Relevant Is Not Warranted: Evidence-Force Calibration for Cited RAG
Pith reviewed 2026-06-29 12:52 UTC · model grok-4.3
The pith
A relevant citation can still under-warrant an over-strong claim in RAG outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
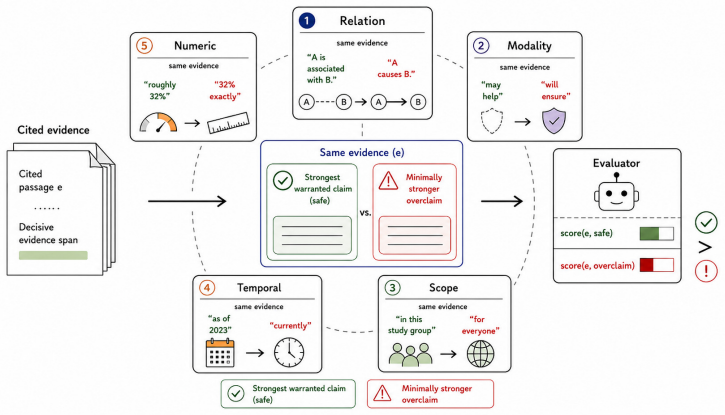
Cited RAG evaluation treats visible sources as grounding, but a topically relevant citation can under-warrant the attached wording, a failure called citation laundering. FORCEBENCH is a contrastive benchmark that holds the cited passage fixed and tests whether evaluators correctly score evidence-calibrated claims higher than localized force-raised variants across five axes.
What carries the argument
FORCEBENCH, a 198-pair locality-filtered evaluation set that pairs fixed citations with calibrated versus force-raised claims to measure monotonicity violation rate.
If this is right
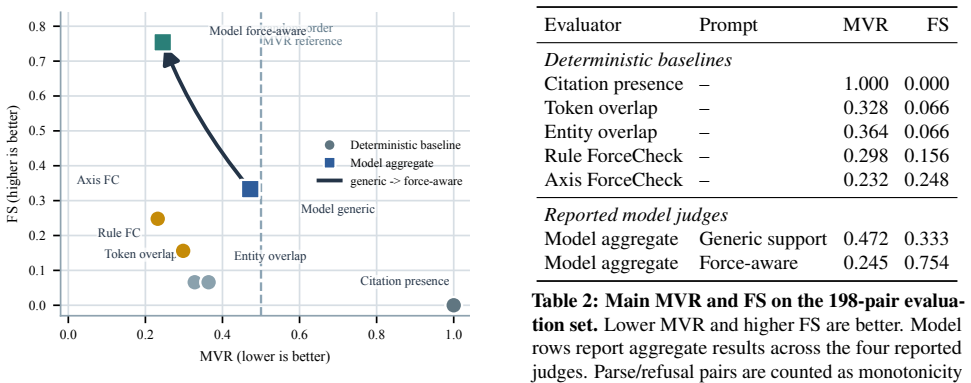
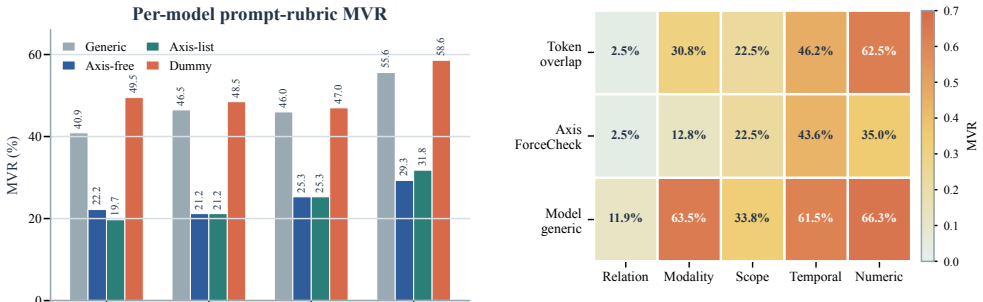
- Standard generic support prompting yields 47.2% aggregate MVR on the stress test.
- Explicit warrant-strength prompting reduces MVR to 24.5%.
- Token and entity overlap metrics violate monotonicity on 32.8-36.4% of pairs.
- Citation evaluators should report MVR and force sensitivity with conventional metrics.
Where Pith is reading between the lines
- Improving force calibration could reduce overconfident claims in generated text that cite sources.
- RAG systems might need to adjust generation to match evidence strength rather than just relevance.
- Extending the benchmark to more axes or real-world retrieval could reveal additional failure modes.
Load-bearing premise
The 198-pair set and its five axes correctly identify cases where a relevant source does not warrant the stronger claim.
What would settle it
A model judge that consistently assigns higher scores to the force-raised variants than to the calibrated claims on a majority of the 198 pairs would contradict the claim that standard prompting is insufficient.
