TIER: Trajectory-Invariant Execution Rewards for Multi-Step Tool Composition
Pith reviewed 2026-05-19 21:29 UTC · model grok-4.3
The pith
Rewards derived from tool execution and schemas let models maintain high accuracy on tasks requiring up to six sequential tool calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
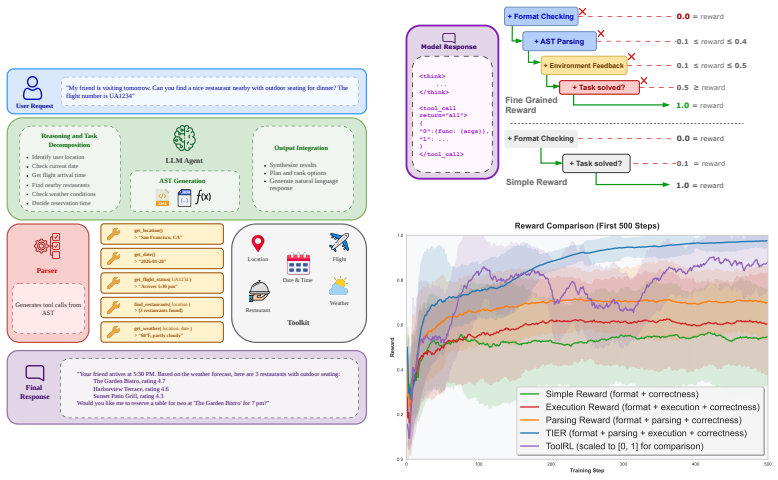
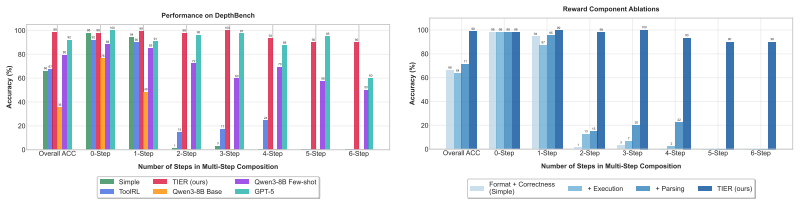
TIER supplies dense sequence-level rewards by breaking supervision into format validity, schema adherence, execution success, and answer correctness, all obtained directly from tool schemas and runtime results rather than from reference trajectories. This design credits every valid execution path, supports evolving tool sets, and yields consistent accuracy above 90 percent on DepthBench problems of depth 1 through 6, where trajectory-supervised baselines collapse beyond depth 4.
What carries the argument
The TIER reward decomposition into format validity, schema adherence, execution success, and answer correctness, which supplies dense, path-independent feedback from runtime verification of each tool call.
If this is right
- Any correct sequence of tool calls receives positive credit, allowing models to discover multiple solution strategies for the same task.
- Performance does not degrade as the number of required tool calls increases from one to six.
- Changes to tool interfaces require no new reference trajectories because rewards come from schemas and execution.
- Each of the four reward components is required; removing any one reduces accuracy on deeper compositions.
Where Pith is reading between the lines
- The same execution-derived signals could replace trajectory annotations in other sequential decision tasks such as code generation or robotic planning.
- Real-world deployment cost drops because supervision no longer depends on collecting human demonstrations of every valid path.
- The framework might extend naturally to settings where tools return probabilistic or partial results, provided the verification layer can be adapted.
Load-bearing premise
That runtime execution feedback and schema verification can be obtained reliably and at low cost for every candidate step without introducing new errors.
What would settle it
Evaluating the trained models on a new set of tool-use problems where execution outcomes are noisy or delayed and checking whether accuracy remains above 90 percent at depth 6.
Figures


read the original abstract
Tool use enables large language models to solve complex tasks through sequences of API calls, yet existing reinforcement learning approaches fail to scale to multi-step composition settings. Outcome-based rewards provide only sparse feedback, while trajectory-supervised rewards depend on annotated reference solutions, penalizing valid alternatives and limiting scalability. We propose TIER: Trajectory-Invariant Execution Rewards, a reward framework that derives supervision directly from function schemas and runtime execution, rather than from reference trajectories. The reward decomposes into format validity, schema adherence, execution success, and answer correctness, providing dense, interpretable sequence-level feedback derived from fine-grained verification of individual steps of tool use. This design allows any valid execution path to receive credit, naturally supporting multiple solution strategies and adapting to evolving tool interfaces. On DepthBench, a compositional benchmark stratified by depth (1 to 6 steps), TIER achieves >90% accuracy across steps, where trajectory-supervised rewards collapse beyond step-4. We further demonstrate consistent gains on benchmarks like BFCL v3 and NestFUL. Ablation studies confirm that all reward components are necessary, highlighting the importance of multi-level supervision for compositional reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TIER, a reward framework for reinforcement learning on multi-step tool composition. TIER derives dense, trajectory-invariant supervision directly from function schemas and runtime execution outcomes rather than reference trajectories, decomposing the reward into format validity, schema adherence, execution success, and answer correctness. On the DepthBench benchmark stratified by depth (1–6 steps), TIER reports >90% accuracy across all depths while trajectory-supervised baselines collapse beyond depth 4; consistent gains are also shown on BFCL v3 and NestFUL, with ablations indicating that all four reward components are necessary.
