Task-Aware Structured Memory for Dynamic Multi-modal In-Context Learning
Pith reviewed 2026-06-27 10:25 UTC · model grok-4.3
The pith
Task-vector guided compression and bipartite graph token merging create query-adaptive hierarchical memory for multi-modal in-context learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
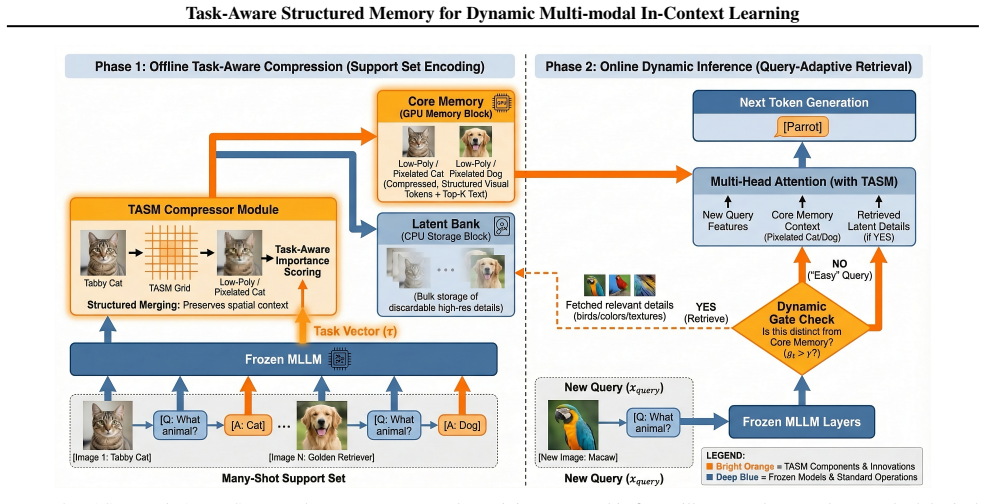
TASM constructs task-aware structured memory through task-vector guided compression that substitutes sample-specific signals with a task-level direction, semantics-aware token merging via bipartite graph matching that aggregates tokens without destructive pruning, and a hierarchical layout of Core Memory plus Latent Bank that enables query-adaptive dynamic retrieval.
What carries the argument
Task-Aware Structured Memory (TASM) using task-vector guided compression to capture shared relevance and bipartite graph matching for semantics-aware token merging.
If this is right
- Heavy compression of key-value caches becomes feasible without large performance drops on multi-modal tasks.
- Memory access can adapt to each new query through the hierarchical Core Memory and Latent Bank structure.
- Bias from sample-dependent importance scoring is avoided by shifting to task-level direction.
- Semantic structure in visual token sequences is retained through merging rather than removal.
Where Pith is reading between the lines
- The same compression pattern could be tested on longer uni-modal sequences or additional modalities.
- Integration with existing multi-modal models requires no parameter updates, lowering deployment barriers.
- Dynamic retrieval from the Latent Bank may reduce average inference latency on repeated task types.
Load-bearing premise
Task-vector compression can replace sample-specific signals with a shared task-level direction while bipartite graph matching preserves the underlying semantic manifold without destructive pruning or bias.
What would settle it
A controlled test in which TASM-compressed memory produces measurably lower accuracy than an uncompressed baseline on a multi-modal in-context learning benchmark at the same compression ratio.
