Same Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws
Pith reviewed 2026-05-22 08:45 UTC · model grok-4.3
The pith
The same Transformer architecture realizes different spectral scaling laws under different optimizers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
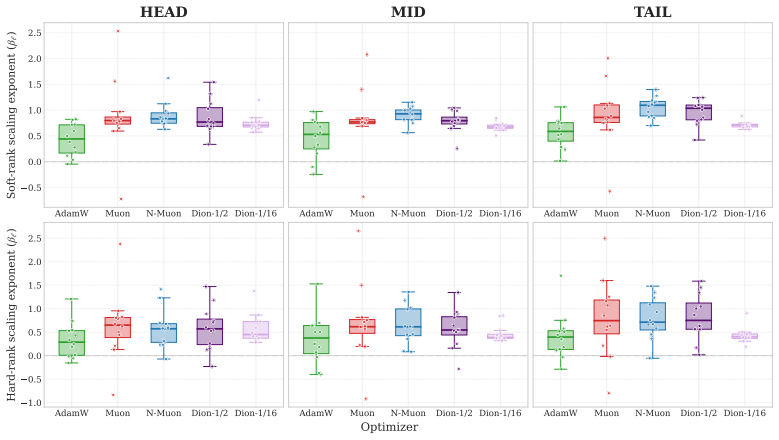
Holding architecture and width schedule fixed, the same Transformer architecture realizes markedly different spectral scaling laws when trained with different optimizers. On rare-token representations, AdamW exhibits weak hard-rank scaling with exponent 0.44 while Muon achieves linear scaling with exponent 1.02. This difference is not reducible to validation loss, since AdamW runs can match the perplexity of lower-rank configurations yet display sharply different spectral geometry. Hard-soft rank asymmetry further shows that optimizers differ both in the amount of capacity realized and in how that capacity is distributed across eigenmodes. Optimizer-induced spectral shifts frequently exceed,
What carries the argument
Eigenspectra of feed-forward network representations measured by soft and hard spectral ranks, which quantify the effective dimensionality the optimizer makes available to the model.
If this is right
- Matched perplexity does not guarantee matched representation structure or spectral geometry.
- Optimizer effects on spectral scaling can be larger than those produced by changes to attention rank or positional encoding.
- Representation capacity depends on how an optimizer distributes utilization across eigenmodes, revealed by hard-soft rank differences.
- Scaling behavior should be studied with optimizer as an explicit variable rather than a fixed detail.
Where Pith is reading between the lines
- Scaling-law predictions could become more accurate by incorporating optimizer-specific exponents for spectral utilization.
- Training runs might benefit from selecting optimizers that maximize hard-rank growth on tail tokens to improve generalization at fixed width.
- The interaction between optimizer and layer type could be tested to see whether spectral advantages appear outside feed-forward blocks.
Load-bearing premise
That soft and hard spectral ranks computed from feed-forward network representations supply a faithful measure of utilized spectral capacity that remains comparable across different optimizers.
What would settle it
Training identical models with AdamW and Muon until both reach the same perplexity and the same hard spectral rank on rare tokens would contradict the claim of optimizer-specific scaling laws.
Figures









read the original abstract
Scaling laws have made language-model performance predictable from model size, data, and compute, but they typically treat the optimizer as a fixed training detail. We show that this assumption misses a fundamental axis of representation scaling: how effectively the optimizer converts added FFN width into utilized spectral capacity. Using eigenspectra of feed-forward network representations, measured through soft and hard spectral-ranks, we find that \emph{the same Transformer architecture realizes markedly different spectral scaling laws when trained with different optimizers}. Holding architecture and width schedule fixed, AdamW exhibits weak hard-rank scaling ($\beta$=0.44) on rare-token (TAIL) representations where learning is known to be hardest, whereas Muon achieves linear scaling ($\beta$=1.02) in the same regimes, a $2.3\times$ increase in the scaling exponent. This difference is not reducible to validation loss: AdamW configurations can match low-rank Dion variants in perplexity, under extended training, while exhibiting sharply different spectral geometry, demonstrating that matched loss does not imply matched representation structure. Hard--soft rank asymmetry further reveals that optimizers differ not only in how much capacity is realized, but also in how that capacity is structured across eigenmodes. To disentangle optimizer effects from architectural ones, we compare against architectural interventions (e.g., attention rank and positional encoding), and find that optimizer-induced spectral shifts often exceed the architectural effects. These results suggest optimization as a first-class axis of representation scaling, motivating optimizer--architecture co-design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the same Transformer architecture, with fixed width schedule, realizes different spectral scaling laws under different optimizers. Using soft and hard spectral ranks derived from FFN representations, it reports that AdamW exhibits weak hard-rank scaling (β=0.44) on rare-token (TAIL) representations while Muon achieves linear scaling (β=1.02), a 2.3× difference; this dissociation persists even when perplexity is matched via extended training, and optimizer-induced shifts exceed those from architectural interventions such as attention rank or positional encodings.
