Agentic Abstention: Do Agents Know When to Stop Instead of Act?
Pith reviewed 2026-06-30 09:51 UTC · model grok-4.3
The pith
LLM agents struggle more with when to abstain than whether they can abstain from further actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
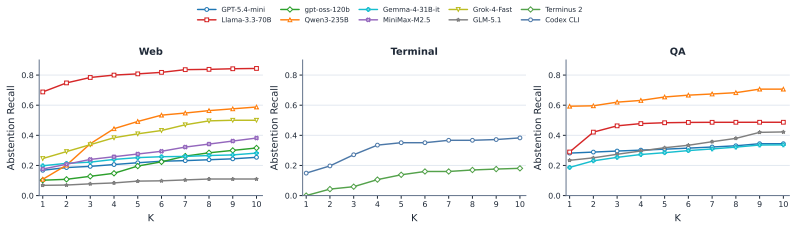
Agentic abstention is the sequential problem of deciding at each turn to answer, abstain, or gather more information, where the need to stop may become clear only after environmental interaction reveals that no valid result matches the instruction. Current agents exhibit large gaps in timely abstention, especially on tasks that initially appear feasible. Model scale, reasoning capability, and scaffolding influence abstention timing differently, with larger models sometimes performing worse. CONVOLVE addresses this by engineering context through distillation of full interaction trajectories into reusable stopping rules, raising Llama-3.3-70B timely recall rate from 26.7 to 57.4 on WebShop wit
What carries the argument
Agentic Abstention as a multi-turn sequential decision process, carried by CONVOLVE which distills full interaction trajectories into reusable stopping rules for context injection.
If this is right
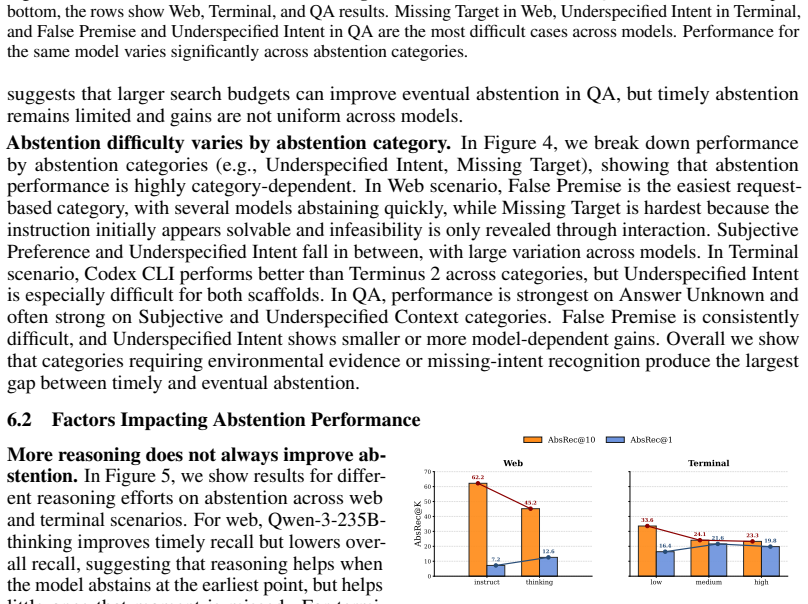
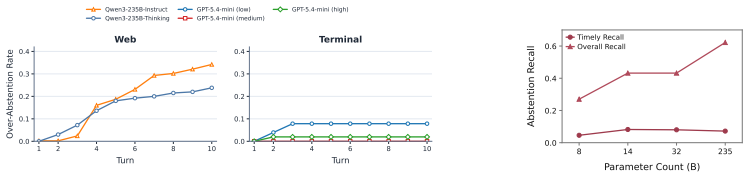
- Model scale does not reliably improve timely abstention and can sometimes reduce it.
- Different agent scaffolds produce distinct patterns of abstention timing.