Figures

read the original abstract
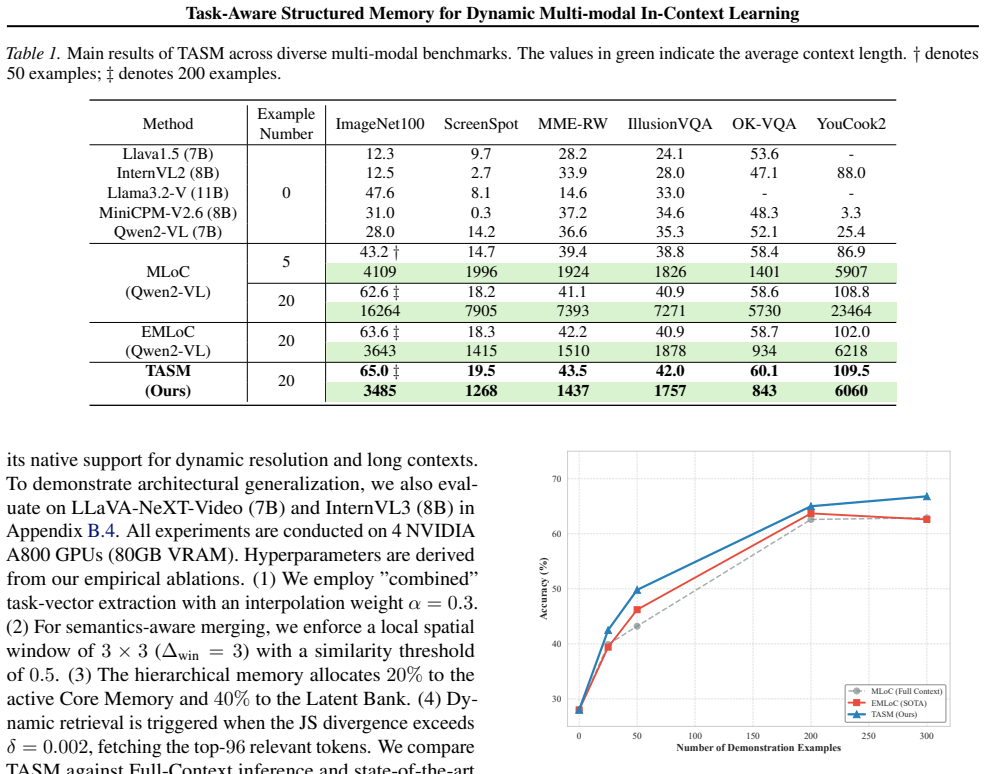
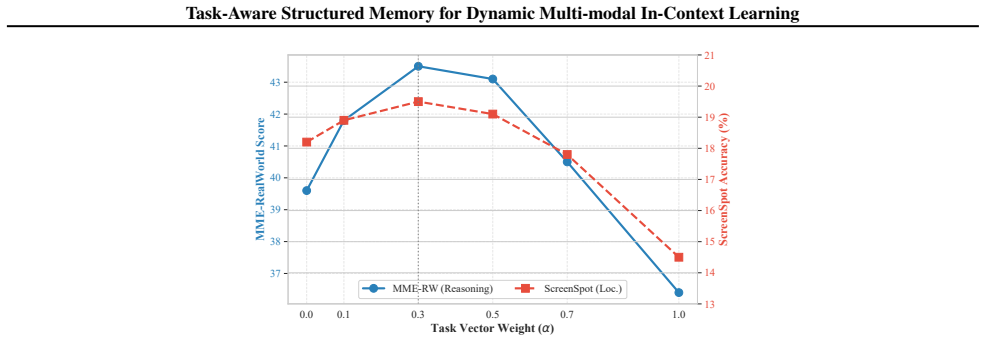
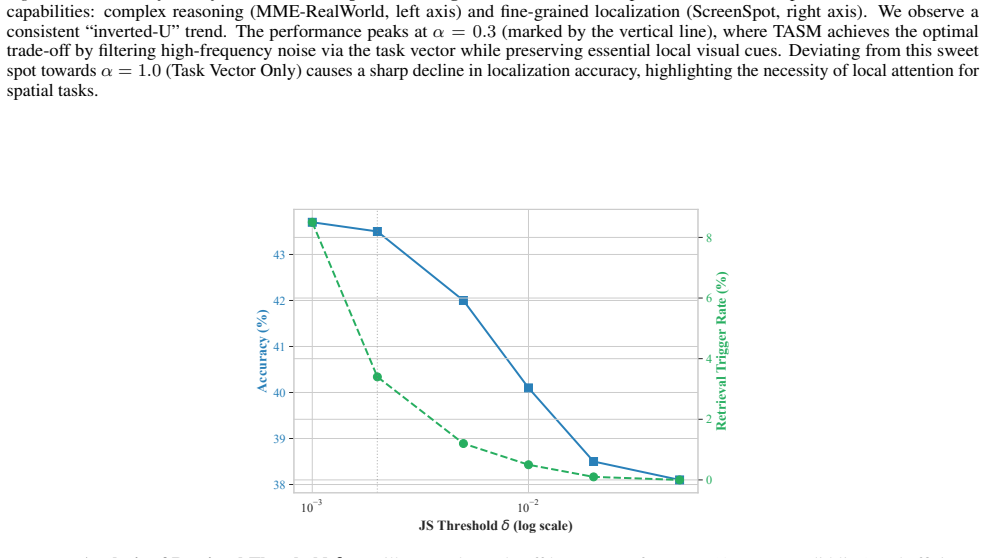
Multi-modal large language models (MLLMs) depend on in-context learning (ICL) for rapid task adaptation, but their scalability is severely limited by finite context windows and the growing cost of key-value (KV) caches in long multi-modal sequences. Existing memory compression approaches typically rely on rigid token removal or sample-dependent importance estimation, which introduces bias, disrupts semantic structure, particularly for visual representations, and yields static memories that cannot adapt to new queries. We introduce TASM (Task-Aware Structured Memory), a training-free framework that addresses these limitations through task-aware, structure-preserving, and dynamically accessible memory construction. TASM employs task-vector guided compression to replace sample-specific signals with a task-level direction that captures shared relevance across demonstrations. To preserve the underlying manifold, it applies semantics-aware token merging via bipartite graph matching, aggregating tokens without destructive pruning. Finally, TASM structures memory into a hierarchy comprising a compact Core Memory and a Latent Bank, facilitating query-adaptive dynamic retrieval. Evaluations confirm TASM maintains high performance under heavy compression, effectively balancing efficiency with adaptability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TASM, a training-free framework for task-aware structured memory in dynamic multi-modal in-context learning for MLLMs. It replaces sample-specific signals with task-vector guided compression, applies semantics-aware token merging via bipartite graph matching to preserve the underlying manifold, and organizes memory hierarchically into a compact Core Memory and Latent Bank to enable query-adaptive dynamic retrieval. The abstract asserts that evaluations confirm maintained high performance under heavy compression while balancing efficiency and adaptability.
