One Video, One World: Turning Monocular Video into Physical 4D Scenes
Pith reviewed 2026-07-01 05:35 UTC · model grok-4.3
The pith
OVOW turns a monocular video into instance-level, simulation-ready 4D mesh scenes without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
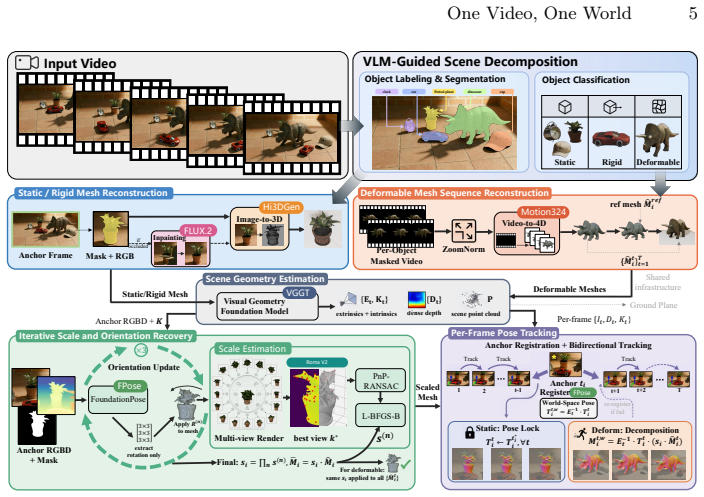
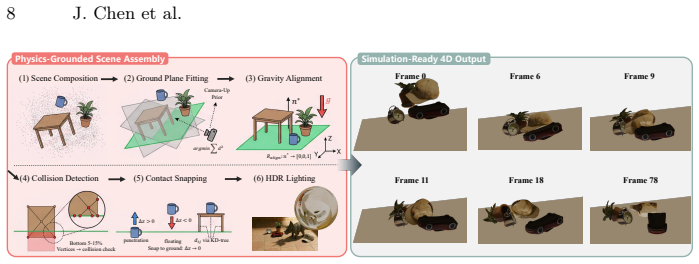
We introduce OVOW, the first training-free system that reconstructs instance-level, simulation-ready 4D mesh scenes from a single monocular video. The system follows a four-stage pipeline: vision-language model for instance discovery, labeling and motion classification; category-aware reconstruction for meshes; iterative render-match-optimize for scale and 6-DoF poses; and physics-grounded assembly for ground contact and support. Motion is handled via direct vertex deformation without priors or rigging, producing watertight meshes for simulation and editing. It also sets a benchmark for Video-to-4D and can generate synthetic data.
What carries the argument
The four-stage OVOW pipeline using vision-language model instance discovery and direct vertex deformation to produce watertight, simulation-ready 4D meshes.
If this is right
- The reconstructed scenes can be directly input to physics simulators for stability checks.
- Performance on synthetic benchmarks shows best layout and geometry accuracy with lowest errors.
- The system runs one to two orders of magnitude faster than baselines on monocular video.
- It doubles as an engine for creating paired video and 4D simulation data.
Where Pith is reading between the lines
- If accurate, this could provide a way to bootstrap physical understanding in AI from passive video observation.
- Future work might test the pipeline on real-world videos with more varied lighting and occlusions.
- The benchmark could become standard for comparing methods on physical plausibility rather than just visual quality.
- Applications in robotics could use the output for planning interactions with the reconstructed scenes.
Load-bearing premise
The vision-language model can correctly identify and classify every instance in the video so errors do not cascade into bad reconstructions or unstable physics.
What would settle it
A counterexample would be if the assembled 4D meshes exhibit inter-object collisions or objects sinking through the floor when simulated in a physics engine, or if they fail to match ground-truth geometry on the proposed benchmark.