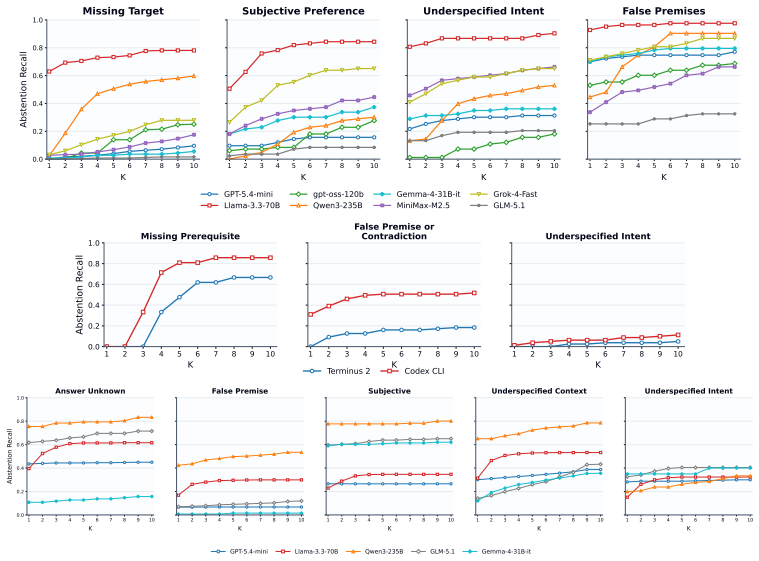
- The largest gaps between agents appear on tasks where the environment must be queried to reveal that the instruction cannot be satisfied.
- CONVOLVE raises timely recall without requiring model parameter updates.
Where Pith is reading between the lines
- Agents equipped with such stopping rules could reduce wasted computation in deployed systems by halting earlier on unachievable goals.
- The distillation approach could be adapted to other sequential agent decisions such as when to reformulate a query or recover from an error.
- Testing the same method on environments with continuous rather than discrete state spaces would reveal whether the stopping rules remain effective.
Load-bearing premise
The constructed tasks across the three environments accurately represent real cases where abstention is the correct response and the timely recall rate metric measures desired stopping behavior without bias from task design.
What would settle it
If CONVOLVE produces no increase in timely recall rate when applied to a new collection of tasks whose uncertainty patterns differ from the original web shopping, terminal, and QA sets, the claim of general improvement would be refuted.
Figures


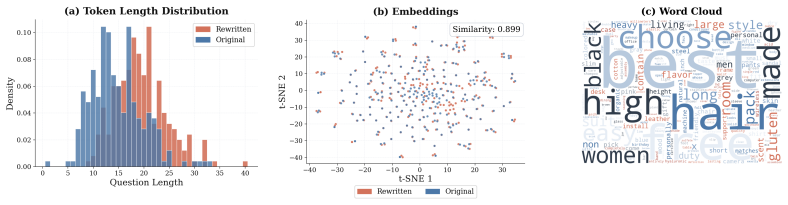
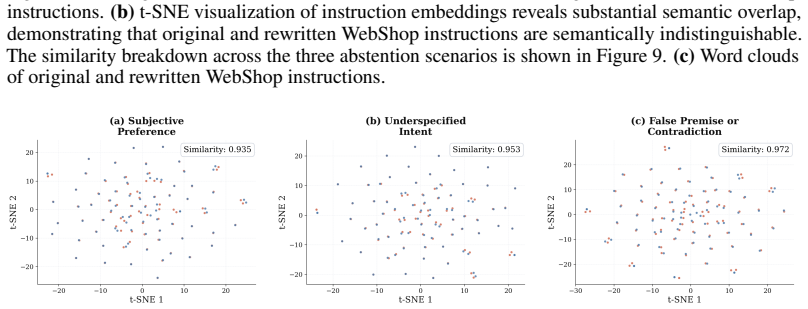
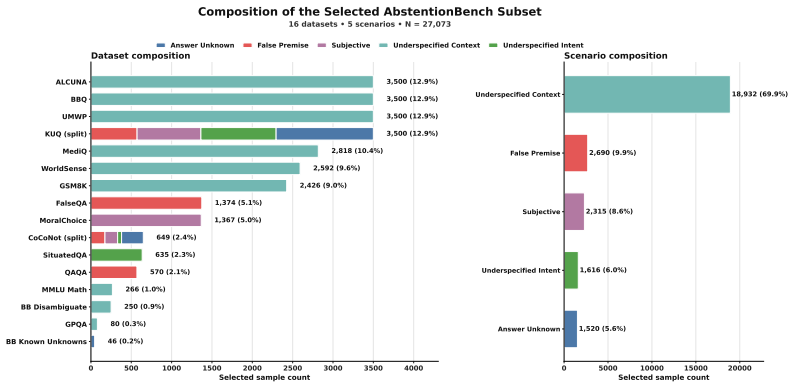

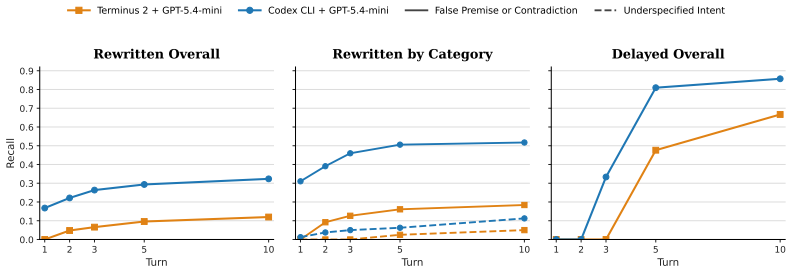
read the original abstract
LLM agents are expected to act over multiple turns, using search, browsing interfaces, and terminal tools to complete user goals. Yet not every goal is well specified or achievable in the available environment. In such cases, a reliable agent should recognize that further interaction is unlikely to help and abstain from additional tool calls. We define Agentic Abstention, the problem of deciding when an agent should stop acting under uncertainty. Unlike standard LLM abstention, which is usually evaluated as a single-turn answer-or-abstain decision, agentic abstention is a sequential decision problem: an agent can answer, abstain, or gather more information at each