TriMotion: Modality-Agnostic Camera Control for Video Generation
Pith reviewed 2026-06-26 18:09 UTC · model grok-4.3
The pith
TriMotion maps video, pose, and text camera descriptions into a shared motion embedding space for consistent video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
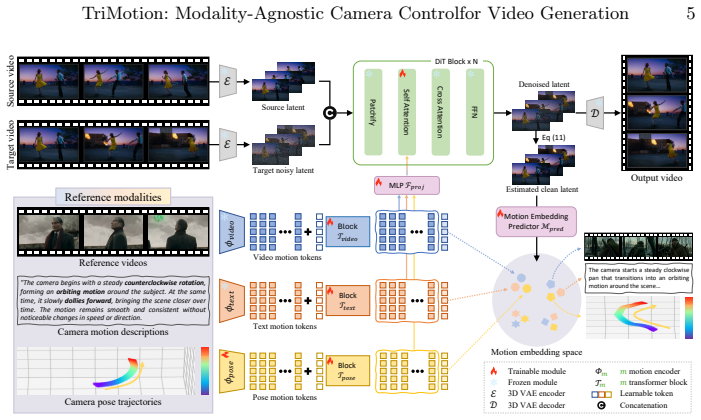
TriMotion projects video, pose, and text inputs that describe the same camera trajectory into one shared motion embedding space. The Motion Triplet Dataset supplies the paired supervision by extending multi-camera data with geometry-grounded text. A latent motion consistency objective then forces the generated video's latent features to respect the target trajectory, enabling accurate control from any of the three modalities.
What carries the argument
Shared motion embedding space that aligns video, pose, and text modalities, trained with a latent motion consistency objective on the Motion Triplet Dataset.
If this is right
- One trained model replaces separate controllers for each input modality.
- Embeddings from different modalities can be chained to compose longer motion sequences.
- The space supports interpolation between motion descriptions given in text and in pose form.
- Trajectory adherence is checked in latent space, avoiding repeated pixel decoding during training.
Where Pith is reading between the lines
- The embedding could enable cross-modal retrieval of motion clips by nearest-neighbor search in the shared space.
- Similar triplet construction might apply to controlling object motion or scene layout if aligned data can be assembled.
- Text prompts could serve as a lightweight interface for adjusting camera paths in an already-generated video.
Load-bearing premise
Reliable synchronized triplets of video, pose, and text for identical camera trajectories can be constructed at scale from existing multi-camera recordings.
What would settle it
Feed the model the same camera trajectory once via text and once via pose sequence, then measure whether the output videos exhibit statistically different camera paths when reconstructed in 3D.
Figures

read the original abstract
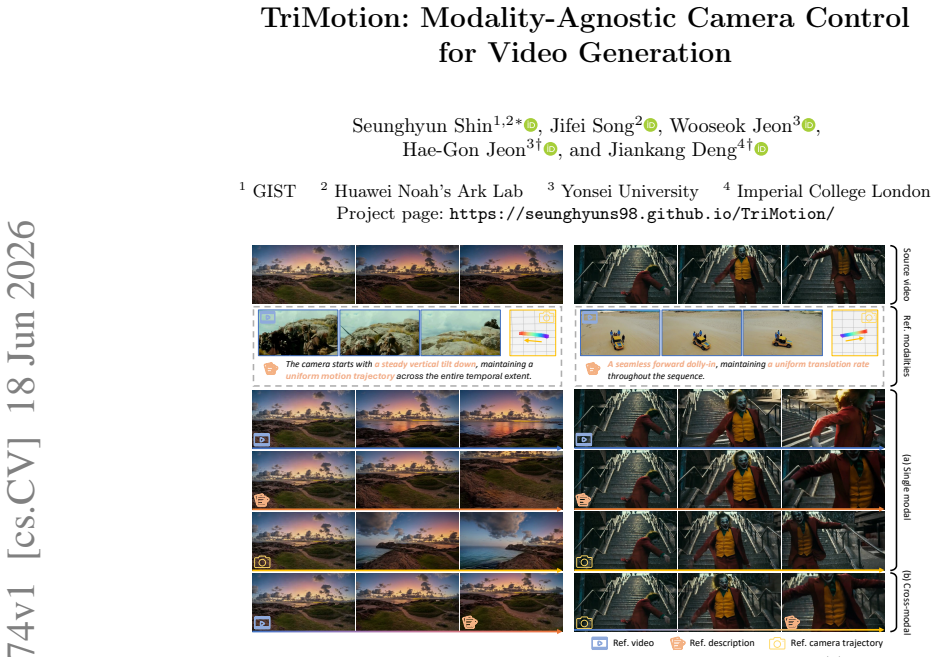