Figures





read the original abstract
We introduce \textbf{OVOW}, the first training-free system that reconstructs \emph{instance-level, simulation-ready} 4D mesh scenes from a single monocular video. Recent 4D reconstruction achieves impressive rendering quality, but its outputs (\eg, implicit fields, Gaussian primitives, or point clouds) lack the watertight topology, instance separation, and standardized physical interfaces required by physics simulators and embodied AI. OVOW closes this gap with a four-stage pipeline: a vision-language model discovers, labels, and motion-classifies all instances; category-aware reconstruction yields per-instance meshes for rigid objects and topology-consistent mesh sequences for deformable ones; an iterative render-match-optimize procedure recovers metric scale and 6-DoF pose trajectories; and physics-grounded assembly enforces ground contact and inter-object support. Crucially, we model all motion, rigid and non-rigid, through direct vertex deformation without category-specific priors or skeleton rigging, producing watertight mesh scenes ready for downstream physics simulation and editing. We further establish the first benchmark for \emph{structured Video-to-4D} evaluation, with metrics for geometric correctness, instance separation, and physical plausibility beyond visual fidelity; the same pipeline doubles as a scalable engine for \emph{synthesizing} paired video-to-4D simulation data for future 4D world models and embodied AI. Across two synthetic benchmarks (static and 4D), OVOW attains the best overall layout and geometry accuracy and the lowest photometric and semantic error among all baselines, and on monocular video runs one to two orders of magnitude faster than the baselines, while downstream physics simulation confirms its physical stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OVOW, a training-free four-stage pipeline for reconstructing instance-level, simulation-ready 4D mesh scenes from monocular video: (1) a vision-language model discovers, labels, and motion-classifies instances; (2) category-aware reconstruction produces per-instance meshes (rigid) or topology-consistent sequences (deformable); (3) iterative render-match-optimize recovers metric scale and 6-DoF trajectories; (4) physics-grounded assembly enforces contacts and support. All motion is modeled via direct vertex deformation. The work claims state-of-the-art layout/geometry/photometric/semantic accuracy on two synthetic benchmarks, 1-2 orders of magnitude faster runtime on monocular video, physical stability in downstream simulation, and introduces a new structured Video-to-4D benchmark; the pipeline also doubles as a data generator for future 4D world models.
Significance. If the VLM-driven instance discovery generalizes and the pipeline produces truly simulation-ready outputs, the work would provide a practical bridge from monocular video to physics-compatible 4D assets, addressing a clear gap between current 4D reconstruction methods (implicit fields, Gaussians) and downstream simulation/embodied-AI needs. The new benchmark and data-synthesis capability are constructive contributions. Current evidence, however, is confined to synthetic data with known ground-truth instances, limiting demonstrated impact on the real monocular-video regime emphasized in the abstract.
major comments (3)
- [Abstract] Abstract: The entire pipeline's correctness rests on the VLM stage accurately discovering, labeling, and motion-classifying every instance so that errors do not propagate into non-watertight meshes or unstable physics; yet no per-stage accuracy metrics, error-propagation analysis, or ablation on real-video failure modes (occlusion, ambiguous motion, novel categories) are reported.
- [Abstract] Abstract: Quantitative superiority claims (best layout/geometry accuracy, lowest photometric/semantic error) are stated only for synthetic benchmarks where ground-truth instances are known a priori; this does not test the load-bearing VLM generalization to the monocular-video setting the system is marketed for.
- [Abstract] Abstract: The claim of 'physical stability' confirmed by downstream simulation is presented without accompanying quantitative metrics (e.g., penetration depth, contact stability scores) or comparison against baselines on the same physics tasks.
minor comments (1)
- [Abstract] The abstract refers to 'two synthetic benchmarks (static and 4D)' without naming them or providing dataset references.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the abstract and evaluation could be strengthened. We address each major comment point by point below, indicating planned revisions where the manuscript requires updates.
read point-by-point responses
-
Referee: [Abstract] Abstract: The entire pipeline's correctness rests on the VLM stage accurately discovering, labeling, and motion-classifying every instance so that errors do not propagate into non-watertight meshes or unstable physics; yet no per-stage accuracy metrics, error-propagation analysis, or ablation on real-video failure modes (occlusion, ambiguous motion, novel categories) are reported.
