Human Universal Grasping
Pith reviewed 2026-06-27 03:49 UTC · model grok-4.3
The pith
A flow-matching model generates natural human grasps from single RGB-D images after training on a million-frame egocentric dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
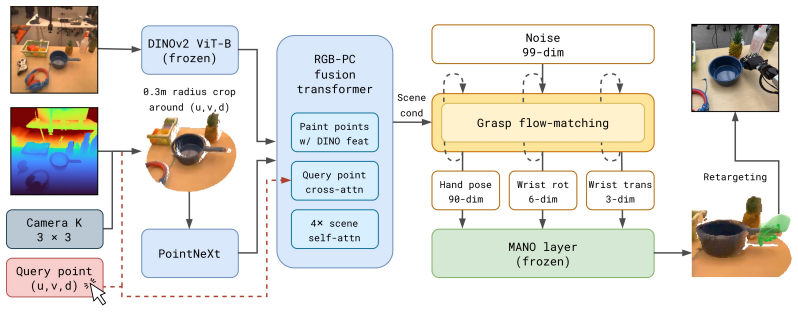
HUG is a flow-matching model that fuses RGB and depth from a stereo camera to generate grasps parameterized by wrist translation, wrist rotation, and MANO hand pose. Trained on the 1M-HUGs dataset of 1M frames and 6707 object instances, it produces diverse grasps that transfer to various robot embodiments for zero-shot grasping in real environments.
What carries the argument
flow-matching model that fuses RGB and depth observations to output a grasp parameterized by wrist translation, wrist rotation, and MANO hand pose
If this is right
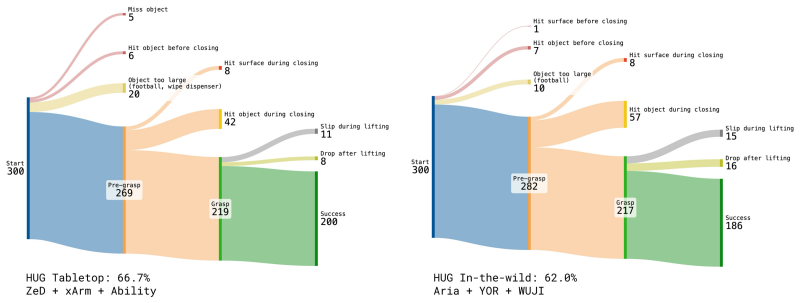
- HUG enables zero-shot grasping in everyday scenes across multiple robot hands and household environments.
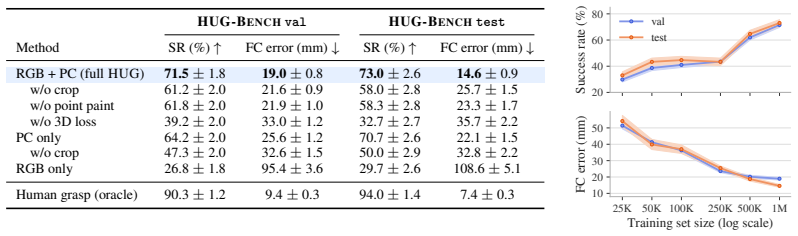
- The approach outperforms state-of-the-art grasping baselines by 23% and 34% on a challenging object set.
- A new simulated benchmark HUG-Bench with 90 unseen objects standardizes evaluation of grasp generation methods.
- Predicted grasps from the model can be retargeted to various robot hands.
Where Pith is reading between the lines
- This suggests that large-scale human egocentric data can provide a more general distribution of grasps than synthetic or limited datasets.
- Future work could extend the model to dynamic scenes or multi-object interactions by collecting additional egocentric data.
- Retargeting success implies that human grasp distributions are transferable across different hand morphologies with appropriate mapping.
- The use of flow-matching indicates that modeling grasp distributions as continuous flows may capture natural variability better than discrete sampling methods.
