MOSAIC: Orchestrating Collaborative Knowledge Tracing with Hierarchical Semantic Alignment
Pith reviewed 2026-06-30 09:19 UTC · model grok-4.3
The pith
MOSAIC uses a frozen LLM for semantic embeddings and cross-granularity consistency to improve collaborative knowledge tracing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MOSAIC establishes that orchestrating LLM-driven semantic alignment with sequential modeling and a cross-granularity consistency objective captures collaborative signals and hierarchical knowledge dependencies more effectively than prior methods, resulting in state-of-the-art performance with AUC improvements of up to 3.4% and accuracy gains of up to 2.5% across benchmarks, plus an AUC of 0.862 on the MOOC dataset.
What carries the argument
The MOSAIC framework, which uses a frozen LLM to produce dynamic embeddings and hierarchical prediction prompts together with a cross-granularity consistency objective that regularizes mastery across levels.
If this is right
- Achieves AUC improvements of up to 3.4% and accuracy gains of up to 2.5% across all benchmarks.
- Exhibits superior robustness in collaboration-rich environments and long-sequence scenarios.
- Delivers both high predictive precision and semantically grounded interpretability.
- Models mastery estimation jointly at concept, topic-cluster, and global proficiency levels.
Where Pith is reading between the lines
- Similar frozen-LLM alignment could be tested on other sequential prediction tasks that involve sparse hierarchical data.
- The consistency objective might reduce sensitivity to missing interactions by propagating information across granularity levels.
- Replacing the LLM with lighter embedding models could be checked to see if the performance edge persists at lower compute cost.
Load-bearing premise
That a frozen LLM will reliably produce dynamic embeddings capturing collaborative signals and that the consistency objective will improve rather than distort mastery estimates at each granularity level.
What would settle it
Removing the cross-granularity consistency objective and measuring whether AUC and accuracy drop below the full MOSAIC version, or testing on a dataset with randomized peer interactions and checking whether the reported gains disappear.
Figures
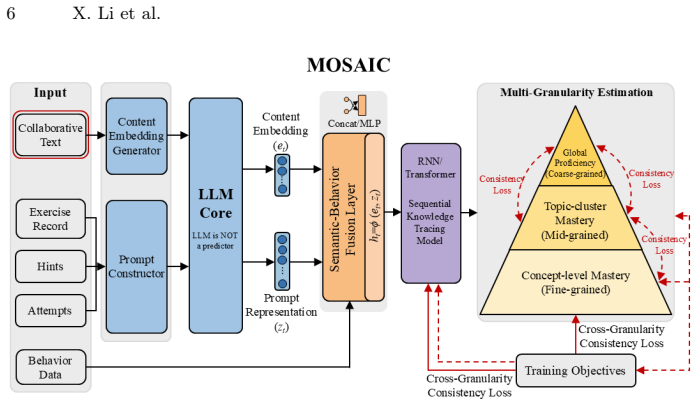
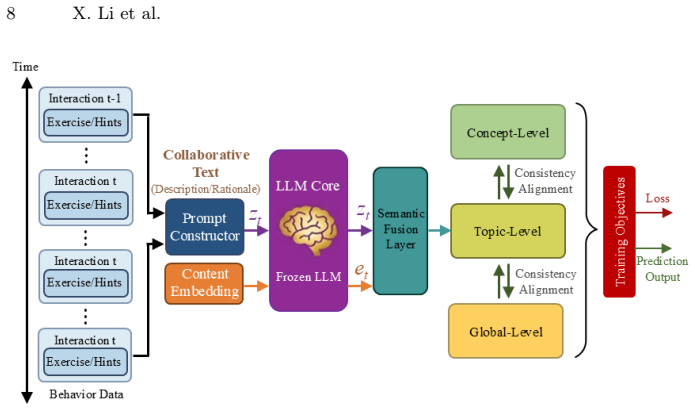
read the original abstract
Knowledge Tracing (KT) is important for personalized education but traditionally suffers from two key limitations: a reliance on shallow ID-based representations that neglect semantic depth and a restriction to single-granularity mastery estimation that overlooks hierarchical knowledge dependencies. To address these challenges, we propose MOSAIC (Multi-granularity Online Semantic AI for Collaborative Knowledge), a novel framework that orchestrates LLM-driven semantic alignment with sequential modeling. Unlike methods that use LLMs solely as predictors, MOSAIC leverages a frozen LLM to generate dynamic, context-aware embeddings and hierarchical prediction prompts, explicitly capturing collaborative signals and peer interactions. Furthermore, we introduce a cross-granularity consistency objective that jointly regularizes mastery estimation across concept, topic-cluster, and global proficiency levels. Extensive experiments on ASSISTments, EdNet, and a newly collected large-scale MOOC dataset demonstrate that MOSAIC establishes new state-of-the-art results. Specifically, our method achieves AUC improvements of up to 3.4\% and Accuracy gains of up to 2.5 \% across all benchmarks. Notably, MOSAIC exhibits superior robustness in collaboration-rich environments and long-sequence scenarios (AUC 0.862 on MOOC), offering both high predictive precision and semantically grounded interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MOSAIC, a KT framework that uses a frozen LLM to generate dynamic context-aware embeddings via hierarchical prediction prompts (capturing collaborative peer signals) and introduces a cross-granularity consistency objective to regularize mastery estimates across concept, topic-cluster, and global levels. It claims new SOTA results with AUC gains up to 3.4% and accuracy gains up to 2.5% on ASSISTments, EdNet, and a new MOOC dataset, plus robustness in collaboration-rich and long-sequence settings (e.g., AUC 0.862 on MOOC).