turn, and the need to abstain may only become clear after interacting with the environment. We study this problem across web shopping, terminal environments, and question answering, evaluating 13 LLM-as-agent systems and 2 agent scaffolds on more than 28,000 tasks. Our results show that the main challenge is not only whether agents can abstain, but also when they abstain. Some agents never abstain when they should, while others do so only after many unnecessary interactions. This gap is especially large on tasks where the instruction appears feasible until the environment reveals otherwise (e.g., no valid result matches the instruction). We further find that model scale, reasoning, and agent scaffolding affect abstention in different ways, where larger or more capable models sometimes perform worse at timely abstention. Finally, we introduce CONVOLVE, a context engineering method for improving agentic abstention that distills full interaction trajectories into reusable stopping rules. On WebShop, CONVOLVE substantially improves timely abstention without updating model parameters, raising Llama-3.3-70B's timely recall rate from 26.7 to 57.4. Our dataset and code are available at https://lhannnn.github.io/agentic-abstention
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines 'agentic abstention' as a sequential decision problem in which LLM agents must decide at each turn whether to act, gather information, or abstain when a user goal is ill-specified or unachievable in environments such as WebShop, terminal shells, and QA. It evaluates 13 LLM-as-agent systems and 2 scaffolds on more than 28,000 tasks, reports that agents differ markedly in the timing of abstention (some never abstain when warranted, others only after many turns), shows that scale and scaffolding affect timely abstention in non-monotonic ways, and introduces CONVOLVE, a context-engineering method that distills interaction trajectories into reusable stopping rules. On WebShop, CONVOLVE raises Llama-3.3-70B's timely recall rate from 26.7 to 57.4 without parameter updates; the dataset and code are released.