Significance. If the empirical claims hold, the work would address a practical bottleneck in scaling ICL for multi-modal models by offering a dynamic, structure-preserving alternative to rigid token removal or sample-dependent methods. The training-free design and explicit targeting of bias and manifold disruption are strengths that could influence follow-on compression techniques.
major comments (2)
- [Abstract] Abstract: the central performance claim ('evaluations confirm TASM maintains high performance under heavy compression') is unsupported because the manuscript provides no quantitative results, ablation studies, tables, figures, or implementation details. This is load-bearing for the primary assertion that the method balances efficiency with adaptability.
- [Method overview] Method overview: the assumption that task-vector guided compression can replace sample-specific signals with a shared task-level direction, and that bipartite graph matching preserves the manifold without destructive pruning or bias, is stated but not reduced to any verifiable quantity or falsifiable test within the manuscript.
Simulated Author's Rebuttal
We thank the referee for the comments. We address each major point below and indicate where revisions are needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim ('evaluations confirm TASM maintains high performance under heavy compression') is unsupported because the manuscript provides no quantitative results, ablation studies, tables, figures, or implementation details. This is load-bearing for the primary assertion that the method balances efficiency with adaptability.
Authors: We agree the abstract claim requires supporting evidence. The provided manuscript text contains only the method description and does not include any quantitative results, tables, figures, or ablation studies. We will revise the abstract to remove or qualify the performance claim until the full experimental evidence is incorporated. revision: yes
-
Referee: [Method overview] Method overview: the assumption that task-vector guided compression can replace sample-specific signals with a shared task-level direction, and that bipartite graph matching preserves the manifold without destructive pruning or bias, is stated but not reduced to any verifiable quantity or falsifiable test within the manuscript.
