Test-Time Training with Next-Token Prediction
Pith reviewed 2026-06-26 13:50 UTC · model grok-4.3
The pith
Next-token prediction can supervise fast-weight updates at test time to improve long-context performance on released language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Test-Time Training with Next-Token Prediction supplies a stable supervision target for fast-weight adaptation by projecting the model's next-position contextual hidden state, and that this produces consistent gains over the released backbone on long-context benchmarks across multiple model families without additional training or architectural changes.
What carries the argument
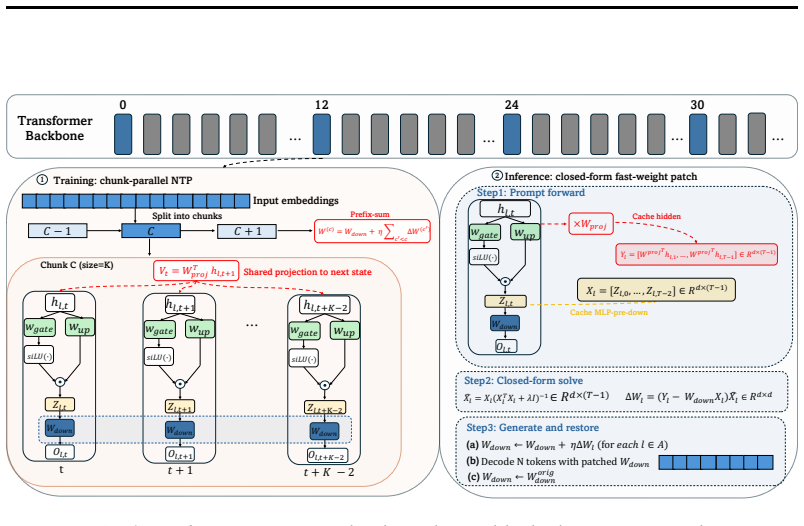
The central mechanism is the value target defined as a pointwise linear projection of the single next-position contextual hidden state, which directly follows the causal next-token prediction computation.
If this is right
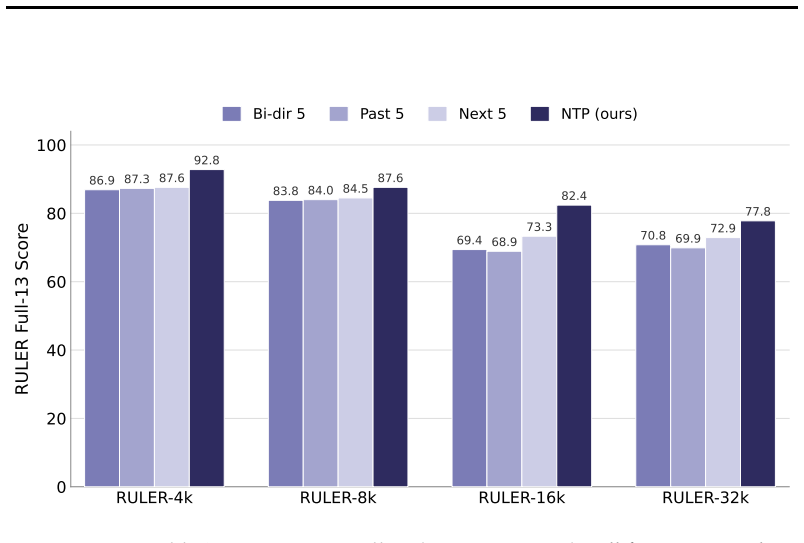
- TTT-NTP is the only tested method that consistently improves the released backbone on RULER Full-13 averaged over 4k-32k lengths across four models from three families.
- The same method produces gains on LongBench-v2 long-document QA for both Llama-3.1-8B and Mistral-7B-v0.3.
- The adaptation works as a drop-in replacement for pretrained checkpoints without requiring backbone redesign.
- Commonsense and knowledge performance remain preserved while long-context scores rise.
Where Pith is reading between the lines
- The success of reusing the next-token signal implies that other self-supervised pretraining objectives could similarly guide test-time adaptation.
- The method may reduce reliance on very long pretraining contexts if test-time updates can compensate for extended inputs.
- Similar projection-based targets could be tested on tasks beyond document QA, such as multi-hop reasoning over retrieved passages.
Load-bearing premise
A pointwise linear projection of the single next-position contextual hidden state must supply a stable and useful supervision target for fast-weight updates at test time without overfitting or instability.
What would settle it
Applying the method to a new long-context model family or benchmark length range and observing no consistent improvement or a performance drop over the base model would falsify the claim of reliable gains.
