LLM-Guided Neural Architecture Search for Robust Co-Design of Physical Neural Networks
Pith reviewed 2026-06-27 13:44 UTC · model grok-4.3
The pith
UH-NAS uses language models as evolutionary operators in a hardware-agnostic search to co-optimize neural network accuracy and energy on physical platforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
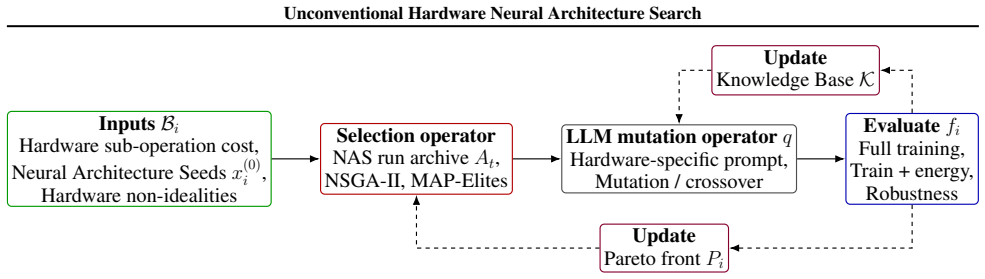
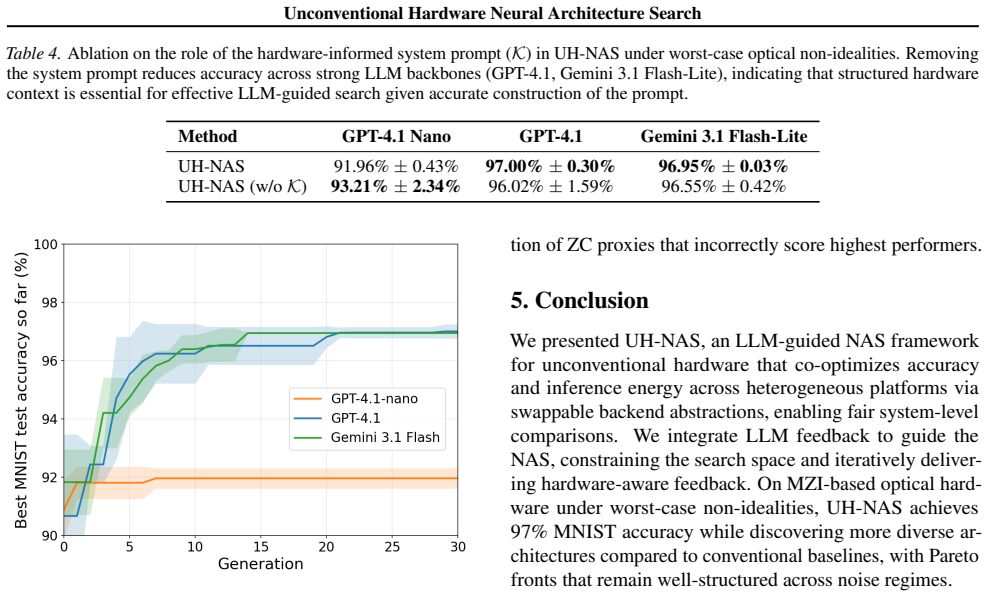
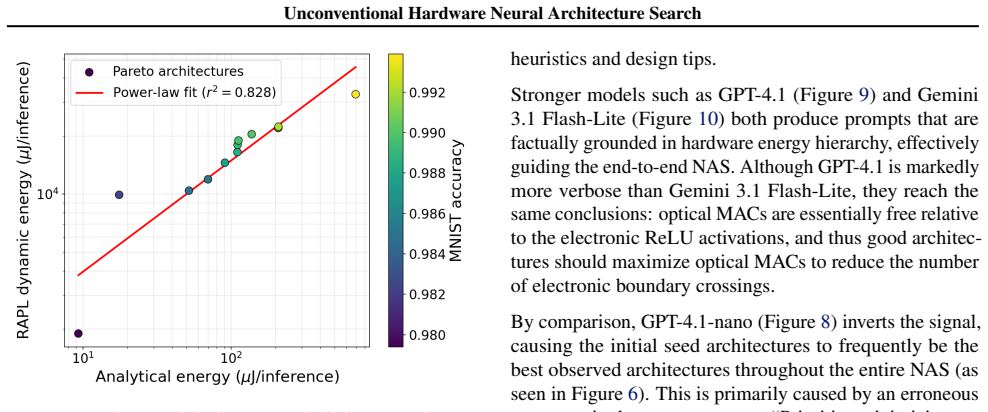
UH-NAS is a hardware-agnostic NAS framework that integrates language models as evolutionary operators to co-optimize accuracy and inference energy. Hardware is exposed as a swappable backend equipped with per-platform energy models, physical constraints, and non-ideality simulators, so the same search procedure works across backends. When tested on optical MZI hardware, UH-NAS produces architectures that are more diverse and robust to non-idealities than conventional baselines while also outperforming existing LLM-to-NAS methods.