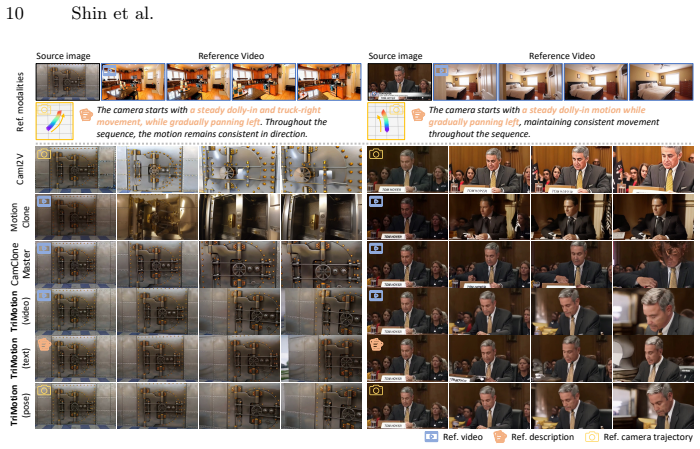
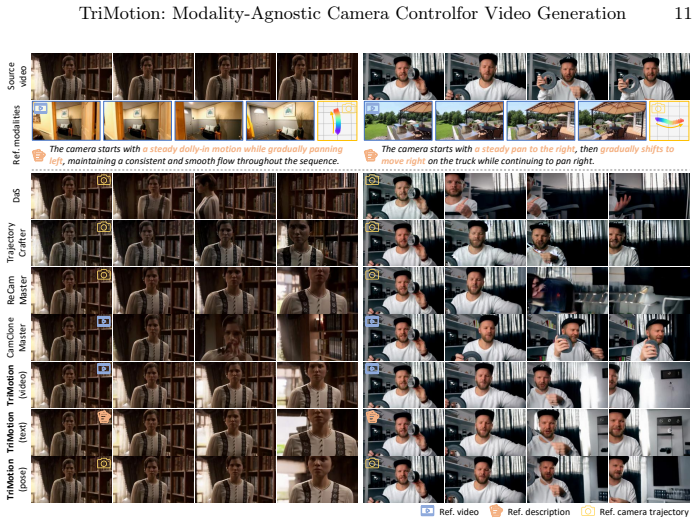
Camera motion control is essential for directing viewpoint changes in generative systems. However, existing methods typically condition the generation process on a single specific modality, such as explicit pose trajectories or reference videos, limiting their ability to support heterogeneous user inputs. To address this limitation, we present TriMotion, a modality-agnostic framework for camera-controlled video generation that maps video, pose, and text inputs, describing the same camera trajectory into a shared motion embedding space. Learning such a space requires synchronized supervision across modalities. Therefore, we build the Motion Triplet Dataset by extending a Multi-Cam Video Dataset with geometry-grounded motion descriptions derived from camera extrinsics. We further introduce a latent motion consistency objective that leverages the motion embedding space to encourage the generated video to follow the target camera trajectory directly in latent space, avoiding the cost of pixel-space decoding. Extensive experiments show that TriMotion generates high-quality videos that accurately follow the target camera trajectories across all three modalities. Beyond standard generation, the shared motion embedding space also enables flexible applications such as sequential motion composition and cross-modal motion interpolation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TriMotion, a modality-agnostic framework for camera-controlled video generation that learns a shared motion embedding space mapping video, pose, and text inputs describing the same camera trajectory. It constructs the Motion Triplet Dataset by extending a Multi-Cam Video Dataset with geometry-grounded motion descriptions derived from camera extrinsics, and proposes a latent motion consistency objective to enforce trajectory adherence directly in latent space without pixel decoding. The central claim is that this produces high-quality videos accurately following target trajectories across all three modalities, while also enabling applications such as sequential motion composition and cross-modal motion interpolation.