Load-bearing premise
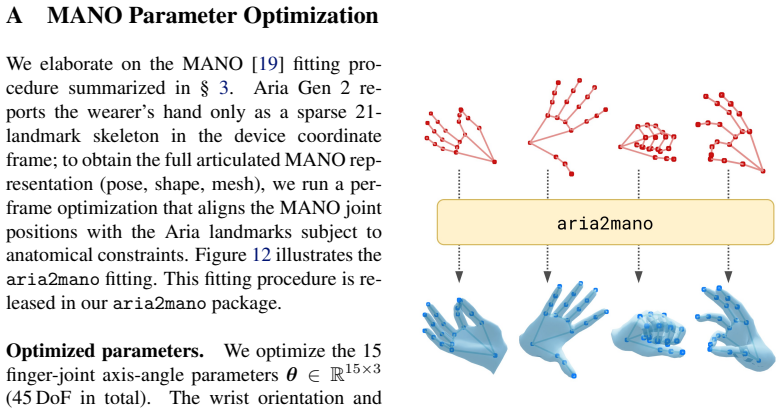
The 1M-frame egocentric dataset collected via smart glasses is representative of the full distribution of natural human grasps across object geometries, sizes, and everyday scenes without significant selection or recording bias.
What would settle it
Evaluating the model on a set of objects and scenes deliberately chosen to be outside the distribution of the 1M-HUGs dataset, such as rare geometries or unusual environments, and checking if the performance advantage over baselines disappears.
Figures














read the original abstract
Humans can grasp objects effortlessly, whereas multi-fingered robots are far from this level of generality. We argue that the most natural source of robot grasping data is from humans, who pick up thousands of objects every day. We present HUG, a flow-matching model that generates diverse human grasps for any user-specified object in a single RGB-D image captured from a stereo camera. Using smart glasses, we first collect 1M-HUGs, an egocentric dataset of human grasps spanning 1M frames (27.8 hrs) and 6,707 object instances across 41 buildings. Next, to model the distribution of natural human grasps, our novel flow-matching model fuses RGB and depth observations to output a grasp parameterized by wrist translation, wrist rotation, and MANO hand pose. Predicted grasps can be retargeted to various robot hands, enabling zero-shot grasping in everyday scenes. To standardize evaluation, we build a new simulated benchmark, HUG-Bench, of 90 unseen objects from five geometric categories and various sizes, with metric-scale 3D meshes. We evaluate HUG in the real world on the 30-object test set of HUG-Bench across multiple stereo cameras, robot embodiments, and household environments. HUG outperforms the state-of-the-art grasping baselines by +23% and +34% on our challenging object set. Code, data, benchmark, checkpoints, and an interactive demo are released on our website: https://grasping.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HUG, a flow-matching model trained on the new 1M-HUGs egocentric dataset (1M frames, 6,707 instances) collected via smart glasses to generate diverse human grasps (wrist pose + MANO parameters) from a single RGB-D image. Grasps are retargeted to robot hands for zero-shot use. A new simulated benchmark HUG-Bench (90 unseen objects, five geometric categories) and a 30-object real-world test set are introduced; HUG is reported to outperform SOTA baselines by +23% and +34%. Code, data, benchmark, and checkpoints are released.
Significance. If the generalization claims hold after addressing evaluation gaps, the work offers a scalable route to natural grasp distributions from everyday human data, with potential impact on multi-fingered robotic grasping generality. The public release of the 1M-HUGs dataset, HUG-Bench meshes, model checkpoints, and interactive demo is a clear strength for reproducibility and follow-on research.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: The +23% and +34% outperformance claims on HUG-Bench and the real-world 30-object set supply no information on the exact success metric (e.g., grasp success rate definition, contact thresholds), baseline implementations, statistical significance testing, or controls for data leakage between the 6,707 training instances and the 90 test objects.