Authors: We agree that explicit per-stage metrics and error-propagation analysis would improve transparency. In the revised manuscript we will add VLM-stage accuracy numbers (instance discovery, labeling, and motion classification) computed against the synthetic ground truth, together with a simple error-propagation table showing how VLM mistakes affect downstream mesh quality and simulation stability. For real-video failure modes we will include a qualitative ablation in the supplement that illustrates representative failure cases (heavy occlusion, ambiguous non-rigid motion, novel categories) together with the resulting mesh and simulation artifacts. revision: yes
-
Referee: [Abstract] Abstract: Quantitative superiority claims (best layout/geometry accuracy, lowest photometric/semantic error) are stated only for synthetic benchmarks where ground-truth instances are known a priori; this does not test the load-bearing VLM generalization to the monocular-video setting the system is marketed for.
Authors: Quantitative metrics require ground-truth instance labels and 4D geometry, which are only available in the synthetic benchmarks; this is why the reported numbers are confined to those datasets. The VLM is used as an off-the-shelf component whose contribution is measured through end-to-end layout, geometry, photometric, and semantic scores. We will revise the abstract and evaluation section to explicitly state that quantitative claims are limited to synthetic data with known instances, while real monocular video results are qualitative and focus on physical plausibility and data-generation utility. A short discussion of VLM generalization limits will also be added. revision: partial
-
Referee: [Abstract] Abstract: The claim of 'physical stability' confirmed by downstream simulation is presented without accompanying quantitative metrics (e.g., penetration depth, contact stability scores) or comparison against baselines on the same physics tasks.
Authors: We acknowledge that the current manuscript presents physical stability only through qualitative simulation roll-outs. In the revision we will introduce quantitative physics metrics (mean penetration depth, contact-force stability over time, and fraction of interpenetrating frames) and will run the same downstream simulation protocol on the baseline outputs for direct comparison. revision: yes
Circularity Check
No circularity; pipeline composes external models and rules without self-referential reduction
full rationale
The described four-stage pipeline chains vision-language models for instance discovery/labeling, category-aware reconstruction, render-match optimization for metric scale/pose, and physics-grounded assembly. No equations, parameters, or claims in the abstract or pipeline description reduce outputs to quantities defined by the paper's own fits, self-citations, or ansatzes. The central claims rest on the composition of these external components and are evaluated on synthetic benchmarks with ground-truth instances, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-language models can discover, label, and motion-classify all instances in monocular video with accuracy sufficient for downstream stages.
- domain assumption Category-aware reconstruction produces watertight, topology-consistent meshes for both rigid and deformable objects.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
SIAM Journal on scientific computing16(5), 1190–1208 (1995)
Byrd, R.H., Lu, P., Nocedal, J., Zhu, C.: A limited memory algorithm for bound constrained optimization. SIAM Journal on scientific computing16(5), 1190–1208 (1995)
1995
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cao, A., Johnson, J.: Hexplane: A fast representation for dynamic scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 130–141 (2023)
2023
-
[4]
arXiv preprint arXiv:2507.21045 (2025)
