LegalGraphRAG: Multi-Agent Graph Retrieval-Augmented Generation for Reliable Legal Reasoning
Pith reviewed 2026-06-29 13:13 UTC · model grok-4.3
The pith
LegalGraphRAG builds a hierarchical legal graph and uses a three-agent verification system to produce more accurate and transparent legal reasoning than standard GraphRAG methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
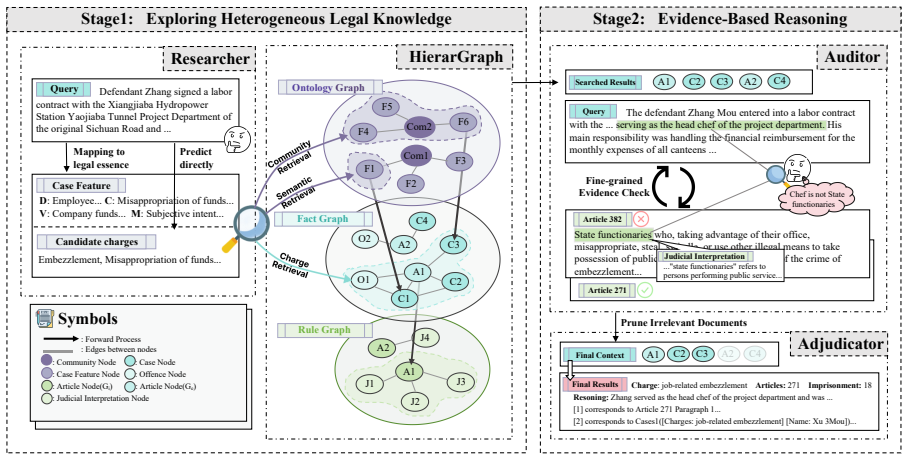
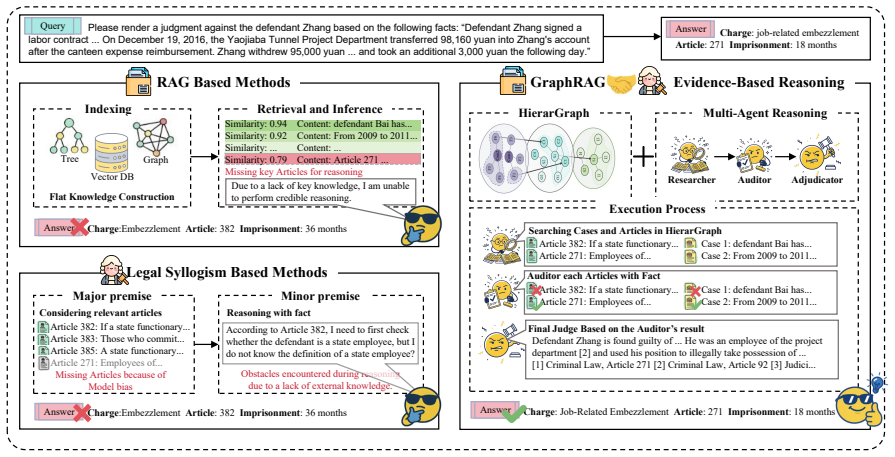
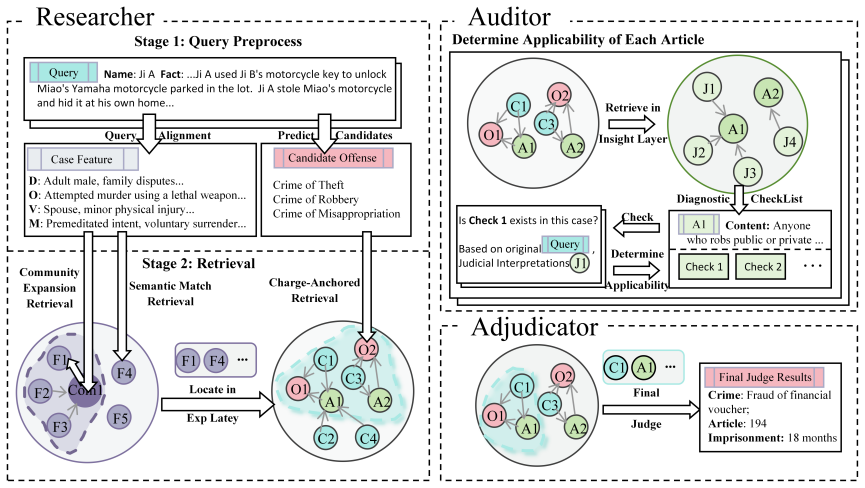
LegalGraphRAG introduces a hierarchical legal graph that differentiates factual details, applied rules, and abstract principles across cases, articles, and interpretations, paired with a multi-agent workflow in which a Researcher retrieves candidate evidence, an Auditor cross-checks its validity against source documents, and an Adjudicator synthesizes the verified set into a final judgment; this combination delivers state-of-the-art accuracy and trustworthiness on legal reasoning benchmarks.