Significance. If the empirical claims hold under rigorous validation, the work could meaningfully advance KT by moving beyond ID-based representations to semantically grounded, hierarchical modeling that incorporates collaboration; the combination of frozen-LLM embeddings with multi-level consistency is a plausible direction for improved interpretability and robustness.
major comments (3)
- [Abstract] Abstract: performance numbers (AUC improvements of up to 3.4%, accuracy gains of up to 2.5%, MOOC AUC 0.862) are stated without any experimental protocol, baseline implementations, data splits, hyperparameter details, statistical tests, or ablation results, making it impossible to determine whether the data support the SOTA claim.
- [Method (LLM embedding and hierarchical prompts)] Embedding generation and prompt design (method section): the central assumption that a frozen general-purpose LLM, when prompted with interaction data, will produce dynamic embeddings that meaningfully encode collaborative peer-interaction signals is neither derived nor empirically verified; no analysis shows how these embeddings differ from static or non-collaborative baselines.
- [Method (cross-granularity consistency loss)] Cross-granularity consistency objective (method section): no derivation or ablation demonstrates why enforcing consistency across concept/topic/global levels improves (rather than averages out) per-level mastery estimates; this is load-bearing for the hierarchical claim yet rests on an untested assumption.
minor comments (2)
- [Title and Abstract] The acronym expansion for MOSAIC differs slightly between the title (Hierarchical Semantic Alignment) and abstract (Multi-granularity Online Semantic AI for Collaborative Knowledge); standardize the expansion.
- [Method] Notation for the three granularity levels (concept, topic-cluster, global) should be introduced once with consistent symbols rather than repeated descriptive phrases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and methodological sections. We address each major comment point-by-point below, providing clarifications from the manuscript and indicating revisions where they strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance numbers (AUC improvements of up to 3.4%, accuracy gains of up to 2.5%, MOOC AUC 0.862) are stated without any experimental protocol, baseline implementations, data splits, hyperparameter details, statistical tests, or ablation results, making it impossible to determine whether the data support the SOTA claim.
Authors: The abstract prioritizes brevity, but the full manuscript details the experimental protocol in Section 4 (datasets: ASSISTments, EdNet, new MOOC with 70/15/15 splits; baselines including DKVMN, AKT, etc.; hyperparameters via grid search; paired t-tests for significance at p<0.05) and ablations in Section 5. We agree the abstract should better signal this support. We will revise it to note the datasets, that results are averaged over 5 runs with statistical tests, and that full protocols, baselines, and ablations appear in Sections 4-5. revision: yes
-
Referee: [Method (LLM embedding and hierarchical prompts)] Embedding generation and prompt design (method section): the central assumption that a frozen general-purpose LLM, when prompted with interaction data, will produce dynamic embeddings that meaningfully encode collaborative peer-interaction signals is neither derived nor empirically verified; no analysis shows how these embeddings differ from static or non-collaborative baselines.
Authors: Section 3.2 derives the hierarchical prediction prompts by explicitly concatenating peer interaction sequences into the input to the frozen LLM, enabling context-aware embeddings that encode collaborative signals (as opposed to isolated student histories). Appendix C provides qualitative embedding visualizations and nearest-neighbor examples illustrating peer influence. We acknowledge that a direct quantitative comparison (e.g., embedding similarity metrics or performance deltas) against static/non-collaborative variants would strengthen verification. We will add this ablation to Section 5. revision: yes
-
Referee: [Method (cross-granularity consistency loss)] Cross-granularity consistency objective (method section): no derivation or ablation demonstrates why enforcing consistency across concept/topic/global levels improves (rather than averages out) per-level mastery estimates; this is load-bearing for the hierarchical claim yet rests on an untested assumption.
