Representations, volume 2025, pages 26698--26720
2025
-
[22]
Marcus J Min, Yangruibo Ding, Luca Buratti, Saurabh Pujar, Gail Kaiser, Suman Jana, and Baishakhi Ray. 2024. Beyond accuracy: Evaluating self-consistency of code large language models with identitychain. In International Conference on Learning Representations, volume 2024, pages 5454--5469
2024
- [23]
-
[24]
Anirudh Phukan, Divyansh Divyansh, Harshit Kumar Morj, Vaishnavi Vaishnavi, Apoorv Saxena, and Koustava Goswami. 2025. Beyond logit lens: Contextual embeddings for robust hallucination detection & grounding in vlms. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language...
2025
-
[25]
Chen Qian, Dongrui Liu, Haochen Wen, Zhen Bai, Yong Liu, and Jing Shao. 2026. Demystifying reasoning dynamics with mutual information: Thinking tokens are information peaks in llm reasoning. Advances in Neural Information Processing Systems, 38:12533--12572
2026
-
[26]
Leonardo Ranaldi and Andre Freitas. 2024. Aligning large and small language models via chain-of-thought reasoning. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1812--1827
2024
-
[27]
Subramanyam Sahoo, Aman Chadha, Vinija Jain, and Divya Chaudhary. 2026. When shallow wins: Silent failures and the depth-accuracy paradox in latent reasoning. In ICLR 2026 Workshop on Latent and Implicit Thinking
2026
-
[28]
Pratyusha Sharma, Jordan Ash, and Dipendra Kumar Misra. 2024. The truth is in there: Improving reasoning in language models with layer-selective rank reduction. In International Conference on Learning Representations, volume 2024, pages 17632--17651
2024
-
[29]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2025. Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning. In International Conference on Learning Representations, volume 2025, pages 10131--10165
2025
-
[30]
Zayne Sprague, Fangcong Yin, Juan Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett. 2025. To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning. In International Conference on Learning Representations, volume 2025, pages 94118--94162
2025
-
[31]
Kaya Stechly, Karthik Valmeekam, and Subbarao Kambhampati. 2024. Chain of thoughtlessness? an analysis of cot in planning. Advances in Neural Information Processing Systems, 37:29106--29141
2024
-
[32]
Le, Ed H
Mirac Suzgun, Nathan Scales, Nathanael Sch \"a rli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, and Jason Wei. 2022. Challenging BIG-Bench tasks and whether chain-of-thought can solve them. In Findings of the Association for Computational Linguistics: ACL 2023
2022
-
[33]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. CommonsenseQA : A question answering challenge targeting commonsense knowledge. In Proceedings of NAACL-HLT
2019
-
[34]
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. 2025. Confidence improves self-consistency in llms. In Findings of the Association for Computational Linguistics: ACL 2025, pages 20090--20111
2025
-
[35]
Boshi Wang, Xiang Yue, Yu Su, and Huan Sun. 2024 a . Grokking of implicit reasoning in transformers: A mechanistic journey to the edge of generalization. Advances in Neural Information Processing Systems, 37:95238--95265
2024
-
[36]
Han Wang, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. 2024 b . Soft self-consistency improves language models agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 287--301
2024
-
[37]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations
2023
-
[38]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems
2022
-
[39]
Chenxin Xu, Robby T Tan, Yuhong Tan, Siheng Chen, Yu Guang Wang, Xinchao Wang, and Yanfeng Wang. 2023. Eqmotion: Equivariant multi-agent motion prediction with invariant interaction reasoning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1410--1420
2023
-
[40]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, volume 36
2023
-
[41]
Xixian Yong, Xiao Zhou, Yingying Zhang, Jinlin Li, Yefeng Zheng, and Xian Wu. 2026. Think or not? exploring thinking efficiency in large reasoning models via an information-theoretic lens. Advances in Neural Information Processing Systems, 38:2787--2827
2026
-
[42]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[43]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.