Cao, Y., Lu, J., Huang, Z., Shen, Z., Zhao, C., Hong, F., Chen, Z., Li, X., Wang, W., Liu, Y., et al.: Reconstructing 4d spatial intelligence: A survey. arXiv preprint arXiv:2507.21045 (2025)
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cao, Z., Hong, F., Chen, Z., Pan, L., Liu, Z.: Physx-anything: Simulation-ready physical 3d assets from single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5839–5848 (2026)
2026
-
[6]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., et al.: Sam 3: Segment anything with concepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, H., Chen, X., Xu, Z., Chen, A.: Motion 3-to-4: 3d motion reconstruction for 4d synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28947–28958 (2026)
2026
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, J., Zhang, B., Tang, X., Wonka, P.: V2m4: 4d mesh animation reconstruction from a single monocular video. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11643–11653 (2025)
2025
-
[9]
In: The Fourteenth International ConferenceonLearningRepresentations(2026), https://openreview.net/forum? id=7VEECFBzmm
Chen, J., Chen, M., Xu, J., Li, X., Dong, J., Sun, M., Jiang, P., Li, H., Yang, Y., Zhao, H., Long, X.X., Huang, R.: Dancetogether: Generating interactive multi-person video without identity drifting. In: The Fourteenth International ConferenceonLearningRepresentations(2026), https://openreview.net/forum? id=7VEECFBzmm
2026
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, J., Gao, K., Cui, Y., Sun, M., Chen, M., Wang, S., Long, X., Ma, F., Tian, Q., Zhao, H., Huang, R.: Lottiegpt: Tokenizing vector animation for autoregressive generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 31639–31651 (June 2026)
2026
-
[11]
In: Proceedings of the 31st International Conference on Computational Linguistics
Chen, J., Li, X., Ye, X., Li, C., Fan, Z., Zhao, H.: Idea23d: Collaborative lmm agents enable 3d model generation from interleaved multimodal inputs. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 4149–4166 (2025)
2025
-
[12]
In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V
Chen, J., Sun, J., Li, X., Xin, H., Xue, Y., Xu, Y., Zhao, H.: LLMsPark: A benchmark for evaluating large language models in strategic gaming contexts. In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2025. pp. 182–194. Association for Computational Linguistics, Suzhou,...
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, M., Chen, J., Fan, Z., Lee, Y., Dang, Z., Wang, L., Cui, Y., Chau, L.P., Wang, Y.: Hvg-3d: Bridging real and simulation domains for 3d-conditional hand- object interaction video synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15986–15997 (June 2026) One Video, One World 17
2026
-
[14]
Machine Vision and Applications37(2), 24 (2026)
Chen, M., Chen, J., Gao, H.a., Chen, X., Fan, Z., Zhao, H.: Ultraman: ultra-fast and high-resolution texture generation for 3d human reconstruction from a single image. Machine Vision and Applications37(2), 24 (2026)
2026
- [15]
-
[16]
Bimanual robot-assisted dressing: A spherical coordinate-based strategy for tight-fitting garments
Chen, M., Yang, R., Hu, Q., Xue, K., Zhou, S., Guo, Y.: Graph2scene: Versatile 3d indoor scene generation with interaction-aware scene graph. In: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 11313– 11320 (2025).https://doi.org/10.1109/IROS60139.2025.11246595
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, W., Rao, J., Wang, W., Li, X., Cheng, X., Cao, L.: Customtex: High-fidelity indoor scene texturing via multi-reference customization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4280–4290 (June 2026)
2026
-
[18]
Advances in Neural Information Processing Systems37, 96181–96206 (2024)
Chu, W.H., Ke, L., Fragkiadaki, K.: Dreamscene4d: Dynamic multi-object scene generation from monocular videos. Advances in Neural Information Processing Systems37, 96181–96206 (2024)
2024
-
[19]
