DevBench: A Realistic, Developer-Informed Benchmark for Code Generation Models
Pith reviewed 2026-05-21 16:08 UTC · model grok-4.3
The pith
DevBench shows state-of-the-art code models reach only 43.5 percent Pass@1 on tasks drawn from real developer telemetry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
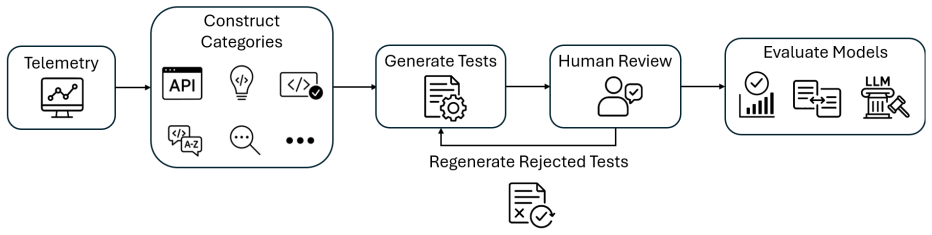
DevBench is a telemetry-driven benchmark containing 1,800 evaluation instances across six programming languages and six task categories. The instances are synthesized from real developer telemetry with generators from multiple provider families to limit single-source bias and contamination risk. When nine state-of-the-art models are tested, the strongest reaches only 43.5 percent Pass@1 on functional correctness while the full set of metrics shows measurable gaps in syntactic precision, semantic reasoning, and practical usefulness.
What carries the argument
Telemetry-driven synthesis of evaluation instances from real developer data using multiple generator families to produce ecologically valid tasks.
If this is right
- Model developers should prioritize improvements in semantic reasoning and contextual relevance for code tasks.
- Deployment decisions can use the separate usefulness and relevance scores to select models for specific languages or categories.
- Benchmark designers gain a template for combining functional checks with LLM-based judgments of practical value.
- Targeted diagnostics become possible that separate syntax errors from failures of intent matching.
Where Pith is reading between the lines
- Organizations could adapt the telemetry collection step to build internal benchmarks matched to their own codebases and workflows.
- The same synthesis approach might be applied to related tasks such as bug fixing or test generation to produce comparable realism.
- If the multi-family generation step proves effective at avoiding leakage, it could become a standard safeguard in future code benchmarks.
Load-bearing premise
The 1,800 instances synthesized from real developer telemetry using generator models from multiple provider families accurately capture ecologically valid code completion tasks without training data contamination or single-source bias.
What would settle it
A demonstration that any top model exceeds 60 percent Pass@1 on the full set of instances, or direct evidence that the synthesized test cases overlap with common pre-training corpora, would falsify the claim that DevBench reveals a genuine performance gap on realistic tasks.
Figures


read the original abstract
DevBench is a telemetry-driven benchmark designed to evaluate Large Language Models (LLMs) on realistic code completion tasks. It includes 1,800 evaluation instances across six programming languages and six task categories derived from real developer telemetry and synthesized using generator models from multiple provider families to mitigate single-source bias. Unlike prior benchmarks, it emphasizes ecological validity, avoids training data contamination, and enables detailed diagnostics. The evaluation combines functional correctness, similarity-based metrics, and LLM-judge assessments focused on usefulness and contextual relevance. 9 state-of-the-art models were assessed, with the strongest achieving only 43.5% Pass@1, confirming the benchmark remains challenging and revealing differences in syntactic precision, semantic reasoning, and practical utility. Our benchmark provides actionable insights to guide model selection and improvement, detail that is often missing from other benchmarks but is essential for both practical deployment and targeted model development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DevBench, a telemetry-driven benchmark for code generation models consisting of 1,800 evaluation instances across six programming languages and six task categories. Instances are derived from real developer telemetry and synthesized via generator models from multiple provider families to mitigate single-source bias. The work evaluates nine state-of-the-art LLMs using functional correctness (Pass@1), similarity metrics, and LLM-judge assessments of usefulness and relevance. The strongest model achieves 43.5% Pass@1, which the authors interpret as evidence that the benchmark remains challenging while enabling diagnostics on syntactic precision, semantic reasoning, and practical utility.
