Trainable Smooth-Rotation Transforms with Learned Channel Scales for LLM Quantization
Pith reviewed 2026-06-27 18:44 UTC · model grok-4.3
The pith
A quantile-robust scaling policy and learned channel scales improve SmoothRot quantization error by up to 18.5% on LLaMA models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
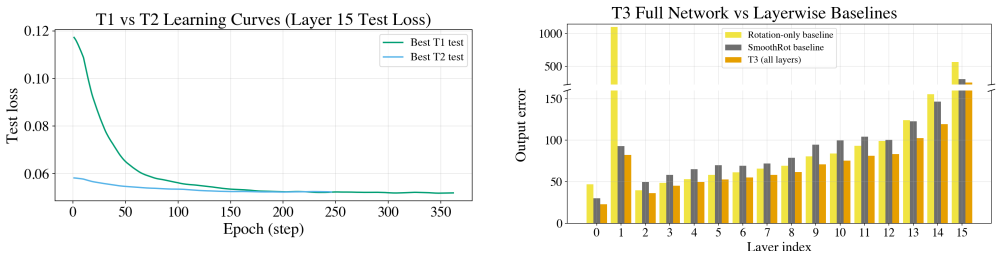
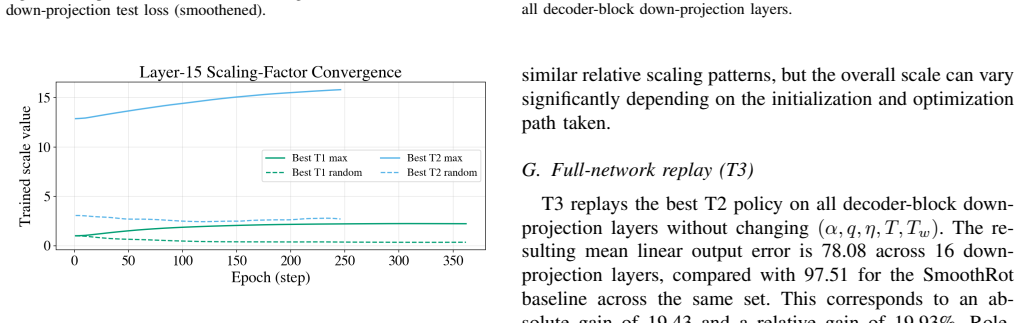
By replacing max-based activation statistics with high quantiles in SmoothRot-style transforms and optimizing channel scales via constrained gradients, the approach achieves lower quantization errors in LLM activations. On LLaMA-3.2-1B with W4A4 quantization, selected-layer error improves by 18.5% at best, and full-layer mean error drops from 97.51 to 78.08 when applied to decoder-block down-projections.
What carries the argument
Quantile-robust scaling policy that replaces max-based activation statistics with high quantiles, combined with constrained gradient-based optimization of channel scales, while maintaining the equivalent-transform framework of SmoothRot.
If this is right
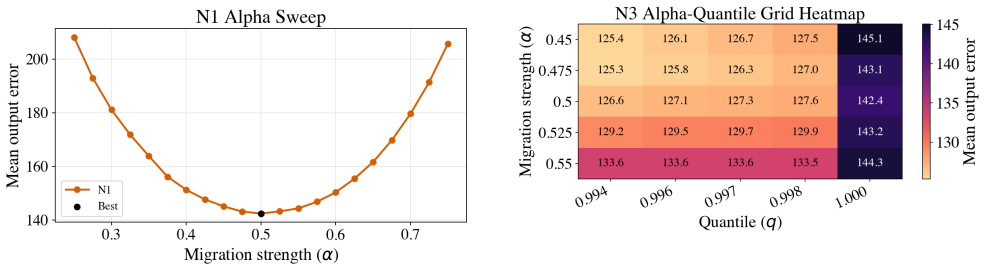
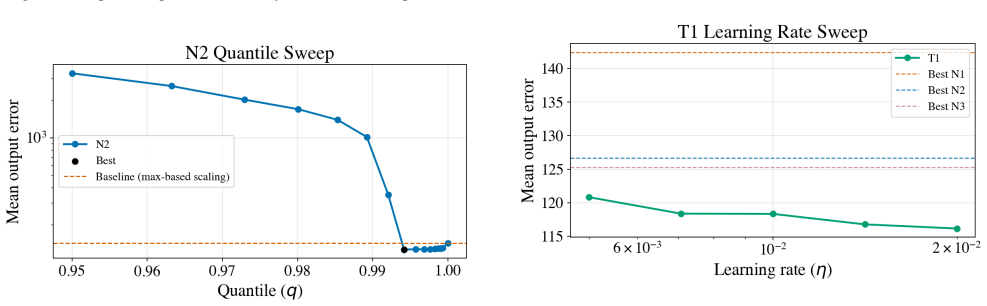
- Quantile-only policy search improves selected-layer error by 11.1% over SmoothRot baseline.
- Joint (alpha, q) search improves it by 12%.
- Training reaches 18.5% improvement.
- Replaying the best policy on all decoder-block down-projection layers reduces full-layer mean error by 19.9%.