Coumans, E., Bai, Y.: Pybullet, a python module for physics simulation for games, robotics and machine learning.https://pybullet.org/wordpress/(2016–2021)
2016
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023)
2023
-
[21]
In: European Conference on Computer Vision
Dille, S., Careaga, C., Aksoy, Y.: Intrinsic single-image hdr reconstruction. In: European Conference on Computer Vision. pp. 161–177. Springer (2024)
2024
-
[22]
arXiv preprint arXiv:2511.15706 (2025)
Edstedt, J., Nordström, D., Zhang, Y., Bökman, G., Astermark, J., Larsson, V., Heyden, A., Kahl, F., Wadenbäck, M., Felsberg, M.: Roma v2: Harder better faster denser feature matching. arXiv preprint arXiv:2511.15706 (2025)
-
[23]
Communi- cations of the ACM24(6), 381–395 (1981)
Fischler, M.A., Bolles, R.C.: Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communi- cations of the ACM24(6), 381–395 (1981)
1981
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fridovich-Keil, S., Meanti, G., Warburg, F.R., Recht, B., Kanazawa, A.: K-planes: Explicit radiance fields in space, time, and appearance. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12479– 12488 (2023)
2023
-
[25]
In: 9th Annual Conference on Robot Learning (2025),https://openreview.net/forum?id=kto4zVmo4w
Geng, Z., Wang, N., Xu, S., Ye, C., Li, B., Chen, Z., Peng, S., Zhao, H.: One view, many worlds: Single-image to 3d object meets generative domain randomization for one-shot 6d pose estimation. In: 9th Annual Conference on Robot Learning (2025),https://openreview.net/forum?id=kto4zVmo4w
2025
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Gu, Z., Cui, Y., Li, Z., Wei, F., Ge, Y., Gu, J., Liu, M.Y., Davis, A., Ding, Y.: Artiscene:Language-drivenartistic3dscenegenerationthroughimageintermediary. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2891–2901 (June 2025)
2025
-
[27]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Guo, H., Zhang, W., Chen, J., Gu, Y., Yang, J., Du, J., Cao, S., Hui, B., Liu, T., Ma, J., Zhou, C., Li, Z.: IW-bench: Evaluating large multimodal models for converting image-to-web. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Findings of the Association for Computational Linguistics: ACL
-
[28]
pp. 6449–6466. Association for Computational Linguistics, Vienna, Austria (Jul 2025). https://doi.org/10.18653/v1/2025.findings- acl.334 , https: //aclanthology.org/2025.findings-acl.334/ 18 J. Chen et al
-
[29]
arXiv preprint arXiv:2506.11430 (2025)
Guo, J., Liu, J., Chen, J., Mao, S., Hu, C., Jiang, P., Yu, J., Xu, J., Liu, Q., Xu, L., et al.: Auto-connect: Connectivity-preserving rigformer with direct preference optimization. arXiv preprint arXiv:2506.11430 (2025)
-
[30]
Make-It-Poseable: Feed-forward Latent Posing Model for 3D Characters
Guo, Z., Zhang, O., Xiang, J., Zhao, A., Zhou, W., Li, H.: Make-it-poseable: Feed-forward latent posing model for 3d humanoid character animation. arXiv preprint arXiv:2512.16767 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Han, H., Yang, R., Liao, H., Xing, J., Xu, Z., Yu, X., Zha, J., Li, X., Li, W.: Reparo: Compositional 3d assets generation with differentiable 3d layout alignment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 25367–25377 (2025)
2025
-
[32]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Hu, S., Arroyo, D.M., Debats, S., Manhardt, F., Carlone, L., Tombari, F.: Mixed diffusion for 3d indoor scene synthesis. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1262–1272 (2026)
2026
-
[33]
ACM Transactions on Graphics (TOG)44(6), 1–15 (2025)
Hu, Y., Yang, Y., Lin, H., Wang, Y., Dong, J., Deng, Y., Zhu, X., Jia, F., Bao, H., Zhou, X., et al.: Split4d: Decomposed 4d scene reconstruction without video segmentation. ACM Transactions on Graphics (TOG)44(6), 1–15 (2025)
2025
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, J., Gojcic, Z., Atzmon, M., Litany, O., Fidler, S., Williams, F.: Neural kernel surface reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4369–4379 (2023)