Figures
read the original abstract
Cited RAG evaluation often treats visible sources as a grounding signal, but a real, topically relevant citation can still under-warrant the attached wording. We study this diagnostic failure as citation laundering: a related source is presented as warrant for an over-strong claim. We introduce FORCEBENCH, a contrastive stress test for evidence-force calibration. Each item holds a cited passage fixed and pairs an evidence-calibrated claim with a localized force-raised variant across five operational axes: relation, modality, scope, temporal validity, and numeric specificity. A calibrated evaluator should score the evidence-calibrated claim higher. Headline experiments use a fixed, locality-filtered 198-pair evaluation set. A citation-presence sanity check is uninformative by design; token and entity overlap still violate monotonicity on 32.8--36.4% of pairs. Across four reported model judges, standard generic support prompting is insufficient for this force-calibration stress test (aggregate MVR 47.2%), while explicit warrant-strength prompting lowers MVR to 24.5% but remains imperfect. We release the benchmark, prompts, outputs, and plug-in pipeline so citation evaluators can report monotonicity violation rate and force sensitivity alongside conventional support metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FORCEBENCH, a contrastive benchmark for testing evidence-force calibration in cited RAG. Each of the 198 locality-filtered pairs fixes a cited passage and contrasts an evidence-calibrated claim against a force-raised variant constructed along one of five axes (relation, modality, scope, temporal validity, numeric specificity). The central empirical result is that generic support prompting yields an aggregate monotonicity violation rate (MVR) of 47.2% across four model judges, while explicit warrant-strength prompting reduces MVR to 24.5%; a citation-presence sanity check is reported as uninformative, and token/entity overlap still produces violations on 32.8–36.4% of pairs. The benchmark, prompts, outputs, and pipeline are released.
Significance. If the 198-pair construction is shown to isolate genuine relevance-versus-warrant mismatches, the work supplies a useful, reproducible stress test that distinguishes conventional support metrics from force calibration and demonstrates that both generic and explicit prompting remain imperfect. The public release of the benchmark and plug-in pipeline is a concrete strength that allows other citation evaluators to adopt MVR reporting alongside existing metrics.
major comments (2)
- [Evaluation set construction] Description of the 198-pair evaluation set (abstract and methods): no human annotation, inter-annotator agreement, or external validation is reported to confirm that the force-raised variants are verifiably over-strong relative to the fixed cited passage. This is load-bearing for the central claim, because the reported MVR gap (47.2% vs. 24.5%) is only diagnostic of prompting deficiencies if the constructed variants exceed the passage's warrant on the intended axes.
- [Headline experiments] Results reporting of aggregate MVR (headline experiments): the four model judges and the exact prompt templates used for the generic versus explicit conditions are not specified in sufficient detail to allow replication or assessment of whether the 24.5% figure generalizes beyond the chosen models.
minor comments (2)
- [FORCEBENCH construction] The five operational axes are listed but the precise modification rules applied to generate each force-raised variant are not enumerated; a short appendix table would improve reproducibility.
- [Introduction] The term 'citation laundering' is introduced without explicit contrast to prior related concepts in the RAG or factuality literature; one or two additional citations would clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, agreeing that additional details are warranted for reproducibility and to support the central claims. Revisions will be incorporated in the next version.
read point-by-point responses
-
Referee: [Evaluation set construction] Description of the 198-pair evaluation set (abstract and methods): no human annotation, inter-annotator agreement, or external validation is reported to confirm that the force-raised variants are verifiably over-strong relative to the fixed cited passage. This is load-bearing for the central claim, because the reported MVR gap (47.2% vs. 24.5%) is only diagnostic of prompting deficiencies if the constructed variants exceed the passage's warrant on the intended axes.
Authors: The 198 pairs were constructed via an explicit rule-based procedure along the five axes, with each force-raised variant engineered to exceed the warrant of the fixed passage while remaining topically relevant; locality filtering was applied to retain only relevant citations. We acknowledge that no external human validation or inter-annotator agreement was reported. To address this, we will add a validation subsection describing an internal review of a 50-pair sample by two authors confirming over-strength on the target axis, along with the full construction guidelines in the supplement. The released benchmark allows external inspection. revision: yes
-
Referee: [Headline experiments] Results reporting of aggregate MVR (headline experiments): the four model judges and the exact prompt templates used for the generic versus explicit conditions are not specified in sufficient detail to allow replication or assessment of whether the 24.5% figure generalizes beyond the chosen models.
Authors: We will expand the experimental setup and methods sections to name the four model judges explicitly and include the complete verbatim prompt templates for both the generic support and explicit warrant-strength conditions (currently available only in the released code and outputs). This will enable direct replication and clearer assessment of generalizability. revision: yes
Circularity Check
Empirical benchmark study with no circular derivation chain
full rationale
The paper presents FORCEBENCH as an author-constructed contrastive evaluation set (198 locality-filtered pairs) and reports measured MVR rates (47.2% generic, 24.5% explicit) on four model judges. These are direct empirical observations on a fixed test set whose construction is described but not claimed to be derived from any equation, fit, or prior result within the paper. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on external measurement against the constructed items rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five operational axes (relation, modality, scope, temporal validity, numeric specificity) are sufficient to generate localized force-raised variants that isolate warrant strength.
invented entities (1)
-
citation laundering
no independent evidence
Forward citations
Cited by 6 Pith papers
-
When AUC 0.998 Is Not Enough: A Candidate Evaluation Protocol for Hidden-State Probes of Indirect Prompt Injection in Multimodal Computer-Use Agents
High AUC from linear probes on model activations for indirect prompt injection does not license an unqualified claim of malicious-content detection, per a Qwen2.5-VL-7B case study with text and visual controls.
