Recognition: 2 theorem links
· Lean TheoremLearn where to Click from Yourself: On-Policy Self-Distillation for GUI Grounding
Pith reviewed 2026-05-12 01:58 UTC · model grok-4.3
The pith
On-policy self-distillation with visual context improves GUI grounding accuracy and efficiency over reinforcement learning methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
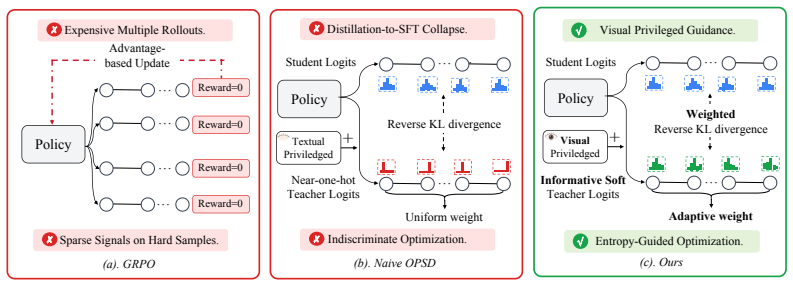
GUI-SD demonstrates that on-policy self-distillation can be effectively adapted to GUI grounding by constructing a visually enriched privileged context for the teacher using a target bounding box and Gaussian soft mask, combined with entropy-guided weighting of tokens based on digit significance and teacher confidence, leading to consistent improvements in accuracy and training efficiency over GRPO-based methods and naive OPSD on six representative benchmarks.
What carries the argument
The GUI-SD framework's visually enriched privileged context (target bounding box plus Gaussian soft mask) and entropy-guided distillation that weights tokens by digit significance and teacher confidence.
If this is right
- GUI-SD outperforms GRPO-based methods in accuracy across six benchmarks.
- It requires fewer computational resources by avoiding multiple rollouts.
- Entropy-guided distillation focuses learning on significant digits and confident predictions.
- The method provides a dense supervision signal from a single rollout for hard samples.
Where Pith is reading between the lines
- Extending GUI-SD to other multimodal grounding tasks could improve efficiency in agent training.
- The privileged context design might inspire similar techniques in other self-distillation scenarios to prevent information leakage.
- Testing GUI-SD on larger models or different architectures would reveal its scalability.
Load-bearing premise
The visually enriched privileged context supplies useful guidance to the teacher without leaking the exact target coordinates, and entropy-guided weighting reliably concentrates learning on the most impactful and reliable tokens.
What would settle it
An ablation study removing the Gaussian soft mask and showing performance dropping to the level of naive OPSD would falsify the claim that the privileged context provides non-leaking guidance.
Figures



read the original abstract
Graphical User Interface (GUI) grounding maps natural language instructions to the visual coordinates of target elements and serves as a core capability for autonomous GUI agents. Recent reinforcement learning methods (e.g., GRPO) have achieved strong performance, but they rely on expensive multiple rollouts and suffer from sparse signals on hard samples. These limitations make on-policy self-distillation (OPSD), which provides dense token-level supervision from a single rollout, a promising alternative. However, its applicability to GUI grounding remains unexplored. In this paper, we present GUI-SD, the first OPSD framework tailored for GUI grounding. First, it constructs a visually enriched privileged context for the teacher using a target bounding box and a Gaussian soft mask, providing informative guidance without leaking exact coordinates. Second, it employs entropy-guided distillation, which adaptively weights tokens based on digit significance and teacher confidence, concentrating optimization on the most impactful and reliable positions. Extensive experiments on six representative GUI grounding benchmarks show that GUI-SD consistently outperforms GRPO-based methods and naive OPSD in both accuracy and training efficiency. Code and training data are available at https://zhangyan-ucas.github.io/GUI-SD/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GUI-SD as the first on-policy self-distillation (OPSD) framework for GUI grounding. It constructs a visually enriched privileged context for the teacher via the target bounding box plus a Gaussian soft mask, applies entropy-guided distillation that weights tokens by digit significance and teacher confidence, and reports consistent outperformance over GRPO-based methods and naive OPSD across six GUI grounding benchmarks in both accuracy and training efficiency.