Authors: Section 3.3 derives the cross-granularity consistency loss via KL divergence between mastery distributions at concept, topic-cluster, and global levels, motivated by the hierarchical dependency structure of knowledge (finer-grained estimates should be consistent with coarser ones to avoid contradiction). Main results in Table 2 show gains, but we agree an isolated ablation is needed to confirm it enhances rather than averages estimates. We will add this ablation (removing the loss and reporting per-granularity AUC drops) to Section 5, plus analysis of per-level improvements. revision: yes
Circularity Check
No derivation chain present; empirical model proposal only
full rationale
The paper proposes an empirical KT framework (MOSAIC) that uses a frozen LLM for embeddings plus a cross-granularity consistency objective, then reports benchmark AUC/Accuracy numbers. No first-principles derivation, uniqueness theorem, or mathematical reduction is claimed or exhibited in the provided text. The central claims are experimental performance results rather than any step that reduces by construction to fitted inputs or self-citations. No equations, ansatzes, or load-bearing self-citations appear that match the enumerated circularity patterns, so the work is self-contained against external benchmarks with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ACM Computing Surveys55(11), 224:1–224:37 (2023)
Abdelrahman, G., Wang, Q., Nunes, B.P.: Knowledge tracing: A survey. ACM Computing Surveys55(11), 224:1–224:37 (2023). https://doi.org/10.1145/3569576
-
[2]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: GPT-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
arXiv preprint arXiv:2403.07279 (2024)
Bai, Y., Zhao, J., Wei, T., Cai, Q., He, L.: A survey of explainable knowledge tracing. arXiv preprint arXiv:2403.07279 (2024)
-
[4]
arXiv preprint arXiv:2601.00796 (2026)
Chan, J., Zhao, Z., Liu, Y.L.: Adagar: Adaptive gabor representation for dynamic scene reconstruction. arXiv preprint arXiv:2601.00796 (2026)
-
[5]
In: International Conference on Learning Representations (2026) 14 X
Chen, W., Guo, X., Li, S., Zhong, Y., Zhang, Z., Zhuang, F., Liu, H., Zhang, L., Ye, G., He, H.: Learning structure-semantic evolution trajectories for graph domain adaptation. In: International Conference on Learning Representations (2026) 14 X. Li et al
2026
-
[6]
Chen, Y., Qian, P., Wang, S., Zhang, S., Xu, H., Lin, S., Wei, X.: Does rag know when retrieval is wrong? diagnosing context compliance under knowledge conflict (2026), https://arxiv.org/abs/2605.14473
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
In: Proceedings of the ACM International Conference on Multimedia
Chen, Z., Hu, Y., Li, Z., Fu, Z., Wen, H., Guan, W.: Hud: Hierarchical uncertainty- aware disambiguation network for composed video retrieval. In: Proceedings of the ACM International Conference on Multimedia. pp. 6143–6152 (2025)
2025
-
[8]
Cheng, Z., Lai, L., Liu, Y.: Resolving the robustness-precision trade- off in financial rag through hybrid document-routed retrieval (2026), https://arxiv.org/abs/2603.26815
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Cheng, Z., Lai, L., Liu, Y., Cheng, K., Qi, X.: Enhancing financial report question-answering: A retrieval-augmented generation system with reranking anal- ysis (2026), https://arxiv.org/abs/2603.16877
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
User Modeling and User-Adapted Interaction4(4), 253–278 (1994)
Corbett, A.T., Anderson, J.R.: Knowledge tracing: Modeling the acquisition of procedural knowledge. User Modeling and User-Adapted Interaction4(4), 253–278 (1994)
1994
-
[11]
China Economic Review82, 102063 (2023)
Dai, Y., Chen, M., Zuo, Z.: Neighbors in space: Satellite imagery and chinese b- share discount. China Economic Review82, 102063 (2023)
2023
-
[12]
Urban Lifeline4(1), 9 (2026)
Deng, M., Lu, S., Shi, J., Zhang, W.: Adaptive traffic signal control optimization using a novel road partition and multi-channel state representation method. Urban Lifeline4(1), 9 (2026)
2026
-
[13]
IEEE Trans- actions on Intelligent Transportation Systems (2026)