Significance. If the experimental validation holds with quantitative support, the shared embedding approach could meaningfully advance controllable video generation by allowing heterogeneous user inputs without modality-specific conditioning, and the dataset construction plus latent consistency loss represent concrete technical contributions to multi-modal motion alignment.
major comments (1)
- [Abstract] The abstract states that 'extensive experiments show that TriMotion generates high-quality videos that accurately follow the target camera trajectories across all three modalities,' yet supplies no quantitative metrics, baselines, ablation studies, or error analysis. This absence is load-bearing for the central claim of accurate cross-modal trajectory following and prevents assessment of whether the shared embedding and latent consistency objective deliver the asserted performance.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for identifying an important presentational issue in the abstract. We address the comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] The abstract states that 'extensive experiments show that TriMotion generates high-quality videos that accurately follow the target camera trajectories across all three modalities,' yet supplies no quantitative metrics, baselines, ablation studies, or error analysis. This absence is load-bearing for the central claim of accurate cross-modal trajectory following and prevents assessment of whether the shared embedding and latent consistency objective deliver the asserted performance.
Authors: We agree that the abstract, as currently written, does not include any numerical results and therefore cannot by itself substantiate the performance claims. The full manuscript does contain quantitative evaluations (trajectory error metrics, user studies, baseline comparisons, and ablations) in the Experiments section; however, these details are not referenced or summarized in the abstract. We will revise the abstract to include a concise statement of the key quantitative findings (e.g., average trajectory adherence scores across modalities and relative improvements over baselines) so that the central claim is supported at the level of the abstract itself. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and description present a standard pipeline of dataset extension (adding geometry-derived text from existing extrinsics) followed by training a shared embedding and a latent consistency loss. No equations, predictions, or uniqueness claims are supplied that reduce by construction to fitted parameters or self-referential definitions. The central result is an empirical claim about generation quality, supported by experiments on the constructed data rather than a closed derivation. This qualifies as self-contained against external benchmarks with no load-bearing self-citation or ansatz smuggling visible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
McGraw-Hill New York, 2008
David Bordwell, Kristin Thompson, and Jeff Smith.Film art: An introduction, volume 7. McGraw-Hill New York, 2008
2008
-
[2]
Columbia University Press, 2002
Robin Wood.Hitchcock’s films revisited. Columbia University Press, 2002
2002
-
[3]
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
Pith/arXiv arXiv 2022
-
[4]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[5]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InCVPR, pages 22563–22575, 2023
2023
-
[6]
Lumiere: A space-time diffusion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[7]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Dynamicrafter: Animating open-domain images with video diffusion priors. InEuropean Conference on Computer Vision, pages 399–417. Springer, 2024
2024
-
[8]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[9]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[10]
Motion prior distillation in time reversal sampling for generative inbetweening
Wooseok Jeon, Seunghyun Shin, Dongmin Shin, and Hae-Gon Jeon. Motion prior distillation in time reversal sampling for generative inbetweening. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[11]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[12]
Cameractrl: Enabling camera control for text-to-video generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation. arXiv preprint arXiv:2404.02101, 2024. 16 Shin et al
Pith/arXiv arXiv 2024
-
[13]
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models.arXiv preprint arXiv:2503.10592, 2025
arXiv 2025
-
[14]
Cami2v: Camera-controlled image-to-video diffusion model.arXiv preprint arXiv:2410.15957, 2024
Guangcong Zheng, Teng Li, Rui Jiang, Yehao Lu, Tao Wu, and Xi Li. Cami2v: Camera-controlled image-to-video diffusion model.arXiv preprint arXiv:2410.15957, 2024