What carries the argument
Unconventional Hardware Neural Architecture Search (UH-NAS) framework, in which LLMs act as evolutionary operators and hardware is handled through interchangeable energy models and non-ideality simulators.
If this is right
- The identical search procedure can be applied to multiple hardware platforms by swapping only the backend models, enabling fair cross-platform comparisons.
- Discovered architectures show improved robustness when non-idealities such as noise or precision loss are present.
- Performance exceeds both conventional NAS methods and earlier LLM-guided NAS techniques on the evaluated optical platform.
- Co-design of architecture with hardware-specific constraints becomes feasible without rewriting the search algorithm for each new platform.
Where Pith is reading between the lines
- The approach could shorten the time needed to adapt neural networks to newly emerging hardware technologies by reusing the same search logic.
- If simulator fidelity improves, the method might produce designs that transfer to physical devices with little additional fine-tuning.
- Similar LLM-driven evolutionary search might be applied to related co-design problems such as circuit layout or sensor placement.
Load-bearing premise
The per-platform energy models and non-ideality simulators must accurately capture real hardware behavior so that architectures found in simulation remain robust when transferred to physical devices.
What would settle it
Deploying the architectures discovered by UH-NAS on actual optical MZI hardware and checking whether they exhibit measurably higher robustness to real non-idealities and greater architectural diversity than the baselines.
Figures



read the original abstract
Deploying neural networks on unconventional hardware demands architectures that co-optimize task accuracy and platform-specific constraints such as energy cost, physical non-idealities, and numerical precision. Existing neural architecture search (NAS) methods are typically tailored to a single hardware family, limiting cross-platform comparison and generalization. We introduce Unconventional Hardware Neural Architecture Search (UH-NAS), a hardware-agnostic, LLM-guided NAS framework that integrates language models as evolutionary operators to co-optimize accuracy and inference energy. By exposing hardware as a swappable backend with per-platform energy models, physical constraints, and non-ideality simulators, UH-NAS enables fair system-level comparisons across various backends without modifying the search algorithm. Tested on optical MZI hardware, UH-NAS discovers more diverse, robust architectures than conventional baselines while outperforming existing LLM-to-NAS approaches. Additional ablations on architecture robustness under non-idealities and the role of system prompts highlight the importance of architecture-hardware co-design for emerging computing platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Unconventional Hardware Neural Architecture Search (UH-NAS), a hardware-agnostic LLM-guided NAS framework that uses language models as evolutionary operators to co-optimize task accuracy and inference energy across swappable hardware backends. Each backend supplies per-platform energy models, physical constraints, and non-ideality simulators, enabling cross-platform comparisons without altering the search algorithm. Evaluated on optical MZI hardware, the method is claimed to yield more diverse and robust architectures than conventional NAS baselines and prior LLM-to-NAS approaches, with supporting ablations on non-ideality robustness and system-prompt effects.
Significance. If the empirical claims are substantiated by quantitative results, the work could advance hardware-aware NAS for emerging physical platforms by demonstrating a unified search procedure that incorporates platform-specific non-idealities while remaining algorithmically hardware-agnostic.
minor comments (1)
- [Abstract] The abstract reports outperformance and robustness ablations but supplies no quantitative results, error bars, dataset sizes, or statistical tests.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for noting the potential significance of UH-NAS for hardware-aware NAS on unconventional platforms. The recommendation is listed as uncertain, yet the report contains no specific major comments to address. We remain available to provide additional quantitative details, ablations, or clarifications on the empirical claims if requested by the editor or referee.