Du, R., Li, Z., Zhang, J., Gao, K., Hu, L.: Point cloud mapping and loop closure detection using superpoint semantic graph for autonomous driving. IEEE Trans- actions on Intelligent Transportation Systems (2026)
2026
-
[14]
IEEE Transactions on Intelligent Transportation Systems26(10), 14968–14983 (2025)
Duan, W., Gao, Z., He, J., Xian, J.: Bayesian critique-tune-based reinforcement learning with adaptive pressure for multi-intersection traffic signal control. IEEE Transactions on Intelligent Transportation Systems26(10), 14968–14983 (2025). https://doi.org/10.1109/TITS.2025.3581858
-
[15]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Duan, W., Yu, Y., He, J., Shi, Y.: Adaptive context length optimization with low- frequency truncation for multi-agent reinforcement learning. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[16]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Feng, W., Ju, L., Wang, L., Song, K., Zhao, X., Ge, Z.: Unsupervised domain adaptation for medical image segmentation by selective entropy constraints and adaptive semantic alignment. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 623–631 (2023)
2023
-
[17]
IEEE Transactions on Medical Imaging (2026)
Feng, W., Wang, B., Wang, Z., Zhou, S., Ge, Z.: Leveraging image-text pairs for generalized category discovery in medical image classification. IEEE Transactions on Medical Imaging (2026)
2026
-
[18]
In: The Fourteenth International Conference on Learning Representations (2026)
Feng, W., Zhou, S., Jiang, Y., Ge, Z.: Prism: Progressive robust learning for open- world continual category discovery. In: The Fourteenth International Conference on Learning Representations (2026)
2026
-
[19]
In: Proceedings of the 33rd ACM International Conference on Information and Knowledge Manage- ment
Fu, L., Guan, H., Du, K., Lin, J., Xia, W., Zhang, W., Tang, R., Wang, Y., Yu, Y.: SINKT: A structure-aware inductive knowledge trac- ing model with large language model. In: Proceedings of the 33rd ACM International Conference on Information and Knowledge Manage- ment. pp. 632–642. ACM (2024). https://doi.org/10.1145/3627673.3679760, https://doi.org/10.1...
-
[20]
Fu, Z., Hu, Y., Yang, Q., Zhang, S., Chen, Z., Li, Z.: Air-know: Arbiter- calibrated knowledge-internalizing robust network for composed image retrieval (2026), https://arxiv.org/abs/2604.19386 MOSAIC 15
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Ghosh, A., Heffernan, N.T., Lan, A.S.: Context-aware attentive knowl- edge tracing. In: Proceedings of the 26th ACM SIGKDD Inter- national Conference on Knowledge Discovery & Data Mining. pp. 2330–2339. ACM (2020). https://doi.org/10.1145/3394486.3403282, https://doi.org/10.1145/3394486.3403282
-
[22]
arXiv preprint arXiv:2511.23402 , year =
Guo, J., Luo, X., Zheng, J., Wang, Y., Chang, K.W., Wang, W., Liu, J.: Quantized- tinyllava: A new multimodal foundation model enables efficient split learning. In: arXiv preprint arXiv:2511.23402 (2025)
-
[23]
Han, X., Xiao, Y., Zhang, Z., Zheng, M.: Interpretable factor decom- position for decision intelligence in large-scale financial markets: Evi- dence from china’s a-share market. arXiv preprint arXiv:2606.12843 (2026). https://doi.org/10.48550/arXiv.2606.12843, https://arxiv.org/abs/2606.12843
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.12843 2026
-
[24]
He, Y., Zhang, C., Chen, F., Cao, J.: Cinematte: Background matting for virtual production and beyond (2026), https://arxiv.org/abs/2605.18328
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
In: Mul- tiMedia Modeling: 30th International Conference, MMM 2024, Amsterdam, The Netherlands, January 29–February 2, 2024, Proceedings, Part III
He, Y., Zhang, W., Deng, J., Cong, Y.: Prior-knowledge-free video frame inter- polation with bidirectional regularized implicit neural representations. In: Mul- tiMedia Modeling: 30th International Conference, MMM 2024, Amsterdam, The Netherlands, January 29–February 2, 2024, Proceedings, Part III. pp. 112–126. Springer-Verlag, Berlin, Heidelberg (2024)
2024
-
[26]
UniShield: An Adaptive Multi-Agent Framework for Unified Forgery Image Detection and Localization