What carries the argument
The hierarchical legal graph for organizing multi-granular legal knowledge plus the Researcher-Auditor-Adjudicator multi-agent loop that enforces evidence verification before judgment.
If this is right
- Retrieval can now target the correct abstraction level within heterogeneous legal corpora instead of returning mismatched granularity.
- Reasoning steps become traceable because only Auditor-verified evidence reaches the final judgment.
- Error-prone direct passage of unverified context to the LLM is replaced by explicit verification.
- The same architecture can be applied to other heterogeneous knowledge domains that require evidence-based conclusions.
Where Pith is reading between the lines
- The multi-agent verification pattern could be tested in medical or regulatory domains where source fidelity is equally critical.
- If the Auditor's cross-check proves reliable at scale, similar agent loops might reduce hallucination rates in other high-stakes RAG applications.
- Hierarchical graph construction may improve retrieval precision in any corpus that contains both concrete instances and general principles.
Load-bearing premise
The Auditor agent can detect invalid or incomplete evidence solely by cross-checking against source documents without missing context or introducing its own errors.
What would settle it
A set of legal queries containing subtle omissions or contradictions in the source documents where the Auditor consistently fails to flag the problem and the Adjudicator issues an incorrect judgment.
Figures









read the original abstract
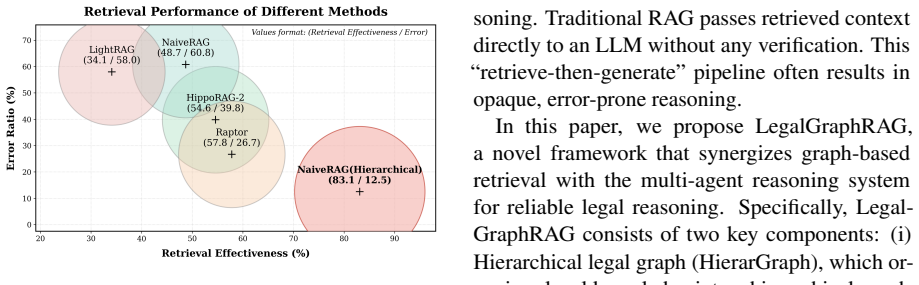
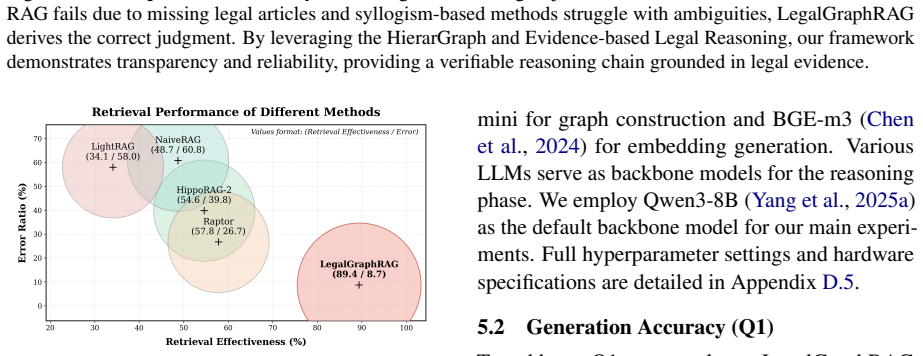
Graph-based Retrieval-Augmented Generation (GraphRAG) advances flat document retrieval by structuring knowledge as relational graphs, enabling more coherent and effective reasoning. However, applying it to specific domains like legal reasoning faces critical challenges. (i) Legal corpora are heterogeneous, containing multi-granular knowledge from cases, articles and interpretations. A flat knowledge graph cannot adequately differentiate between factual details, applied rules, and abstract