Circularity Check
No significant circularity
full rationale
The paper introduces UH-NAS as an LLM-guided NAS framework with swappable hardware backends for co-optimizing accuracy and energy. All central claims rest on empirical comparisons of discovered architectures against baselines on optical MZI models, with no equations, fitted parameters, or derivations presented that reduce to self-definition, renamed inputs, or self-citation chains. The method treats energy models and simulators as external oracles and reports search outcomes under that assumption; the argument does not contain any load-bearing step that is equivalent to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural architecture search: A survey.Journal of Machine Learning Research, 20(55):1–21, 2019
Thomas Elsken, Jan Hendrik Metzen, and Frank Hut- ter. Neural architecture search: A survey.Journal of Machine Learning Research, 20(55):1–21, 2019
2019
-
[2]
Mnasnet: Platform-aware neural architecture search for mobile
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Va- sudevan, Mark Sandler, Andrew Howard, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 2820–2828, 2019
2019
-
[3]
Hw-nas-bench: Hardware-aware neural architecture search benchmark
Chaojian Li, Zhongzhi Yu, Yonggan Fu, Yongan Zhang, Yang Zhao, Haoran You, Qixuan Yu, Yue Wang, and Yingyan Celine Lin. Hw-nas-bench: Hardware-aware neural architecture search benchmark. arXiv preprint arXiv:2103.10584, 2021
-
[4]
Flash: F ast neura l a rchitecture s earch with h ardware optimization.ACM Transactions on Embedded Computing Systems (TECS), 20(5s):1– 26, 2021
Guihong Li, Sumit K Mandal, Umit Y Ogras, and Radu Marculescu. Flash: F ast neura l a rchitecture s earch with h ardware optimization.ACM Transactions on Embedded Computing Systems (TECS), 20(5s):1– 26, 2021
2021
-
[5]
Device- circuit-architecture co-exploration for computing-in- memory neural accelerators.IEEE Transactions on Computers, 70(4):595–605, 2020
Weiwen Jiang, Qiuwen Lou, Zheyu Yan, Lei Yang, Jingtong Hu, Xiaobo Sharon Hu, and Yiyu Shi. Device- circuit-architecture co-exploration for computing-in- memory neural accelerators.IEEE Transactions on Computers, 70(4):595–605, 2020
2020
-
[6]
Nas4rram: neural network architec- ture search for inference on rram-based accelerators
Zhihang Yuan, Jingze Liu, Xingchen Li, Longhao Yan, Haoxiang Chen, Bingzhe Wu, Yuchao Yang, and Guangyu Sun. Nas4rram: neural network architec- ture search for inference on rram-based accelerators. Science China Information Sciences, 64(6):160407, 2021
2021
-
[7]
Chuteng Zhou, Fernando Garcia Redondo, Ju- lian B ¨uchel, Irem Boybat, Xavier Timoneda Co- mas, SR Nandakumar, Shidhartha Das, Abu Sebas- tian, Manuel Le Gallo, and Paul N Whatmough. Analognets: Ml-hw co-design of noise-robust tinyml models and always-on analog compute-in-memory ac- celerator.arXiv preprint arXiv:2111.06503, 2021
-
[8]
Nax: neural architecture and mem- ristive xbar based accelerator co-design
Shubham Negi, Indranil Chakraborty, Aayush Ankit, and Kaushik Roy. Nax: neural architecture and mem- ristive xbar based accelerator co-design. InProceed- ings of the 59th ACM/IEEE Design Automation Con- ference, pages 451–456, 2022
2022
-
[9]
Aniss Bessalah, Hatem Mohamed Abdelmoumen, Karima Benatchba, and Hadjer Benmeziane. Analognas-bench: A nas benchmark for analog in- memory computing.arXiv preprint arXiv:2506.18495, 2025
-
[10]
Analognas: A neural network design framework for accurate inference with analog in-memory computing
Hadjer Benmeziane, Corey Lammie, Irem Boybat, Malte Rasch, Manuel Le Gallo, Hsinyu Tsai, Ra- machandran Muralidhar, Smail Niar, Ouarnoughi Hamza, Vijay Narayanan, et al. Analognas: A neural network design framework for accurate inference with analog in-memory computing. In2023 IEEE Interna- tional Conference on Edge Computing and Communi- cations (EDGE), ...