Huang, Q., Xu, Z., Zhang, X., Zhang, J.: Unishield: An adaptive multi-agent framework for unified forgery image detection and localization. arXiv preprint arXiv:2510.03161 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP)
Huang, Q., Chen, Z., Li, Z., Wang, C., Song, X., Hu, Y., Nie, L.: Median: Adap- tive intermediate-grained aggregation network for composed image retrieval. In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP). pp. 1–5. IEEE (2025)
2025
-
[28]
Ji, F., Yang, J., Song, Z., Gao, L., Liang, J., Chen, Z., Zhang, J., Chen, X.: Servim- age:Animagegenerationandeditingbenchmarkfromreal-worldcommercialimag- ing services (2026), https://arxiv.org/abs/2604.24023
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
arXiv preprint arXiv:2508.09241 (2025)
Ji, F., Yang, J., Song, Z., Wang, Y., Cui, Z., Li, Y., Jiang, Q., Fang, M., Chen, X.: Finestate-bench: A comprehensive benchmark for fine-grained state control in gui agents. arXiv preprint arXiv:2508.09241 (2025)
-
[30]
Advanced Engineering Informatics62, 102774 (2024)
Jia, N., Huang, W., Ding, C., Wang, J., Zhu, Z.: Physics-informed unsupervised domain adaptation framework for cross-machine bearing fault diagnosis. Advanced Engineering Informatics62, 102774 (2024)
2024
-
[31]
SCRIBE: Structured Mid-Level Supervision for Tool-Using Language Models
Jiang, Y., Ferraro, F.: Scribe: Structured mid-level supervision for tool-using lan- guage models. arXiv preprint arXiv:2601.03555 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Jiang, Y., Li, D., Ferraro, F.: Drp: Distilled reasoning pruning with skill-aware step decomposition for efficient large reasoning models (2026), https://arxiv.org/abs/2505.13975
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Knowledge-Based Systems343, 115998 (2026)
Jiao, R., Zhang, J., Li, C., Hu, L.: Large-kernel spatially parallel feature fusion for monocular 3d perception in autonomous driving. Knowledge-Based Systems343, 115998 (2026)
2026
-
[34]
Learning and Individual Differences103, 102274 (2023)
Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., Gasser, U., Groh, G., Günnemann, S., Hüllermeier, E., et al.: ChatGPT for good? on opportunities and challenges of large language models for education. Learning and Individual Differences103, 102274 (2023)
2023
-
[35]
Knowledge- Based Systems284, 111300 (2024) 16 X
Ke, F., Wang, W., Tan, W., Du, L., Jin, Y., Huang, Y., Yin, H.: HiTSKT: A hierarchical transformer model for session-aware knowledge tracing. Knowledge- Based Systems284, 111300 (2024) 16 X. Li et al
2024
-
[36]
In: 2026 9th International Symposium on Big Data and Applied Statistics (ISBDAS)
Lai, L., Cheng, Z., Cheng, K., Qi, X.: Do transformers always win? an empirical study of semantic embeddings for short-text e-commerce reviews. In: 2026 9th International Symposium on Big Data and Applied Statistics (ISBDAS). pp. 525– 529 (2026). https://doi.org/10.1109/ISBDAS69350.2026.11484350
-
[37]
arXiv preprint arXiv:2406.02893 (2024)
Lee, U., Bae, J., Kim, D., Lee, S., Park, J., Ahn, T., Lee, G., Stratton, D., Kim, H.: Language model can do knowledge tracing: Simple but effec- tive method to integrate language model and knowledge tracing task. arXiv preprint arXiv:2406.02893 (2024). https://doi.org/10.48550/arXiv.2406.02893, https://arxiv.org/abs/2406.02893
-
[38]
Lee, U., Park, Y., Kim, Y., Choi, S., Kim, H.: MonaCoBERT: Monotonic attention basedConvBERTforknowledgetracing.In:InternationalConferenceonIntelligent Tutoring Systems. pp. 107–123. Springer (2024)
2024
-
[39]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 13035–13053 (2023)
Li, H., Zhao, J., Bazin, J.C., Kim, P., Joo, K., Zhao, Z., Liu, Y.H.: Hong kong world: Leveraging structural regularity for line-based slam. IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 13035–13053 (2023)
2023
-
[40]
In: Pro- ceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing
Li, R., Wu, S., Wang, J., Zhang, W.: CIKT: A collaborative and iter- ative knowledge tracing framework with large language models. In: Pro- ceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing. pp. 19321–19334. Association for Computational Linguis- tics, Suzhou, China (2025). https://doi.org/10.18653/v1/2025.emnlp-main.97...