Significance. If the central measurements are robust, the work establishes optimization as an independent axis of representation scaling that is not captured by loss alone. The explicit comparison of optimizer effects against architectural controls, together with the hard–soft rank asymmetry, supplies a concrete empirical basis for optimizer–architecture co-design in large language models.
major comments (3)
- [Methods] Methods section: The procedure for extracting FFN activations, computing eigenspectra, and defining the hard-rank threshold (including any normalization or token-sampling controls) is not described in sufficient detail. Without explicit controls ensuring that activation statistics and token distributions are matched across AdamW and Muon runs, it remains possible that observed rank differences arise from optimizer-dependent sparsity or scale rather than from genuine differences in utilized spectral capacity.
- [§4] Scaling-law fits (abstract and §4): The reported exponents β=0.44 and β=1.02 are obtained by fitting power laws to the same rank-versus-width observations used to demonstrate the optimizer difference. This makes the scaling laws descriptive summaries rather than independent predictions; the manuscript should clarify whether any out-of-sample validation or theoretical motivation for the functional form was performed.
- [Experimental Setup] Experimental controls: While the abstract notes that some AdamW runs were extended to match perplexity, the text does not report whether total training steps, data order, or batch composition were equalized for the TAIL-token spectral measurements. This control is load-bearing for the claim that geometry differences are optimizer-induced rather than artifacts of unequal optimization trajectories.
minor comments (2)
- [Abstract] Abstract: The numerical values β=0.44 and β=1.02 should be accompanied by standard errors or confidence intervals when first stated.
- [Figures] Figures: Plots showing eigenvalue decay or rank-versus-width should include the exact hard-rank threshold used and clearly distinguish optimizer curves with consistent line styles across panels.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating the revisions we will make to improve clarity, reproducibility, and the robustness of our claims.
read point-by-point responses
-
Referee: [Methods] Methods section: The procedure for extracting FFN activations, computing eigenspectra, and defining the hard-rank threshold (including any normalization or token-sampling controls) is not described in sufficient detail. Without explicit controls ensuring that activation statistics and token distributions are matched across AdamW and Muon runs, it remains possible that observed rank differences arise from optimizer-dependent sparsity or scale rather than from genuine differences in utilized spectral capacity.
Authors: We agree that greater methodological detail is required for reproducibility and to rule out potential confounds. In the revised manuscript we will expand the Methods section with a precise, step-by-step account of FFN activation extraction, eigenspectra computation, the exact definition of the hard-rank threshold (including the eigenvalue cutoff, normalization procedure, and any scaling), and the token-sampling protocol. We will also add explicit verification that mean activation statistics and token-frequency distributions are matched across the AdamW and Muon runs used for the reported comparisons, thereby supporting that the observed spectral differences reflect genuine differences in utilized capacity rather than optimizer-induced sparsity or scale artifacts. revision: yes
-
Referee: [§4] Scaling-law fits (abstract and §4): The reported exponents β=0.44 and β=1.02 are obtained by fitting power laws to the same rank-versus-width observations used to demonstrate the optimizer difference. This makes the scaling laws descriptive summaries rather than independent predictions; the manuscript should clarify whether any out-of-sample validation or theoretical motivation for the functional form was performed.