arXiv 2024
-
[15]
Recammaster: Camera- controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera- controlled generative rendering from a single video. InICCV, 2025
2025
-
[16]
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, et al. Vd3d: Taming large video diffusion transformers for 3d camera control.arXiv preprint arXiv:2407.12781, 2024
arXiv 2024
-
[17]
Ac3d: Analyzing and improving 3d camera control in video diffusion transformers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22875–22889, 2025
2025
-
[18]
Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 100–111, 2025
2025
-
[19]
Diffusion as shader: 3d-aware video diffusion for versatile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as shader: 3d-aware video diffusion for versatile video generation control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–12, 2025
2025
-
[20]
Generative camera dolly: Extreme monocular dynamic novel view synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl Vondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[21]
Jacobs, Yael Pritch, Inbar Mosseri, Mike Zheng Shou, Neal Wadhwa, and Nataniel Ruiz
David Junhao Zhang, Roni Paiss, Shiran Zada, Nikhil Karnad, David E. Jacobs, Yael Pritch, Inbar Mosseri, Mike Zheng Shou, Neal Wadhwa, and Nataniel Ruiz. Recapture: Generative video camera controls for user-provided videos using masked video fine-tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[22]
JunyoungSeo,JisangHan,JaewooJung,SiyoonJin,JoungBinLee,TakuyaNarihira, Kazumi Fukuda, Takashi Shibuya, Donghoon Ahn, Shoukang Hu, Seungryong Kim, and Yuki Mitsufuji. Vid-camedit: Video camera trajectory editing with generative rendering from estimated geometry.arXiv preprint arXiv:2506.13697, 2025
arXiv 2025
-
[23]
Reangle-a-video: 4d video genera- tion as video-to-video translation
Hyeonho Jeong, Suhyeon Lee, and Jong Chul Ye. Reangle-a-video: 4d video genera- tion as video-to-video translation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[24]
Camclonemaster: Enabling reference-based camera control for video generation
Yawen Luo, Xiaoyu Shi, Jianhong Bai, Menghan Xia, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. Camclonemaster: Enabling reference-based camera control for video generation. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–10, 2025
2025
-
[25]
Teng Hu, Jiangning Zhang, Ran Yi, Yating Wang, Hongrui Huang, Jieyu Weng, Yabiao Wang, and Lizhuang Ma. Motionmaster: Training-free camera motion transfer for video generation.arXiv preprint arXiv:2404.15789, 2024. TriMotion: Modality-Agnostic Camera Controlfor Video Generation 17
arXiv 2024
-
[26]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7310–7320, 2024
2024
-
[27]
Wanquan Feng, Jiawei Liu, Pengqi Tu, Tianhao Qi, Mingzhen Sun, Tianxiang Ma, Songtao Zhao, Siyu Zhou, and Qian He. I2vcontrol-camera: Precise video camera control with adjustable motion strength.arXiv preprint arXiv:2411.06525, 2024
arXiv 2024
-
[28]
Dejia Xu, Weili Nie, Chao Liu, Sifei Liu, Jan Kautz, Zhangyang Wang, and Arash Vahdat. Camco: Camera-controllable 3d-consistent image-to-video generation.arXiv preprint arXiv:2406.02509, 2024
Pith/arXiv arXiv 2024
-
[29]
Teng Li, Guangcong Zheng, Rui Jiang, Shuigen Zhan, Tao Wu, Yehao Lu, Yining Lin, and Xi Li. Realcam-i2v: Real-world image-to-video generation with interactive complex camera control.arXiv preprint arXiv:2502.10059, 2025
arXiv 2025
-
[30]
Pengyang Ling, Jiazi Bu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Tong Wu, Huaian Chen, Jiaqi Wang, and Yi Jin. Motionclone: Training-free motion cloning for controllable video generation.arXiv preprint arXiv:2406.05338, 2024
arXiv 2024
-
[31]
Gs-dit: Advancing video generation with dynamic 3d gaussian fields through efficient dense 3d point tracking
Weikang Bian, Zhaoyang Huang, Xiaoyu Shi, Yijin Li, Fu-Yun Wang, and Hongsheng Li. Gs-dit: Advancing video generation with dynamic 3d gaussian fields through efficient dense 3d point tracking. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21717–21727, 2025
2025
-
[32]
Trajectory attention for fine-grained video motion control.arXiv preprint arXiv:2411.19324, 2024
Zeqi Xiao, Wenqi Ouyang, Yifan Zhou, Shuai Yang, Lei Yang, Jianlou Si, and Xingang Pan. Trajectory attention for fine-grained video motion control.arXiv preprint arXiv:2411.19324, 2024
arXiv 2024
-
[33]
Unreal Engine 5.https://www.unrealengine.com/en-US/unreal- engine-5
Epic Games. Unreal Engine 5.https://www.unrealengine.com/en-US/unreal- engine-5. Accessed: 2026-02-28
2026
-
[34]
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models.arXiv preprint arXiv:2310.01728, 2023
Pith/arXiv arXiv 2023
-
[35]
