RAT: Reference-Augmented Training for ASV Anti-Spoofing
Pith reviewed 2026-06-27 11:40 UTC · model grok-4.3
The pith
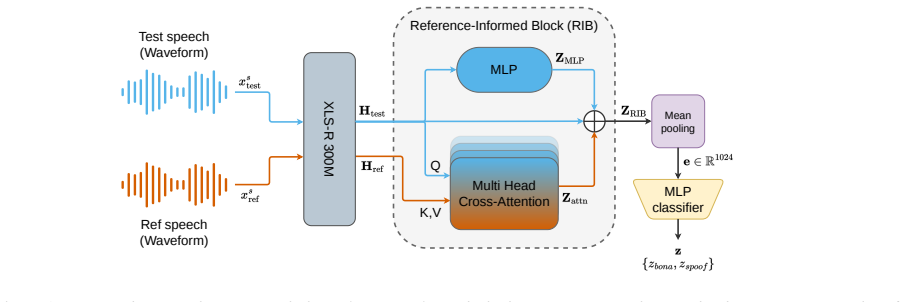
Training anti-spoofing detectors with speaker reference recordings improves performance even when the reference is absent or ignored at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Conditioning a spoofing countermeasure on speaker-reference recordings during training causes the optimization to rapidly diminish the reference contributions, yielding a detector whose inference is largely independent of the reference channel yet still benefits from the invariance induced by reference-augmented training.
What carries the argument
Reference-Augmented Training (RAT), the strategy of supplying speaker-reference recordings as an additional input channel only during training.
If this is right
- A single detector trained under RAT surpasses large ensemble systems on the ASVspoof 5 benchmark.
- Detection accuracy remains high when the reference input is replaced by a zero vector at inference.
- The optimization process quickly reduces dependence on the reference channel.
- The same invariance benefit appears even when the reference recording is mismatched or absent during testing.
Where Pith is reading between the lines
- Reference signals supplied only at training time may act as a form of regularization that encourages robustness to spoofing artifacts.
- The approach could be tested on other audio classification tasks where auxiliary conditioning during training improves generalization without added inference cost.
- If the invariance mechanism generalizes, similar reference-augmented schedules might reduce the need for matched reference data at deployment in related verification systems.
Load-bearing premise
The observed gains arise because reference-augmented training induces useful invariance rather than from unrelated differences in model size, data augmentation, or optimization settings.
What would settle it
An ablation that trains an otherwise identical model without any reference channel and obtains the same 2.57 percent EER and 0.074 minDCF on ASVspoof 5.
Figures
read the original abstract
We introduce a spoofing countermeasure architecture conditioned on speaker-reference recordings, but observe that it converges to a solution that effectively ignores the reference during inference. Surprisingly, training with a reference channel induces invariance that improves deepfake detection, even when the reference is absent or mismatched during inference. Based on this observation, we propose a Reference-Augmented Training (RAT) strategy. RAT yields improved detection performance compared to single-utterance baselines, even when the reference recording is replaced with a zero vector at inference. Through rigorous analysis, we demonstrate that the optimization process rapidly diminishes the reference contributions, leading to inference largely independent of the reference channel. Using RAT, we achieve state-of-the-art 2.57% EER and 0.074 minDCF on the ASVspoof 5 benchmark with a single detector, surpassing even large ensemble systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Reference-Augmented Training (RAT) for ASV anti-spoofing. A detector is conditioned on speaker-reference recordings during training, yet optimization rapidly diminishes the reference contribution so that inference is effectively reference-independent. The central claim is that this training procedure induces invariance to the reference channel, yielding improved deepfake detection even when the reference is replaced by a zero vector or mismatched at inference. RAT is reported to outperform single-utterance baselines and to reach state-of-the-art 2.57% EER and 0.074 minDCF on the ASVspoof 5 benchmark with a single detector, surpassing large ensembles.
Significance. If the performance gains are causally attributable to reference-augmented training rather than confounding differences in architecture or optimization, the method supplies a training-only modification that improves countermeasures without altering inference cost or architecture. The reported analysis of reference-contribution decay, if isolated from other factors, would constitute a useful empirical observation about how auxiliary conditioning can regularize spoofing detectors.
major comments (2)
- [Abstract] Abstract: the claim that RAT induces invariance responsible for the gains requires an ablation that holds model architecture, loss, data pipeline, and optimizer schedule fixed while toggling only the presence of the reference channel during training. The abstract states that optimization diminishes reference contributions but does not report such an isolation experiment, leaving the attribution to RAT unproven.