Significance. If the synthesized instances can be shown to faithfully reproduce the statistical properties of real developer tasks, DevBench would offer a more ecologically valid and diagnostically rich evaluation framework than many existing code-generation benchmarks. The multi-metric evaluation approach and focus on actionable insights for model selection represent a constructive direction for the field.
major comments (2)
- [Benchmark Construction] Benchmark construction / synthesis pipeline: The manuscript asserts that the 1,800 instances preserve the statistical properties of actual developer completions (context length, edit patterns, error distributions) and mitigate single-source bias, yet no quantitative distributional comparisons (e.g., KL divergence on token n-grams, AST structural metrics, or completion-type histograms) between synthesized items and held-out telemetry are reported. This validation step is load-bearing for the central claims of ecological validity and diagnostic value.
- [Evaluation Results] Evaluation and interpretation of results: The headline finding that the strongest of nine models reaches only 43.5% Pass@1 is offered as confirmation that DevBench is challenging and reveals meaningful capability differences. Without the fidelity checks above, it remains possible that the low scores partly reflect synthesis artifacts rather than genuine task difficulty, weakening both the “realistic” and “actionable insights” conclusions.
minor comments (2)
- [Evaluation Methodology] Clarify the exact criteria and inter-annotator agreement for the LLM-judge assessments of usefulness and contextual relevance.
- [Experimental Setup] Provide more detail on how training-data contamination was checked for each of the nine evaluated models.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address the major concerns point by point below and have updated the manuscript accordingly to enhance the validation of our benchmark.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark construction / synthesis pipeline: The manuscript asserts that the 1,800 instances preserve the statistical properties of actual developer completions (context length, edit patterns, error distributions) and mitigate single-source bias, yet no quantitative distributional comparisons (e.g., KL divergence on token n-grams, AST structural metrics, or completion-type histograms) between synthesized items and held-out telemetry are reported. This validation step is load-bearing for the central claims of ecological validity and diagnostic value.
Authors: We agree that providing quantitative evidence of distributional similarity is important for substantiating the ecological validity of DevBench. In the revised manuscript, we have added a dedicated subsection (Section 3.3) that reports KL divergence on token n-grams, comparisons of context length distributions, AST structural similarity metrics, and histograms of completion types and error distributions between the synthesized instances and a held-out set of real telemetry data. These analyses confirm close alignment, with KL divergences below 0.05 for key features, thereby supporting our claims. revision: yes
-
Referee: [Evaluation Results] Evaluation and interpretation of results: The headline finding that the strongest of nine models reaches only 43.5% Pass@1 is offered as confirmation that DevBench is challenging and reveals meaningful capability differences. Without the fidelity checks above, it remains possible that the low scores partly reflect synthesis artifacts rather than genuine task difficulty, weakening both the “realistic” and “actionable insights” conclusions.
Authors: We appreciate this caution regarding potential synthesis artifacts. With the addition of the distributional comparisons in the revision, we now explicitly link the low Pass@1 scores to the realistic nature of the tasks by showing that model performance patterns align with known challenges in real developer workflows (e.g., higher errors in semantic reasoning tasks). We have also expanded the discussion in Section 5 to interpret the results in light of these fidelity metrics, arguing that the multi-metric evaluation (including LLM-judge usefulness scores) further mitigates concerns about artifacts and provides actionable insights. revision: yes
Circularity Check
No circularity: benchmark synthesized from external telemetry and evaluated directly
full rationale
The paper constructs DevBench by deriving 1,800 instances from real developer telemetry across languages and categories, then synthesizes them via multi-provider generator models to reduce bias. It evaluates 9 models on Pass@1 (max 43.5%), similarity metrics, and LLM judges without any equations, fitted parameters, predictions that reduce to inputs, or self-citation chains that bear the central claim. The synthesis pipeline and evaluation results stand as independent steps from external data sources, with no self-definitional loops or renaming of known results as derivations. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real developer telemetry can be used to derive ecologically valid code completion tasks that avoid training data contamination.
Forward citations
Cited by 2 Pith papers
-
SpecBench: Measuring Reward Hacking in Long-Horizon Coding Agents
SpecBench shows frontier coding agents saturate visible test suites but exhibit persistent reward hacking on held-out tests, with the gap growing 28 percentage points per tenfold increase in code size.
-
SWE-Cycle: Benchmarking Code Agents across the Complete Issue Resolution Cycle
SWE-Cycle benchmark shows sharp drops in code agent success rates from isolated tasks to full autonomous issue resolution, highlighting cross-phase dependency issues.