-
[41]
Li, W., Su, X., Cao, Y., Xu, H., Xia, X., You, S., Chen, Y., Xu, C.: Sentinel-vla: A metacognitive vla model with active status monitoring for dynamic reasoning and error recovery (2026), https://arxiv.org/abs/2605.01191
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Li, W., Su, X., Niu, D., Cao, Y., Xu, H., Qu, Z., Fan, L., You, S., Xu, C.: Vla-attc: Adaptive test-time compute for vla models with relative action critic model (2026), https://arxiv.org/abs/2605.01194
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Li, W., Su, X., Wu, J., Yang, F., Liu, Y., Chen, Y., You, S., Xu, C.: Identify, isolate, and purge: Mitigating hallucinations in lvlms via self-evolving distillation. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 6791–6800 (2025)
2025
-
[44]
Reflect-Guard: Enhancing LLM Safeguards against Adversarial Prompts via Logical Self-Reflection
Lin, L., You, J., Li, Y., Lin, L.S., Wang, Y., Zhang, Z., Zheng, M.: Reflect-guard: Enhancing llm safeguards against adversarial prompts via logical self-reflection. arXiv preprint arXiv:2605.24834 (2026). https://doi.org/10.48550/arXiv.2605.24834, https://doi.org/10.48550/arXiv.2605.24834
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.24834 2026
-
[45]
In: Proceedings of the ACM Web Conference 2024
Liu, G., Zhan, H., Kim, J.J.: Question difficulty consistent knowl- edge tracing. In: Proceedings of the ACM Web Conference 2024. pp. 4239–4248. ACM (2024). https://doi.org/10.1145/3589334.3645582, https://doi.org/10.1145/3589334.3645582
-
[46]
IEEE Transactions on Knowledge and Data Engineering 33(1), 100–115 (2021)
Liu, Q., Huang, Z., Yin, Y., Chen, E., Xiong, H., Su, Y., Hu, G.: EKT: Exercise-aware knowledge tracing for student performance pre- diction. IEEE Transactions on Knowledge and Data Engineering 33(1), 100–115 (2021). https://doi.org/10.1109/TKDE.2019.2924374, https://doi.org/10.1109/TKDE.2019.2924374
-
[47]
Liu, X., Song, S., Zhang, Z., Zhang, C., Lan, H., Zeng, J., Wu, M., Heinrich, M., Yong, S.: Agora: Toward autonomous bug detection in production-level consensus protocolswithllmagents.In:InternationalConferenceonMachineLearning(2026)
2026
-
[48]
International Joint Conference on Artificial Intelligence (2025) MOSAIC 17
Liu, X., Tang, Z., Li, X.H., Song, Y., Ji, S., Liu, Z., Han, B., Jiang, L., Li, J.: One- shot federated learning methods: A practical guide. International Joint Conference on Artificial Intelligence (2025) MOSAIC 17
2025
-
[49]
Routledge (2012)
Lord, F.M.: Applications of Item Response Theory to Practical Testing Problems. Routledge (2012)
2012
-
[50]
In: Proceedings of UrbanAI ’25
Lou, S.: Urban-mas: Human-centered urban prediction with llm- based multi agent system. In: Proceedings of UrbanAI ’25. pp. 37–40. UrbanAI ’25, Association for Computing Machinery, New York, NY, USA (2025). https://doi.org/10.1145/3764926.3771951, https://doi.org/10.1145/3764926.3771951
-
[51]
Lou, S., Cui, Z.: Enhancing human mobility prediction with spa- tially aware llm-based multi-agent systems. In: Proceedings of HILDA ’26. HILDA ’26, Association for Computing Machinery, New York, NY, USA (2026). https://doi.org/10.1145/3814573.3814949, https://doi.org/10.1145/3814573.3814949
- [52]
-
[53]
In: Proceed- ings of the 2019 IEEE/WIC/ACM International Conference on Web Intel- ligence
Nakagawa, H., Iwasawa, Y., Matsuo, Y.: Graph-based knowledge tracing: Modeling student proficiency using graph neural network. In: Proceed- ings of the 2019 IEEE/WIC/ACM International Conference on Web Intel- ligence. pp. 156–163. ACM (2019). https://doi.org/10.1145/3350546.3352513, https://doi.org/10.1145/3350546.3352513
-
[54]
In: Proceedings of the 29th ACM International Conference on Information & Knowledge Management
Pandey, S., Srivastava, J.: RKT: Relation-aware self-attention for knowl- edge tracing. In: Proceedings of the 29th ACM International Conference on Information & Knowledge Management. pp. 1205–1214. ACM (2020), https://dblp.org/rec/conf/cikm/PandeyS20