- [Results] Results (benchmark numbers): the reported 2.57% EER and 0.074 minDCF are presented without error bars, number of runs, or statistical tests against the single-utterance baseline, which is necessary to substantiate the claim of surpassing ensemble systems on ASVspoof 5.
minor comments (2)
- [Abstract] Abstract: the term 'rigorous analysis' of reference-contribution decay is used without indicating the quantitative method (e.g., gradient norms, ablation on reference masking, or contribution metrics) employed.
- [Methods] Notation: the precise mechanism by which the reference recording is fused into the detector (concatenation, cross-attention, etc.) should be stated with an equation in the methods section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and describe the revisions we will implement to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that RAT induces invariance responsible for the gains requires an ablation that holds model architecture, loss, data pipeline, and optimizer schedule fixed while toggling only the presence of the reference channel during training. The abstract states that optimization diminishes reference contributions but does not report such an isolation experiment, leaving the attribution to RAT unproven.
Authors: We agree that an explicit isolation experiment would provide stronger causal evidence for the role of reference-augmented training. While the manuscript already includes analysis showing rapid decay of reference contributions during optimization, this does not fully substitute for a controlled ablation that differs solely in the presence of the reference channel. We will add this ablation (training identical models with and without the reference input, all other factors fixed) and report the resulting performance differences in the revised manuscript. revision: yes
-
Referee: [Results] Results (benchmark numbers): the reported 2.57% EER and 0.074 minDCF are presented without error bars, number of runs, or statistical tests against the single-utterance baseline, which is necessary to substantiate the claim of surpassing ensemble systems on ASVspoof 5.
Authors: We acknowledge the importance of statistical rigor when claiming improvements over baselines and ensembles. The current results reflect single-run evaluations. In the revision we will repeat all experiments across multiple random seeds, report means and standard deviations, and include statistical significance tests comparing RAT to the single-utterance baseline. revision: yes
Circularity Check
No circularity; empirical benchmark result stands on its own
full rationale
The paper introduces RAT as a training strategy and reports concrete EER/minDCF numbers on the fixed ASVspoof 5 benchmark. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would make the reported performance reduce to the inputs by construction. The central claim is an observed empirical improvement, not a self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ASVspoof 5 benchmark and its official evaluation protocol (EER, minDCF) constitute a fair and representative test of anti-spoofing performance.
Reference graph
Works this paper leans on
-
[1]
Introduction Automatic Speaker Verification (ASV) systems face increas- ing threats from sophisticated spoofing attacks [1], including deepfakes created by text-to-speech synthesis and voice conver- sion [2, 3]. Traditional spoofing countermeasures (CMs) oper- ate on single test utterances [4] without leveraging additional speaker-specific information tha...
-
[2]
Background 2.1. ASV spoofing countermeasures Current anti-spoofing systems utilize pretrained Self-supervised learning (SSL) models such as Wav2Vec2 [10] or WavLM [11] due to their ability to extract rich speaker representations. These rich features are further processed and pooled, most commonly by Graph Attention Networks [12] from the AASIST frame- wor...
-
[3]
Architecture & Methodology Our architecture consists of three main components: an SSL feature extractor, a reference-informed block, and a downstream classifier, presented in Figure 1. SSL Feature Extractor: We use a pre-trained XLS-R [24] model based on the Wav2Vec2 architecture with 300M param- arXiv:2606.10908v1 [cs.SD] 9 Jun 2026 Reference-Informed Bl...
Pith/arXiv arXiv 2026
-
[4]
Results We first evaluate the detection performance of the proposed Reference-Augmented Training (RAT) strategy against single- utterance baselines. We compare our method (≈328Mparam- eters) with the best single system reported in the available lit- erature: WavLM + Hybrid Pruning (≈86M) [28], as well as best models from the ASVspoof 5 challenge: best sin...