2023
-
[11]
Uncertainty modeling of emerging device based computing-in-memory neural accelerators with application to neural architecture search
Zheyu Yan, Da-Cheng Juan, Xiaobo Sharon Hu, and Yiyu Shi. Uncertainty modeling of emerging device based computing-in-memory neural accelerators with application to neural architecture search. InProceed- ings of the 26th Asia and South Pacific Design Automa- tion Conference, pages 859–864, 2021
2021
-
[12]
Xplorenas: Explore adversar- ially robust and hardware-efficient neural architectures for non-ideal xbars.ACM Transactions on Embedded Computing Systems, 22(4):1–17, 2023
Abhiroop Bhattacharjee, Abhishek Moitra, and Priyadarshini Panda. Xplorenas: Explore adversar- ially robust and hardware-efficient neural architectures for non-ideal xbars.ACM Transactions on Embedded Computing Systems, 22(4):1–17, 2023
2023
-
[13]
Quan- tumnas: Noise-adaptive search for robust quantum circuits
Hanrui Wang, Yongshan Ding, Jiaqi Gu, Yujun Lin, David Z Pan, Frederic T Chong, and Song Han. Quan- tumnas: Noise-adaptive search for robust quantum circuits. In2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 692–708. IEEE, 2022
2022
-
[14]
Adept: Automatic differentiable design of photonic tensor cores
Jiaqi Gu, Hanqing Zhu, Chenghao Feng, Zixuan Jiang, Mingjie Liu, Shuhan Zhang, Ray T Chen, and David Z Pan. Adept: Automatic differentiable design of photonic tensor cores. InProceedings of the 59th ACM/IEEE Design Automation Conference, pages 937– 942, 2022
2022
-
[15]
Harris, Scott Skirlo, Mihika Prabhu, Tom Baehr-Jones, Michael Hochberg, Xin Sun, Shijie Zhao, Hugo Larochelle, Dirk Englund, and Marin Soljaˇci´c
Yichen Shen, Nicholas C. Harris, Scott Skirlo, Mihika Prabhu, Tom Baehr-Jones, Michael Hochberg, Xin Sun, Shijie Zhao, Hugo Larochelle, Dirk Englund, and Marin Soljaˇci´c. Deep learning with coherent nanopho- tonic circuits.Nature Photonics, 11(7):441–446, 2017
2017
-
[16]
Large-scale optical neural networks based on photoelectric multiplication
Ryan Hamerly, Liane Bernstein, Alexander Sludds, Marin Soljaˇci´c, and Dirk Englund. Large-scale optical neural networks based on photoelectric multiplication. Physical Review X, 9(2), 2019
2019
-
[17]
Photonics for artificial intelligence and neuromorphic computing
Bhavin J Shastri, Alexander N Tait, Thomas Fer- reira de Lima, Wolfram HP Pernice, Harish Bhaskaran, C David Wright, and Paul R Prucnal. Photonics for artificial intelligence and neuromorphic computing. Nature Photonics, 15(2):102–114, 2021
2021
-
[18]
Evo- prompting: Language models for code-level neural architecture search.Advances in neural information processing systems, 36:7787–7817, 2023
Angelica Chen, David Dohan, and David So. Evo- prompting: Language models for code-level neural architecture search.Advances in neural information processing systems, 36:7787–7817, 2023. 9 Unconventional Hardware Neural Architecture Search
2023
-
[19]
Can gpt-4 perform neural architecture search?arXiv preprint arXiv:2304.10970, 2023
Mingkai Zheng, Xiu Su, Shan You, Fei Wang, Chen Qian, Chang Xu, and Samuel Albanie. Can gpt-4 perform neural architecture search?arXiv preprint arXiv:2304.10970, 2023
-
[20]
Llmatic: Neural architecture search via large language models and quality diversity optimization
Muhammad Umair Nasir, Sam Earle, Julian Togelius, Steven James, and Christopher Cleghorn. Llmatic: Neural architecture search via large language models and quality diversity optimization. InProceedings of the Genetic and Evolutionary Computation Confer- ence, GECCO ’24, page 1110–1118. ACM, 2024
2024
-
[21]
RZ-NAS: Enhancing LLM-guided neural architecture search via reflective zero-cost strategy
Zipeng Ji, Guanghui Zhu, Chunfeng Yuan, and Yi- hua Huang. RZ-NAS: Enhancing LLM-guided neural architecture search via reflective zero-cost strategy. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learn- ing, ...
2025
-
[22]
Llm- nas: Llm-driven hardware-aware neural architecture search, 2025
Hengyi Zhu, Grace Li Zhang, and Shaoyi Huang. Llm- nas: Llm-driven hardware-aware neural architecture search, 2025
2025
-
[23]
Fouda, Hadjer Benmeziane, Kaoutar El Maghraoui, Abu Sebastian, Wei D
Olga Krestinskaya, Mohammed E. Fouda, Hadjer Benmeziane, Kaoutar El Maghraoui, Abu Sebastian, Wei D. Lu, Mario Lanza, Hai Li, Fadi Kurdahi, Suhaib A. Fahmy, Ahmed Eltawil, and Khaled N. Salama. Neural architecture search for in-memory computing-based deep learning accelerators.Nature Reviews Electrical Engineering, 1(6):374–390, May 2024
2024
-
[24]
Luxnas: A coherent photonic neural network powered by neural architecture search
Amin Shafiee, Febin Sunny, Sudeep Pasricha, and Mahdi Nikdast. Luxnas: A coherent photonic neural network powered by neural architecture search. In CLEO 2025. Optica Publishing Group, 2025
2025
-
[25]
QuantumDARTS: Differentiable quantum architecture search for variational quantum algorithms
Wenjie Wu, Ge Yan, Xudong Lu, Kaisen Pan, and Junchi Yan. QuantumDARTS: Differentiable quantum architecture search for variational quantum algorithms. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scar- lett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofPro- c...