Significance. If the empirical claims hold, the work offers a computationally lighter alternative to rollout-heavy RL methods for training GUI agents, addressing sparse reward issues on hard samples while maintaining dense token-level supervision. The public release of code and training data is a clear strength that supports reproducibility.
major comments (1)
- [Privileged context construction] The central methodological claim (abstract and method description) asserts that the Gaussian soft mask 'provides informative guidance without leaking exact coordinates.' Because the mask is centered on the ground-truth target, its spatial peak directly encodes approximate location information unavailable to the student or to naive OPSD. An ablation that recenters the mask at random locations (while preserving shape and variance) is required to confirm that reported gains over baselines are attributable to entropy-guided weighting and on-policy distillation rather than this privileged cue.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one or two key quantitative deltas (e.g., average accuracy lift and training-time reduction) rather than only the qualitative statement of 'consistent outperformance.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed review of our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Privileged context construction] The central methodological claim (abstract and method description) asserts that the Gaussian soft mask 'provides informative guidance without leaking exact coordinates.' Because the mask is centered on the ground-truth target, its spatial peak directly encodes approximate location information unavailable to the student or to naive OPSD. An ablation that recenters the mask at random locations (while preserving shape and variance) is required to confirm that reported gains over baselines are attributable to entropy-guided weighting and on-policy distillation rather than this privileged cue.
Authors: We appreciate the referee's observation. The Gaussian soft mask is indeed centered on the ground-truth target, which provides a soft spatial prior unavailable to the student or naive OPSD. While the mask remains probabilistic and does not encode exact pixel coordinates, it does convey approximate location information. To rigorously isolate this effect from the entropy-guided weighting and on-policy distillation, we agree that the proposed ablation (recentering the mask at random locations while preserving shape and variance) is necessary. We will conduct this experiment and include the results in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper introduces GUI-SD as an on-policy self-distillation method for GUI grounding, consisting of a privileged teacher context (bounding box + Gaussian mask) and entropy-guided token weighting. These are presented as design choices, not derived predictions. Performance claims rest entirely on comparative experiments across six independent benchmarks against GRPO and naive OPSD baselines. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The derivation chain is absent; the work is self-contained via external empirical evaluation rather than internal reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gaussian mask spread
axioms (1)
- domain assumption Privileged visual context supplies useful guidance without coordinate leakage
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Gaussian soft mask ... α(x, y) = exp(−d² / 2σ²)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
entropy-guided distillation ... w_ent(t) = exp(−H(p_T)/τ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Chen Chen, Jiawei Shao, Dakuan Lu, Haoyi Hu, Xiangcheng Liu, Hantao Yao, and Wu Liu. Gui-eyes: Tool-augmented perception for visual grounding in gui agents.arXiv preprint arXiv:2601.09770, 2026