Authors: The manuscript presents the design rationale for task-vector compression and bipartite merging but does not include explicit metrics (e.g., manifold distance measures or bias quantification) or dedicated falsification experiments for these assumptions. We can add such targeted measurements in a revision if required. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces a training-free TASM framework relying on task-vector guided compression and bipartite graph matching for token merging. These steps are presented as direct algorithmic constructions without reduction to fitted parameters from the authors' prior work, self-definitional loops, or load-bearing self-citations. The central claims rest on the explicit method definitions and empirical evaluations rather than renaming or smuggling in prior ansatzes. The derivation chain is self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Token embeddings and task vectors preserve semantic relevance across demonstrations
- domain assumption Bipartite graph matching aggregates tokens without destroying the data manifold
invented entities (2)
-
Core Memory
no independent evidence
-
Latent Bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2023 , month = sep, howpublished =
2023
-
[2]
From Few to Many: Self-Improving Many-Shot Reasoners Through Iterative Optimization and Generation , booktitle =
Xingchen Wan and Han Zhou and Ruoxi Sun and Sercan. From Few to Many: Self-Improving Many-Shot Reasoners Through Iterative Optimization and Generation , booktitle =. 2025 , url =
2025
-
[3]
Large Multimodal Model Compression via Iterative Efficient Pruning and Distillation , booktitle =
Maolin Wang and Yao Zhao and Jiajia Liu and Jingdong Chen and Chenyi Zhuang and Jinjie Gu and Ruocheng Guo and Xiangyu Zhao , editor =. Large Multimodal Model Compression via Iterative Efficient Pruning and Distillation , booktitle =. 2024 , url =. doi:10.1145/3589335.3648321 , timestamp =
-
[4]
Hehai Lin and Hui Liu and Shilei Cao and Jing Li and Haoliang Li and Wenya Wang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2511.05883 , eprinttype =. 2511.05883 , timestamp =
-
[5]
Parameterized Static Analysis for Weak Memory Models , booktitle =
Divyanjali Sharma and Subodh Sharma , editor =. Parameterized Static Analysis for Weak Memory Models , booktitle =. 2024 , url =. doi:10.1145/3641399.3641443 , timestamp =
-
[6]
Joint Enhancement of Relational Reasoning for Long-Context LLM s
Chen, Zhirui and Shen, Wei and Huang, Jiashui and Shao, Ling. Joint Enhancement of Relational Reasoning for Long-Context LLM s. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.462
-
[7]
2025 , institution =
2025
-
[8]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[9]
M. J. Kearns , title =
-
[10]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[11]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[12]
Suppressed for Anonymity , author=
-
[13]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[14]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[15]
Hu, Shengding and Tu, Yuge and Han, Xu and He, Chaoqun and Cui, Ganqu and Long, Xiang and Zheng, Zhi and Fang, Yewei and Huang, Yuxiang and Zhao, Weilin and others , journal=
-
[16]
McKinzie, Brandon and Gan, Zhe and Fauconnier, Jean-Philippe and Dodge, Sam and Zhang, Bowen and Dufter, Philipp and Shah, Dhruti and Du, Xianzhi and Peng, Futang and Weers, Floris and others , journal=
-
[17]
arXiv preprint arXiv:2405.02246 , year=
What matters when building vision-language models? , author=. arXiv preprint arXiv:2405.02246 , year=
-
[18]
XTuner Contributors , howpublished =
-
[19]
Li, Bo and Zhang, Kaichen and Zhang, Hao and Guo, Dong and Zhang, Renrui and Li, Feng and Zhang, Yuanhan and Liu, Ziwei and Li, Chunyuan , year=
-
[20]
arXiv preprint arXiv:2402.11530 , year=
Efficient Multimodal Learning from Data-centric Perspective , author=. arXiv preprint arXiv:2402.11530 , year=
-
[21]
Introducing our multimodal models , author =
-