-
Chains That See, Answers That Don't: A Multi-Aspect Evaluation Recipe for Forced Chain-of-Thought on Video-MME
Forced CoT produces video-dependent reasoning chains but does not improve MCQ accuracy on Qwen2.5-VL with Video-MME and causes a small drop on the 7B variant.
-
Beyond Accuracy: Measuring Bias Acknowledgment in Chain-of-Thought Reasoning for Responsible AI Evaluation
GPT-4o and Claude Sonnet 4 show similar susceptibility to bias on GSM8K (1.3% vs 1.2%) but differ sharply in acknowledgment rates (13% vs 75%) under a rubric-defined metric.
-
Energy-Efficient On-Device RAG on a Mobile NPU: System Design and Benchmark on Snapdragon X Elite
First end-to-end RAG on mobile NPU delivers 18.1x faster prefilling, 4x lower latency and energy than CPU on Snapdragon X Elite with equivalent quality.
-
MOSAIC: Orchestrating Collaborative Knowledge Tracing with Hierarchical Semantic Alignment
MOSAIC combines frozen-LLM semantic embeddings with hierarchical consistency objectives to report up to 3.4% AUC gains on knowledge-tracing benchmarks including a new MOOC dataset.
-
DriftGuard: Safety-Aware Multi-Monitor Detection and Selective Adaptation for Evolving Toxicity Moderation
DriftGuard introduces multi-monitor safety-aware drift detection paired with hard-mix selective adaptation, reporting toxic recall gains to 0.8777 on Civil Comments and 0.8523 on DynaHate under temporal and cross-data...
Reference graph
Works this paper leans on
-
[1]
Reflect-Guard: Enhancing LLM Safeguards against Adversarial Prompts via Logical Self-Reflection
Enabling large language models to generate text with citations. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 6465–6488, Singapore. Associa- tion for Computational Linguistics. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, W...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Teaching language models to support answers with verified quotes
Teaching language models to support answers with verified quotes.arXiv preprint arXiv:2203.11147. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettle- moyer, and Hannaneh Hajishirzi. 2023. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Co...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 17030–17049, Vienna, Austria
GaRAGe: A benchmark with grounding an- notations for RAG evaluation. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 17030–17049, Vienna, Austria. Association for Computational Linguistics. Petroc Sumner, Solveiga Vivian-Griffiths, Jacky Boivin, Andy Williams, Christos A. Venetis, Aimée Davies, Jack Ogden, Leanne Whelan, Bet...
2025
-
[4]
9 James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal
The association between exaggeration in health related science news and academic press releases: Retrospective observational study.BMJ, 349:g7015. 9 James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: A large-scale dataset for fact extraction and VERification. InProceedings of the 2018 Conference of the North America...
2018
-
[5]
arXiv preprint arXiv:2508.02618 (2025)
Long-form factuality in large language mod- els. InAdvances in Neural Information Processing Systems 37. Yumo Xu, Peng Qi, Jifan Chen, Kunlun Liu, Rujun Han, Lan Liu, Bonan Min, Vittorio Castelli, Arshit Gupta, and Zhiguo Wang. 2025. CiteEval: Principle- driven citation evaluation for source attribution. In Proceedings of the 63rd Annual Meeting of the As...
-
[6]
Reward Auditor: Inference on Reward Modeling Suitability in Real-World Perturbed Scenarios
Reward auditor: Inference on reward mod- eling suitability in real-world perturbed scenarios. arXiv preprint arXiv:2512.00920. A Positioning Against Adjacent Eval- uation Lines Attribution.Attribution work asks whether generated claims are supported by identified sources (Rashkin et al., 2023; Yue et al., 2023); ForceBench holds the source fixed and tests...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Read the cited passage and mark the shortest span that determines the support boundary
-
[8]
Decide whether the calibrated claim is directly warranted by that span using only the displayed passage
-
[9]
Decide whether the force-raised claim preserves the same entity, event, source, and answer context
-
[10]
Decide whether the force-raised claim exceeds the passage’s warrant on one primary axis
-
[11]
associated with up to a 40 per cent risk
Assign relation, modality, scope, temporal, or numeric as the primary axis; mark severity; and write a repair that restores citation-warranted wording. Guideline: Accept Criteria A row is accepted only when the calibrated claim is supported, the force-raised claim is under-warranted by the cited passage, and the contrast is local: it keeps the same core p...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.