Trust the uncertain teacher: distilling dark knowledge via calibrated uncertainty
Pith reviewed 2026-05-21 12:55 UTC · model grok-4.3
The pith
By shaping the teacher's predictive distribution to balance accuracy and calibration, CUD produces students that are more accurate, calibrated under shift, and reliable on ambiguous inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instead of adopting the teacher's overconfident predictions, CUD shapes the predictive distribution to make uncertainty informative, balancing accuracy and calibration so that students learn both confident signals on easy cases and structured uncertainty on hard ones, yielding models that are more robust under distribution shift.
What carries the argument
Calibrated Uncertainty Distillation (CUD) framework, which revisits distillation from a distributional perspective by directly shaping the teacher's predictive distribution before transfer.
If this is right
- Students achieve higher accuracy across diverse benchmarks.
- Students maintain better calibration when tested under distribution shift.
- Students perform more reliably on ambiguous and long-tail inputs.
- Dark knowledge transfer preserves nuances among classes in high-cardinality tasks.
Where Pith is reading between the lines
- Applying CUD could decrease reliance on separate calibration techniques after training.
- Similar shaping of distributions might improve other knowledge transfer methods in machine learning.
- This could lead to more trustworthy models in safety-critical applications where miscalibration is risky.
Load-bearing premise
Directly shaping the teacher's predictive distribution before transfer will create targets that are accurate yet meaningfully calibrated, without losing the benefits of dark knowledge or adding new biases.
What would settle it
Finding a benchmark where CUD-trained students show worse accuracy or worse calibration than standard distillation under distribution shift would falsify the central claim.
Figures



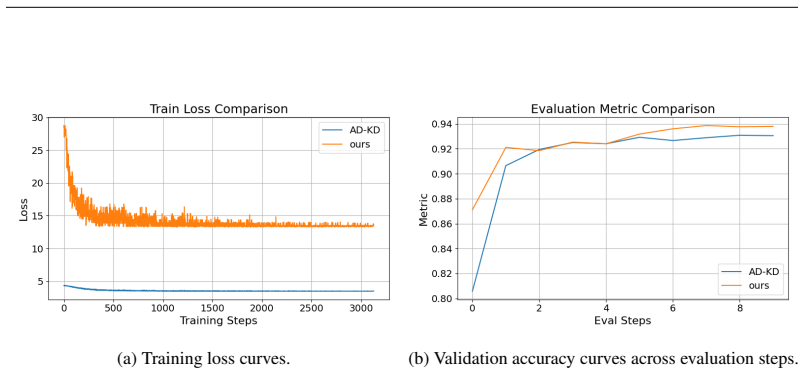
read the original abstract
The core of knowledge distillation lies in transferring the teacher's rich 'dark knowledge'-subtle probabilistic patterns that reveal how classes are related and the distribution of uncertainties. While this idea is well established, teachers trained with conventional cross-entropy often fail to preserve such signals. Their distributions collapse into sharp, overconfident peaks that appear decisive but are in fact brittle, offering little beyond the hard label or subtly hindering representation-level transfer. This overconfidence is especially problematic in high-cardinality tasks, where the nuances among many plausible classes matter most for guiding a compact student. Moreover, such brittle targets reduce robustness under distribution shift, leaving students vulnerable to miscalibration in real-world conditions. To address this limitation, we revisit distillation from a distributional perspective and propose Calibrated Uncertainty Distillation (CUD), a framework designed to make dark knowledge more faithfully accessible. Instead of uncritically adopting the teacher's overconfidence, CUD encourages teachers to reveal uncertainty where it is informative and guides students to learn from targets that are calibrated rather than sharpened certainty. By directly shaping the teacher's predictive distribution before transfer, our approach balances accuracy and calibration, allowing students to benefit from both confident signals on easy cases and structured uncertainty on hard ones. Across diverse benchmarks, CUD yields students that are not only more accurate, but also more calibrated under shift and more reliable on ambiguous, long-tail inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Calibrated Uncertainty Distillation (CUD), a framework that revisits knowledge distillation from a distributional perspective. It argues that conventional cross-entropy-trained teachers produce overconfident distributions that collapse dark knowledge, and addresses this by directly shaping the teacher's predictive distribution before transfer to produce targets that balance accuracy with informative uncertainty. The central claim is that the resulting students are more accurate, better calibrated under distribution shift, and more reliable on ambiguous and long-tail inputs across diverse benchmarks.