principles, limiting accurate retrieval. (ii) Reliable legal judgment demands transparent, evidence-based reasoning. Traditional RAG passes retrieved context directly to an LLM without verification, resulting in opaque, error-prone reasoning. To this end, we propose LegalGraphRAG, a framework designed for reliable legal reasoning. Our approach introduces two core components: a hierarchical legal graph that hierarchically organizes legal sources to enable retrieval at appropriate abstraction levels, and a multi-agent system for reliable legal reasoning, where a Researcher retrieves candidate evidence, an Auditor rigorously verifies its validity against source documents, and an Adjudicator synthesizes the set of verified evidence to render a final judgment. Extensive experiments show that LegalGraphRAG achieves the state-of-the-art performance, outperforming existing GraphRAG baselines in accurate and trustworthy legal analysis. Our code, datasets and implementation details are available at https://github.com/XMUDeepLIT/LegalGraphRAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LegalGraphRAG, a framework for reliable legal reasoning that introduces a hierarchical legal graph to organize heterogeneous multi-granular legal knowledge (cases, articles, interpretations) at appropriate abstraction levels, combined with a multi-agent system (Researcher for candidate evidence retrieval, Auditor for verification against source documents, Adjudicator for synthesis and judgment). It claims this yields state-of-the-art performance in accurate and trustworthy legal analysis, outperforming existing GraphRAG baselines, with code, datasets, and implementation details released at a GitHub repository.
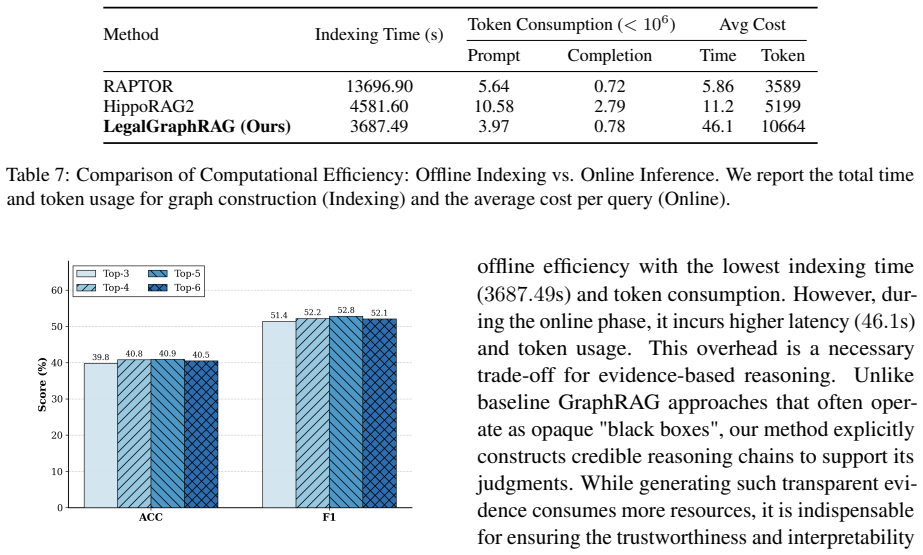
Significance. If the empirical claims hold under rigorous evaluation, the work addresses two substantive challenges in domain-specific RAG—handling legal knowledge heterogeneity via hierarchy and ensuring verifiable reasoning via multi-agent verification—which could improve reliability in high-stakes legal applications. The open release of code and datasets is a clear strength for reproducibility and follow-on work.