[22]
Young, Alex and Chen, Bei and Li, Chao and Huang, Chengen and Zhang, Ge and Zhang, Guanwei and Li, Heng and Zhu, Jiangcheng and Chen, Jianqun and Chang, Jing and others , journal=
-
[23]
Liu, Yuliang and Yang, Biao and Liu, Qiang and Li, Zhang and Ma, Zhiyin and Zhang, Shuo and Bai, Xiang , journal=
-
[24]
Wang, Weihan and Lv, Qingsong and Yu, Wenmeng and Hong, Wenyi and Qi, Ji and Wang, Yan and Ji, Junhui and Yang, Zhuoyi and Zhao, Lei and Song, Xixuan and others , journal=
-
[25]
Chu, Xiangxiang and Qiao, Limeng and Lin, Xinyang and Xu, Shuang and Yang, Yang and Hu, Yiming and Wei, Fei and Zhang, Xinyu and Zhang, Bo and Wei, Xiaolin and others , journal=
-
[26]
Li, Yanwei and Zhang, Yuechen and Wang, Chengyao and Zhong, Zhisheng and Chen, Yixin and Chu, Ruihang and Liu, Shaoteng and Jia, Jiaya , journal=
-
[27]
Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , journal=
-
[28]
arXiv preprint arXiv:2203.15556 , year=
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
-
[29]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=
-
[30]
Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Sun, Maosong and Huang, Gao , journal=
-
[31]
Byeon, Minwoo and Park, Beomhee and Kim, Haecheon and Lee, Sungjun and Baek, Woonhyuk and Kim, Saehoon , year =
-
[32]
Schuhmann, Christoph and Beaumont, Romain and Vencu, Richard and Gordon, Cade and Wightman, Ross and Cherti, Mehdi and Coombes, Theo and Katta, Aarush and Mullis, Clayton and Wortsman, Mitchell and others , journal=
-
[33]
Lu, Haoyu and Liu, Wen and Zhang, Bo and Wang, Bingxuan and Dong, Kai and Liu, Bo and Sun, Jingxiang and Ren, Tongzheng and Li, Zhuoshu and Sun, Yaofeng and others , journal=
-
[34]
Zhang, Ao and Fei, Hao and Yao, Yuan and Ji, Wei and Li, Li and Liu, Zhiyuan and Chua, Tat-Seng , journal=
-
[35]
2023 , howpublished =
Javaheripi, Mojan and Bubeck, Sébastien , title =. 2023 , howpublished =
2023
-
[36]
Ao Zhang and Yuan Yao and Wei Ji and Zhiyuan Liu and Tat-Seng Chua , journal=
-
[37]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , journal=
-
[38]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[39]
2024 , howpublished =
Banks, Jeanine and Warkentin, Tris , title =. 2024 , howpublished =
2024
-
[40]
Driess, Danny and Xia, Fei and Sajjadi, Mehdi SM and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and others , journal=
-
[41]
2023 , organization=
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , journal=. 2023 , organization=
2023
-
[42]
Alayrac, Jean-Baptiste and Donahue, Jeff and Luc, Pauline and Miech, Antoine and Barr, Iain and Hasson, Yana and Lenc, Karel and Mensch, Arthur and Millican, Katherine and Reynolds, Malcolm and others , journal=
-
[43]
Sparks of artificial general intelligence: Early experiments with
Bubeck, S. Sparks of artificial general intelligence: Early experiments with. arXiv preprint arXiv:2303.12712 , year=
-
[44]
ICML , pages=
Learning transferable visual models from natural language supervision , author=. ICML , pages=. 2021 , organization=
2021
-
[45]
Sun, Quan and Fang, Yuxin and Wu, Ledell and Wang, Xinlong and Cao, Yue , journal=
-
[46]
NeurIPS , volume=
Object scene representation transformer , author=. NeurIPS , volume=
-
[47]
NeurIPS , volume=
Language is not all you need: Aligning perception with language models , author=. NeurIPS , volume=
-
[48]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[49]
Peng, Zhiliang and Wang, Wenhui and Dong, Li and Hao, Yaru and Huang, Shaohan and Ma, Shuming and Wei, Furu , journal=
-
[50]
OpenCompass Contributors , howpublished =
-
[51]
Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving
Chaoyou Fu and Yuhan Dai and Yongdong Luo and Lei Li and Shuhuai Ren and Renrui Zhang and Zihan Wang and Chenyu Zhou and Yunhang Shen and Mengdan Zhang and Peixian Chen and Yanwei Li and Shaohui Lin and Sirui Zhao and Ke Li and Tong Xu and Xiawu Zheng and Enhong Chen and Caifeng Shan and Ran He and Xing Sun , title =. 2025 , url =. doi:10.1109/CVPR52734.2...