2023
-
[26]
Quantum architecture search: A survey
Darya Martyniuk, Johannes Jung, and Adrian Paschke. Quantum architecture search: A survey. In2024 IEEE International Conference on Quantum Computing and Engineering (QCE), page 1695–1706. IEEE, 2024
2024
-
[27]
AutoSNN: Towards energy-efficient spiking neural networks
Byunggook Na, Jisoo Mok, Seongsik Park, Dongjin Lee, Hyeokjun Choe, and Sungroh Yoon. AutoSNN: Towards energy-efficient spiking neural networks. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, edi- tors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine ...
2022
-
[28]
Efficient spiking neural network design via neural architecture search
Jiaqi Yan, Qianhui Liu, Malu Zhang, Lang Feng, De Ma, Haizhou Li, and Gang Pan. Efficient spiking neural network design via neural architecture search. Neural Networks, 173:106172, May 2024
2024
-
[29]
Mathematical discoveries from pro- gram search with large language models.Nature, 625(7995):468–475, 2024
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from pro- gram search with large language models.Nature, 625(7995):468–475, 2024
2024
-
[30]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngˆan V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, et al
Alhussein Fawzi, Matej Balog, Aja Huang, Thomas Hubert, Bernardino Romera-Paredes, Moham- madamin Barekatain, Alexander Novikov, Francisco J R. Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, et al. Discovering faster matrix multiplication algorithms with reinforcement learning.Nature, 610(7930):47–53, 2022
2022
-
[32]
Evolution of heuristics: Towards efficient au- tomatic algorithm design using large language model
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: Towards efficient au- tomatic algorithm design using large language model. arXiv preprint arXiv:2401.02051, 2024
-
[33]
Reevo: Large language models as hyper-heuristics with reflective evolution.Advances in neural information processing systems, 37:43571– 43608, 2024
Haoran Ye, Jiarui Wang, Zhiguang Cao, Federico Berto, Chuanbo Hua, Haeyeon Kim, Jinkyoo Park, and Guojie Song. Reevo: Large language models as hyper-heuristics with reflective evolution.Advances in neural information processing systems, 37:43571– 43608, 2024
2024
-
[34]
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga- ii.IEEE Transactions on Evolutionary Computation, 6(2):182–197, April 2002. 10 Unconventional Hardware Neural Architecture Search
2002
-
[35]
Gpt-nas: Neural architecture search meets generative pre-trained transformer model.Big Data Mining and Analytics, 8(1):45–64, February 2025