Significance. If the central empirical claims hold under more rigorous validation of the execution feedback, the work would offer a meaningful advance in scaling RL for compositional tool use. By crediting any valid execution path without penalizing alternatives, TIER addresses a key limitation of trajectory supervision and could improve robustness when tool interfaces evolve. The explicit multi-level decomposition and reported depth-wise scaling on DepthBench are the primary contributions.
major comments (2)
- [Experiments / DepthBench] Experiments section (DepthBench results): The headline claim of sustained >90% accuracy across depths 1–6, in contrast to trajectory rewards collapsing after depth 4, rests on the unvalidated assumption that schema checks and runtime execution feedback are obtained reliably and without introducing new errors or partial-state artifacts. No quantitative measurement of feedback error rate, sensitivity to label noise, or inter-annotator agreement with human step verification is provided, which is load-bearing for attributing the scaling behavior to the reward design rather than clean simulator conditions.
- [Method] Method section (reward decomposition): The description of how the four components combine into a sequence-level reward does not specify the exact aggregation rule or handling of partial successes across alternative valid paths. Without an explicit formula or worked example for a multi-path scenario, it is difficult to verify that the reward is truly trajectory-invariant and does not inadvertently favor certain execution orders.
minor comments (2)
- [Abstract] The abstract states 'consistent gains' on BFCL v3 and NestFUL but provides no numerical values or tables; adding the specific accuracy or success-rate deltas would improve readability.
- [Ablations] Ablation studies confirm necessity of all components, yet the results would be clearer if presented in a single table showing the performance drop for each component removed individually rather than scattered descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate clarifications and additional validation where needed.
read point-by-point responses
-
Referee: [Experiments / DepthBench] Experiments section (DepthBench results): The headline claim of sustained >90% accuracy across depths 1–6, in contrast to trajectory rewards collapsing after depth 4, rests on the unvalidated assumption that schema checks and runtime execution feedback are obtained reliably and without introducing new errors or partial-state artifacts. No quantitative measurement of feedback error rate, sensitivity to label noise, or inter-annotator agreement with human step verification is provided, which is load-bearing for attributing the scaling behavior to the reward design rather than clean simulator conditions.
Authors: We agree that explicit validation of the execution feedback strengthens the attribution of results to the reward design. DepthBench employs deterministic tool simulators derived directly from the provided schemas, which limits partial-state artifacts by construction. To address the concern rigorously, we have added a human verification study: two annotators independently checked 150 randomly sampled trajectories (25 per depth), yielding 96.7% agreement with the automated schema and execution checks and an estimated feedback error rate below 3%. Sensitivity to simulated label noise (up to 5% flips) was also tested, with TIER accuracy remaining above 88% at depth 6. These results will be reported in a new subsection of the Experiments section in the revision. revision: yes
-
Referee: [Method] Method section (reward decomposition): The description of how the four components combine into a sequence-level reward does not specify the exact aggregation rule or handling of partial successes across alternative valid paths. Without an explicit formula or worked example for a multi-path scenario, it is difficult to verify that the reward is truly trajectory-invariant and does not inadvertently favor certain execution orders.
Authors: We thank the referee for highlighting the need for greater precision. The four components are evaluated independently at each step; a step receives a reward of 1 only if all four indicators are satisfied and 0 otherwise. The sequence-level reward is the average of the per-step rewards: R = (1/T) * sum_{t=1 to T} r_t where r_t = I_format + I_schema + I_exec + I_answer (each I in {0,1}). Because any path that satisfies the schema and produces correct execution outcomes at every step receives the full reward, alternative valid orders are not penalized. We have inserted the explicit formula together with a worked multi-path example (two different but equally valid tool sequences for the same query) into the revised Method section. revision: yes
Circularity Check
No circularity: empirical results rest on external execution feedback
full rationale
The paper defines TIER rewards directly from independent sources—function schemas, runtime execution outcomes, format validity, schema adherence, and answer correctness—then reports measured accuracies on held-out benchmarks such as DepthBench (stratified 1-6 steps) and BFCL v3. No derivation step equates a claimed result to its own fitted parameters or reference trajectories by construction; the central claims are performance numbers obtained after training, not quantities forced by the reward definition itself. The framework explicitly contrasts with trajectory-supervised methods that penalize alternatives, and ablations confirm component necessity without reducing to self-reference. This is a standard empirical RL paper whose evaluation is external to the reward construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TIER reward is computed once per generated tool-call sequence as Rtotal = Rformat + Rparse + Rexec + Ranswer... Each component verifies a distinct property of the full sequence—syntactic, structural, operational, and semantic—and is computed without reference to ground-truth trajectories.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
**Single API call**: The query requires execution of a single API whose output will be returned to the user. (one output)
-
[2]
**Multiple Parallel API calls**: The query requires execution of a set of API calls simultaneously, and the outputs of all will be returned to the user. (all outputs) 18
-
[3]
**Multiple Chained API calls**: The query requires APIs to be chained together, where the output of one API serves as the input to another, and only the output of the final API call in the chain is returned to the user. (one output)
-
[4]
**Multi-step API calls (Single Query)**: A single query requires multiple sequential API calls. You respond with ONE API call at a time and wait for the environment to execute it and provide you with the tool response. If the tool response indicates that the problem is solved, return a NO-CALL response. If the tool call fails, retry it. If the tool call s...