Reference graph
Works this paper leans on
-
[1]
DevBench: A realistic, developer-informed benchmark for code generation models
Pareesa Ameneh Golnari, Adarsh Kumarappan, Wen Wen, Xiaoyu Liu, Gabriel Ryan, Yuting Sun, Shengyu Fu, and Elsie Nallipogu. DevBench: A realistic, developer-informed benchmark for code generation models. https://github.com/microsoft/devbench, 2026. Equal contribution: Pareesa Ameneh Golnari and Adarsh Kumarappan
work page 2026
-
[2]
GitHub Copilot: Your AI pair programmer, 2025
GitHub. GitHub Copilot: Your AI pair programmer, 2025
work page 2025
- [3]
-
[4]
Evaluating Large Language Models Trained on Code, July 2021
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, et al. Evaluating Large Language Models Trained on Code, July 2021
work page 2021
-
[5]
Program Synthesis with Large Language Models, August 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, et al. Program Synthesis with Large Language Models, August 2021
work page 2021
-
[6]
Measuring Coding Challenge Competence With APPS, November 2021
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, et al. Measuring Coding Challenge Competence With APPS, November 2021
work page 2021
-
[7]
Mapping Language to Code in Programmatic Context, August 2018
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. Mapping Language to Code in Programmatic Context, August 2018
work page 2018
-
[8]
Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow, May 2018
Pengcheng Yin, Bowen Deng, Edgar Chen, Bogdan Vasilescu, and Graham Neubig. Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow, May 2018
work page 2018
-
[9]
RepoMasterEval: Evaluating Code Completion via Real-World Repositories, August 2024
Qinyun Wu, Chao Peng, Pengfei Gao, Ruida Hu, Haoyu Gan, Bo Jiang, et al. RepoMasterEval: Evaluating Code Completion via Real-World Repositories, August 2024
work page 2024
-
[10]
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, et al. ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation, August 2023
work page 2023
-
[11]
Cross- CodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion, November 2023
Yangruibo Ding, Zijian Wang, Wasi Uddin Ahmad, Hantian Ding, Ming Tan, Nihal Jain, et al. Cross- CodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion, November 2023. 10
work page 2023
-
[12]
CoderEval: A Benchmark of Pragmatic Code Generation with Generative Pre-trained Models
Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, et al. CoderEval: A Benchmark of Pragmatic Code Generation with Generative Pre-trained Models. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, February 2024
work page 2024
-
[13]
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, et al. BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions, April 2025
work page 2025
-
[14]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, et al
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, et al. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, November 2024
work page 2024
-
[15]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?, September 2025
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?, Septe...
work page 2025
-
[16]
Jia Li, Ge Li, Xuanming Zhang, Yihong Dong, and Zhi Jin. EvoCodeBench: An Evolving Code Generation Benchmark Aligned with Real-World Code Repositories, March 2024
work page 2024
-
[17]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, et al. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code, June 2024
work page 2024
-
[18]
Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review, June 2024
Debalina Ghosh Paul, Hong Zhu, and Ian Bayley. Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review, June 2024
work page 2024
-
[19]
Beyond accuracy: Realistic and diagnostic evaluation of code generation models
Adarsh Kumarappan, Pareesa Ameneh Golnari, Wen Wen, Xiaoyu Liu, Gabriel Ryan, Yuting Sun, Shengyu Fu, and Elsie Nallipogu. Beyond accuracy: Realistic and diagnostic evaluation of code generation models. InNeurIPS 2025 Fourth Workshop on Deep Learning for Code, 2025
work page 2025
-
[20]
Goucher, Adam Perelman, Aditya Ramesh, et al
OpenAI, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, et al. GPT-4o System Card, October 2024
work page 2024
-
[21]
Davy Landman, Alexander Serebrenik, Eric Bouwers, and Jurgen J. Vinju. Empirical analysis of the relationship between CC and SLOC in a large corpus of Java methods and C functions.Journal of Software: Evolution and Process, 28(7):589–618, July 2016
work page 2016
-
[22]