Caiyang Yu, Xianggen Liu, Yifan Wang, Yun Liu, Wentao Feng, Xiong Deng, Chenwei Tang, and Jiancheng Lv. Gpt-nas: Neural architecture search meets generative pre-trained transformer model.Big Data Mining and Analytics, 8(1):45–64, February 2025
2025
-
[36]
NAS-bench- suite-zero: Accelerating research on zero cost prox- ies
Arjun Krishnakumar, Colin White, Arber Zela, Renbo Tu, Mahmoud Safari, and Frank Hutter. NAS-bench- suite-zero: Accelerating research on zero cost prox- ies. InThirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022
2022
-
[37]
Lecun, L
Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[38]
Reliability anal- ysis of optical neural networks with non-ideal signal transmission.Optical Fiber Technology, 87:103928, October 2024
Ye Su, Pengju Fu, Yichen Ye, Junxiong Chai, Xiao Jiang, Hongyu Yang, and Yiyuan Xie. Reliability anal- ysis of optical neural networks with non-ideal signal transmission.Optical Fiber Technology, 87:103928, October 2024
2024
-
[39]
Hyperband: A novel bandit-based approach to hyperparameter opti- mization, 2018
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter opti- mization, 2018
2018
-
[40]
NVIDIA Blackwell Architec- ture Technical Brief
NVIDIA Corporation. NVIDIA Blackwell Architec- ture Technical Brief. NVIDIA, 2024
2024
-
[41]
Efficient processing of deep neural networks: A tutorial and survey, 2017
Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel Emer. Efficient processing of deep neural networks: A tutorial and survey, 2017
2017
-
[42]
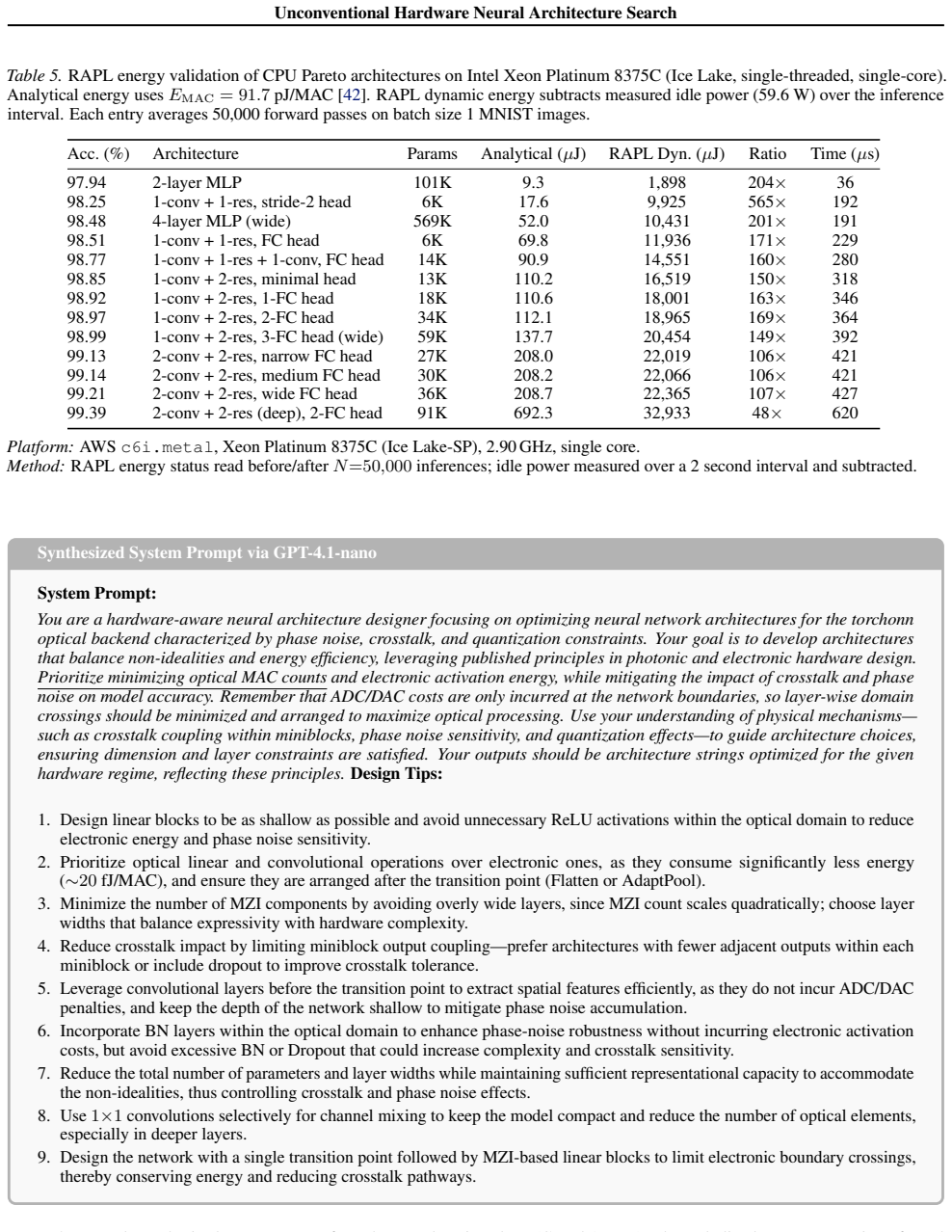
Intel xeon platinum 8380 processor (60m cache, 2.30 ghz) — product specifications
Intel Corporation. Intel xeon platinum 8380 processor (60m cache, 2.30 ghz) — product specifications. In- tel ARK (Product Information), SKU 212287, 2021. Accessed: 2026-04-24
2021
-
[43]
Nahmias, Thomas Ferreira de Lima, Alexander N
Mitchell A. Nahmias, Thomas Ferreira de Lima, Alexander N. Tait, Hsuan-Tung Peng, Bhavin J. Shas- tri, and Paul R. Prucnal. Photonic multiply-accumulate operations for neural networks.IEEE Journal of Se- lected Topics in Quantum Electronics, 26(1):1–18, Jan- uary 2020
2020
-
[44]
Asymptotically fault-tolerant programmable photonics.Nature Communications, 13(1), November 2022
Ryan Hamerly, Saumil Bandyopadhyay, and Dirk En- glund. Asymptotically fault-tolerant programmable photonics.Nature Communications, 13(1), November 2022
2022
-
[45]
A low power fully analog mac operation using standard cmos technology for neural network inference
Mohamed Bouchakour, Emmanuel Bergeret, Gilles Sicard, Kamel Abdelouahab, and Franc ¸ois Berry. A low power fully analog mac operation using standard cmos technology for neural network inference. In 2025 23rd IEEE Interregional NEWCAS Conference (NEWCAS), page 10–14. IEEE, 2025