Figures
read the original abstract
Next-token prediction is the self-supervised signal that trains language models, and every observed prompt token provides the same signal at test time. We study whether this signal can define the inner-loop objective for test-time training (TTT) in pretrained long-context language models. Many TTT architectures require models to be trained with test-time adaptation in mind, limiting their direct applicability to released LLM checkpoints. While recent in-place TTT methods make fast-weight adaptation possible for pretrained LLMs without redesigning the backbone, they leave a central question unresolved: what should each test-time write store? Existing recipes train the fast weight to match a learned local value proxy but they are not directly tied to the self-supervised next-token prediction signal. We introduce Test-Time Training with Next-Token Prediction (TTT-NTP), a drop-in fast-weight adaptation method for pretrained LLMs that instead supervises updates using the model's own next contextual hidden state. This makes each local write follow the same causal computation that supports next-token prediction: the value target is a pointwise linear projection of a single next-position contextual state. On RULER Full-13 (averaged over 4k, 8k, 16k, and 32k context lengths), TTT-NTP is the only method that consistently improves the released backbone across four models spanning three families and a 0.6--8B size range: Llama-3.1-8B (+3.9), Mistral-7B-v0.3 (+3.0), and the Qwen3 series (Qwen3-4B +4.1, Qwen3-0.6B +2.9). On the real-world LongBench-v2 long-document QA benchmark, TTT-NTP improves over the base model on both Llama-3.1-8B (+5.6) and Mistral-7B-v0.3 (+3.7), while preserving commonsense and knowledge performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TTT-NTP, a test-time training method for pretrained long-context LLMs that supervises fast-weight updates using a pointwise linear projection of the model's own next-position contextual hidden state, aligning each write with the causal next-token prediction objective from pretraining. It reports that this drop-in adaptation improves the base model on RULER Full-13 (averaged over 4k-32k lengths) across four models from three families (Llama-3.1-8B +3.9, Mistral-7B-v0.3 +3.0, Qwen3-4B +4.1, Qwen3-0.6B +2.9) and on LongBench-v2 long-document QA (+5.6 and +3.7 on two models), while preserving commonsense performance.
Significance. If the central result holds, the work supplies a simple, backbone-compatible TTT recipe that reuses the pretraining signal without requiring model redesign or learned value proxies, with demonstrated gains on long-context retrieval and QA tasks across model scales and families. The multi-model, multi-benchmark evaluation and explicit comparison to prior in-place TTT methods are strengths.
major comments (3)
- [Abstract] Abstract: The headline gains on RULER Full-13 and LongBench-v2 are reported as single point estimates without variance, number of runs, or statistical tests; this is load-bearing for the claim that TTT-NTP is 'the only method that consistently improves' the backbone, as the abstract supplies no controls for prompt-specific effects or optimizer stochasticity.
- [Abstract] Abstract: The value target is defined as 'a pointwise linear projection of a single next-position contextual state,' but neither the explicit form of the projection matrix nor whether it contains learned parameters is stated; this directly affects the claim that each write 'follows the same causal computation' as pretraining and leaves the circularity concern (self-derived target) unaddressed in the reported results.
- [Abstract] Abstract: No information is given on inner-loop step count, learning rate schedule, regularization, or update variance across the 4k-32k context lengths; without this, it is impossible to verify that observed improvements arise from NTP alignment rather than generic auxiliary-loss effects or prompt-specific overfitting.
minor comments (1)
- [Abstract] The abstract refers to 'RULER Full-13' and 'LongBench-v2' without citing the exact task subsets or versions used; adding these references would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and commit to revisions that improve the abstract's clarity and completeness without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline gains on RULER Full-13 and LongBench-v2 are reported as single point estimates without variance, number of runs, or statistical tests; this is load-bearing for the claim that TTT-NTP is 'the only method that consistently improves' the backbone, as the abstract supplies no controls for prompt-specific effects or optimizer stochasticity.
Authors: We agree the abstract would be strengthened by reporting variance or noting the number of runs. The gains are shown to be consistent across four models from three families on two benchmarks, which underpins the 'consistently improves' phrasing. We will revise the abstract to include a brief qualifier on the single-run nature of the reported numbers and add variance information to the main results tables. revision: yes
-
Referee: [Abstract] Abstract: The value target is defined as 'a pointwise linear projection of a single next-position contextual state,' but neither the explicit form of the projection matrix nor whether it contains learned parameters is stated; this directly affects the claim that each write 'follows the same causal computation' as pretraining and leaves the circularity concern (self-derived target) unaddressed in the reported results.
Authors: The projection is a fixed, parameter-free linear transformation (a simple scaling and shift derived from the hidden-state dimensionality) applied to the next-position state; no parameters are learned during the inner loop. This construction directly reuses the causal next-position computation from pretraining, so the target is not circular. We will state the explicit form of the projection in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: No information is given on inner-loop step count, learning rate schedule, regularization, or update variance across the 4k-32k context lengths; without this, it is impossible to verify that observed improvements arise from NTP alignment rather than generic auxiliary-loss effects or prompt-specific overfitting.