2023
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., Guo, Y.C., An, X., Yang, Y., Li, Y., Zou, Z.X., Liang, D., Liu, X., Cao, Y.P., Sheng, L.: Midi: Multi-instance diffusion for single image to 3d scene generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23646–23657 (2025)
2025
-
[36]
arXiv preprint arXiv:2601.05251 (2026)
Jiang, Z., Zheng, C., Laina, I., Larlus, D., Vedaldi, A.: Mesh4d: 4d mesh recon- struction and tracking from monocular video. arXiv preprint arXiv:2601.05251 (2026)
-
[37]
arXiv preprint arXiv:2512.10935 (2025)
Karhade, J., Keetha, N., Zhang, Y., Gupta, T., Sharma, A., Scherer, S., Ra- manan, D.: Any4d: Unified feed-forward metric 4d reconstruction. arXiv preprint arXiv:2512.10935 (2025)
-
[38]
ACM Transactions on Graphics (TOG)42(4), 1–14 (2023)
Kerbl, B., Kopanas, G., Leimkuehler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (TOG)42(4), 1–14 (2023)
2023
-
[39]
arXiv preprint arXiv:2509.07996 (2025)
Kong, L., Yang, W., Mei, J., Liu, Y., Liang, A., Zhu, D., Lu, D., Yin, W., Hu, X., Jia, M., et al.: 3d and 4d world modeling: A survey. arXiv preprint arXiv:2509.07996 (2025)
-
[40]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025)
2025
-
[41]
International journal of computer vision81(2), 155–166 (2009)
Lepetit, V., Moreno-Noguer, F., Fua, P.: Ep n p: An accurate o (n) solution to the p n p problem. International journal of computer vision81(2), 155–166 (2009)
2009
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Z., Niklaus, S., Snavely, N., Wang, O.: Neural scene flow fields for space-time view synthesis of dynamic scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6498–6508 (2021)
2021
-
[43]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026),https: //openreview.net/forum?id=yslRXs9gcJ
Li, Z., Wang, Y., Zheng, H., Luo, Y., Wen, B.: Sparc3d: Sparse representation and construction for high-resolution 3d shapes modeling. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026),https: //openreview.net/forum?id=yslRXs9gcJ
2026
-
[44]
Advances in Neural Information Processing Systems37, 21377–21400 (2024) One Video, One World 19
Li, Z., Chen, Y., Liu, P.: Dreammesh4d: Video-to-4d generation with sparse- controlled gaussian-mesh hybrid representation. Advances in Neural Information Processing Systems37, 21377–21400 (2024) One Video, One World 19
2024
-
[45]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Liang, H., Xu, D., Bhatt, N.P., Hu, H., Liang, H., Plataniotis, K.N.: Comp4d: Compositional 4d scene generation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 3567–3577 (2026)
2026
-
[46]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems
Liang, H., Yin, Y., Xu, D., Liang, H., Wang, Z., Plataniotis, K.N., Zhao, Y., Wei, Y.: Diffusion4d: fast spatial-temporal consistent 4d generation via video diffusion models. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. pp. 110854–110875 (2024)
2024
-
[47]
PAT3D: Physics-Augmented Text-to-3D Scene Generation
Lin, G., Huang, K., Liu, M., Gao, R., Chen, H., Chen, L., Lu, B., Komura, T., Liu, Y., Zhu, J.Y., et al.: Pat3d: Physics-augmented text-to-3d scene generation. arXiv preprint arXiv:2511.21978 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
In: Proceed- ings of the 33rd ACM International Conference on Multimedia
Lin, J., Wang, Z., Xu, D., Jiang, S., Gong, Y., Jiang, M.: Phys4dgen: Physics- compliant 4d generation with multi-material composition perception. In: Proceed- ings of the 33rd ACM International Conference on Multimedia. pp. 10398–10407 (2025)
2025
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ling, L., Ge, Y., Sheng, Y., Bera, A.: I-scene: 3d instance models are implicit generalizable spatial learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26974–26983 (2026)
2026
-
[51]
arXiv preprint arXiv:2505.02836 (2025)
