Heterogeneous Tactile Transformer
Pith reviewed 2026-06-30 05:50 UTC · model grok-4.3
The pith
A transformer with sensor-specific encoders learns shared tactile representations from paired data across four different sensors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
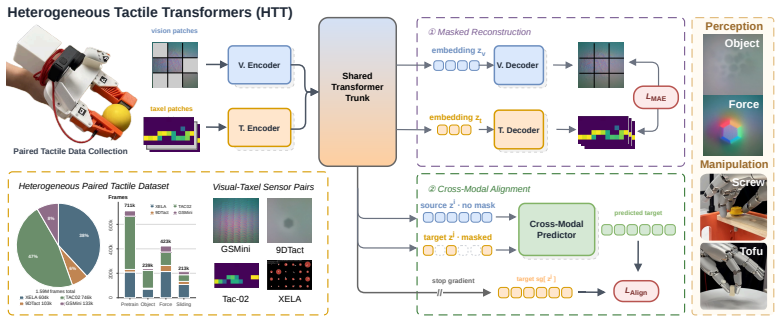
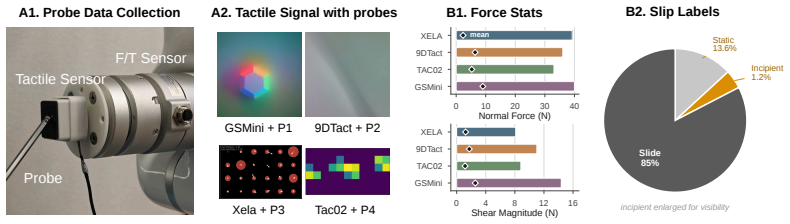
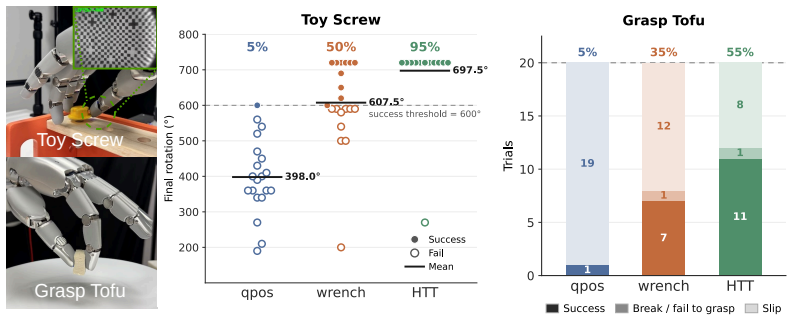
The Heterogeneous Tactile Transformer consists of sensor-specific encoders and a shared transformer trunk. It is pretrained with per-modality masked reconstruction together with cross-modal alignment between paired sensors on the Heterogeneous Paired Tactile dataset of 1.6M synchronized frames across four vision- and array-based sensors. Across distinct tactile perception and real-world manipulation tasks, this produces transferable representations that adapt to new tasks and previously unseen sensors.
What carries the argument
Sensor-specific encoders plus a shared transformer trunk, trained by per-modality masked reconstruction and cross-modal alignment on paired tactile frames.
If this is right
- Representations transfer to new tactile perception and real-world manipulation tasks.
- The model adapts to previously unseen sensors.
- Pretraining on the HPT dataset supports learning contact-rich manipulation policies from data collected on varied sensors.
- Sensor-specific encoders allow the shared trunk to process inputs from heterogeneous hardware without direct compatibility.
Where Pith is reading between the lines
- The same pretraining approach could let researchers pool tactile data collected on different hardware in different labs without requiring matched sensor pairs for every new experiment.
- Extending the method to align more than two sensors simultaneously might increase robustness when many sensor types are available.
- The framework suggests a route to reduce the data-collection burden when deploying tactile sensing on new robot hardware.
Load-bearing premise
The combination of per-modality masked reconstruction and cross-modal alignment on the HPT paired dataset produces representations that genuinely generalize beyond the four sensors and tasks used in pretraining and evaluation.
What would settle it
Evaluating the pretrained model on a fifth tactile sensor absent from the HPT dataset and measuring whether its performance on a held-out manipulation task equals or exceeds a model trained from scratch on data from that fifth sensor.