major comments (3)
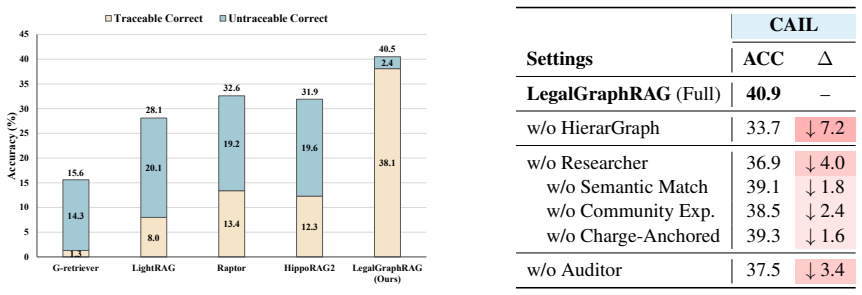
- [Abstract] Abstract: The central claim that LegalGraphRAG 'achieves the state-of-the-art performance, outperforming existing GraphRAG baselines in accurate and trustworthy legal analysis' is asserted without any metrics, baselines, dataset sizes, statistical tests, or error analysis. This is load-bearing for the empirical contribution and must be substantiated with concrete results from the experimental section.
- [Abstract] Abstract (multi-agent system description): The trustworthiness advantage over standard GraphRAG rests on the Auditor agent's ability to 'rigorously verify its validity against source documents' without missing context or introducing errors. No quantitative evaluation of Auditor precision/recall, no ablation removing the Auditor, and no error analysis on legal edge cases (ambiguous statutes, cross-referenced precedents) are referenced, undermining the 'transparent, evidence-based' claim.
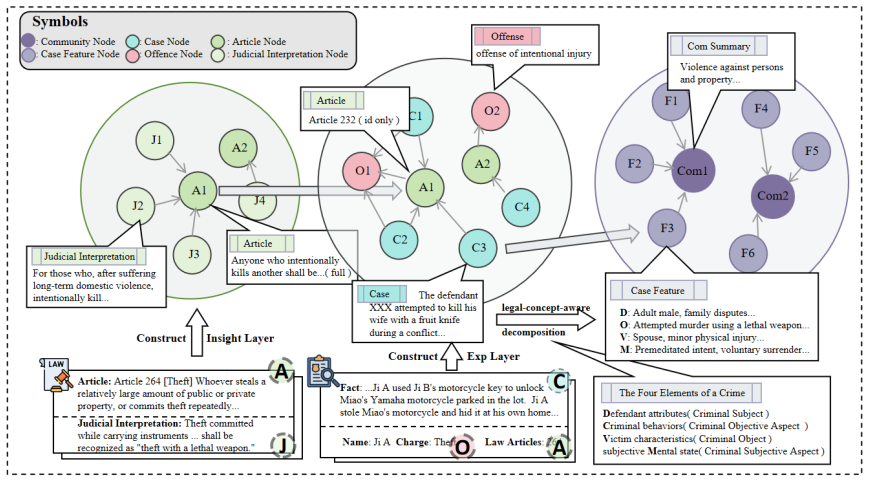
- [Abstract] Abstract (hierarchical legal graph): The claim that a flat knowledge graph 'cannot adequately differentiate between factual details, applied rules, and abstract principles' motivates the hierarchical graph, but no construction details, hierarchy levels, relation types, or retrieval mechanism at different abstraction levels are provided to support the differentiation benefit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract should be more self-contained and will revise it to include key quantitative results, component evaluations, and methodological details drawn from the full manuscript. Point-by-point responses are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that LegalGraphRAG 'achieves the state-of-the-art performance, outperforming existing GraphRAG baselines in accurate and trustworthy legal analysis' is asserted without any metrics, baselines, dataset sizes, statistical tests, or error analysis. This is load-bearing for the empirical contribution and must be substantiated with concrete results from the experimental section.