-
[3]
Liangyu Chen, Hanzhang Zhou, Chenglin Cai, Jianan Zhang, Panrong Tong, Quyu Kong, Xu Zhang, Chen Liu, Yuqi Liu, Wenxuan Wang, et al. Ui-ins: Enhancing gui grounding with multi-perspective instruction-as-reasoning.arXiv preprint arXiv:2510.20286, 2025
-
[4]
Seeclick: Harnessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9313–9332, 2024
work page 2024
-
[5]
WebFactory: Automated Compression of Foundational Language Intelligence into Grounded Web Agents
Sicheng Fan, Qingyun Shi, Shengze Xu, Shengbo Cai, Tieyong Zeng, Li Ling, Yanyi Shang, and Dehan Kong. Webfactory: Automated compression of foundational language intelligence into grounded web agents.arXiv preprint arXiv:2603.05044, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Gui-bee: Align gui action grounding to novel environments via autonomous exploration
Yue Fan, Handong Zhao, Ruiyi Zhang, Yu Shen, Xin Eric Wang, and Gang Wu. Gui-bee: Align gui action grounding to novel environments via autonomous exploration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33249–33266, 2025
work page 2025
-
[7]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for gui agents.arXiv preprint arXiv:2410.05243, 2024
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
MolmoWeb: Open Visual Web Agent and Open Data for the Open Web
Tanmay Gupta, Piper Wolters, Zixian Ma, Peter Sushko, Rock Yuren Pang, Diego Llanes, Yue Yang, Taira Anderson, Boyuan Zheng, Zhongzheng Ren, et al. Molmoweb: Open visual web agent and open data for the open web.arXiv preprint arXiv:2604.08516, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Kun Huang, Weikai Xu, Yuxuan Liu, Quandong Wang, Pengzhi Gao, Wei Liu, Jian Luan, Bin Wang, and Bo An. Mobileipl: Enhancing mobile agents thinking process via iterative preference learning.arXiv preprint arXiv:2505.12299, 2025
-
[12]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026. 10
work page internal anchor Pith review arXiv 2026
-
[13]
Todi: Token-wise distilla- tion via fine-grained divergence control
Seongryong Jung, Suwan Yoon, DongGeon Kim, and Hwanhee Lee. Todi: Token-wise distilla- tion via fine-grained divergence control. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 8089–8102, 2025
work page 2025
-
[14]
Weitai Kang, Bin Lei, Gaowen Liu, Caiwen Ding, and Yan Yan. Guirlvg: Incentivize gui visual grounding via empirical exploration on reinforcement learning.arXiv preprint arXiv:2508.04389, 2025
-
[15]
Jeonghyun Kim, SooKyung Kim, Richeng Xuan, and Hyunsoo Cho. Trust the uncertain teacher: distilling dark knowledge via calibrated uncertainty.arXiv preprint arXiv:2602.12687, 2026
-
[16]
Hanyu Lai, Xiao Liu, Yanxiao Zhao, Han Xu, Hanchen Zhang, Bohao Jing, Yanyu Ren, Shuntian Yao, Yuxiao Dong, and Jie Tang. Computerrl: Scaling end-to-end online reinforcement learning for computer use agents.arXiv preprint arXiv:2508.14040, 2025
-
[17]
Screenspot-pro: Gui grounding for professional high-resolution computer use
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: Gui grounding for professional high-resolution computer use. InProceedings of the 33rd ACM International Conference on Multimedia, pages 8778– 8786, 2025
work page 2025
-
[18]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
arXiv preprint arXiv:2504.14239 , year=
Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, and Fei Wu. Infigui-r1: Advancing multimodal gui agents from reactive actors to deliberative reasoners.arXiv preprint arXiv:2504.14239, 2025
-
[20]
arXiv preprint arXiv:2509.15221 , year =