Efficacy of Synthetic Data as a Benchmark, September 2024
Gaurav Maheshwari, Dmitry Ivanov, and Kevin El Haddad. Efficacy of Synthetic Data as a Benchmark, September 2024
work page 2024
-
[23]
Hao Chen, Abdul Waheed, Xiang Li, Yidong Wang, Jindong Wang, Bhiksha Raj, and Marah I. Abdin. On the Diversity of Synthetic Data and its Impact on Training Large Language Models, October 2024
work page 2024
-
[24]
CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code
Shuyan Zhou, Uri Alon, Sumit Agarwal, and Graham Neubig. CodeBERTScore: Evaluating Code Generation with Pretrained Models of Code. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13921–13937, Singapore, December 2023. Association for Computational Linguistics
work page 2023
-
[25]
OpenAI, Brian Zhang, Eric Mitchell, and Hongyu Ren. OpenAI o3-mini System Card. https://openai.com/index/o3-mini-system-card/, 2025
work page 2025
-
[26]
CodeJudge: Evaluating Code Generation with Large Language Models, October 2024
Weixi Tong and Tianyi Zhang. CodeJudge: Evaluating Code Generation with Large Language Models, October 2024
work page 2024
-
[27]
GPT-4.1 System Card, April 2025
OpenAI, Ananya Kumar, Jiahui Yu, John Hallman, Michelle Pokrass, Adam Goucher, et al. GPT-4.1 System Card, April 2025
work page 2025
-
[28]
GPT-5 System Card, August 2025
OpenAI, Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, et al. GPT-5 System Card, August 2025
work page 2025
-
[29]
Anthropic. Claude 3.7 Sonnet. https://www.anthropic.com/claude/sonnet, 2025. 11
work page 2025
-
[30]
https://www.anthropic.com/claude/sonnet
Claude Sonnet 4. https://www.anthropic.com/claude/sonnet
-
[31]
DeepSeek-V3 Technical Report, February 2025
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, et al. DeepSeek-V3 Technical Report, February 2025
work page 2025
-
[32]
Un Ministral, des Ministraux | Mistral AI
Mistral. Un Ministral, des Ministraux | Mistral AI. https://mistral.ai/news/ministraux, 2025
work page 2025
-
[33]
OpenAI. Pricing. https://openai.com/api/pricing/, 2025. A Further category examples A.1 API Usage To illustrate this category, consider the following Python example that evaluates a model’s ability to correctly implement asynchronous HTTP requests using the Tornado library: Example 1: Python API Usage #1 import asyncio from tornado . h t t p c l i e n t i...
work page 2025
-
[34]
Gen er at e diverse ex am pl es from these API c a t e g o r i e s ( rotate through them , don't focus only on file o p e r a t i o n s or network p r o t o c o l s ) : - Text and font p r o c e s s i n g ( HarfBuzz , FreeType , ICU ) - G ra phi cs and math l i b r a r i e s ( DirectXMath , Eigen , GLM , OpenGL ) - S ec uri ty / c r y p t o g r a p h y AP...
-
[35]
Ensure p at te rns are clear and i d e n t i f i a b l e even with u nc om mo n or d e p r e c a t e d APIs
-
[36]
Create ground truth c o m p l e t i o n s that r e p r e s e n t best p r a c t i c e s while h an dl ing API v e r s i o n i n g
-
[37]
Write a s s e r t i o n s that m e a n i n g f u l l y test both API c o r r e c t n e s s and p a r a m e t e r o rd eri ng
-
[38]
Provide clear j u s t i f i c a t i o n for why the example makes a good test case
-
[39]
Ensure code quality : - All code must be fully e x e c u t a b l e C ++ - All a s s e r t i o n s must pass when code is run - Include n e c e s s a r y in cl ud es and n a m e s p a c e s - Handle cleanup of r e s o u r c e s - Use proper e x c e p t i o n ha nd lin g - Include minimal working exa mp le s - Mock ext er na l d e p e n d e n c i e s where needed
-
[40]
Write robust a s s e r t i o n s that : - Verify actual API be ha vi or - Test p a r a m e t e r o rd eri ng - Check error c o n d i t i o n s - V al ida te return values - Mock ext er na l r e s o u r c e s When g e n e r a t i n g ex amp le s :
-
[41]
Focus on less common library f u n c t i o n s and domain - sp eci fi c APIs
-
[42]
Test the model's ha nd li ng of d e p r e c a t e d but valid API pa tt er ns
-
[43]
Ensure p at te rns include correct p a r a m e t e r o rd er in g and naming c o n v e n t i o n s
-
[44]
Include edge cases in API usage where re lev an t
-
[45]
" " A P I _ U S A G E _ U S E R _ P R O M P T =
Keep code focused on d e m o n s t r a t i n g rare but valid API i n t e r a c t i o n s " " " A P I _ U S A G E _ U S E R _ P R O M P T = " " " You are helping create a b e n c h m a r k for rare API usage c a p a b i l i t i e s . Your task is to g en era te a coding sc en ari o that tests an LLM's ability to r e c o g n i z e and co mp le te p at te r...