Figures

read the original abstract
Tactile sensors are inherently heterogeneous: a model trained on one sensor cannot be directly used on another, which limits learning contact-rich manipulation policies from diverse tactile data at scale. To bridge this gap, we propose the Heterogeneous Tactile Transformer (HTT), a framework that learns shared tactile representations across heterogeneous sensors. HTT consists of sensor-specific encoders and a shared transformer trunk, and is pretrained with per-modality masked reconstruction together with cross-modal alignment between paired sensors. Pretraining uses our novel Heterogeneous Paired Tactile (HPT) dataset, containing 1.6M synchronized paired frames across four vision- and array-based tactile sensors. Across distinct tactile perception and real-world manipulation tasks, HTT is shown to learn transferable representations that adapt to new tasks and previously unseen sensors. Dataset, code, and model checkpoints will be released upon publication at https://jxbi1010.github.io/htt-gh-page/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Heterogeneous Tactile Transformer (HTT), consisting of sensor-specific encoders and a shared transformer trunk. It is pretrained via per-modality masked reconstruction and cross-modal alignment losses on the authors' new Heterogeneous Paired Tactile (HPT) dataset of 1.6M synchronized paired frames collected from four vision- and array-based tactile sensors. The central claim is that the resulting representations transfer successfully to distinct tactile perception tasks and real-world manipulation tasks, including adaptation to new tasks and previously unseen sensors.
Significance. If the transfer results are quantitatively supported, the work addresses a core practical barrier in tactile robotics: sensor heterogeneity that prevents pooling data across devices. Enabling cross-sensor transfer could allow larger-scale pretraining and more general policies. The planned public release of the HPT dataset, code, and checkpoints would further increase the contribution's value for reproducibility and follow-on research.
major comments (1)
- [Abstract] Abstract: the central claim that HTT 'is shown to learn transferable representations that adapt to new tasks and previously unseen sensors' is asserted without any quantitative metrics, baselines, ablation studies, or error analysis. This absence makes it impossible to evaluate whether the generalization result holds or is affected by post-hoc experimental choices.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify the presentation of our results. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that HTT 'is shown to learn transferable representations that adapt to new tasks and previously unseen sensors' is asserted without any quantitative metrics, baselines, ablation studies, or error analysis. This absence makes it impossible to evaluate whether the generalization result holds or is affected by post-hoc experimental choices.
Authors: We agree that the abstract, as a concise summary, would be strengthened by including key quantitative metrics to support the central claim. The full manuscript already contains the requested quantitative results, baselines, ablation studies, and error analyses in the experimental sections. To directly address this point, we will revise the abstract to incorporate specific performance numbers on transfer to new tasks and unseen sensors while retaining its brevity. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a standard self-supervised pretraining pipeline (per-modality masked reconstruction + cross-modal alignment) on a new paired dataset (HPT), followed by empirical evaluation on downstream tasks. No equations, uniqueness theorems, or self-citations are presented that reduce claimed generalization performance to quantities defined by construction from the same fitted parameters or inputs. The central claim is an empirical demonstration of transfer, not a derivation that collapses to its own training objective.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors (Basel, Switzerland), 17, 2017. URLhttps://api. semanticscholar.org/CorpusID:3474913