Ling, L., Lin, C.H., Lin, T.Y., Ding, Y., Zeng, Y., Sheng, Y., Ge, Y., Liu, M.Y., Bera, A., Li, Z.: Scenethesis: A language and vision agentic framework for 3d scene generation. arXiv preprint arXiv:2505.02836 (2025)
-
[52]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=LuGHbK8qTa
Liu, I., Su, H., Wang, X.: Dynamic gaussians mesh: Consistent mesh reconstruction from dynamic scenes. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=LuGHbK8qTa
2025
-
[53]
ACM Transactions on Graphics (TOG)44(4), 1–12 (2025)
Liu, I., Xu, Z., Yifan, W., Tan, H., Xu, Z., Wang, X., Su, H., Shi, Z.: Riganything: Template-free autoregressive rigging for diverse 3d assets. ACM Transactions on Graphics (TOG)44(4), 1–12 (2025)
2025
-
[54]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, T., Huang, Z., Chen, Z., Wang, G., Hu, S., Shen, L., Sun, H., Cao, Z., Li, W., Liu, Z.: Free4d: Tuning-free 4d scene generation with spatial-temporal consistency. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 25571–25582 (2025)
2025
-
[55]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Long, X., Guo, Y.C., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Habermann, M., Theobalt, C., et al.: Wonder3d: Single image to 3d using cross- domain diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9970–9980 (2024)
2024
-
[56]
ACM Trans
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia)34(6), 248:1–248:16 (Oct 2015)
2015
-
[57]
Advances in Neural Information Processing Systems38, 148548–148583 (2026)
Lu, Y., Tian, Y., Jiang, Z., Zhao, Y., Yang, Y., Ouyang, H., Hu, H., Yu, H., Shen, Y., Liao, Y.: Orientation matters: Making 3d generative models orientation-aligned. Advances in Neural Information Processing Systems38, 148548–148583 (2026)
2026
-
[58]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., et al.: Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv preprint arXiv:2108.10470 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[59]
In: Thirteenth International Conference on 3D Vision (2026),https://openreview.net/forum?id=KpelxFFxQT 20 J
Meng, Y., Wu, H., Zhang, Y., Xie, W.: Scenegen: Single-image 3d scene generation in one feedforward pass. In: Thirteenth International Conference on 3D Vision (2026),https://openreview.net/forum?id=KpelxFFxQT 20 J. Chen et al
2026
-
[60]
arXiv preprint arXiv:2503.14501 (2025)
Miao, Q., Li, K., Quan, J., Min, Z., Ma, S., Xu, Y., Yang, Y., Liu, P., Luo, Y.: Advances in 4d generation: A survey. arXiv preprint arXiv:2503.14501 (2025)
- [61]
-
[62]
Communications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM65(1), 99–106 (2021)
2021
-
[63]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Nazarczuk, M., Tanay, T., Moreau, A., Zhang, Z., Pérez-Pellitero, E.: Charge: A comprehensive novel view synthesis benchmark and dataset to bind them all. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15323–15333 (2026)
2026
-
[64]
In: Proceedings of the IEEE/CVF international conference on computer vision
Park, K., Sinha, U., Barron, J.T., Bouaziz, S., Goldman, D.B., Seitz, S.M., Martin- Brualla, R.: Nerfies: Deformable neural radiance fields. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5865–5874 (2021)
2021
-
[65]
ACM Transactions on Graphics (TOG)40(6), 1–12 (2021)
Park, K., Sinha, U., Hedman, P., Barron, J.T., Bouaziz, S., Goldman, D.B., Martin-Brualla, R., Seitz, S.M.: Hypernerf: a higher-dimensional representation for topologically varying neural radiance fields. ACM Transactions on Graphics (TOG)40(6), 1–12 (2021)
2021
-
[66]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Pumarola, A., Corona, E., Pons-Moll, G., Moreno-Noguer, F.: D-nerf: Neural radiance fields for dynamic scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10318–10327 (2021)
2021
-
[67]
In: 9th Annual Conference on Robot Learning (2025),https://openreview.net/forum? id=BNCh3SS1Yl
Qiu, X., Yang, J., Wang, Y., Chen, Z., Wang, Y., Wang, T.H., Xian, Z., Gan, C.: Articulate anymesh: Open-vocabulary 3d articulated objects modeling. In: 9th Annual Conference on Robot Learning (2025),https://openreview.net/forum? id=BNCh3SS1Yl