Zhaoyang Liu, JingJing Xie, Zichen Ding, Zehao Li, Bowen Yang, Zhenyu Wu, Xuehui Wang, Qiushi Sun, Shi Liu, Weiyun Wang, et al. Scalecua: Scaling open-source computer use agents with cross-platform data.arXiv preprint arXiv:2509.15221, 2025
-
[21]
Ziwei Liu, Tao Feng, Borui Kang, Yanbing Yang, and Jun Luo. Zoom to essence: Trainless gui grounding by inferring upon interface elements.arXiv preprint arXiv:2603.14448, 2026
-
[22]
Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Pengxiang Zhao, Guangyi Liu, et al. Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 17608–17616, 2026
work page 2026
-
[23]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Juan A Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M Tamer Özsu, Aishwarya Agrawal, David Vazquez, et al. Ui- vision: A desktop-centric gui benchmark for visual perception and interaction.arXiv preprint arXiv:2503.15661, 2025
-
[25]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. Pope: Learning to reason on hard problems via privileged on-policy exploration.arXiv preprint arXiv:2601.18779, 2026
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026. 11
work page internal anchor Pith review arXiv 2026
-
[29]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review arXiv 2026
-
[30]
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback.arXiv preprint arXiv:2602.02482, 2026
-
[31]
Ea-kd: Entropy-based adaptive knowledge distillation
Chi-Ping Su, Ching-Hsun Tseng, Bin Pu, Lei Zhao, Jiewen Yang, Zhuangzhuang Chen, and Shin-Jye Lee. Ea-kd: Entropy-based adaptive knowledge distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 731–740, 2025
work page 2025
-
[32]
Gui-g2: Gaussian reward modeling for gui grounding
Fei Tang, Zhangxuan Gu, Zhengxi Lu, Xuyang Liu, Shuheng Shen, Changhua Meng, Wen Wang, Wenqi Zhang, Yongliang Shen, Weiming Lu, et al. Gui-g2: Gaussian reward modeling for gui grounding. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33214–33222, 2026
work page 2026
-
[33]
LPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Jiaqi Tang, Yu Xia, Yi-Feng Wu, Yuwei Hu, Yuhui Chen, Qing-Guo Chen, Xiaogang Xu, Xiangyu Wu, Hao Lu, Yanqing Ma, et al. Lpo: Towards accurate gui agent interaction via location preference optimization.arXiv preprint arXiv:2506.09373, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Ui-venus-1.5 technical report.arXiv preprint arXiv:2602.09082, 2026
Venus Team, Changlong Gao, Zhangxuan Gu, Yulin Liu, Xinyu Qiu, Shuheng Shen, Yue Wen, Tianyu Xia, Zhenyu Xu, Zhengwen Zeng, et al. Ui-venus-1.5 technical report.arXiv preprint arXiv:2602.09082, 2026
-
[35]
Hao Wang, Hao Gu, Hongming Piao, Kaixiong Gong, Yuxiao Ye, Xiangyu Yue, Sirui Han, Yike Guo, and Dapeng Wu. Learning while staying curious: Entropy-preserving supervised fine- tuning via adaptive self-distillation for large reasoning models.arXiv preprint arXiv:2602.02244, 2026
-
[36]
Wenkai Wang, Xiyun Li, Hongcan Guo, Wenhao Yu, Tianqing Fang, Haitao Mi, Dong Yu, and Shengyu Zhang. Measure twice, click once: Co-evolving proposer and visual critic via reinforcement learning for gui grounding.arXiv preprint arXiv:2604.21268, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Xuehui Wang, Zhenyu Wu, JingJing Xie, Zichen Ding, Bowen Yang, Zehao Li, Zhaoyang Liu, Qingyun Li, Xuan Dong, Zhe Chen, et al. Mmbench-gui: Hierarchical multi-platform evaluation framework for gui agents.arXiv preprint arXiv:2507.19478, 2025
-
[38]
arXiv preprint arXiv:2602.11858 , year=
Lai Wei, Liangbo He, Jun Lan, Lingzhong Dong, Yutong Cai, Siyuan Li, Huijia Zhu, Weiqiang Wang, Linghe Kong, Yue Wang, et al. Zooming without zooming: Region-to-image distillation for fine-grained multimodal perception.arXiv preprint arXiv:2602.11858, 2026
-
[39]