2017
-
[2]
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, D. Jayaraman, and R. Calandra. Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation. IEEE Robotics and Automation Letters, 5(3):3838–3845, July 2020. ISSN 2377-3774. doi:10.1109/lr...
-
[3]
C. Lin, H. Zhang, J. Xu, L. Wu, and H. Xu. 9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation.IEEE Robotics and Automation Letters, 9(2):923–930, 2023
2023
-
[4]
T. Tomo, M. Regoli, A. Schmitz, L. Natale, H. Kristanto, S. Somlor, L. Jamone, G. Metta, and S. Sugano. A new silicone structure for uskin - a soft, distributed, digital 3-axis skin sensor and its integration on the humanoid robot icub.IEEE Robotics and Automation Letters, PP: 1–1, 03 2018. doi:10.1109/LRA.2018.2812915
-
[5]
Bhirangi, T
R. Bhirangi, T. Hellebrekers, C. Majidi, and A. Gupta. Reskin:versatile, replaceable, lasting tactile skins. InCoRL, 2021
2021
-
[6]
TAC-02 — Robotic Finger Dev Kit.https://www.tacniq.ai/ tac-02-robotic-finger-dev-kit, n.d
TacnIQ.ai. TAC-02 — Robotic Finger Dev Kit.https://www.tacniq.ai/ tac-02-robotic-finger-dev-kit, n.d. Accessed: 2025-12-10
2025
-
[7]
Huang, Y
B. Huang, Y . Wang, X. Yang, Y . Luo, and Y . Li. 3d vitac:learning fine-grained manipulation with visuo-tactile sensing. InProceedings of Robotics: Conference on Robot Learning(CoRL), 2024
2024
-
[8]
Higuera, A
C. Higuera, A. Sharma, C. K. Bodduluri, T. Fan, P. Lancaster, M. Kalakrishnan, M. Kaess, B. Boots, M. Lambeta, T. Wu, and M. Mukadam. Sparsh: Self-supervised touch representations for vision-based tactile sensing. In8th Annual Conference on Robot Learning,
-
[9]
URLhttps://openreview.net/forum?id=xYJn2e1uu8
-
[10]
J. Zhao, Y . Ma, L. Wang, and E. Adelson. Transferable tactile transformers for representation learning across diverse sensors and tasks. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=KXsropnmNI
2024
-
[11]
Gupta, Y
H. Gupta, Y . Mo, S. Jin, and W. Yuan. Sensor-invariant tactile representation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[12]
R. Feng, J. Hu, W. Xia, A. Shen, Y . Sun, B. Fang, D. Hu, et al. Anytouch: Learning unified static-dynamic representation across multiple visuo-tactile sensors. InThe Thirteenth International Conference on Learning Representations
-
[13]
F. Yang, C. Feng, Z. Chen, H. Park, D. Wang, Y . Dou, Z. Zeng, X. Chen, R. Gangopadhyay, A. Owens, et al. Binding touch to everything: Learning unified multimodal tactile representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26340–26353, 2024
2024
-
[14]
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick. Masked autoencoders are scalable vision learners. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15979–15988, 2022. doi:10.1109/CVPR52688.2022.01553. 9
-
[15]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[16]
S. Yu, L. Kelvin, and H. Soh. Demonstrating the Octopi-1.5 Visual-Tactile-Language Model. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi:10. 15607/RSS.2025.XXI.058
2025
-
[17]
Q. Li, O. Kroemer, Z. Su, F. F. Veiga, M. Kaboli, and H. J. Ritter. A review of tactile information: Perception and action through touch.IEEE Transactions on Robotics, 36(6): 1619–1634, 2020
2020
-
[18]
S. Luo, J. Bimbo, R. Dahiya, and H. Liu. Robotic tactile perception of object properties: A review.Mechatronics, 48:54–67, 2017
2017
-
[19]
T. Li, Y . Yan, C. Yu, J. An, Y . Wang, and G. Chen. A comprehensive review of robot intelligent grasping based on tactile perception.Robotics and Computer-Integrated Manufacturing, 90: 102792, 2024
2024
-
[20]
GelSight Mini Tactile Sensor.https://www.gelsight.com/ gelsightmini/, 2023
GelSight Inc. GelSight Mini Tactile Sensor.https://www.gelsight.com/ gelsightmini/, 2023. Accessed: 2025-04-29
2023
-
[21]
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, D. Jayaraman, and R. Calandra. Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation. IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020. doi:10.1109/LRA.2020. 2977257
-
[22]