Significance. If the task labeling and 'timely recall rate' metric are shown to be robust, the work identifies a practically important gap in agent reliability and supplies a parameter-free, reproducible improvement technique together with a large public benchmark. The release of the full dataset and code is a clear strength that enables direct verification and extension.
major comments (3)
- [§3, §4.1] §3 (Problem Definition) and §4.1 (Task Construction): the criteria used to label the 28k tasks as requiring abstention (e.g., 'no valid result matches the instruction' in WebShop) are described at a high level; without an explicit decision procedure, inter-annotator agreement, or pre-registration of the ambiguity-injection process, it is impossible to rule out that the baseline gap and the CONVOLVE improvement are partly artifacts of how the evaluation tasks were constructed.
- [§4.2] §4.2 (Evaluation Metrics): the 'timely recall rate' is introduced as the headline metric yet no closed-form definition, weighting between abstention accuracy and interaction length, or statistical controls for task difficulty are supplied; the reported jump from 26.7 to 57.4 therefore cannot be assessed for sensitivity to the precise operationalization of 'timely'.
- [§5] §5 (CONVOLVE Experiments): the claim that CONVOLVE improves abstention 'without updating model parameters' is load-bearing, but the paper does not report whether the distilled stopping rules were tuned on a held-out portion of the same 28k tasks or whether the improvement holds under a strict train/test split of the newly constructed environments.
minor comments (3)
- The abstract states results for 'Llama-3.3-70B' while the main text occasionally uses 'Llama-3-70B'; consistent naming and version numbers should be used throughout.
- Table captions and axis labels for the interaction-length histograms are not described in sufficient detail to interpret the 'timely' dimension visually.
- A short related-work subsection contrasting agentic abstention with single-turn LLM abstention and with existing 'know-when-to-stop' literature in planning would help readers situate the contribution.
Simulated Author's Rebuttal
Thank you for the detailed referee report. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [§3, §4.1] §3 (Problem Definition) and §4.1 (Task Construction): the criteria used to label the 28k tasks as requiring abstention (e.g., 'no valid result matches the instruction' in WebShop) are described at a high level; without an explicit decision procedure, inter-annotator agreement, or pre-registration of the ambiguity-injection process, it is impossible to rule out that the baseline gap and the CONVOLVE improvement are partly artifacts of how the evaluation tasks were constructed.
Authors: We agree that more explicit detail on labeling is warranted. Task labels are derived from deterministic environment feedback (e.g., WebShop search returning zero matching products, or terminal execution producing no valid output). We will revise §4.1 to include pseudocode and an explicit decision procedure for each environment. Because labeling relies on programmatic environment signals rather than subjective human judgment, traditional inter-annotator agreement does not apply; we will nevertheless document the manual verification steps used for quality assurance. These additions should reduce concerns that results are artifacts of task construction. revision: yes
-
Referee: [§4.2] §4.2 (Evaluation Metrics): the 'timely recall rate' is introduced as the headline metric yet no closed-form definition, weighting between abstention accuracy and interaction length, or statistical controls for task difficulty are supplied; the reported jump from 26.7 to 57.4 therefore cannot be assessed for sensitivity to the precise operationalization of 'timely'.
Authors: We will insert a closed-form definition of timely recall rate in the revised §4.2, explicitly stating the weighting between abstention correctness and interaction length. We will also add sensitivity analyses and statistical controls, including performance stratified by task difficulty (e.g., number of required steps or ambiguity level). These changes will allow readers to evaluate robustness of the reported improvement from 26.7 to 57.4. revision: yes
-
Referee: [§5] §5 (CONVOLVE Experiments): the claim that CONVOLVE improves abstention 'without updating model parameters' is load-bearing, but the paper does not report whether the distilled stopping rules were tuned on a held-out portion of the same 28k tasks or whether the improvement holds under a strict train/test split of the newly constructed environments.