Authors: The Experiments section reports concrete metrics (accuracy, F1, trustworthiness scores), baseline comparisons (including multiple GraphRAG variants), dataset sizes, statistical significance tests, and error analysis on the legal benchmarks. We will revise the abstract to include representative numbers and baseline references to substantiate the claim. revision: yes
-
Referee: [Abstract] Abstract (multi-agent system description): The trustworthiness advantage over standard GraphRAG rests on the Auditor agent's ability to 'rigorously verify its validity against source documents' without missing context or introducing errors. No quantitative evaluation of Auditor precision/recall, no ablation removing the Auditor, and no error analysis on legal edge cases (ambiguous statutes, cross-referenced precedents) are referenced, undermining the 'transparent, evidence-based' claim.
Authors: The manuscript contains ablation studies isolating the Auditor, quantitative precision/recall results for verification, and error analysis on edge cases such as ambiguous statutes. We will add a brief reference to these findings in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract (hierarchical legal graph): The claim that a flat knowledge graph 'cannot adequately differentiate between factual details, applied rules, and abstract principles' motivates the hierarchical graph, but no construction details, hierarchy levels, relation types, or retrieval mechanism at different abstraction levels are provided to support the differentiation benefit.
Authors: Section 3 details the hierarchical graph construction (three abstraction levels, specific relation types between cases/articles/interpretations, and level-aware retrieval). We will incorporate a concise summary of these elements and their empirical benefit into the abstract. revision: yes
Circularity Check
No circularity: empirical engineering result with no derivation chain
full rationale
The paper proposes LegalGraphRAG as a multi-agent GraphRAG framework for legal reasoning and reports SOTA empirical performance on experiments. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The central claim rests on experimental outcomes rather than any reduction of outputs to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The Auditor verification step is an untested modeling assumption but does not constitute circularity under the defined patterns, as the paper does not claim to derive it from itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Legal corpora are heterogeneous, containing multi-granular knowledge from cases, articles and interpretations that a flat graph cannot differentiate.
- domain assumption Traditional RAG passes retrieved context directly to an LLM without verification, resulting in opaque, error-prone reasoning.
invented entities (2)
-
hierarchical legal graph
no independent evidence
-
multi-agent system (Researcher, Auditor, Adjudicator)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Improving language models by retrieving from trillions of tokens. InInternational conference on machine learning. PMLR. Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.0321...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Chatlaw: A Multi-Agent Legal Assistant based on a Role-Aligned Mixture-of-Experts Architecture
Chatlaw: A multi-agent collaborative legal assistant with knowledge graph enhanced mixture- of-experts large language model.arXiv preprint arXiv:2306.16092. Xin Dai, Buqiang Xu, Zhenghao Liu, Yukun Yan, Huiyuan Xie, Xiaoyuan Yi, Shuo Wang, and Ge Yu
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Legal δ: Enhancing legal reasoning in llms via reinforcement learning with chain-of-thought guided information gain.arXiv preprint arXiv:2508.12281. Hudson de Martim. 2025. Graph rag for legal norms: A hierarchical and temporal approach.arXiv preprint arXiv:2505.00039. Chenlong Deng, Kelong Mao, and Zhicheng Dou. 2024a. Learning interpretable legal case r...
-
[4]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Inlegalllama: Indian legal knowledge en- hanced large language model. InInternational Joint Conference on Artificial Intelligence. Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chen- hui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, and 1 others. 2024. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprin...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Antoine Louis, Gijs Van Dijck, and Gerasimos Spanakis
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Antoine Louis, Gijs van Dijck, and Gerasimos Spanakis
Finding the law: Enhancing statutory article retrieval via graph neural networks.arXiv preprint arXiv:2301.12847. Antoine Louis, Gijs van Dijck, and Gerasimos Spanakis
-
[7]
InProceedings of the AAAI Conference on Artificial Intelligence, volume 38
Interpretable long-form legal question answer- ing with retrieval-augmented large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38. Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. 2025. An empirical study of catas- trophic forgetting in large language models during continual fine-tuning.IEEE T...