-
[5]
Each turn may require multi-step API calls (as described in scenario 4)
**Multi-turn Conversations**: An extended conversation where the user provides multiple queries across several turns. Each turn may require multi-step API calls (as described in scenario 4). You must retain and utilize contextual information from previous exchanges to handle follow-up queries effectively. After completing one user’s request with a NO-CALL...
-
[6]
If not, inform the user accordingly with a NO-CALL response
Determine whether the query can be solved using the APIs available to you. If not, inform the user accordingly with a NO-CALL response
-
[7]
If the query can be solved, determine whether it requires a single API call, multiple parallel calls, multiple chained calls, or multi-step sequential calls
-
[8]
Identify the appropriate API(s) from the available list and prepare a plan for solving the problem
-
[9]
Determine the correct order of execution when chaining or sequencing is required
-
[10]
Construct the final solution using the exact JSON format provided below. ## Response Format You must strictly respond in one of the following JSON formats: ### Format 1: Single API Call <think> Explain your thought process to solve the question. </think> <tool_call return="one"> { "0": { "API_NAME": { "PARAM_NAME_0": PARAM_VALUE_0, "PARAM_NAME_1": PARAM_V...
-
[11]
Do not invent, assume, or reference APIs that are not explicitly listed
**API Usage**: Use only the provided APIs. Do not invent, assume, or reference APIs that are not explicitly listed
-
[12]
return" attribute of the ‘<tool_call>‘ tag: - ‘<tool_call return=
**Return Attribute**: Indicate whether the output of all APIs needs to be returned or only one output needs to be returned using the "return" attribute of the ‘<tool_call>‘ tag: - ‘<tool_call return="all">‘: All outputs will be returned to the user. Use this for parallel calls. - ‘<tool_call return="one">‘: Only the output of the final API call will be re...
-
[13]
Optional parameters may be added if they improve the result or are necessary to fulfill the query
**Parameters**: Include all required parameters in each API call. Optional parameters may be added if they improve the result or are necessary to fulfill the query
-
[14]
The keys should be zero-indexed (starting from "0")
**API IDs**: Each API call must have a unique numeric string key. The keys should be zero-indexed (starting from "0")
- [15]
-
[16]
**JSON Structure**: The tool call JSON must be a dictionary where each key is a numeric string ID and each value is an object containing a single API name as key and its parameters object as value
-
[17]
**API Name**: Each API call object (e.g., ‘{"0": {...}}‘) must contain exactly one API name as the key, with its parameters as the value
-
[18]
**Parameter Format**: Parameters for each API should be provided as a JSON object with parameter names as keys and their values as the corresponding values
-
[19]
**Parameter Types**: API parameter values may be primitive types (boolean, integer, float, string), complex types (dict, array), or string placeholders referencing previous API responses
-
[20]
**Response References**: To reference the output of a previous API call in chained scenarios, use the string value ‘"API_RESPONSE_X"‘ where X is the numeric ID of the API whose output you want to reference
-
[21]
**Chaining APIs**: When chaining API calls together, use ‘"API_RESPONSE_0"‘, ‘"API_RESPONSE_1"‘, etc. as parameter values to pass the output from one API as input to another
-
[22]
Wait for the environment to execute it and provide feedback before proceeding with the next step
**Multi-step Execution**: For multi-step scenarios (scenarios 4 and 5), respond with only ONE API call at a time (a JSON object with a single key "0"). Wait for the environment to execute it and provide feedback before proceeding with the next step. 21
-
[23]
**Context Retention**: For multi-turn conversations (scenario 5), maintain awareness of previous exchanges and use that context when relevant to the current query
-
[24]
**NO-CALL Format**: When no API calls are needed, respond with an empty JSON object ‘{}‘ inside the ‘<tool_call return="one">‘ tag. The available tool definitions are added at the end of this prompt dynamically. In addition to the required tools we also add irrelevant and ambiguous tool definitions to elicit reasoning capabilities of the model. D Traces f...
work page 2024
-
[25]
Get current time using GetTime
-
[26]
Get current location using GetCurrentLocation
-
[27]
Use FindRestaurantsByLocation with the location from step 2 to get all restaurants there
-
[28]
Filter those restaurants to French cuisine using FilterByCuisine
-
[29]
Then, filter the French restaurants by opening hours using FilterByOpeningHours, using the current time from step 1. Wait, but the FilterByOpeningHours requires a specific time. So after getting the current time, I can pass that as the time parameter. So the steps are sequential. Each step depends on the previous one’s output. So this would be a chained A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.