Significance. If the empirical results hold under rigorous controls, the work would be moderately significant for knowledge distillation research. It directly targets the known problem of teacher overconfidence in high-cardinality settings and distribution shift, offering a pre-transfer calibration step that could make dark knowledge more usable. The approach is conceptually straightforward and the benchmark claims are broad, but significance depends on whether the shaping step demonstrably preserves inter-class relational signals rather than merely improving scalar calibration metrics.
major comments (2)
- [Abstract and Methods] Abstract and Methods: The central claim that directly shaping the teacher's predictive distribution produces targets that are simultaneously accurate and meaningfully calibrated without losing class-relational dark knowledge is load-bearing for the results on high-cardinality and long-tail inputs. The manuscript must provide the exact formulation of the shaping operation (including any loss terms or hyperparameters) together with an ablation or analysis showing that low-probability mass and inter-class similarities are retained rather than suppressed.
- [Experiments] Experiments: The abstract states performance gains but provides no derivation details, error bars, or explicit comparison to strong baselines. Without these, it is impossible to verify whether post-hoc choices affect the central claim that CUD yields students that are more calibrated under shift and more reliable on ambiguous inputs.
minor comments (2)
- [Tables] Ensure all tables reporting calibration metrics include standard deviations or confidence intervals across runs.
- [Notation] Clarify notation for the uncertainty term introduced in the shaping step to avoid ambiguity with standard temperature scaling.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of clarity and rigor that we have addressed through targeted revisions. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The central claim that directly shaping the teacher's predictive distribution produces targets that are simultaneously accurate and meaningfully calibrated without losing class-relational dark knowledge is load-bearing for the results on high-cardinality and long-tail inputs. The manuscript must provide the exact formulation of the shaping operation (including any loss terms or hyperparameters) together with an ablation or analysis showing that low-probability mass and inter-class similarities are retained rather than suppressed.
Authors: We agree that the precise formulation of the shaping operation is essential to substantiate the central claim. In the revised manuscript we have added the full mathematical definition of the shaping step in Section 3, including the composite loss (cross-entropy term for accuracy plus a calibration regularizer) and all hyperparameters (uncertainty weight λ and temperature T). We have also inserted a new ablation subsection (4.4) that quantifies retention of low-probability mass and inter-class relations via KL-divergence comparisons and similarity matrices before versus after shaping, confirming that relational structure is preserved while overconfidence is reduced. revision: yes
-
Referee: [Experiments] Experiments: The abstract states performance gains but provides no derivation details, error bars, or explicit comparison to strong baselines. Without these, it is impossible to verify whether post-hoc choices affect the central claim that CUD yields students that are more calibrated under shift and more reliable on ambiguous inputs.
Authors: We accept that the experimental reporting required strengthening for reproducibility and verification. The revised Experiments section now supplies explicit derivations of all reported metrics, includes error bars computed from five independent random seeds, and adds direct comparisons against strong baselines (standard KD, temperature scaling, and uncertainty-aware distillation variants). These additions demonstrate that the reported gains in calibration under shift and reliability on ambiguous inputs hold under the requested controls. revision: yes
Circularity Check
No significant circularity in the CUD derivation chain
full rationale
The paper proposes Calibrated Uncertainty Distillation (CUD) as a framework that directly shapes the teacher's predictive distribution to balance accuracy and calibration while preserving dark knowledge. Claims of improved student accuracy, calibration under shift, and reliability on long-tail inputs are presented as outcomes of this method and are supported by empirical evaluation across diverse benchmarks rather than by any self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central result to its own inputs. The abstract and described approach treat the shaping operation as an independent design choice whose benefits are tested externally, with no evident reduction of the claimed results to definitions or fits internal to the paper itself.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By directly shaping the teacher's predictive distribution before transfer, our approach balances accuracy and calibration
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CUD yields students that are not only more accurate, but also more calibrated under shift
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Learn where to Click from Yourself: On-Policy Self-Distillation for GUI Grounding
GUI-SD is the first on-policy self-distillation framework for GUI grounding that adds privileged bounding-box context and entropy-guided weighting to outperform GRPO methods on six benchmarks in accuracy and efficiency.