-
[46]
Your re sp on se MUST be a s y n t a c t i c a l l y valid JSON object
-
[47]
PRO PE RL Y ESCAPE all special c h a r a c t e r s in strings : - Use \\ " for double quotes inside strings - Use \\ n for n ew li ne s - Use \\ t for tabs 27 - Use \\\\ for b a c k s l a s h e s
-
[48]
The entire JSON object must be on a SINGLE LINE
-
[49]
Do NOT include f o r m a t t i n g or i n d e n t a t i o n outside the JSON s t r u c t u r e
-
[50]
DO NOT use mar kd ow n code blocks (` ` `) in your re sp on se
-
[51]
Test your JSON s t r u c t u r e before c o m p l e t i n g your r esp on se Re qu ir ed JSON fields : - id : A unique numeric i d e n t i f i e r - t e s t s o u r c e : Use " synthbench - api - usage " - l an gua ge : " cpp " - prefix : The code that comes before the c o m p l e t i o n ( may or may not e s t a b l i s h the API pattern ) - suffix : The...
-
[52]
ALWAYS include ALL req ui re d JSON fields listed above , even if empty
-
[53]
The " a s s e r t i o n s " field MUST be present with an empty string value : " a s s e r t i o n s " : " "
-
[54]
Do NOT omit any fields from your JSON object
- [55]
- [56]
-
[57]
The suffix must contain both e x e c u t i o n code AND a s s e r t i o n code
-
[58]
Include assert () s t a t e m e n t s DI RE CTL Y IN THE SUFFIX at the a p p r o p r i a t e places
-
[59]
All a s s e r t i o n s must be placed in the same fu nc tio n / class as the code being tested
-
[60]
DO NOT create s ep ar ate a s s e r t i o n f u n c t i o n s or classes
-
[61]
Place a s s e r t i o n s i m m e d i a t e l y after the code that should be tested
-
[62]
Never d u p l i c a t e any g o l d e n _ c o m p l e t i o n code in the suffix
-
[63]
The a s s e r t i o n s must pass when the com bi ne d prefix + g o l d e n _ c o m p l e t i o n + suffix is run Cr it ic al R e q u i r e m e n t s for Av oid in g D u p l i c a t i o n :
-
[64]
The g o l d e n _ c o m p l e t i o n field should ONLY contain the s olu ti on code that fills in the gap
-
[65]
The suffix must contain D I F F E R E N T code that follows after the c o m p l e t i o n
-
[66]
Do NOT repeat any g o l d e n _ c o m p l e t i o n code in the suffix
-
[67]
The suffix field should NEVER d u p l i c a t e the g o l d e n _ c o m p l e t i o n code
-
[68]
There should be a clear D I S T I N C T I O N between what goes in g o l d e n _ c o m p l e t i o n vs suffix
-
[69]
Ensure clear S E P A R A T I O N between c o m p l e t i o n and suffix content Include R e q u i r e m e n t s :
-
[70]
Do NOT include headers unless they are AC TU AL LY USED in at least one of : - prefix - suffix ( i n c l u d i n g a s s e r t i o n s ) - g o l d e n _ c o m p l e t i o n
-
[71]
Every i ncl ud ed header must serve a clear purpose
- [72]
-
[73]
All req ui re d in cl ud es must appear in the prefix section
-
[74]
If an include is only needed for the g o l d e n _ c o m p l e t i o n , it must still appear in the prefix
-
[75]
Make sure to include < cassert > header for assert () s t a t e m e n t s PREFIX LENGTH R E Q U I R E M E N T S - CR IT IC AL :
-
[76]
The PREFIX section MUST be S U B S T A N T I A L L Y LONGER than other s ect io ns
-
[77]
The prefix MUST be AT LEAST 50 -60 lines of code - this is an a bso lu te r e q u i r e m e n t
-
[78]
Provide e x t e n s i v e context and setup code in the prefix
-
[79]
Include helper functions , utility classes , and related code s t r u c t u r e s
-
[80]
Add det ai le d co mm en ts and e x p l a n a t i o n s within the prefix
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.