-
[5]
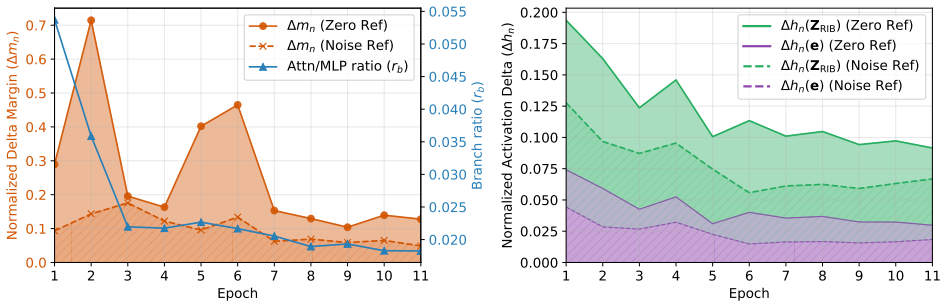
To measure the reference re- liance, we replace the referencex i ref with a perturbed reference ˜ri during evaluation after each epoch
Analysis of Training Dynamics To understandhowthe model converges to this reference- invariant solution, we analyzed the model’s and the RIB block’s internal dynamics during training. To measure the reference re- liance, we replace the referencex i ref with a perturbed reference ˜ri during evaluation after each epoch. We explored two op- tions of˜ri, that...
-
[6]
Conclusion We proposed Reference-Augmented Training (RAT), a train- ing paradigm for ASV anti-spoofing that conditions the model on reference speaker recordings. By employing a Reference- Informed Block (RIB) with cross-attention, we discovered that the network utilizes the reference during early training as a corrective signal to better isolate spoofing ...
-
[7]
Computational resources were provided by the e-INFRA CZ project (ID:90254), supported by the Ministry of Education, Youth and Sports of the Czech Re- public
Acknowledgments This work was supported by the Brno University of Technology internal project FIT-S-26-9011. Computational resources were provided by the e-INFRA CZ project (ID:90254), supported by the Ministry of Education, Youth and Sports of the Czech Re- public
-
[8]
The authors reviewed and edited the output as needed and take full respon- sibility for the publication’s content
Generative AI Use Disclosure During the preparation of this work, the authors used Generative AI Models (specifically Google Gemini, ChatGPT, and Gram- marly) for language editing and text refinement. The authors reviewed and edited the output as needed and take full respon- sibility for the publication’s content
-
[9]
Diffuse or Confuse: A Dif- fusion Deepfake Speech Dataset,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Diffuse or Confuse: A Dif- fusion Deepfake Speech Dataset,” in2024 International Confer- ence of the Biometrics Special Interest Group (BIOSIG). IEEE, Sep. 2024, p. 1–7
2024
-
[10]
The dawn of a text-dependent society: deepfakes as a threat to speech verification systems,
A. Firc and K. Malinka, “The dawn of a text-dependent society: deepfakes as a threat to speech verification systems,” inProceed- ings of the 37th ACM/SIGAPP Symposium on Applied Computing, ser. SAC ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 1646–1655
2022
-
[11]
Resilience of V oice Assistants to Synthetic Speech,
K. Malinkaet al., “Resilience of V oice Assistants to Synthetic Speech,” inComputer Security – ESORICS 2024. Cham: Springer Nature Switzerland, 2024, pp. 66–84
2024
-
[12]
Evaluation framework for deepfake speech detection: a comparative study of state-of-the-art deepfake speech detectors,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Evaluation framework for deepfake speech detection: a comparative study of state-of-the-art deepfake speech detectors,”Cybersecurity, vol. 8, no. 1, 2025
2025
-
[13]
Tandem Assessment of Spoofing Counter- measures and Automatic Speaker Verification: Fundamentals,
T. Kinnunen, H. Delgado, N. Evans, K. A. Lee, V . Vestman, A. Nautsch, M. Todisco, X. Wang, M. Sahidullah, J. Yamagishi, and D. A. Reynolds, “Tandem Assessment of Spoofing Counter- measures and Automatic Speaker Verification: Fundamentals,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 28, pp. 2195–2210, 2020
2020
-
[14]
Deepfake Speech De- tection: A Spectrogram Analysis,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Deepfake Speech De- tection: A Spectrogram Analysis,” inProceedings of the 39th ACM/SIGAPP Symposium on Applied Computing, ser. SAC ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 1312–1320
2024
-
[15]