Authors: We acknowledge that the reported exponents are obtained by fitting power laws directly to the rank-versus-width observations presented in the paper and therefore function as descriptive summaries of the empirical trends rather than independent, out-of-sample predictions. The power-law functional form is motivated by prior literature on spectral scaling in neural representations. No out-of-sample validation was performed in the current experiments. In the revision we will explicitly state this descriptive character in §4 and the abstract, supply the relevant theoretical motivation from the spectral-scaling literature, and note the limitation regarding predictive validation. revision: partial
-
Referee: [Experimental Setup] Experimental controls: While the abstract notes that some AdamW runs were extended to match perplexity, the text does not report whether total training steps, data order, or batch composition were equalized for the TAIL-token spectral measurements. This control is load-bearing for the claim that geometry differences are optimizer-induced rather than artifacts of unequal optimization trajectories.
Authors: We appreciate the importance of this control. For the perplexity-matched AdamW runs, total training steps were extended while preserving identical data order and batch composition with the corresponding Muon runs; only the number of steps was adjusted to reach perplexity parity. TAIL-token spectral measurements were performed on token samples drawn from the same data distribution and ordering. In the revised manuscript we will add an explicit paragraph in the Experimental Setup section documenting these controls and confirming that the TAIL measurements used matched token subsets. revision: yes
Circularity Check
Spectral scaling exponents reduce to power-law fits on measured rank-vs-width data
specific steps
-
fitted input called prediction
[Abstract]
"Holding architecture and width schedule fixed, AdamW exhibits weak hard-rank scaling (β=0.44) on rare-token (TAIL) representations where learning is known to be hardest, whereas Muon achieves linear scaling (β=1.02) in the same regimes, a 2.3× increase in the scaling exponent."
The β exponents are computed by fitting a power-law form (hard-rank ∝ width^β) to the empirically measured hard spectral ranks collected at multiple widths. The scaling law is therefore a curve fit to the same observations it purports to describe, not an independent prediction from optimizer dynamics or first principles.
full rationale
The paper's core claim is that AdamW and Muon induce different spectral scaling laws (quantified by hard-rank exponent β) for the same architecture. These β values are obtained by fitting power laws directly to the observed hard spectral rank versus width measurements on TAIL tokens. This makes the reported scaling laws descriptive summaries of the input data rather than independent derivations or predictions. The comparison to architectural interventions adds some external content, but the optimizer-induced scaling result itself is a post-hoc fit. No self-citation chains, self-definitions, or ansatz smuggling were found in the derivation of the scaling exponents.
Axiom & Free-Parameter Ledger
free parameters (1)
- hard-rank scaling exponent β
axioms (1)
- domain assumption Spectral ranks computed from FFN activations measure utilized capacity in a manner comparable across optimizers
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using eigenspectra of feed-forward network representations, measured through soft and hard spectral-ranks... AdamW exhibits weak hard-rank scaling (β=0.44) on rare-token (TAIL) representations... Muon achieves linear scaling (β=1.02)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[3]
Razvan Pascanu, Clare Lyle, Ionut-Vlad Modoranu, Naima Elosegui Borras, Dan Alistarh, Petar Velickovic, Sarath Chandar, Soham De, and James Martens. Optimizers qualitatively alter solutions and we should leverage this.arXiv preprint arXiv:2507.12224, 2025
-
[4]
Old Optimizer, New Norm: An Anthology
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Towards robust scaling laws for optimizers.arXiv preprint arXiv:2602.07712, 2026
Alexandra V olkova, Mher Safaryan, Christoph H Lampert, and Dan Alistarh. Towards robust scaling laws for optimizers.arXiv preprint arXiv:2602.07712, 2026
-
[6]
Nerve: Nonlinear eigenspectrum dynamics in llm feed- forward networks
Nandan Kumar Jha and Brandon Reagen. Nerve: Nonlinear eigenspectrum dynamics in llm feed- forward networks. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[7]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InEmpirical Methods in Natural Language Processing (EMNLP), 2021
work page 2021
-
[8]
Nandan Kumar Jha and Brandon Reagen. Spectral scaling laws in language models: How effectively do feed-forward networks use their latent space? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
work page 2025
-
[9]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[10]