-
[8]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv preprint arXiv:2402.07927. Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Exploring the Use of Text Classification in the Legal Domain
Raptor: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth International Conference on Learning Representations. Jeffrey A Segal. 1984. Predicting supreme court cases probabilistically: The search and seizure cases, 1962- 1981.American Political Science Review, 78(4):891– 900. Dong Shu, Haoran Zhao, Xukun Liu, David Demeter, Meng...
work page internal anchor Pith review Pith/arXiv arXiv 1984
-
[10]
Zhen Wan, Yating Zhang, Yexiang Wang, Fei Cheng, and Sadao Kurohashi
From louvain to leiden: guaranteeing well- connected communities.Scientific reports, 9(1):1– 12. Zhen Wan, Yating Zhang, Yexiang Wang, Fei Cheng, and Sadao Kurohashi. 2024. Reformulating domain adaptation of large language models as adapt-retrieve- revise: A case study on chinese legal domain. In Findings of the Association for Computational Lin- guistics...
2024
-
[11]
Xuran Wang, Xinguang Zhang, Vanessa Hoo, Zhouhang Shao, and Xuguang Zhang
Survey on factuality in large language models: Knowledge, retrieval and domain-specificity.arXiv preprint arXiv:2310.07521. Xuran Wang, Xinguang Zhang, Vanessa Hoo, Zhouhang Shao, and Xuguang Zhang. 2024. Legalreasoner: A multi-stage framework for legal judgment prediction via large language models and knowledge integration. IEEE Access. Jason Wei, Xuezhi...
-
[12]
CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction
Agentic self-evolution for large language mod- els: Taxonomy, techniques, and applications.Au- thorea Preprints. Chaojun Xiao, Haoxi Zhong, Zhipeng Guo, Cunchao Tu, Zhiyuan Liu, Maosong Sun, Yansong Feng, Xi- anpei Han, Zhen Hu, Heng Wang, and 1 others. 2018. Cail2018: A large-scale legal dataset for judgment prediction.arXiv preprint arXiv:1807.02478. Nu...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
the suspect intentionally caused serious injury
Disc-lawllm: Fine-tuning large language mod- els for intelligent legal services.arXiv preprint arXiv:2309.11325. Shengbin Yue, Shujun Liu, Yuxuan Zhou, Chenchen Shen, Siyuan Wang, Yao Xiao, Bingxuan Li, Yun Song, Xiaoyu Shen, Wei Chen, and 1 others. 2024. Lawllm: Intelligent legal system with legal reason- ing and verifiable retrieval. InInternational Con...
-
[14]
corresponds to Article 133
-
[15]
Researcher Auditor Adjudicator Figure 11: Qualitative analysis of a representative case regarding the crime ofDangerous Driving
corresponds to Cases1([Charges: Crime of Dangerous Driving] [Name: Wang]) ... Researcher Auditor Adjudicator Figure 11: Qualitative analysis of a representative case regarding the crime ofDangerous Driving. The visualization highlights the retrieval of evidence related to specific statutory conditions. 12 demonstrates the legal reasoning process for an Oc...
2023
-
[16]
Employee
andFuzi-Mingcha(Wu et al., 2023a) in- tegrate unsupervised legal texts with supervised fine-tuning to enhance domain understanding. Be- Query The defendant Zhang Mou entered into a labor contract with the Yaojiaba Tunnel Project Department of the Xiangjiaba Hydropower Station Project, originally under Sichuan Road and Bridge Construction Group Co., Ltd., ...
2016
-
[17]
corresponds to Article 271 Paragraph 1
-
[18]
large amount
corresponds to Cases1([Charges: job-related embezzlement] [Name: Xu 3Mou]) ... Article 272 Final: No Researcher Auditor Adjudicator Community Expansion Retrieval Semantic Match Retrieval Charge-Anchored Retrieval Figure 12: Qualitative analysis of a representative case regarding the crime ofOccupational Embezzlement. The example demonstrates the model’s r...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.