- [Dataset / Experiments] Dataset collection and evaluation sections: The central generalization claim rests on the assumption that the smart-glasses egocentric protocol yields an unbiased sample of natural grasps; however, no quantitative validation (grasp-type histograms, object-size coverage statistics, or direct comparison against third-party human grasp datasets) is reported to rule out systematic biases in wrist orientation, visibility, or object selection.
minor comments (1)
- [Abstract] The abstract refers to 'our challenging object set' without a forward reference to the precise composition of the 90-object HUG-Bench or the 30-object real-world subset.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The +23% and +34% outperformance claims on HUG-Bench and the real-world 30-object set supply no information on the exact success metric (e.g., grasp success rate definition, contact thresholds), baseline implementations, statistical significance testing, or controls for data leakage between the 6,707 training instances and the 90 test objects.
Authors: We agree these details are essential. In the revised manuscript we will explicitly define the grasp success metric (percentage of grasps maintaining stable contact without slippage under gravity for 5 seconds, with 0.01 m penetration threshold) in the Experiments section. Baseline implementations and any adaptations will be detailed with hyperparameters. Statistical significance will be reported via paired tests with p-values. We will add an explicit statement confirming the 90 test objects are disjoint from the 6,707 training instances (collected in separate sessions and buildings) along with supporting evidence. revision: yes
-
Referee: [Dataset / Experiments] Dataset collection and evaluation sections: The central generalization claim rests on the assumption that the smart-glasses egocentric protocol yields an unbiased sample of natural grasps; however, no quantitative validation (grasp-type histograms, object-size coverage statistics, or direct comparison against third-party human grasp datasets) is reported to rule out systematic biases in wrist orientation, visibility, or object selection.
Authors: We acknowledge the value of such validation. The revised version will include grasp-type histograms derived from MANO parameters and object-size coverage statistics for the 1M-HUGs dataset. Direct quantitative comparisons against third-party datasets require aligning incompatible capture protocols and taxonomies and are not feasible without substantial new effort; we will discuss this limitation and describe how the multi-building, everyday-environment protocol was designed to reduce bias. revision: partial
Circularity Check
No significant circularity
full rationale
The paper collects an external egocentric dataset (1M-HUGs) via smart glasses, trains a flow-matching model on it to predict grasp parameters from RGB-D input, and evaluates generalization on held-out objects in a newly constructed benchmark (HUG-Bench) plus real-world tests. No equations, parameters, or claims reduce the reported performance gains to quantities defined by the same fitted values or self-citations; the central results rest on standard supervised learning from independent data with external baselines. Dataset representativeness is an empirical assumption, not a definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- flow-matching model parameters
axioms (1)
- domain assumption Egocentric RGB-D frames from smart glasses capture the natural distribution of human grasps without major bias from recording setup or participant behavior.