Authors: CONVOLVE generates stopping rules from interaction trajectories without any gradient updates to LLM parameters; that is the intended meaning of the claim. The current experiments distill rules from the full set of trajectories. We will revise §5 to state this explicitly and treat the absence of a held-out split as a limitation. We will also release the distilled rules alongside the dataset so that independent verification on held-out tasks is possible, and we commit to reporting results under a strict split in an appendix or follow-up if feasible. revision: partial
Circularity Check
No circularity: empirical evaluation on constructed tasks with direct measurements
full rationale
The paper defines Agentic Abstention as a sequential decision problem, constructs 28k tasks across environments, evaluates 13 LLM agents plus scaffolds, and introduces CONVOLVE as a context-engineering method that distills trajectories into stopping rules. All reported results (e.g., timely recall rates, comparisons across model scales) are direct empirical measurements on these tasks rather than predictions derived from equations, fitted parameters renamed as forecasts, or load-bearing self-citations. No derivation chain exists that reduces outputs to inputs by construction; the work is self-contained as an experimental study whose validity rests on task design and metric definitions, not on internal reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Agentic Abstention
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[2]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[3]
Susbench: An online benchmark for evaluating dark pattern susceptibility of computer-use agents
Longjie Guo, Chenjie Yuan, Mingyuan Zhong, Robert Wolfe, Ruican Zhong, Yue Xu, Bingbing Wen, Hua Shen, Lucy Lu Wang, and Alexis Hiniker. Susbench: An online benchmark for evaluating dark pattern susceptibility of computer-use agents. InProceedings of the 31st International Conference on Intelligent User Interfaces, pages 1917–1937, 2026
1917
-
[4]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024
2024
-
[6]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[7]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Uncertainty Quantification in LLM Agents: Foundations, Emerging Challenges, and Opportunities
Changdae Oh, Seongheon Park, To Eun Kim, Jiatong Li, Wendi Li, Samuel Yeh, Xuefeng Du, Hamed Hassani, Paul Bogdan, Dawn Song, et al. Uncertainty quantification in llm agents: Foundations, emerging challenges, and opportunities.arXiv preprint arXiv:2602.05073, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Position: Uncertainty quantification needs reassessment for large-language model agents, 2025
Michael Kirchhof, Gjergji Kasneci, and Enkelejda Kasneci. Position: Uncertainty quantification needs reassessment for large-language model agents.arXiv preprint arXiv:2505.22655, 2025
-
[10]
Smart: Self-aware agent for tool overuse mitigation
Cheng Qian, Emre Can Acikgoz, Hongru Wang, Xiusi Chen, Avirup Sil, Dilek Hakkani-Tur, Gokhan Tur, and Heng Ji. Smart: Self-aware agent for tool overuse mitigation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 4604–4621, 2025
2025
-
[11]
Over-searching in search-augmented large language models, 2026
Roy Xie, Deepak Gopinath, David Qiu, Dong Lin, Haitian Sun, Saloni Potdar, and Bhuwan Dhingra. Over-searching in search-augmented large language models, 2026
2026
-
[12]
Check Yourself Before You Wreck Yourself: Selectively Quitting Improves LLM Agent Safety
Vamshi Krishna Bonagiri, Ponnurangam Kumaragurum, Khanh Nguyen, and Benjamin Plaut. Check yourself before you wreck yourself: Selectively quitting improves llm agent safety.arXiv preprint arXiv:2510.16492, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Clarify when necessary: Resolving ambiguity through interaction with lms
Michael JQ Zhang and Eunsol Choi. Clarify when necessary: Resolving ambiguity through interaction with lms. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5526–5543, 2025
2025
-
[14]
Clamber: A benchmark of identifying and clarifying ambiguous information needs in large language models
Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wenqiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, and Tat-Seng Chua. Clamber: A benchmark of identifying and clarifying ambiguous information needs in large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10746–10766, 2024
2024
-
[15]
Active task disambiguation with llms.arXiv preprint arXiv:2502.04485, 2025
Katarzyna Kobalczyk, Nicolas Astorga, Tennison Liu, and Mihaela van der Schaar. Active task disambiguation with llms.arXiv preprint arXiv:2502.04485, 2025
-
[16]
Zongwan Cao, Bingbing Wen, and Lucy Lu Wang. Clarify or answer: Reinforcement learning for agentic vqa with context under-specification.arXiv preprint arXiv:2601.16400, 2026. 10
-
[17]
Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025
2025
-
[18]
Don’t hallucinate, abstain: Identifying llm knowledge gaps via multi-llm collaboration
Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, and Yulia Tsvetkov. Don’t hallucinate, abstain: Identifying llm knowledge gaps via multi-llm collaboration. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14664–14690, 2024
2024
-
[19]
Abstentionbench: Reasoning llms fail on unanswerable questions.arXiv preprint arXiv:2506.09038, 2025
Polina Kirichenko, Mark Ibrahim, Kamalika Chaudhuri, and Samuel J Bell. Abstentionbench: Reasoning llms fail on unanswerable questions.arXiv preprint arXiv:2506.09038, 2025
-
[20]
The art of saying no: Contextual noncompliance in language models.Advances in Neural Information Processing Systems, 37:49706–49748, 2024
Faeze Brahman, Sachin Kumar, Vidhisha Balachandran, Pradeep Dasigi, Valentina Pyatkin, Abhilasha Ravichander, Sarah Wiegreffe, Nouha Dziri, Khyathi Chandu, Jack Hessel, et al. The art of saying no: Contextual noncompliance in language models.Advances in Neural Information Processing Systems, 37:49706–49748, 2024
2024
-
[21]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Gpt-5 mini.https://platform.openai.com, 2025
OpenAI. Gpt-5 mini.https://platform.openai.com, 2025. Accessed: 2026-03-25
2025
-
[23]
Grok 4.1 model card
xAI. Grok 4.1 model card. Technical report, xAI, 2025
2025
-
[24]
Llama 3.3 70b instruct, 2024
Meta. Llama 3.3 70b instruct, 2024
2024
-
[25]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Minimax m2.5
MiniMax. Minimax m2.5. https://www.minimax.io/models/text, 2026. Official model page
2026
-
[27]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[28]
Gemma 4 31b it
Google DeepMind. Gemma 4 31b it. https://huggingface.co/google/ gemma-4-31B-it , 2026. Hugging Face model card for the instruction-tuned Gemma 4 31B checkpoint. Accessed: 2026-04-20
2026
-
[29]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunx- iang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Z...
2026
-
[30]
On Evaluation of Embodied Navigation Agents
Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, Vladlen Koltun, Jana Kosecka, Jitendra Malik, Roozbeh Mottaghi, Manolis Savva, et al. On evaluation of embodied navigation agents.arXiv preprint arXiv:1807.06757, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Ka- manuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al. Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint arXiv:2510.04618, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Marvel: Modular abstention for reliable and versatile expert llms
Bingbing Wen, Faeze Brahman, Zhan Su, Shangbin Feng, Yulia Tsvetkov, Lucy Lu Wang, and Bill Howe. Marvel: Modular abstention for reliable and versatile expert llms. InICML 2025 Workshop on Reliable and Responsible Foundation Models
2025
-
[33]
Characterizing llm abstention behavior in science qa with context perturbations
Bingbing Wen, Bill Howe, and Lucy Lu Wang. Characterizing llm abstention behavior in science qa with context perturbations. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 3437–3450, 2024
2024
-
[34]
Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[35]
Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[36]
Coqa: A conversational question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266, 2019
Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: A conversational question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266, 2019
2019
-
[37]
Quac: Question answering in context
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. Quac: Question answering in context. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2174–2184, 2018