2020
-
[55]
Advances in Neural Information Processing Systems28, 505–513 (2015), https://proceedings.neurips.cc/paper/2015/hash/bac9162b47c56fc8a4d2a519803d51b3- Abstract.html
Piech, C., Bassen, J., Huang, J., Ganguli, S., Sahami, M., Guibas, L.J., Sohl-Dickstein, J.: Deep knowledge tracing. Advances in Neural Information Processing Systems28, 505–513 (2015), https://proceedings.neurips.cc/paper/2015/hash/bac9162b47c56fc8a4d2a519803d51b3- Abstract.html
2015
-
[56]
Qian, P., Wang, S., Wang, X., Chen, Y., Xu, W., Yu, Q., Lin, S., Zhang, S., You, J., Wei, X.: Relevant is not warranted: Evidence-force calibration for cited rag (2026), https://arxiv.org/abs/2605.28044
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
BMC Medical In- formatics and Decision Making (2026)
Qin, X., Chignell, M.H., Greifenberger, A., Lokuge, S., Toumeh, E., Sternat, T., Katzman, M., Wang, L.: Explainable counterfactual reasoning in depression med- ication selection at multi-levels (personalized and population). BMC Medical In- formatics and Decision Making (2026)
2026
-
[58]
In: 2025 IEEE International Conference on Data Mining Workshops (ICDMW)
Qin, X., Li, S., Cai, Y., Wang, L.: Enhancing counterfactual explanations with feasibility and diversity. In: 2025 IEEE International Conference on Data Mining Workshops (ICDMW). pp. 2310–2319. IEEE (2025)
2025
-
[59]
In: 2025 IEEE International Conference on Data Mining (ICDM)
Qin, X., Yu, R., Khayati, A., Qiu, Z., Zou, G., Li, Y., Wang, L.: Interpretable and interactive deep survival analysis with time-dependent extreme gradient in- tegration. In: 2025 IEEE International Conference on Data Mining (ICDM). pp. 673–682. IEEE (2025)
2025
-
[60]
IEEE Transactions on Learning Technologies17, 1898–1919 (2024)
Shen, S., Liu, Q., Huang, Z., Zheng, Y., Yin, M., Wang, M., Chen, E.: A survey of knowledge tracing: Models, variants, and applications. IEEE Transactions on Learning Technologies17, 1898–1919 (2024)
1919
-
[61]
In: International Conference on Smart Transportation and City Engineering (STCE 2025)
Shi, J., Lin, Y., Hua, Y.S., Wang, Z., Zhang, Z., Zheng, W., Song, Y.w., Lu, K., Lu, S.: Multiscenario highway lane-change intention prediction: a physics-informed ai framework for three-class classification. In: International Conference on Smart Transportation and City Engineering (STCE 2025). vol. 14120, pp. 129–145. SPIE (2026) 18 X. Li et al
2025
-
[62]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Su, Y., Liu, Q., Liu, Q., Huang, Z., Yin, Y., Chen, E., Ding, C.H.Q., Wei, S., Hu, G.: Exercise-enhanced sequential modeling for student performance prediction. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 2435–2443 (2018), https://ojs.aaai.org/index.php/AAAI/article/view/11864
2018
-
[63]
AutoPCR: Automated Phenotype Concept Recognition by Prompting
Tao, Y., Huang, Y.i., Wang, Y., Luo, X., Liu, J.: Autopcr: Automated phenotype concept recognition by prompting. In: arXiv preprint arXiv:2507.19315 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
In: 2024 19th International Workshop on Semantic and Social Media Adaptation & Personalization (SMAP)
Tian, J., Wang, Z., Zhao, J., Ding, Z.: Mmrec: Llm based multi-modal recom- mender system. In: 2024 19th International Workshop on Semantic and Social Media Adaptation & Personalization (SMAP). pp. 105–110. IEEE (2024)
2024
-
[65]
Wang, S., Qian, P., Chen, Y., You, J., Wang, X., Jiang, X., Liu, L., Yu, H., Xu, J.: When safe skills collide: Measuring compositional risk in agent skill ecosystems (2026), https://arxiv.org/abs/2606.00448
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
In: Proceedings of the 2025 9th Inter- national Conference on Computer Science and Artificial Intelligence
Wang, Z., Tian, J.: Dlrrec: Denoising latent representations via multi-modal knowl- edge fusion in deep recommender systems. In: Proceedings of the 2025 9th Inter- national Conference on Computer Science and Artificial Intelligence. pp. 575–581 (2025)
2025
-
[67]