Reference graph
Works this paper leans on
-
[1]
R. Wang, J. Zhang, J. Chen, Y . Xu, P. Li, T. Liu, and H. Wang. Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation, 2023. URLhttps: //arxiv.org/abs/2210.02697
arXiv 2023
-
[2]
H.-S. Fang, H. Yan, Z. Tang, H. Fang, C. Wang, and C. Lu. Anydexgrasp: General dexter- ous grasping for different hands with human-level learning efficiency, 2025. URLhttps: //arxiv.org/abs/2502.16420
arXiv 2025
-
[3]
J. Ye, K. Wang, C. Yuan, R. Yang, Y . Li, J. Zhu, Y . Qin, X. Zou, and X. Wang. Dex1b: Learning with 1b demonstrations for dexterous manipulation, 2025. URLhttps://arxiv.org/abs/ 2506.17198
arXiv 2025
-
[4]
Y . Xu, W. Wan, J. Zhang, H. Liu, Z. Shan, H. Shen, R. Wang, H. Geng, Y . Weng, J. Chen, T. Liu, L. Yi, and H. Wang. Unidexgrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy, 2023. URLhttps://arxiv.org/ abs/2303.00938
arXiv 2023
-
[5]
H. Chen, Y . Yao, Y . Ye, Z. Xu, H. Bharadhwaj, J. Wang, S. Tulsiani, Z. Erickson, and J. Ich- nowski. Web2grasp: Learning functional grasps from web images of hand-object interactions. arXiv preprint arXiv:2505.05517, 2025
arXiv 2025
-
[6]
Gupta, M
H. Gupta, M. A. Mirzaee, and W. Yuan. Grasp to act: Dexterous grasping for tool use in dynamic settings.IEEE Robotics and Automation Letters, 11(5):6288–6295, 2026
2026
-
[7]
A. Iyer, Z. Peng, Y . Dai, I. Guzey, S. Haldar, S. Chintala, and L. Pinto. Open teach: A versatile teleoperation system for robotic manipulation. InConference on Robot Learning (CoRL), 2024
2024
-
[8]
S. P. Arunachalam, I. G ¨uzey, S. Chintala, and L. Pinto. Holo-dex: Teaching dexterity with im- mersive mixed reality. InIEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[9]
R. Ding, Y . Qin, J. Zhu, C. Jia, S. Yang, R. Yang, X. Qi, and X. Wang. Bunny-VisionPro: Real- time bimanual dexterous teleoperation for imitation learning, 2024. URLhttps://arxiv. org/abs/2407.03162
arXiv 2024
-
[10]
Y . Qin, W. Yang, B. Huang, K. Van Wyk, H. Su, X. Wang, Y .-W. Chao, and D. Fox. AnyTeleop: A general vision-based dexterous robot arm-hand teleoperation system. InRobotics: Science and Systems (RSS), 2023
2023
-
[11]
Project Aria Gen 2.https://facebookresearch.github
Meta Reality Labs Research. Project Aria Gen 2.https://facebookresearch.github. io/projectaria_tools/gen2/, 2026. Accessed: 2026-06-15
2026
- [12]
-
[13]
Ability Hand.https://www.psyonic.io/ability-hand, 2026
Psyonic. Ability Hand.https://www.psyonic.io/ability-hand, 2026. Accessed: 2026- 06-15
2026
-
[14]
K. Shaw, A. Agarwal, and D. Pathak. LEAP Hand: Low-cost, efficient, and anthropomorphic hand for robot learning. InRobotics: Science and Systems (RSS), 2023
2023
-
[15]
WUJI Hand.https://docs.wuji.tech/docs/en/wuji-hand/v1/,
WUJI Technology. WUJI Hand.https://docs.wuji.tech/docs/en/wuji-hand/v1/,
-
[16]
Accessed: 2026-06-15
2026
- [17]
-
[18]
K. Li, P. Li, T. Liu, Y . Li, and S. Huang. Maniptrans: Efficient dexterous bimanual manipula- tion transfer via residual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6991–7003, 2025
2025
-
[19]
He and W
G. He and W. Zhang. Wujihand retargeting.https://github.com/wuji-technology/ wuji-retargeting, 2026. Accessed: 2026-06-15
2026
-
[20]
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: modeling and capturing hands and bodies together.ACM Transactions on Graphics, 36(6):1–17, Nov. 2017. ISSN 1557-7368. doi:10.1145/3130800.3130883. URLhttp://dx.doi.org/10.1145/3130800.3130883
-
[21]
L. Pinto and A. Gupta. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours, 2015. URLhttps://arxiv.org/abs/1509.06825