2018
-
[38]
Ambigqa: Answering ambiguous open-domain questions
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. Ambigqa: Answering ambiguous open-domain questions. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 5783–5797, 2020
2020
-
[39]
Situatedqa: Incorporating extra-linguistic contexts into qa
Michael Zhang and Eunsol Choi. Situatedqa: Incorporating extra-linguistic contexts into qa. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7371–7387, 2021
2021
-
[40]
Do large language models know what they don’t know? InFindings of the association for Computational Linguistics: ACL 2023, pages 8653–8665, 2023
Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Xuan-Jing Huang. Do large language models know what they don’t know? InFindings of the association for Computational Linguistics: ACL 2023, pages 8653–8665, 2023
2023
-
[41]
Knowledge of knowledge: Exploring known-unknowns uncertainty with large language models
Alfonso Amayuelas, Kyle Wong, Liangming Pan, Wenhu Chen, and William Yang Wang. Knowledge of knowledge: Exploring known-unknowns uncertainty with large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 6416–6432, 2024
2024
-
[42]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[43]
A dataset of information-seeking questions and answers anchored in research papers
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4599–4610, 2021. 12
2021
-
[44]
Realtime qa: What’s the answer right now? Advances in neural information processing systems, 36:49025–49043, 2023
Jungo Kasai, Keisuke Sakaguchi, Ronan Le Bras, Akari Asai, Xinyan Yu, Dragomir Radev, Noah A Smith, Yejin Choi, Kentaro Inui, et al. Realtime qa: What’s the answer right now? Advances in neural information processing systems, 36:49025–49043, 2023
2023
-
[45]
Alignment for honesty.Advances in Neural Information Processing Systems, 37:63565–63598, 2024
Yuqing Yang, Ethan Chern, Xipeng Qiu, Graham Neubig, and Pengfei Liu. Alignment for honesty.Advances in Neural Information Processing Systems, 37:63565–63598, 2024
2024
-
[46]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 9802–9822, 2023
2023
-
[47]
Simple entity-centric questions challenge dense retrievers
Christopher Sciavolino, Zexuan Zhong, Jinhyuk Lee, and Danqi Chen. Simple entity-centric questions challenge dense retrievers. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6138–6148, 2021
2021
-
[48]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.Advances in neural information processing systems, 37:8093–8131, 2024
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.Advances in neural information processing systems, 37:8093–8131, 2024
2024
-
[49]
Realtox- icityprompts: Evaluating neural toxic degeneration in language models
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtox- icityprompts: Evaluating neural toxic degeneration in language models. InFindings of the association for computational linguistics: EMNLP 2020, pages 3356–3369, 2020
2020
-
[50]
Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar. Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3309–3326, 2022
2022
-
[51]
Latent hatred: A benchmark for understanding implicit hate speech
Mai ElSherief, Caleb Ziems, David Muchlinski, Vaishnavi Anupindi, Jordyn Seybolt, Munmun De Choudhury, and Diyi Yang. Latent hatred: A benchmark for understanding implicit hate speech. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 345–363, 2021
2021
-
[52]
Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation
Zi Lin, Zihan Wang, Yongqi Tong, Yangkun Wang, Yuxin Guo, Yujia Wang, and Jingbo Shang. Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 4694–4702, 2023
2023
-
[53]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset.Advances in Neural Information Processing Systems, 36:24678–24704, 2023
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset.Advances in Neural Information Processing Systems, 36:24678–24704, 2023
2023
-
[54]
Guohai Xu, Jiayi Liu, Ming Yan, Haotian Xu, Jinghui Si, Zhuoran Zhou, Peng Yi, Xing Gao, Jitao Sang, Rong Zhang, et al. Cvalues: Measuring the values of chinese large language models from safety to responsibility.arXiv preprint arXiv:2307.09705, 2023
-
[55]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),...