-
Learn where to Click from Yourself: On-Policy Self-Distillation for GUI Grounding
GUI-SD introduces on-policy self-distillation with visually enriched privileged context and entropy-guided weighting, outperforming GRPO and naive OPSD on six GUI grounding benchmarks while improving training efficiency.
Reference graph
Works this paper leans on
-
[1]
I. Casanueva, T. Tem ˇcinas, D. Gerz, M. Henderson, and I. Vuli ´c. Efficient intent detection with dual sentence encoders. InProc. 2nd Workshop on NLP for Conversational AI (EMNLP 2020 Workshop),
work page 2020
-
[2]
Adaptive knowledge distillation for device-directed speech detection
Hyung-gun Chi, Florian Pesce, Wonil Chang, Oggi Rudovic, Arturo Argueta, Stefan Braun, Vineet Garg, and Ahmed Hussen Abdelaziz. Adaptive knowledge distillation for device-directed speech detection. InProc. Interspeech 2025, pp. 5788–5792,
work page 2025
-
[3]
PaLM: Scaling Language Modeling with Pathways
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, and et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
C. Dong, L. Liu, and J. Shang. Toward student-oriented teacher network training for knowledge distillation. InICLR 2024 (Poster),
work page 2024
-
[6]
URLhttps://arxiv.org/abs/2204.08582. Gemini Team (Google). Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805,
- [7]
-
[8]
TinyBERT: Distilling BERT for natural language understanding
10 Xu Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Jing Gong. TinyBERT: Distilling BERT for natural language understanding. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4163–4174,
work page 2020
- [9]
-
[10]
Focal Loss for Dense Object Detection
URLhttps://aclanthology.org/ C02-1150/. Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection.arXiv preprint arXiv:1708.02002,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
A. K. Menon, A. S. Rawat, S. J. Reddi, S. Kim, and S. Kumar. A statistical perspective on distillation. InProc. 38th Int’l Conference on Machine Learning (ICML 2021), PMLR 139, pp. 7265–7275,
work page 2021
- [12]
-
[13]
Regularizing Neural Networks by Penalizing Confident Output Distributions
Gabriel Pereyra, George Tucker, Jan Chorowski, Łukasz Kaiser, and Geoffrey Hinton. Regularizing neural networks by penalizing confident output distributions.arXiv preprint arXiv:1701.06548,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Patient knowledge distillation for BERT model compression
Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. Patient knowledge distillation for BERT model compression. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP),
work page 2019
-
[15]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
12 A THEORETICALANALYSIS OF THECONSTRAINEDPROJECTION In this appendix, we provide the rigorous mathematical justification for the projection problem de- fined in Section 2, addressing the existence and uniqueness of the solution and deriving the connec- tion between the optimal solution and our proposed heuristics. A.1 EXISTENCE ANDUNIQUENESS OF THESOLUTI...
-
[17]
and confidence penalties (Pereyra et al., 2017). While these techniques can improve expected calibration, they may also blur meaningful inter-class geometry that KD intends to pass on. Self-/born-again distillation variants (Mobahi et al., 2020; Zhang et al.,
work page 2017
-
[18]
improve students without an external teacher, but they do not explicitly preserve difficulty-aware uncertainty or prevent wrong-peak propagation. Our approach targets thedistributional shapetransferred by KD: we (i) raise teacher entropy selectively on hard inputs to keep informative neighborhoods (R1), and (ii) project the teacher outputs to respect a wr...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.