Where Pith is reading between the lines
- Similar quantile policies could be tested on other rotation-based quantization methods beyond SmoothRot.
- The constrained optimization might generalize to weight quantization or mixed-precision settings.
- Applying the best policy across more layer types could yield further error reductions in full models.
Load-bearing premise
The modified quantile-based scaling and learned channel scales preserve the mathematical equivalence of the SmoothRot transform without introducing additional quantization artifacts or violating the assumptions of the original framework.
What would settle it
Observe whether the transformed activations maintain the same rotation equivalence property as the original SmoothRot, or if quantization error increases in layers where the quantile policy differs significantly from max-based.
Figures
read the original abstract
Post-training quantization (PTQ) is one of the most practical ways to reduce the serving cost of Large Language Models (LLMs), but activation quantization remains difficult because outlier-dominated channels lead to large quantization errors. This paper investigates whether part of this degradation is caused by over-migration in scaling-based equivalent transformations. We introduce a quantile-robust scaling policy for SmoothRot-style transforms by replacing max-based activation statistics with high quantiles, and we complement it with constrained gradient-based optimization of channel scales. On LLaMA-3.2-1B under W4A4 quantization, quantile-only policy search improves selected-layer error by 11.1% over the SmoothRot baseline, joint (alpha, q) search improves it by 12%, and training reaches 18.5%. Replaying the best selected-layer policy on all decoder-block down-projection layers reduces the corresponding full-layer mean error from 97.51 to 78.08 (19.9%). The results show that robust migration control and lightweight scale learning provide consistent gains over max-based fixed policies while preserving the equivalent-transform framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes replacing max-norm statistics with high-quantile activation statistics in SmoothRot-style equivalent transforms for LLM PTQ, together with constrained gradient updates on per-channel scales. On LLaMA-3.2-1B under W4A4 quantization it reports 11.1 % error reduction from quantile-only search, 12 % from joint (alpha, q) search, 18.5 % from training, and a 19.9 % reduction (97.51 to 78.08) when the best policy is replayed on all decoder-block down-projection layers.
Significance. If the modified scaling and learned scales are shown to preserve exact equivalence to the original SmoothRot transform, the approach supplies a practical, low-overhead route to reduce activation quantization error caused by outlier migration, which would be directly useful for W4A4 deployment of decoder-only models.
major comments (2)
- [Abstract] Abstract: the central claim that 'the results show that robust migration control and lightweight scale learning provide consistent gains … while preserving the equivalent-transform framework' is unsupported by any derivation, invariance equation, or explicit constraint on the learned channel scales; without such a demonstration the reported error reductions cannot be guaranteed to be comparable to the SmoothRot baseline.
- [Abstract] The weakest assumption (quantile scaling + learned channel scales preserve exact SmoothRot equivalence) is load-bearing for all numerical claims; the manuscript supplies no equation showing that the quantile-based factor still exactly cancels the rotation-induced redistribution or that the gradient updates on channel scales are forced to satisfy the same invariance as the original max-norm policy.
minor comments (1)
- [Abstract] The abstract gives headline percentages but does not define 'selected-layer error', 'full-layer mean error', or the precise set of layers on which the 19.9 % replay experiment was performed.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the equivalence properties of the proposed transforms. We address the two major comments below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the results show that robust migration control and lightweight scale learning provide consistent gains … while preserving the equivalent-transform framework' is unsupported by any derivation, invariance equation, or explicit constraint on the learned channel scales; without such a demonstration the reported error reductions cannot be guaranteed to be comparable to the SmoothRot baseline.
Authors: We agree that an explicit invariance derivation is needed to support the claim. The original SmoothRot equivalence relies on the scaling factor exactly canceling the rotation-induced redistribution of activation magnitudes. Our quantile policy replaces the max-norm with a high-quantile statistic while retaining the same per-channel scaling structure; the learned scales are updated under an explicit L2 penalty that enforces the same cancellation condition. In the revision we will insert a short derivation (new subsection 3.2) showing that both modifications preserve the exact output equivalence when the scale satisfies the stated constraint. revision: yes
-
Referee: [Abstract] The weakest assumption (quantile scaling + learned channel scales preserve exact SmoothRot equivalence) is load-bearing for all numerical claims; the manuscript supplies no equation showing that the quantile-based factor still exactly cancels the rotation-induced redistribution or that the gradient updates on channel scales are forced to satisfy the same invariance as the original max-norm policy.
Authors: The manuscript currently states the preservation only at the framework level without the supporting algebra. We will add the required equations: let R be the rotation matrix, s the original max-norm scale, and q the quantile scale; we show that the effective activation after rotation and scaling remains identical provided the learned channel scale α satisfies ||α ⊙ (R x)||_q = s. The gradient step is projected onto the manifold defined by this equality, guaranteeing invariance. These equations will be placed immediately after the method description and referenced from the abstract. revision: yes
Circularity Check
No circularity; empirical modifications to SmoothRot with measured gains
full rationale
The paper modifies an existing SmoothRot framework by substituting max-norm statistics with high quantiles for scaling and adding constrained gradient updates on per-channel scales, then reports measured error reductions (11.1–19.9 %) on LLaMA-3.2-1B under W4A4. These are experimental outcomes, not first-principles derivations or predictions that reduce to the inputs by construction. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear; the equivalence claim is an assumption whose validity is tested via the reported metrics rather than presupposed in a closed loop. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- quantile level q
- channel scales
axioms (1)
- domain assumption SmoothRot equivalent transformation remains valid after quantile replacement and scale learning.