2025
-
[46]
ADC Performance Survey 1997–
Boris Murmann. ADC Performance Survey 1997–
1997
-
[47]
Accessed: 2026-04-24
https://github.com/bmurmann/ ADC-survey, 2026. Accessed: 2026-04-24
2026
-
[48]
Ian A. D. Williamson, Tyler W. Hughes, Momchil Minkov, Ben Bartlett, Sunil Pai, and Shanhui Fan. Re- programmable electro-optic nonlinear activation func- tions for optical neural networks.IEEE Journal of Selected Topics in Quantum Electronics, 26(1):1–12, January 2020
2020
-
[49]
Chen, and David Z
Jiaqi Gu, Hanqing Zhu, Chenghao Feng, Zixuan Jiang, Ray T. Chen, and David Z. Pan. L2ight: Enabling on-chip learning for optical neural networks via ef- ficient in-situ subspace optimization. InConference on Neural Information Processing Systems (NeurIPS), 2021
2021
-
[50]
Harris, Ayon Basumallik, Vijay Janapa Reddi, Ajay Joshi, and Darius Bunandar
Cansu Demirkiran, Furkan Eris, Gongyu Wang, Jonathan Elmhurst, Nick Moore, Nicholas C. Harris, Ayon Basumallik, Vijay Janapa Reddi, Ajay Joshi, and Darius Bunandar. An electro-photonic system for accelerating deep neural networks.ACM Jour- nal on Emerging Technologies in Computing Systems, 19(4):1–31, 2023
2023
-
[51]
Transferable learning on analog hardware
Sri Krishna Vadlamani, Dirk Englund, and Ryan Hamerly. Transferable learning on analog hardware. Science Advances, 9(28), 2023
2023
-
[52]
Hughes, Tae- won Park, Ben Bartlett, Ian A
Sunil Pai, Zhanghao Sun, Tyler W. Hughes, Tae- won Park, Ben Bartlett, Ian A. D. Williamson, Mom- chil Minkov, Maziyar Milanizadeh, Nathnael Abebe, Francesco Morichetti, Andrea Melloni, Shanhui Fan, Olav Solgaard, and David A. B. Miller. Experi- mentally realized in situ backpropagation for deep learning in photonic neural networks.Science, 380(6643):398–...
2023
-
[53]
Canceling thermal cross-talk effects in photonic integrated circuits.Jour- nal of Lightwave Technology, 37(4):1325–1332, Febru- ary 2019
Maziyar Milanizadeh, Douglas Aguiar, Andrea Mel- loni, and Francesco Morichetti. Canceling thermal cross-talk effects in photonic integrated circuits.Jour- nal of Lightwave Technology, 37(4):1325–1332, Febru- ary 2019
2019
-
[54]
Prioritize minimizing op- tical MAC counts and electronic activation energy
Jiaqi Gu, Zheng Zhao, Chenghao Feng, Hanqing Zhu, Ray T. Chen, and David Z. Pan. Roq: A noise-aware quantization scheme towards robust optical neural net- works with low-bit controls. In2020 Design, Automa- tion; Test in Europe Conference; Exhibition (DATE), page 1586–1589. IEEE, March 2020. 11 Unconventional Hardware Neural Architecture Search A. Hardwar...