SASV 2022: The First Spoofing-Aware Speaker Verification Challenge,
J.-w. Jung, H. Tak, H.-j. Shim, H.-S. Heo, B.-J. Lee, S.-W. Chung, H.-J. Yu, N. Evans, and T. Kinnunen, “SASV 2022: The First Spoofing-Aware Speaker Verification Challenge,” inProc. Inter- speech (submitted), 2022
2022
-
[16]
Differential Anomaly Detec- tion for Facial Images,
M. Ibsen, L. J. Gonzalez-Soler, C. Rathgeb, P. Drozdowski, M. Gomez-Barrero, and C. Busch, “Differential Anomaly Detec- tion for Facial Images,” in2021 IEEE International Workshop on Information Forensics and Security (WIFS). IEEE, 2021, pp. 1–6
2021
-
[17]
Speaker- Aware Anti-spoofing,
X. Liu, M. Sahidullah, K. A. Lee, and T. Kinnunen, “Speaker- Aware Anti-spoofing,” inInterspeech 2023, 2023, pp. 2498–2502
2023
-
[18]
SZU-AFS anti- spoofing system for the ASVspoof 5 Challenge,
Y . Xu, J. Zhong, S. Zheng, Z. Liu, and B. Li, “SZU-AFS anti- spoofing system for the ASVspoof 5 Challenge,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop, 2024, pp. 64–71
2024
-
[19]
Exploring WavLM back-ends for speech spoofing and deepfake detection,
T. Stourbe, V . Miara, T. Lepage, and R. Dehak, “Exploring WavLM back-ends for speech spoofing and deepfake detection,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop, 2024, pp. 72–78
2024
-
[20]
Graph Attention Networks for Anti-Spoofing,
H. Tak, J. weon Jung, J. Patino, M. Todisco, and N. Evans, “Graph Attention Networks for Anti-Spoofing,” inProc. Inter- speech 2021, 2021, pp. 2356–2360
2021
-
[21]
AASIST: Audio Anti-Spoofing Us- ing Integrated Spectro-Temporal Graph Attention Networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “AASIST: Audio Anti-Spoofing Us- ing Integrated Spectro-Temporal Graph Attention Networks,” in ICASSP 2022 - 2022 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2022, pp. 6367– 6371
2022
-
[22]
A single end-to-end voice anti-spoofing model with graph attention and feature aggregation for ASVspoof 5 Chal- lenge,
W. Xiaet al., “A single end-to-end voice anti-spoofing model with graph attention and feature aggregation for ASVspoof 5 Chal- lenge,” inThe Automatic Speaker Verification Spoofing Counter- measures Workshop, 2024
2024
-
[23]
SCDF: A Speaker Characteristics Deepfake Speech Dataset for Bias Analysis,
V . Stanˇek, K. Srna, A. Firc, and K. Malinka, “SCDF: A Speaker Characteristics Deepfake Speech Dataset for Bias Analysis,” in BIOSIG 2025. Gesellschaft f ¨ur Informatik e.V ., 2025
2025
-
[24]
BUT systems and analyses for the ASVspoof 5 Challenge,
J. Rohdin, L. Zhang, P. Old ˇrich, V . Stanˇek, D. Mihola, J. Peng, T. Stafylakis, D. Beveraki, A. Silnova, J. Brukner, and L. Bur- get, “BUT systems and analyses for the ASVspoof 5 Challenge,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 24–31
2024
-
[25]
Exploring generalization to unseen au- dio data for spoofing: insights from SSL models,
A. Kulkarni, H. M. Tran, A. Kulkarni, S. Dowerah, D. Lo- live, and M. M. Doss, “Exploring generalization to unseen au- dio data for spoofing: insights from SSL models,” inThe Auto- matic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 86–93
2024
-
[26]
ASVspoof 5 Challenge: advanced ResNet architectures for robust voice spoofing detec- tion,
A.-T. Dao, M. Rouvier, and D. Matrouf, “ASVspoof 5 Challenge: advanced ResNet architectures for robust voice spoofing detec- tion,” inThe Automatic Speaker Verification Spoofing Counter- measures Workshop, 2024, pp. 163–169
2024
-
[27]
Enhancing spoofing detection in ASVspoof 5 Workshop 2024: fusion of WavLM- ResNet18-SA for optimal performance against speech deepfakes,
P.-C. Chan, W.-Y . Chen, and J.-C. Wang, “Enhancing spoofing detection in ASVspoof 5 Workshop 2024: fusion of WavLM- ResNet18-SA for optimal performance against speech deepfakes,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop, 2024, pp. 158–162