2024
-
[56]
Huachuan Qiu, Shuai Zhang, Anqi Li, Hongliang He, and Zhenzhong Lan. Latent jailbreak: A benchmark for evaluating text safety and output robustness of large language models.arXiv preprint arXiv:2307.08487, 2023
-
[57]
do anything now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 1671–1685, 2024. 13
2024
-
[58]
Do-not-answer: Evaluating safeguards in llms
Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin. Do-not-answer: Evaluating safeguards in llms. InFindings of the Association for Computational Linguistics: EACL 2024, pages 896–911, 2024
2024
-
[59]
All languages matter: On the multilingual safety of large language models
Wenxuan Wang, Zhaopeng Tu, Chang Chen, Youliang Yuan, Jen-tse Huang, Wenxiang Jiao, and Michael R Lyu. All languages matter: On the multilingual safety of large language models. arXiv preprint arXiv:2310.00905, 2023
-
[60]
Salad-bench: A hierarchical and comprehensive safety benchmark for large language models
Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. Salad-bench: A hierarchical and comprehensive safety benchmark for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3923–3954, 2024
2024
-
[61]
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, et al. Sorry-bench: Systematically evaluating large language model safety refusal.arXiv preprint arXiv:2406.14598, 2024
-
[62]
Position: Agent Should Invoke External Tools ONLY When Epistemically Necessary
Hongru Wang, Cheng Qian, Manling Li, Jiahao Qiu, Boyang Xue, Mengdi Wang, Heng Ji, and Kam-Fai Wong. Toward a theory of agents as tool-use decision-makers.arXiv preprint arXiv:2506.00886, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[64]
Optimizing generative ai by backpropagating language model feedback.Nature, 639(8055):609–616, 2025
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. Optimizing generative ai by backpropagating language model feedback.Nature, 639(8055):609–616, 2025
2025
-
[65]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Dynamic cheatsheet: Test-time learning with adaptive memory
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7080–7106, 2026
2026
-
[67]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 3045–3059, 2021
2021
-
[68]
Demystifying prompts in language models via perplexity estimation
Hila Gonen, Srini Iyer, Terra Blevins, Noah A Smith, and Luke Zettlemoyer. Demystifying prompts in language models via perplexity estimation. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10136–10148, 2023
2023
-
[69]
Unnatural instructions: Tuning language models with (almost) no human labor
Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. Unnatural instructions: Tuning language models with (almost) no human labor. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14409–14428, 2023
2023
-
[70]
Han Luo and Guy Laban. Dialogguard: Multi-agent psychosocial safety evaluation of sensitive llm responses.arXiv preprint arXiv:2512.02282, 2025
-
[71]
Alcuna: Large language models meet new knowledge
Xunjian Yin, Baizhou Huang, and Xiaojun Wan. Alcuna: Large language models meet new knowledge. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1397–1414, 2023
2023
-
[72]
Bbq: A hand-built bias benchmark for question answering
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thomp- son, Phu Mon Htut, and Samuel Bowman. Bbq: A hand-built bias benchmark for question answering. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2086–2105, 2022. 14
2022
-
[73]
Beyond the imitation game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on machine learning research, 2023
2023
-
[74]
Won’t get fooled again: Answering questions with false premises
Shengding Hu, Yifan Luo, Huadong Wang, Xingyi Cheng, Zhiyuan Liu, and Maosong Sun. Won’t get fooled again: Answering questions with false premises. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5626–5643, 2023
2023
-
[75]
Simcse: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 6894–6910, 2021
2021
-
[76]
Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning.Advances in Neural Information Processing Systems, 37:28858–28888, 2024
Shuyue S Li, Vidhisha Balachandran, Shangbin Feng, Jonathan S Ilgen, Emma Pierson, Pang W Koh, and Yulia Tsvetkov. Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning.Advances in Neural Information Processing Systems, 37:28858–28888, 2024
2024
-
[77]
Evaluating the moral beliefs encoded in llms.Advances in Neural Information Processing Systems, 36:51778–51809, 2023
Nino Scherrer, Claudia Shi, Amir Feder, and David Blei. Evaluating the moral beliefs encoded in llms.Advances in Neural Information Processing Systems, 36:51778–51809, 2023
2023
-
[78]
2: Question answering with questionable assumptions
Najoung Kim, Phu Mon Htut, Samuel Bowman, and Jackson Petty. 2: Question answering with questionable assumptions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8466–8487, 2023
2023
-
[79]
Youssef Benchekroun, Megi Dervishi, Mark Ibrahim, Jean-Baptiste Gaya, Xavier Martinet, Grégoire Mialon, Thomas Scialom, Emmanuel Dupoux, Dieuwke Hupkes, and Pascal Vincent. Worldsense: A synthetic benchmark for grounded reasoning in large language models.arXiv preprint arXiv:2311.15930, 2023
-
[80]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.