Muon: An optimizer for hidden layers in neural networks.URL https://kellerjordan
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cecista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks.URL https://kellerjordan. github. io/posts/muon, 2024
work page 2024
-
[11]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Normuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491,
Zichong Li, Liming Liu, Chen Liang, Weizhu Chen, and Tuo Zhao. Normuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491, 2025
-
[13]
Dion: Distributed Orthonormalized Updates
Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
-
[14]
Large language models struggle to learn long-tail knowledge
Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. Large language models struggle to learn long-tail knowledge. InInternational conference on machine learning (ICML), 2023
work page 2023
-
[15]
Quality over quantity in attention layers: When adding more heads hurts
Noah Amsel, Gilad Yehudai, and Joan Bruna. Quality over quantity in attention layers: When adding more heads hurts. InThe Thirteenth International Conference on Learning Representa- tions (ICLR), 2025
work page 2025
-
[16]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. InNeurocomputing, 2024. 13
work page 2024
-
[17]
Ta-Chung Chi, Ting-Han Fan, Li-Wei Chen, Alexander Rudnicky, and Peter Ramadge. Latent positional information is in the self-attention variance of transformer language models without positional embeddings. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2023
work page 2023
-
[18]
Adam: A method for stochastic optimization
Diederik P Kingma. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR), 2015
work page 2015
-
[19]
Adafactor: Adaptive learning rates with sublinear memory cost
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. InInternational Conference on Machine Learning (ICML), 2018
work page 2018
-
[20]
Scaling laws and symmetry, evidence from neural force fields
Khang Ngo and Siamak Ravanbakhsh. Scaling laws and symmetry, evidence from neural force fields. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[21]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning (ICML), 2018
work page 2018
-
[22]
Nikhil Vyas, Depen Morwani, Rosie Zhao, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham M. Kakade. SOAP: Improving and stabilizing shampoo using adam for language modeling. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[23]
Training deep learning models with norm-constrained lmos
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and V olkan Cevher. Training deep learning models with norm-constrained lmos. InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[24]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In 15th European signal processing conference, 2007
work page 2007
-
[25]
Quentin Garrido, Randall Balestriero, Laurent Najman, and Yann Lecun. RankMe: Assessing the downstream performance of pretrained self-supervised representations by their rank. In International conference on machine learning (ICML), 2023
work page 2023
-
[26]
Diff-erank: A novel rank-based metric for evaluating large language models
Lai Wei, Zhiquan Tan, Chenghai Li, Jindong Wang, and Weiran Huang. Diff-erank: A novel rank-based metric for evaluating large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[27]
Layer by layer: Uncovering hidden representations in language models
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Nikul Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models. In Forty-second International Conference on Machine Learning (ICML), 2025
work page 2025
-
[28]
Rank Is Not Capacity: Spectral Occupancy for Latent Graph Models
Nikolaos Nakis, Panagiotis Promponas, Konstantinos Tsirkas, Katerina Mamali, Eftychia Makri, Leandros Tassiulas, and Nicholas A Christakis. Rank is not capacity: Spectral occupancy for latent graph models.arXiv preprint arXiv:2605.11142, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Convergence of muon with newton-schulz
Gyu Yeol Kim and Min hwan Oh. Convergence of muon with newton-schulz. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[30]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[31]
Fantastic pretraining optimizers and where to find them
Kaiyue Wen, David Leo Wright Hall, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[32]
Re-parameterizing your optimizers rather than architectures
Xiaohan Ding, Honghao Chen, Xiangyu Zhang, Kaiqi Huang, Jungong Han, and Guiguang Ding. Re-parameterizing your optimizers rather than architectures. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[33]
PoLAR: Polar-decomposed low-rank adapter representation
Kai Lion, Liang Zhang, Bingcong Li, and Niao He. PoLAR: Polar-decomposed low-rank adapter representation. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 14
work page 2025
-
[34]
On measures of entropy and information
Alfréd Rényi. On measures of entropy and information. InProceedings of the fourth Berkeley symposium on mathematical statistics and probability, volume 1: contributions to the theory of statistics, 1961