2025
-
[68]
In: Proceedings of the IEEE/CVF international conference on computer vision
Reizenstein, J., Shapovalov, R., Henzler, P., Sbordone, L., Labatut, P., Novotny, D.: Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10901–10911 (2021)
2021
-
[69]
Advances in Neural Information Processing Systems37, 56828–56858 (2024)
Ren, J., Xie, C., Mirzaei, A., Kreis, K., Liu, Z., Torralba, A., Fidler, S., Kim, S.W., Ling, H., et al.: L4gm: Large 4d gaussian reconstruction model. Advances in Neural Information Processing Systems37, 56828–56858 (2024)
2024
-
[70]
arXiv preprint arXiv:2601.16148 (2026)
Sabathier, R., Novotny, D., Mitra, N.J., Monnier, T.: Actionmesh: Animated 3d mesh generation with temporal 3d diffusion. arXiv preprint arXiv:2601.16148 (2026)
-
[71]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shi, Y., Li, W., Wang, Z., Li, H., Chen, X., Tan, P., Zhang, L.: Scenemaker: Open-set 3d scene generation with decoupled de-occlusion and pose estimation model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 27146–27156 (2026)
2026
-
[72]
arXiv preprint arXiv:2601.11514 (2026)
Siddiqui, Y., Frost, D., Aroudj, S., Avetisyan, A., Howard-Jenkins, H., DeTone, D., Moulon, P., Wu, Q., Li, Z., Straub, J., et al.: Shaper: Robust conditional 3d shape generation from casual captures. arXiv preprint arXiv:2601.11514 (2026)
-
[73]
In: Proceedings of the 40th International Conference on Machine Learning
Singer, U., Sheynin, S., Polyak, A., Ashual, O., Makarov, I., Kokkinos, F., Goyal, N., Vedaldi, A., Parikh, D., Johnson, J., et al.: Text-to-4d dynamic scene generation. In: Proceedings of the 40th International Conference on Machine Learning. pp. 31915–31929 (2023)
2023
-
[74]
Advances in neural information processing systems38, 72152–72184 (2026) One Video, One World 21
Song, C., Li, X., Yang, F., Xu, Z., Wei, J., Liu, F., Feng, J., Lin, G., Zhang, J.: Puppeteer: Rig and animate your 3d models. Advances in neural information processing systems38, 72152–72184 (2026) One Video, One World 21
2026
-
[76]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Song, C., Zhang, J., Li, X., Yang, F., Chen, Y., Xu, Z., Liew, J.H., Guo, X., Liu, F., Feng, J., et al.: Magicarticulate: Make your 3d models articulation-ready. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15998–16007 (2025)
2025
-
[77]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sun, M., Chen, J., Dong, J., Chen, Y., Jiang, X., Mao, S., Jiang, P., Wang, J., Dai, B., Huang, R.: Drive: Diffusion-based rigging empowers generation of versatile and expressive characters. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21170–21180 (2025)
2025
-
[78]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Sun, M., Zeng, C., Pei, J., Chen, J., Song, C., Wang, S., Chang, T., Huang, B., Zeng, Z., Huang, R.: Animator-centric skeleton generation on objects with fine-grained details. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 17336–17345 (June 2026)
2026
-
[79]
In: Computer Graphics Forum
Tang, X., Li, R., Fan, X.: Zeroscene: A zero-shot framework for 3d scene generation from a single image and controllable texture editing. In: Computer Graphics Forum. p. e70419. Wiley Online Library (2026)
2026
-
[80]
In: Thirteenth International Conference on 3D Vision (2025)
Tao, S., Zhou, B., Tu, H., Wang, Y., Liu, Y.: Tesselation gs: Neural mesh gaus- sians for robust monocular reconstruction of dynamic objects. In: Thirteenth International Conference on 3D Vision (2025)
2025
-
[81]
Team, S.D., Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., Lin, A., Liu, J., Ma, Z., Sagar, A., Song, B., Wang, X., Yang, J., Zhang, B., Dollár, P., Gkioxari, G., Feiszli, M., Malik, J.: Sam 3d: 3dfy anything in images (2025),https://arxiv.org/abs/2511.16624
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.