arXiv preprint arXiv:2506.03143 , year=
Qianhui Wu, Kanzhi Cheng, Rui Yang, Chaoyun Zhang, Jianwei Yang, Huiqiang Jiang, Jian Mu, Baolin Peng, Bo Qiao, Reuben Tan, et al. Gui-actor: Coordinate-free visual grounding for gui agents.arXiv preprint arXiv:2506.03143, 2025
-
[40]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents, 2024.URL https://arxiv. org/abs/2410.23218
work page internal anchor Pith review arXiv 2024
-
[42]
Tianbao Xie, Jiaqi Deng, Xiaochuan Li, Junlin Yang, Haoyuan Wu, Jixuan Chen, Wenjing Hu, Xinyuan Wang, Yuhui Xu, Zekun Wang, et al. Scaling computer-use grounding via user interface decomposition and synthesis.arXiv preprint arXiv:2505.13227, 2025
-
[43]
Mobilerl: Online agentic reinforcement learning for mobile gui agents
Yifan Xu, Xiao Liu, Xinghan Liu, Jiaqi Fu, Hanchen Zhang, Bohao Jing, Shudan Zhang, Yuting Wang, Wenyi Zhao, and Yuxiao Dong. Mobilerl: Online agentic reinforcement learning for mobile gui agents.arXiv preprint arXiv:2509.18119, 2025
-
[44]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Yan Yang, Dongxu Li, Yutong Dai, Yuhao Yang, Ziyang Luo, Zirui Zhao, Zhiyuan Hu, Junzhe Huang, Amrita Saha, Zeyuan Chen, et al. Gta1: Gui test-time scaling agent.arXiv preprint arXiv:2507.05791, 2025
-
[48]
Xinbin Yuan, Jian Zhang, Kaixin Li, Zhuoxuan Cai, Lujian Yao, Jie Chen, Enguang Wang, Qibin Hou, Jinwei Chen, Peng-Tao Jiang, et al. Enhancing visual grounding for gui agents via self-evolutionary reinforcement learning.arXiv preprint arXiv:2505.12370, 2025
-
[49]
Fdc-ground: Improving grpo for gui grounding via exponential rewards and fact-aligned pruning
Xiangjian Zeng, Wenjing Li, Qingqiang Wu, and Liang Zhang. Fdc-ground: Improving grpo for gui grounding via exponential rewards and fact-aligned pruning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 28122–28130, 2026
work page 2026
-
[50]
Bofei Zhang, Zirui Shang, Zhi Gao, Wang Zhang, Rui Xie, Xiaojian Ma, Tao Yuan, Xinxiao Wu, Song-Chun Zhu, and Qing Li. Tongui: Building generalized gui agents by learning from multimodal web tutorials.arXiv e-prints, pages arXiv–2504, 2025
work page 2025
-
[51]
Shaojie Zhang, Pei Fu, Ruoceng Zhang, Jiahui Yang, Anan Du, Xiuwen Xi, Shaokang Wang, Ying Huang, Bin Qin, Zhenbo Luo, et al. Hyperclick: Advancing reliable gui grounding via uncertainty calibration.arXiv preprint arXiv:2510.27266, 2025
-
[52]
Btl-ui: Blink-think-link reasoning model for gui agent
Shaojie Zhang, Ruoceng Zhang, Pei Fu, Shaokang Wang, Jiahui Yang, Xin Du, Shiqi Cui, Bin Qin, Ying Huang, Zhenbo Luo, et al. Btl-ui: Blink-think-link reasoning model for gui agent. arXiv preprint arXiv:2509.15566, 2025
-
[53]
OPSDL: On-Policy Self-Distillation for Long-Context Language Models
Xinsen Zhang, Zhenkai Ding, Tianjun Pan, Run Yang, Chun Kang, Xue Xiong, and Jingnan Gu. Opsdl: On-policy self-distillation for long-context language models.arXiv preprint arXiv:2604.17535, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Co- epg: A framework for co-evolution of planning and grounding in autonomous gui agents
Yuan Zhao, Hualei Zhu, Tingyu Jiang, Shen Li, Xiaohang Xu, and Hao Henry Wang. Co- epg: A framework for co-evolution of planning and grounding in autonomous gui agents. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 36582–36590, 2026
work page 2026
-
[55]
Yuqi Zhou, Sunhao Dai, Shuai Wang, Kaiwen Zhou, Qinglin Jia, and Jun Xu. Gui-g1: Understanding r1-zero-like training for visual grounding in gui agents.arXiv preprint arXiv:2505.15810, 2025. 13 Appendix The appendix includes the following aspects: • Appendix A: Evaluation Benchmarks. • Appendix B: Training Details. • Appendix C: Additional Experiments and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.