work page 1961
-
[35]
Rényi divergence and kullback-leibler divergence
Tim Van Erven and Peter Harremos. Rényi divergence and kullback-leibler divergence. InIEEE Transactions on Information Theory, 2014
work page 2014
-
[36]
A theory of multineuronal dimensionality, dynamics and measurement.BioRxiv, 2017
Peiran Gao, Eric Trautmann, Byron Yu, Gopal Santhanam, Stephen Ryu, Krishna Shenoy, and Surya Ganguli. A theory of multineuronal dimensionality, dynamics and measurement.BioRxiv, 2017
work page 2017
-
[37]
Yu Hu and Haim Sompolinsky. The spectrum of covariance matrices of randomly connected recurrent neuronal networks with linear dynamics.PLoS computational biology, 2022
work page 2022
-
[38]
Slow transition to low-dimensional chaos in heavy-tailed recurrent neural networks
Yi Xie, Stefan Mihalas, and Łukasz Ku ´smierz. Slow transition to low-dimensional chaos in heavy-tailed recurrent neural networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[39]
What are you sinking? a geometric approach on attention sink
Valeria Ruscio, Umberto Nanni, and Fabrizio Silvestri. What are you sinking? a geometric approach on attention sink. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[40]
Scaling laws for gradient descent and sign descent for linear bigram models under zipf’s law
Frederik Kunstner and Francis Bach. Scaling laws for gradient descent and sign descent for linear bigram models under zipf’s law. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[41]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlí ˇcek, Anton Lozhkov, Margaret Mitchell, Colin A Raffel, Leandro V on Werra, Thomas Wolf, et al. The fineweb datasets: Decanting the web for the finest text data at scale. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[42]
modded-nanogpt: Speedrunning the nanogpt baseline, 2024
Keller Jordan, Jeremy Bernstein, Brendan Rappazzo, @fernbear.bsky.social, Boza Vlado, You Jiacheng, Franz Cesista, Braden Koszarsky, and @Grad62304977. modded-nanogpt: Speedrunning the nanogpt baseline, 2024
work page 2024
-
[43]
Searching for efficient transformers for language modeling
David So, Wojciech Ma´nke, Hanxiao Liu, Zihang Dai, Noam Shazeer, and Quoc V Le. Searching for efficient transformers for language modeling. InAdvances in neural information processing systems (NeurIPS), 2021
work page 2021
-
[44]
Scaling vision transformers to 22 billion parameters
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. InInternational Conference on Machine Learning (ICML), 2023
work page 2023
-
[45]
What can transformers learn in-context? a case study of simple function classes
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. InAdvances in neural information processing systems (NeurIPS), 2022
work page 2022
-
[46]
The impact of positional encoding on length generalization in transformers
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, and Siva Reddy. The impact of positional encoding on length generalization in transformers. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[47]
Extending the context of pretrained LLMs by dropping their positional embedding
Yoav Gelberg, Koshi Eguchi, Takuya Akiba, and Edoardo Cetin. Extending the context of pretrained LLMs by dropping their positional embedding. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[48]
A spectral condition for feature learning
Greg Yang, James B Simon, and Jeremy Bernstein. A spectral condition for feature learning. arXiv preprint arXiv:2310.17813, 2023
-
[49]
Symbolic discovery of optimization algorithms
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V Le. Symbolic discovery of optimization algorithms. InThirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023. 15
work page 2023
-
[50]
Springer Science & Business Media, 2010
Jose C Principe.Information theoretic learning: Renyi’s entropy and kernel perspectives. Springer Science & Business Media, 2010
work page 2010
-
[51]
On layer normalization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. On layer normalization in the transformer architecture. InInternational Conference on Machine Learning (ICML), 2020
work page 2020
-
[52]
Towards understanding inductive bias in transform- ers: A view from infinity
Itay Lavie, Guy Gur-Ari, and Zohar Ringel. Towards understanding inductive bias in transform- ers: A view from infinity. InForty-first International Conference on Machine Learning (ICML), 2024. 16 Appendix A Experimental Setup 18 A.1 Model architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 A.2 Training protocol . . . . . ....
work page 2024
-
[53]
Lowering the AdamW learning rate to 10−4 avoids divergence up to PostLN-75, but it reaches to PPL = 106.7 , compared with PPL = 40.9 for Muon and PPL = 32.8 for NorMuon. Thus, AdamW can be made stable only by moving to a substantially worse optimization regime, whereas Muon-family optimizers train these partial PostLN configurations at useful perplexity. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.