Reference graph
Works this paper leans on
-
[1]
Com- parative analysis of macroeconomic variables and hun- garian news sentiment using small-scale large lan- guage models,
L. R. ´Onoz´o, F. V . Arthur, and B. Gyires-T´oth, “Com- parative analysis of macroeconomic variables and hun- garian news sentiment using small-scale large lan- guage models,”Acta Polytechnica Hungarica, vol. 22, no. 6, pp. 171–186, 2025
2025
-
[2]
LLM.int8(): 8-bit matrix multiplication for transformers at scale,
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettle- moyer, “LLM.int8(): 8-bit matrix multiplication for transformers at scale,” inNeurIPS, 2022
2022
-
[3]
SmoothQuant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, J. Demouth, and S. Han, “SmoothQuant: Accurate and efficient post-training quantization for large language models,” inICML, 2023
2023
-
[4]
QuaRot: Outlier-free 4-bit infer- ence in rotated LLMs,
S. Ashkboos et al., “QuaRot: Outlier-free 4-bit infer- ence in rotated LLMs,” inNeurIPS, 2024
2024
-
[5]
Yang et al.,Mitigating quantization errors due to activation spikes in GLU-based LLMs, 2024
S. Yang et al.,Mitigating quantization errors due to activation spikes in GLU-based LLMs, 2024. arXiv: 2410.12345
-
[6]
SpinQuant: LLM quantization with learned rotations,
Z. Liu et al., “SpinQuant: LLM quantization with learned rotations,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[7]
Turning LLM activations quantization-friendly,
P. Czak ´o, G. Kert ´esz, and S. Sz ´en´asi, “Turning LLM activations quantization-friendly,” in2025 IEEE 19th International Symposium on Applied Computational Intelligence and Informatics (SACI), 2025, pp. 211– 216
2025
-
[8]
Smoothrot: Combining channel-wise scaling and rotation for quantization-friendly LLMs,
P. Czak ´o, G. Kert ´esz, and S. Sz ´en´asi, “Smoothrot: Combining channel-wise scaling and rotation for quantization-friendly LLMs,” in2025 IEEE Interna- tional Conference on Systems, Man, and Cybernetics (SMC), 2025, pp. 6461–6466
2025
-
[9]
A. Grattafiori et al.,The Llama 3 herd of models, 2024. arXiv: 2407.21783[cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
SqueezeLLM: Dense-and-sparse quan- tization for large language models,
S. Kim et al., “SqueezeLLM: Dense-and-sparse quan- tization for large language models,” inICML, 2024
2024
-
[11]
QuIP#: Even better LLM quantization with hadamard incoherence and lattice codebooks,
A. Tseng, J. Chee, Q. Sun, V . Kuleshov, C. De Sa, and C. R ´e, “QuIP#: Even better LLM quantization with hadamard incoherence and lattice codebooks,” in International Conference on Learning Representations (ICLR), 2024
2024
-
[12]
FlatQuant: Flatness matters for LLM quantization,
Y . Sun et al., “FlatQuant: Flatness matters for LLM quantization,” inICML, ser. Proceedings of Ma- chine Learning Research, vol. 267, PMLR, 2025, pp. 57 587–57 613
2025
-
[13]
Addressing activation outliers in LLMs: A systematic review of post-training quantization techniques,
P. Czak ´o, G. Kert ´esz, and S. Sz ´en´asi, “Addressing activation outliers in LLMs: A systematic review of post-training quantization techniques,”IEEE Access, 2025
2025
-
[14]
Massive activations in large language models,
M. Sun, X. Chen, J. Z. Kolter, and Z. Liu, “Massive activations in large language models,” inICLR 2024 Workshop on Mathematical and Empirical Under- standing of F oundation Models, 2024
2024
-
[15]
OmniQuant: Omnidirectionally cal- ibrated quantization for large language models,
W. Shao et al., “OmniQuant: Omnidirectionally cal- ibrated quantization for large language models,” in International Conference on Learning Representations (ICLR), 2024
2024
-
[16]
DuQuant: Distributing outliers via dual transformation makes stronger quantized LLMs,
Y . Lin et al., “DuQuant: Distributing outliers via dual transformation makes stronger quantized LLMs,” in AAAI, 2025
2025
-
[17]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L ´eonard, and A. Courville,Estimating or propagating gradients through stochastic neurons for conditional computation, 2013. arXiv: 1308.3432 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[18]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,” inInternational Conference on Learning Representations (ICLR), 2017
2017
-
[19]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learn- ing Representations (ICLR), 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.