Pith/arXiv arXiv 2015
-
[22]
H.-S. Fang, C. Wang, M. Gou, and C. Lu. Graspnet-1billion: A large-scale benchmark for gen- eral object grasping. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 11441–11450, 2020. doi:10.1109/CVPR42600.2020.01146
-
[23]
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu. Anygrasp: Robust and efficient grasp perception in spatial and temporal domains, 2023. URLhttps: //arxiv.org/abs/2212.08333
arXiv 2023
-
[24]
Mousavian, C
A. Mousavian, C. Eppner, and D. Fox. 6-dof graspnet: Variational grasp generation for object manipulation. InProceedings of the IEEE/CVF international conference on computer vision, pages 2901–2910, 2019
2019
-
[25]
Sundermeyer, A
M. Sundermeyer, A. Mousavian, R. Triebel, and D. Fox. Contact-graspnet: Efficient 6-dof grasp generation in cluttered scenes. In2021 IEEE international conference on robotics and automation (ICRA), pages 13438–13444. IEEE, 2021
2021
-
[26]
N. Chavan-Dafle, S. Popovych, S. Agrawal, D. D. Lee, and V . Isler. Simultaneous object reconstruction and grasp prediction using a camera-centric object shell representation, 2022. URLhttps://arxiv.org/abs/2109.06837
arXiv 2022
-
[27]
P. Liu, Y . Orru, J. Vakil, C. Paxton, N. Shafiullah, and L. Pinto. Demonstrating ok-robot: What really matters in integrating open-knowledge models for robotics. InRobotics: Science and Systems XX, RSS2024. Robotics: Science and Systems Foundation, July 2024. doi:10.15607/ rss.2024.xx.091. URLhttp://dx.doi.org/10.15607/RSS.2024.XX.091
-
[28]
Z. J. Cui, O. Rayyan, H. Etukuru, B. Tan, Z. Andrianarivo, Z. Teng, Y . Zhou, K. Mehta, N. Wojno, K. Y . Wu, M. H. Anjaria, Z. Wu, M. Mao, G. Zhang, B. Shah, Y . Kim, S. Chintala, L. Pinto, and N. M. M. Shafiullah. Contact-anchored policies: Contact conditioning creates strong robot utility models, 2026. URLhttps://arxiv.org/abs/2602.09017
arXiv 2026
-
[29]
T. G. W. Lum, M. Matak, V . Makoviychuk, A. Handa, A. Allshire, T. Hermans, N. D. Ratliff, and K. V . Wyk. DextrAH-g: Pixels-to-action dexterous arm-hand grasping with geometric fabrics. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview. net/forum?id=S2Jwb0i7HN. 12
2024
- [30]
-
[31]
Christen, M
S. Christen, M. Kocabas, E. Aksan, J. Hwangbo, J. Song, and O. Hilliges. D-grasp: Phys- ically plausible dynamic grasp synthesis for hand-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20577–20586, 2022
2022
-
[32]
W. Wan, H. Geng, Y . Liu, Z. Shan, Y . Yang, L. Yi, and H. Wang. Unidexgrasp++: Improving dexterous grasping policy learning via geometry-aware curriculum and iterative generalist- specialist learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3891–3902, 2023
2023
- [33]
-
[34]
J. Lu, H. Kang, H. Li, B. Liu, Y . Yang, Q. Huang, and G. Hua.UGG: Unified Generative Grasping, page 414–433. Springer Nature Switzerland, Nov. 2024. ISBN 9783031728556. doi:10.1007/978-3-031-72855-6 24. URLhttp://dx.doi.org/10. 1007/978-3-031-72855-6_24
-
[35]
Etukuru, N
H. Etukuru, N. Naka, Z. Hu, S. Lee, J. Mehu, A. Edsinger, C. Paxton, S. Chintala, L. Pinto, and N. M. M. Shafiullah. Robot utility models: General policies for zero-shot deployment in new environments. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8275–8283. IEEE, 2025
2025
-
[36]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
Pith/arXiv arXiv 2024
-
[37]
M. Xu, H. Zhang, Y . Hou, Z. Xu, L. Fan, M. Veloso, and S. Song. Dexumi: Using hu- man hand as the universal manipulation interface for dexterous manipulation.arXiv preprint arXiv:2505.21864, 2025
arXiv 2025
- [38]
-
[39]
Guzey, Y