M. Lambeta, T. Wu, A. Sengul, V . R. Most, N. Black, K. Sawyer, R. Mercado, H. Qi, A. Sohn, B. Taylor, N. Tydingco, G. Kammerer, D. Stroud, J. Khatha, K. Jenkins, K. Most, N. Stein, R. Chavira, T. Craven-Bartle, E. Sanchez, Y . Ding, J. Malik, and R. Calandra. Digitizing touch with an artificial multimodal fingertip, 2024. URLhttps://arxiv.org/abs/2411.02479
-
[23]
J. Xu, W. Chen, H. Qian, D. Wu, and R. Chen. Thintact: Thin vision-based tactile sensor by lensless imaging.IEEE Transactions on Robotics, 2025
2025
- [24]
-
[25]
H. Khamis, R. Albero, M. Salerno, A. Shah Idil, and A. Loizou. Papillarray: An incipient slip sensor for dexterous robotic or prosthetic manipulation – design and prototype validation. Sensors and Actuators A: Physical, 270, 12 2017. doi:10.1016/j.sna.2017.12.058
- [26]
-
[27]
Suresh, Z
S. Suresh, Z. Si, S. Anderson, M. Kaess, and M. Mukadam. MidasTouch: Monte-Carlo inference over distributions across sliding touch. InProc. Conf. on Robot Learning, CoRL, Auckland, NZ, Dec. 2022
2022
-
[28]
S. Yu, K. Lin, A. Xiao, J. Duan, and H. Soh. Octopi: Object property reasoning with large tactile-language models. InProceedings of Robotics: Science and Systems, 2024
2024
-
[29]
R. Feng, Y . Zhou, S. Mei, D. Zhou, P. Wang, S. Cui, B. Fang, G. Yao, and D. Hu. Anytouch 2: General optical tactile representation learning for dynamic tactile perception. InThe Fourteenth International Conference on Learning Representations, 2026. 10
2026
-
[30]
Z. Si, G. Zhang, Q. Ben, B. Romero, Z. Xian, C. Liu, and C. Gan. DIFFTACTILE: A physics-based differentiable tactile simulator for contact-rich robotic manipulation. In The Twelfth International Conference on Learning Representations, 2024. URLhttps: //openreview.net/forum?id=eJHnSg783t
2024
-
[31]
R. Gao, Z. Si, Y .-Y . Chang, S. Clarke, J. Bohg, L. Fei-Fei, W. Yuan, and J. Wu. Objectfolder 2.0: A multisensory object dataset for sim2real transfer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10598–10608, 2022
2022
-
[32]
Z. Xu, R. Uppuluri, X. Zhang, C. Fitch, P. G. Crandall, W. Shou, D. Wang, and Y . She. Unit: Data efficient tactile representation with generalization to unseen objects.IEEE Robotics and Automation Letters, 2025
2025
- [33]
-
[34]
L. Fu, G. Datta, H. Huang, W. C.-H. Panitch, J. Drake, J. Ortiz, M. Mukadam, M. Lambeta, R. Calandra, and K. Goldberg. A touch, vision, and language dataset for multimodal alignment. InForty-first International Conference on Machine Learning, 2024. URLhttps: //openreview.net/forum?id=tFEOOH9eH0
2024
- [35]
-
[36]
C. Higuera, A. Sharma, T. Fan, C. K. Bodduluri, B. Boots, M. Kaess, M. Lambeta, T. Wu, Z. Liu, F. R. Hogan, et al. Tactile beyond pixels: Multisensory touch representations for robot manipulation.arXiv preprint arXiv:2506.14754, 2025
- [37]
-
[38]
R. Gao, T. Taunyazov, Z. Lin, and Y . Wu. Supervised autoencoder joint learning on heterogeneous tactile sensory data: Improving material classification performance. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10907–10913. IEEE, 2020
2020
-
[39]
B. Zandonati, R. Wang, R. Gao, and Y . Wu. Investigating vision foundational models for tactile representation learning.ArXiv, abs/2305.00596, 2023. URLhttps://api. semanticscholar.org/CorpusID:258426712
-
[40]
Grella, A
F. Grella, A. Albini, G. Cannata, and P. Maiolino. Touch-to-touch translation-learning the mapping between heterogeneous tactile sensing technologies. In2025 IEEE 21st International Conference on Automation Science and Engineering (CASE), pages 1998–2004. IEEE, 2025
1998
- [41]
-
[42]
E. S. PAGE. Continuous inspection schemes.Biometrika, 41(1-2):100–115, 06 1954. ISSN 0006-3444. doi:10.1093/biomet/41.1-2.100. URLhttps://doi.org/10.1093/biomet/ 41.1-2.100
-
[43]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021. 11
2021
-
[44]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi:10.15607/RSS.2023.XIX.016
-
[45]
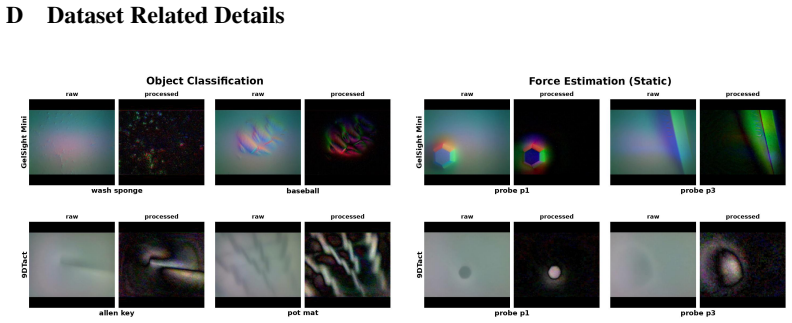
Q. K. Luu, P. Zhou, Z. Xu, Z. Zhang, Q. Qiu, and Y . She. Manifeel: Benchmarking and understanding visuotactile manipulation policy learning.arXiv preprint arXiv:2505.18472, 2025. 12 A Appendix Figure 4: The four heterogeneous tactile sensors used in HPT pretraining, each mounted in the UMI gripper shell. Left to right: GelSight Mini and 9DTact (optical-b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.