Evaluating llms’ ability to understand numerical time series for text generation
Mizuki Arai, Tatsuya Ishigaki, Masayuki Kawarada, Yusuke Miyao, Hiroya Taka- mura, and Ichiro Kobayashi. Evaluating llms’ ability to understand numerical time series for text generation. InProceedings of the 18th International Natural Language Generation Conference, pages 232–248, 2025
2025
-
[36]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[37]
Scal- ing rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scal- ing rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[38]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
Pith/arXiv arXiv 2022
-
[39]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[40]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 18 Shin et al
2020
-
[41]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[42]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rup- precht, and David Novotny. Vggt: Visual geometry grounded transformer. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[43]
Sharut Gupta, Joshua Robinson, Derek Lim, Soledad Villar, and Stefanie Jegelka. Structuring representation geometry with rotationally equivariant contrastive learn- ing.arXiv preprint arXiv:2306.13924, 2023
arXiv 2023
-
[44]
Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content
Qiuheng Wang, Yukai Shi, Jiarong Ou, Rui Chen, Ke Lin, Jiahao Wang, Boyuan Jiang, Haotian Yang, Mingwu Zheng, Xin Tao, et al. Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8428–8437, 2025
2025
-
[45]
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018
Pith/arXiv arXiv 2018
-
[46]
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
Pith/arXiv arXiv 2018
-
[47]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[48]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[49]
Megasam: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10486–10496, 2025
2025
-
[50]
Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency
Yiming Xie, Chun-Han Yao, Vikram Voleti, Huaizu Jiang, and Varun Jampani. Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency. arXiv preprint arXiv:2407.17470, 2024
arXiv 2024
-
[51]
Amazon mechanical turk: A research tool for organizations and information systems scholars
Kevin Crowston. Amazon mechanical turk: A research tool for organizations and information systems scholars. InShaping the Future of ICT Research. Methods and Approaches: IFIP WG 8.2, Working Conference, Tampa, FL, USA, December 13-14, 2012. Proceedings, 2012
2012
-
[52]
Kinetic typography diffusion model
Seonmi Park, Inhwan Bae, Seunghyun Shin, and Hae-Gon Jeon. Kinetic typography diffusion model. InEuropean Conference on Computer Vision, pages 166–185. Springer, 2024
2024
-
[53]
Chanhui Lee, Seunghyun Shin, Donggyu Choi, Hae-gon Jeon, and Jeany Son. Universal image immunization against diffusion-based image editing via semantic injection.arXiv preprint arXiv:2602.14679, 2026
arXiv 2026
-
[54]
Wooseok Jeon, Seungho Park, Seunghyun Shin, Sangeyl Lee, Hyeonho Jeong, and Hae-Gon Jeon. Rebalancing reference frame dominance to improve motion in image-to-video models.arXiv preprint arXiv:2605.19398, 2026. TriMotion: Modality-Agnostic Camera Controlfor Video Generation 19
Pith/arXiv arXiv 2026
-
[55]
Video color grading via look-up table generation
Seunghyun Shin, Dongmin Shin, Jisu Shin, Hae-Gon Jeon, and Joon-Young Lee. Video color grading via look-up table generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19141–19152, 2025
2025
-
[56]
Close imitation of expert retouching for black-and-white photography
Seunghyun Shin, Jisu Shin, Jihwan Bae, Inwook Shim, and Hae-Gon Jeon. Close imitation of expert retouching for black-and-white photography. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25037–25046, June 2024
2024
-
[57]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
Pith/arXiv arXiv 2025
-
[58]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017
2017
-
[59]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
2016
-
[60]
Musiq: Multi- scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi- scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
2021
-
[61]
aesthetic-predictor
LAION-AI. aesthetic-predictor. https://github.com/LAION- AI/aesthetic- predictor, 2022
2022
-
[62]
Amt: All-pairs multi-field transforms for efficient frame interpolation
Zhen Li, Zuo-Liang Zhu, Ling-Hao Han, Qibin Hou, Chun-Le Guo, and Ming- Ming Cheng. Amt: All-pairs multi-field transforms for efficient frame interpolation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9801–9810, 2023
2023
-
[63]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021. 20 Shin et al. A Additional Details of the Motion Triplet Dataset A.1 Pose Preprocessing an...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.