I. Guzey, Y . Dai, G. Savva, R. Bhirangi, and L. Pinto. Bridging the human to robot dexterity gap through object-oriented rewards. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3344–3351. IEEE, 2025
2025
-
[40]
Karaev, I
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rupprecht. Cotracker: It is better to track together. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[41]
C. Doersch, Y . Yang, M. Vecerik, D. Gokay, A. Gupta, Y . Aytar, J. Carreira, and A. Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement, 2023. URL https://arxiv.org/abs/2306.08637
arXiv 2023
-
[42]
Y . Ye, P. Hebbar, A. Gupta, and S. Tulsiani. Diffusion-guided reconstruction of everyday hand-object interaction clips. InProceedings of the IEEE/CVF international conference on computer vision, pages 19717–19728, 2023
2023
-
[43]
Pavlakos, D
G. Pavlakos, D. Shan, I. Radosavovic, A. Kanazawa, D. Fouhey, and J. Malik. Reconstructing hands in 3d with transformers. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 13
2024
-
[44]
Y . Ye, X. Li, A. Gupta, S. De Mello, S. Birchfield, J. Song, S. Tulsiani, and S. Liu. Affordance diffusion: Synthesizing hand-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22479–22489, 2023
2023
-
[45]
S. Park, H. Bharadhwaj, and S. Tulsiani. Demodiffusion: One-shot human imitation using pre-trained diffusion policy, 2025. URLhttps://arxiv.org/abs/2506.20668
arXiv 2025
-
[46]
S. Haldar and L. Pinto. Point policy: Unifying observations and actions with key points for robot manipulation.arXiv preprint arXiv:2502.20391, 2025
arXiv 2025
-
[47]
C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y . Zhu, and A. Anandkumar. Mimicplay: Long-horizon imitation learning by watching human play.arXiv preprint arXiv:2302.12422, 2023
arXiv 2023
-
[48]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[49]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[50]
K. Shaw, S. Bahl, and D. Pathak. Videodex: Learning dexterity from internet videos. In Conference on Robot Learning (CoRL), 2023
2023
-
[51]
J. Shi, Z. Zhao, T. Wang, I. Pedroza, A. Luo, J. Wang, J. Ma, and D. Jayaraman. Ze- romimic: Distilling robotic manipulation skills from web videos. InInternational Conference on Robotics and Automation (ICRA), 2025
2025
-
[52]
M. K. Srirama, S. Dasari, S. Bahl, and A. Gupta. Hrp: Human affordances for robotic pre- training. InRobotics: Science and Systems (RSS), 2024
2024
-
[53]
T. Tao, M. K. Srirama, J. J. Liu, K. Shaw, and D. Pathak. Dexwild: Dexterous human interac- tions for in-the-wild robot policies.arXiv preprint arXiv:2505.07813, 2025
Pith/arXiv arXiv 2025
-
[54]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
Pith/arXiv arXiv 2026
-
[55]
J. Engel, K. Somasundaram, M. Goesele, A. Sun, A. Gamino, A. Turner, A. Talattof, A. Yuan, B. Souti, B. Meredith, et al. Project aria: A new tool for egocentric multi-modal ai research. arXiv preprint arXiv:2308.13561, 2023
Pith/arXiv arXiv 2023
-
[56]
V . Liu, A. Adeniji, H. Zhan, R. Bhirangi, P. Abbeel, and L. Pinto. Egozero: Robot learning from smart glasses, 2025. URLhttps://arxiv.org/abs/2505.20290
arXiv 2025
- [57]
-
[58]
Y .-W. Chao, W. Yang, Y . Xiang, P. Molchanov, A. Handa, J. Tremblay, Y . S. Narang, K. Van Wyk, U. Iqbal, S. Birchfield, J. Kautz, and D. Fox. DexYCB: A benchmark for cap- turing hand grasping of objects. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9044–9053, 2021
2021
-
[59]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. R¨adle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y . Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Doll ´ar, N. Ravi, K. ...