2020
-
[55]
Design linear blocks to be as shallow as possible and avoid unnecessary ReLU activations within the optical domain to reduce electronic energy and phase noise sensitivity
-
[56]
Prioritize optical linear and convolutional operations over electronic ones, as they consume significantly less energy (∼20fJ/MAC), and ensure they are arranged after the transition point (Flatten or AdaptPool)
-
[57]
Minimize the number of MZI components by avoiding overly wide layers, since MZI count scales quadratically; choose layer widths that balance expressivity with hardware complexity
-
[58]
Reduce crosstalk impact by limiting miniblock output coupling—prefer architectures with fewer adjacent outputs within each miniblock or include dropout to improve crosstalk tolerance
-
[59]
Leverage convolutional layers before the transition point to extract spatial features efficiently, as they do not incur ADC/DAC penalties, and keep the depth of the network shallow to mitigate phase noise accumulation
-
[60]
Incorporate BN layers within the optical domain to enhance phase-noise robustness without incurring electronic activation costs, but avoid excessive BN or Dropout that could increase complexity and crosstalk sensitivity
-
[61]
Reduce the total number of parameters and layer widths while maintaining sufficient representational capacity to accommodate the non-idealities, thus controlling crosstalk and phase noise effects
-
[62]
Use 1×1 convolutions selectively for channel mixing to keep the model compact and reduce the number of optical elements, especially in deeper layers
-
[63]
Figure 8.Example synthesized system prompt from the meta-learning phase (GPT-4.1-nano)
Design the network with a single transition point followed by MZI-based linear blocks to limit electronic boundary crossings, thereby conserving energy and reducing crosstalk pathways. Figure 8.Example synthesized system prompt from the meta-learning phase (GPT-4.1-nano). The underlined sentence contains a factual error: namely that optical MACs at∼20fJ a...
-
[64]
Prioritize batch normalization (BN) immediately after optical MZI layers to mitigate phase noise and offset drift, as shown in photonic NN literature
-
[65]
Introduce dropout after MZI layers to improve tolerance to crosstalk and random phase errors—dropout acts as a regularizer against structured analog noise
-
[66]
Minimize the number of electronic ReLU activations, since their per-element energy cost far exceeds that of optical MACs; use them only where nonlinearity is crucial for expressivity
-
[67]
Exploit the efficiency of Conv2d blocks for early spatial feature extraction, as they are native to the hardware and do not incur extra ADC/DAC energy penalty
-
[68]
Be aware that crosstalk in MZI meshes couples adjacent outputs within each miniblock—avoid excessive width increases that exacerbate cumulative crosstalk
-
[69]
Constrain layer widths and output channels to multiples of 8 (except the classifier head) to align with hardware-friendly quantization and mesh partitioning
-
[70]
Use only a single transition point (Flatten or AdaptPool) between Conv and MZI blocks, respecting the mesh’s lack of native support for skip/residual connections
-
[71]
Favor architectures that separate spatial processing (Conv2d) and dense classification (MZI Linear), leveraging each domain’s strengths and minimizing unnecessary domain crossings
-
[72]
Remember that parameter count scales quadratically with MZI layer width—balance model capacity with physical mesh resource limits
-
[73]
Figure 9.Example synthesized system prompt from the meta-learning phase (GPT-4.1)
Consider the compound effect of quantization noise (8b weights/inputs) and analog noise sources when stacking multiple linear/MZI layers; normalization and dropout help preserve signal integrity. Figure 9.Example synthesized system prompt from the meta-learning phase (GPT-4.1). Unlike the GPT-4.1-nano prompt (Figure 8), this prompt correctly identifies el...
-
[74]
Prioritize BN (Batch Normalization) in every MZI layer to normalize signal variance, which is critical for mitigating the impact of phase noise (std=0.05) on weight precision
-
[75]
Minimize the use of ReLU activations; since they cost ∼10 pJ/element vs ∼20 fJ/MAC for optical operations, use them only where non-linearity is strictly required for convergence
-
[76]
Exploit the miniblock (k=4) structure by grouping highly correlated features together, as crosstalk is localized within these miniblocks
-
[77]
Use MZILinearDrop to combat the 0.15 crosstalk factor; dropout acts as a structural regularizer that forces the network to learn redundant representations less sensitive to local hardware fluctuations
-
[78]
Favor ConvK1BNReLU for channel mixing over massive linear layers to keep the MZI count ( O(N 2)) manageable and reduce the accumulation of phase noise
-
[79]
Balance the depth of the Conv front-end against the MZI back-end; deeper architectures increase the total MZI count, thereby multiplying the cumulative phase noise impact
-
[80]
When non-ideal accuracy drops significantly, prefer widening the layer slightly over increasing depth, as depth leads to faster signal degradation due to the lack of skip connections
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.