arXiv preprint arXiv:2502.02945 (2025)
Wang, Z., Zhou, J., Chen, Q., Zhang, M., Jiang, B., Zhou, A., Bai, Q., He, L.: LLM-KT: Aligning large language models with knowledge tracing using a plug-and-play instruction. arXiv preprint arXiv:2502.02945 (2025). https://doi.org/10.48550/arXiv.2502.02945, https://arxiv.org/abs/2502.02945
-
[68]
In: Proceedings of the ACM Web Conference 2026 (WWW ’26)
Xiao, C., Hou, L.: Prototype-aligned federated soft-prompts for continual web per- sonalization. In: Proceedings of the ACM Web Conference 2026 (WWW ’26). ACM (2026). https://doi.org/10.1145/3774904.3792626
-
[69]
In: The Fourteenth International Conference on Learning Representations (ICLR) (2026)
Xiao, S., Xu, T., Xiao, C., Luo, W., Hou, L., Zhao, C.: Meta-UCF: Unified task- conditioned LoRA generation for continual learning in large language models. In: The Fourteenth International Conference on Learning Representations (ICLR) (2026)
2026
-
[70]
In: International Conference on Multimedia Modeling (2025)
Xu, Z., Zhang, X., Li, R., Tang, Z.: Fakeshield: Explainable image forgery de- tection and localization via multi-modal large language models. In: International Conference on Multimedia Modeling (2025)
2025
-
[71]
In: International Conference on Machine Learning
Xu, Z., Zhang, X., Xu, Y., Huang, Q., Chen, S., Yao, T., Ding, S., Zhang, J.: Genshield: Unified detection and artifact correction for ai-generated images. In: International Conference on Machine Learning. PMLR (2026)
2026
-
[72]
Drones10(2), 147 (2026)
Yang, J., Zhang, H., Ji, F., Wang, Y., Wang, M., Luo, Y., Ding, W.: Frequency point game environment for uavs via expert knowledge and large language model. Drones10(2), 147 (2026)
2026
-
[73]
ACM Transactions on Information Systems (2025)
Yuan, M., Zhang, Z., Chen, W., Zhao, C., Cai, T., Wang, D., Liu, R., Zhuang, F.: Hek-cl: Hierarchical enhanced knowledge-aware contrastive learning for recom- mendation. ACM Transactions on Information Systems (2025)
2025
-
[74]
arXiv preprint arXiv:2508.02618 (2025)
Zang, J.: Alleviating attention hacking in discriminative reward modeling through interaction distillation. arXiv preprint arXiv:2508.02618 (2025)
-
[75]
In: 2024 International Joint Conference on Neural Networks (IJCNN)
Zang, J., Liu, H.: Explanation based bias decoupling regularization for natural language inference. In: 2024 International Joint Conference on Neural Networks (IJCNN). pp. 1–8. IEEE (2024)
2024
-
[76]
arXiv e-prints pp
Zang, J., Ning, M., Wei, Y., Dou, S., Zhang, J., Mo, N., Li, B., Gui, T., Zhang, Q., Huang, X.: Compression hacking: a supplementary perspective on informatics metric of language models from geometric distortion. arXiv e-prints pp. arXiv–2505 (2025)
2025
-
[77]
arXiv preprint arXiv:2507.22330 (2025) MOSAIC 19
Zhang, C., Li, H., Liu, X., Jiang, L., Wang, D.: Hypernetworks for model- heterogeneous personalized federated learning. arXiv preprint arXiv:2507.22330 (2025) MOSAIC 19
-
[78]
Zhang, H., Yang, S., Liang, X., Shang, C., Jiang, Y., Tao, C., Xiong, J., So, H.K.H., Xie, R., Chang, A.X., Wong, N.: Find your optimal teacher: Personalized data synthesis via router-guided multi-teacher distillation (2026), https://arxiv.org/abs/2510.10925
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[79]
In: Proceedings of the 26th International Confer- ence on World Wide Web
Zhang, J., Shi, X., King, I., Yeung, D.Y.: Dynamic key-value memory net- works for knowledge tracing. In: Proceedings of the 26th International Confer- ence on World Wide Web. pp. 765–774. International World Wide Web Con- ferences Steering Committee (2017). https://doi.org/10.1145/3038912.3052580, https://doi.org/10.1145/3038912.3052580
-
[80]
Expert Systems with Applications p
Zhang, J., Song, X., Li, Y., Liang, D., Zhang, Z., Cai, J.: Adaptive dual cross- attention network for multispectral object detection in autonomous driving. Expert Systems with Applications p. 132012 (2026)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.