2024
-
[28]
Evolutionary Multi-Objective Fusion of Deepfake Speech Detectors,
V . Stan ˇek, M. Pere ˇs´ıni, L. Sekanina, A. Firc, and K. Malinka, “Evolutionary Multi-Objective Fusion of Deepfake Speech Detectors,” 2026. [Online]. Available: https://arxiv.org/abs/2604. 01330
2026
-
[29]
Deepfakes as a threat to a speaker and facial recognition: An overview of tools and attack vectors,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Deepfakes as a threat to a speaker and facial recognition: An overview of tools and attack vectors,”Heliyon, vol. 9, no. 4, p. e15090, 2023
2023
-
[30]
ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J. weon Jung, H. jin Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. H. Kinnunen, N. Evans, K. A. Lee, and J. Yamagishi, “ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 1–8
2024
-
[31]
Revisiting and Improving Scoring Fusion for Spoofing-aware Speaker Verification Using Compositional Data Analysis,
X. Wang, T. Kinnunen, K. A. Lee, P.-G. No ´e, and J. Yamagishi, “Revisiting and Improving Scoring Fusion for Spoofing-aware Speaker Verification Using Compositional Data Analysis,” inIn- terspeech 2024, 2024, pp. 1110–1114
2024
-
[32]
XLS-R: Self-supervised Cross-lingual Speech Rep- resentation Learning at Scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Conneau, and M. Auli, “XLS-R: Self-supervised Cross-lingual Speech Rep- resentation Learning at Scale,” inInterspeech 2022, 2022, pp. 2278–2282
2022
-
[33]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vish- wanathan, and R. Garnett, Eds., vol. 30. Curran Associates, Inc., 2017
2017
-
[34]
Malafide: a novel adversarial convolutive noise attack against deepfake and spoofing detection systems,
M. Panariello, W. Ge, H. Tak, M. Todisco, and N. Evans, “Malafide: a novel adversarial convolutive noise attack against deepfake and spoofing detection systems,” inInterspeech 2023, 2023, pp. 2868–2872
2023
-
[35]
Malacopula: adversarial automatic speaker ver- ification attacks using a neural-based generalised Hammerstein model,
M. Todisco, M. Panariello, X. Wang, H. Delgado, K. A. Lee, and N. Evans, “Malacopula: adversarial automatic speaker ver- ification attacks using a neural-based generalised Hammerstein model,” inThe Automatic Speaker Verification Spoofing Counter- measures Workshop (ASVspoof 2024), 2024, pp. 94–100
2024
-
[36]
J. Peng, L. Zhang, J. Han, O. Plchot, J. Rohdin, T. Stafylakis, S. Wang, and J. ˇCernock´y, “Hybrid pruning: In-situ compression of self-supervised speech models for speaker verification and anti-spoofing,” 2025. [Online]. Available: https://arxiv.org/abs/ 2508.16232
arXiv 2025
-
[37]
Learn from real: reality defender’s submission to ASVspoof5 Challenge,
Y . Zhu, C. Goel, S. Koppisetti, T. Tran, A. Kumar, and G. Bharaj, “Learn from real: reality defender’s submission to ASVspoof5 Challenge,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 116– 123
2024
-
[38]
Raw- boost: A Raw Data Boosting and Augmentation Method Applied to Automatic Speaker Verification Anti-Spoofing,
H. Tak, M. Kamble, J. Patino, M. Todisco, and N. Evans, “Raw- boost: A Raw Data Boosting and Augmentation Method Applied to Automatic Speaker Verification Anti-Spoofing,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 6382–6386
2022
-
[39]
USTC-KXDIGIT system description for ASVspoof5 Challenge,
Y . Chen, H. Wu, N. Jiang, X. Xia, Q. Gu, Y . Hao, P. Cai, Y . Guan, J. Wang, W.-L. Xie, L. Fang, S. Fang, Y . Song, W. Guo, L. Liu, and M. Xu, “USTC-KXDIGIT system description for ASVspoof5 Challenge,” inThe Automatic Speaker Verification Spoofing Countermeasures Workshop (ASVspoof 2024), 2024, pp. 109–115
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.