Authors: We will add a concise statement of the inner-loop hyperparameters (step count, learning rate, and regularization) to the abstract and ensure the methods section already contains the full schedule and variance analysis across lengths. The paper's direct comparisons to prior in-place TTT baselines help isolate the contribution of the NTP objective. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper defines TTT-NTP by setting the fast-weight target to a pointwise linear projection of the model's own next-position hidden state, explicitly to align with pretraining's causal next-token computation. This is a methodological design choice rather than a derivation in which a claimed result reduces to its inputs by construction. The headline results (consistent gains on RULER Full-13 and LongBench-v2 across four models) are presented as empirical measurements on held-out benchmarks, not as predictions forced by the target definition itself. No equations, self-citations, uniqueness theorems, or fitted parameters renamed as predictions appear in the supplied text. The approach is self-supervised by nature, but the performance delta is not tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Next-token prediction supplies a suitable self-supervised signal for test-time fast-weight adaptation
Reference graph
Works this paper leans on
-
[1]
URL https: //arxiv.org/abs/2412.15204. Rachit Bansal, Aston Zhang, Rishabh Tiwari, Lovish Madaan, Sai Surya Duvvuri, Devvrit Khatri, David Brandfonbrener, David Alvarez-Melis, Prajjwal Bhargava, Mihir Sanjay Kale, and Samy Jelassi. Let’s (not) just put things in context: Test-time training for long-context llms,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni
URLhttps://arxiv.org/abs/2512.13898. Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. Advances in Neural Information Processing Systems, 38:113506–113543,
-
[3]
Longformer: The Long-Document Transformer
URLhttps://arxiv.org/abs/2004.05150. Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pp. 7432–7439,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending con- text window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Longlora: Efficient fine-tuning of long-context large language models
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. Longlora: Efficient fine-tuning of long-context large language models. InInternational Conference on Learning Representations, volume 2024, pp. 8220–8238,
2024
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
URL https://arxiv.org/ abs/2205.14135. Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. Longrope: Extending llm context window beyond 2 million tokens.arXiv preprint arXiv:2402.13753,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Guhao Feng, Shengjie Luo, Kai Hua, Ge Zhang, Di He, Wenhao Huang, and Tianle Cai. In-place test-time training.arXiv preprint arXiv:2604.06169,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Data Engineering for Scaling Language Models to 128K Context.arXiv Preprint arXiv:2402.10171, 2024
Yao Fu, Rameswar Panda, Xinyao Niu, Xiang Yue, Hannaneh Hajishirzi, Yoon Kim, and Hao Peng. Data engineering for scaling language models to 128k context.arXiv preprint arXiv:2402.10171,
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[14]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URLhttps://openreview.net/forum?id=a68SUt6zFt
ISSN 2835-8856. URLhttps://openreview.net/forum?id=a68SUt6zFt. Featured Certification. Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Leon Derczynski, et al. Rwkv: Reinventing rnns for the transformer era. InFindings of the association for computational linguistics: EMNLP 2023...
2023
-
[17]
Yarn: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models. InInternational Conference on Learning Representations, volume 2024, pp. 31932–31951,
2024
-
[18]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation.arXiv preprint arXiv:2108.12409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Hopfield Networks is All You Need
Hubert Ramsauer, Bernhard Sch ¨afl, Johannes Lehner, Philipp Seidl, Michael Widrich, Thomas Adler, Lukas Gruber, Markus Holzleitner, Milena Pavlovi´c, Geir Kjetil Sandve, et al. Hopfield networks is all you need.arXiv preprint arXiv:2008.02217,
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[20]
URLhttps://arxiv.org/abs/2102.11174. J ¨urgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139,
-
[21]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states.arXiv preprint arXiv:2407.04620,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Retentive Network: A Successor to Transformer for Large Language Models
15 Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models. arXiv preprint arXiv:2307.08621,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675,
Arnuv Tandon, Karan Dalal, Xinhao Li, Daniel Koceja, Marcel Rød, Sam Buchanan, Xiaolong Wang, Jure Leskovec, Sanmi Koyejo, Tatsunori Hashimoto, et al. End-to-end test-time training for long context.arXiv preprint arXiv:2512.23675,
-
[24]
Shaobo Wang, Xuan Ouyang, Tianyi Xu, Yuzheng Hu, Jialin Liu, Guo Chen, Tianyu Zhang, Junhao Zheng, Kexin Yang, Xingzhang Ren, Dayiheng Liu, and Linfeng Zhang. Opus: Towards efficient and principled data selection in large language model pre-training in every iteration.arXiv preprint arXiv:2602.05400,
-
[25]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length.Advances in neural informatio...
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. InInternational Conference on Learning Representations, volume 2025, pp. 29687–29707, 2025b. Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. B...
2025
-
[27]
Big Bird: Transformers for Longer Sequences
URLhttps://arxiv.org/abs/2007.14062. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pp. 4791–4800,
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[28]
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T Freeman, and Hao Tan. Test-time training done right.arXiv preprint arXiv:2505.23884,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.