Pith/arXiv arXiv 2026
-
[60]
J. Min, Y . Jeon, J. Kim, and M. Choi. S2M2: Scalable stereo matching model for reliable depth estimation, 2025. URLhttps://arxiv.org/abs/2507.13229
arXiv 2025
-
[61]
L. Yang, X. Zhan, K. Li, W. Xu, J. Li, and C. Lu. CPF: Learning a contact potential field to model the hand-object interaction. InICCV, 2021
2021
-
[62]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753, 2019
2019
-
[63]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[64]
Darcet, M
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision transformers need registers. In International Conference on Learning Representations (ICLR), 2024
2024
-
[65]
G. Qian, Y . Li, H. Peng, J. Mai, H. Hammoud, M. Elhoseiny, and B. Ghanem. PointNeXt: Revisiting PointNet++ with improved training and scaling strategies. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[66]
Tancik, P
M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ra- mamoorthi, J. T. Barron, and R. Ng. Fourier features let networks learn high frequency func- tions in low dimensional domains. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[67]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InIEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 4195–4205, 2023
2023
-
[68]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. MuJoCo: A physics engine for model-based control. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5026– 5033, 2012
2012
-
[69]
B. Li, D. Wu, J. Li, S. Zhou, Z. Zeng, L. Li, and H. Zha. Mv-sam3d: Adaptive multi-view fusion for layout-aware 3d generation, 2026. URLhttps://arxiv.org/abs/2603.11633
Pith/arXiv arXiv 2026
-
[70]
B. Yi, C. M. Kim, J. Kerr, G. Wu, R. Feng, A. Zhang, J. Kulhanek, H. Choi, Y . Ma, M. Tancik, and A. Kanazawa. Viser: Imperative, web-based 3d visualization in python, 2025. URL https://arxiv.org/abs/2507.22885
arXiv 2025
-
[71]
C. Portaneri, M. Rouxel-Labb ´e, M. Hemmer, D. Cohen-Steiner, and P. Alliez. Alpha wrapping with an offset.ACM Trans. Graph., 41(4), July 2022. ISSN 0730-0301. doi:10.1145/3528223. 3530152. URLhttps://doi.org/10.1145/3528223.3530152
-
[72]
X. Wei, M. Liu, Z. Ling, and H. Su. Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search.ACM Transactions on Graphics (TOG), 41(4):1–18, 2022
2022
-
[73]
Project aria gen 2 mps performance benchmarks.https: //facebookresearch.github.io/projectaria_tools/gen2/technical-specs/ mps/benchmarks/performance, 2025
Meta Reality Labs Research. Project aria gen 2 mps performance benchmarks.https: //facebookresearch.github.io/projectaria_tools/gen2/technical-specs/ mps/benchmarks/performance, 2025. Accessed: 2026-06-14
2025
-
[74]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[75]
xArm 7.https://www.ufactory.us/product/ufactory-xarm-7, 2026
UFACTORY. xArm 7.https://www.ufactory.us/product/ufactory-xarm-7, 2026. Accessed: 2026-06-15
2026
-
[76]
M. H. Anjaria, M. E. Erciyes, V . Ghatnekar, N. Navarkar, H. Etukuru, X. Jiang, K. Patel, D. Kabra, N. Wojno, R. A. Prayage, S. Chintala, L. Pinto, N. M. M. Shafiullah, and Z. J. Cui. Yor: Your own mobile manipulator for generalizable robotics, 2026. URLhttps://arxiv. org/abs/2602.11150
arXiv 2026
-
[77]
NERO.https://global.agilex.ai/products/nero, 2026
AgileX Robotics. NERO.https://global.agilex.ai/products/nero, 2026. Accessed: 2026-06-15
2026
-
[78]
Gyenes, E
B. Gyenes, E. Gospodinov, J. Frieling, E. Krohmer, N. Schreiber, X. Jia, N. Freymuth, and G. Neumann. Fourier features let agents learn high precision policies with imitation learning,
-
[79]
URLhttps://arxiv.org/abs/2606.12334
-
[80]
S. D. Team, X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, X. Li, A. Lin, J. Liu, Z. Ma, A. Sagar, B. Song, X. Wang, J. Yang, B. Zhang, P. Doll´ar, G. Gkioxari, M. Feiszli, and J. Malik. Sam 3d: 3dfy anything in images, 2026. URL https://arxiv.org/abs/2511.16624
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.