-
[52]
Visual Haystacks:
Tsung. Visual Haystacks:. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[53]
Fu, Chaoyou and Chen, Peixian and Shen, Yunhang and Qin, Yulei and Zhang, Mengdan and Lin, Xu and Yang, Jinrui and Zheng, Xiawu and Li, Ke and Sun, Xing and Wu, Yunsheng and Ji, Rongrong , journal=
-
[54]
Liu, Yuan and Duan, Haodong and Zhang, Yuanhan and Li, Bo and Zhang, Songyang and Zhao, Wangbo and Yuan, Yike and Wang, Jiaqi and He, Conghui and Liu, Ziwei and others , journal=
-
[55]
On the hidden mystery of
Liu, Yuliang and Li, Zhang and Li, Hongliang and Yu, Wenwen and Huang, Mingxin and Peng, Dezhi and Liu, Mingyu and Chen, Mingrui and Li, Chunyuan and Jin, Lianwen and others , journal=. On the hidden mystery of
-
[56]
arXiv preprint arXiv:1809.02156 , year=
Object hallucination in image captioning , author=. arXiv preprint arXiv:1809.02156 , year=
-
[57]
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and others , booktitle=
-
[58]
arXiv preprint arXiv:2404.14219 , year=
Phi-3 technical report: A highly capable language model locally on your phone , author=. arXiv preprint arXiv:2404.14219 , year=
-
[59]
Lu, Pan and Bansal, Hritik and Xia, Tony and Liu, Jiacheng and Li, Chunyuan and Hajishirzi, Hannaneh and Cheng, Hao and Chang, Kai-Wei and Galley, Michel and Gao, Jianfeng , journal=
-
[60]
arXiv preprint arXiv:2308.12038 , year=
Large multilingual models pivot zero-shot multimodal learning across languages , author=. arXiv preprint arXiv:2308.12038 , year=
-
[61]
Chen, Keqin and Zhang, Zhao and Zeng, Weili and Zhang, Richong and Zhu, Feng and Zhao, Rui , journal=
-
[62]
Liu, Zechun and Zhao, Changsheng and Iandola, Forrest and Lai, Chen and Tian, Yuandong and Fedorov, Igor and Xiong, Yunyang and Chang, Ernie and Shi, Yangyang and Krishnamoorthi, Raghuraman and others , journal=
-
[63]
arXiv preprint arXiv:2205.01068 , year=
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
-
[64]
JMLR , volume=
Scaling instruction-finetuned language models , author=. JMLR , volume=
-
[65]
Chowdhery, Aakanksha and Narang, Sharan and Devlin, Jacob and Bosma, Maarten and Mishra, Gaurav and Roberts, Adam and Barham, Paul and Chung, Hyung Won and Sutton, Charles and Gehrmann, Sebastian and others , journal=
-
[66]
arXiv preprint arXiv:2302.13971 , year=
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. arXiv preprint arXiv:2302.13971 , year=
-
[67]
ECCV , pages=
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. ECCV , pages=. 2014 , organization=
2014
-
[68]
See https://vicuna
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90\ author=. See https://vicuna. lmsys. org (accessed 14 April 2023) , volume=
2023
-
[69]
, year =
OpenAI. , year =. Hello
-
[70]
, year =
Google Deepmind. , year =
-
[71]
Antol, Stanislaw and Agrawal, Aishwarya and Lu, Jiasen and Mitchell, Margaret and Batra, Dhruv and Zitnick, C Lawrence and Parikh, Devi , booktitle=
-
[72]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
nocaps: Novel object captioning at scale , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[73]
Marino, Kenneth and Rastegari, Mohammad and Farhadi, Ali and Mottaghi, Roozbeh , booktitle=
-
[74]
2017 , publisher=
Krishna, Ranjay and Zhu, Yuke and Groth, Oliver and Johnson, Justin and Hata, Kenji and Kravitz, Joshua and Chen, Stephanie and Kalantidis, Yannis and Li, Li-Jia and Shamma, David A and others , journal=. 2017 , publisher=
2017
-
[75]
Xie, Chunyu and Li, Jincheng and Zhang, Baochang , year=
-
[76]
Srinivasan, Krishna and Raman, Karthik and Chen, Jiecao and Bendersky, Michael and Najork, Marc , booktitle=
-
[77]
ECCV , pages=
Biten, Ali Furkan and Tito, Rub. ECCV , pages=. 2022 , organization=
2022
-
[78]
Kim, Geewook and Hong, Teakgyu and Yim, Moonbin and Nam, JeongYeon and Park, Jinyoung and Yim, Jinyeong and Hwang, Wonseok and Yun, Sangdoo and Han, Dongyoon and Park, Seunghyun , booktitle =
-
[79]
CVPR , pages=
Synthetic data for text localisation in natural images , author=. CVPR , pages=
-
[80]
arXiv preprint arXiv:2403.00231 , year=
Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models , author=. arXiv preprint arXiv:2403.00231 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.