VGGT-Edit: Feed-forward Native 3D Scene Editing with Residual Field Prediction
Pith reviewed 2026-05-20 20:42 UTC · model grok-4.3
The pith
VGGT-Edit performs text-conditioned 3D scene editing by predicting residual geometric displacements in a single feed-forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
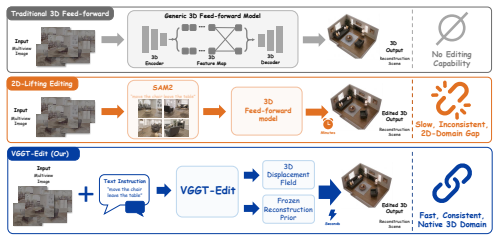
VGGT-Edit uses depth-synchronized text injection to align semantic guidance with the backbone's spatial poses, then applies a residual transformation head that directly predicts 3D geometric displacements to deform the scene while preserving background stability. Training with a multi-term objective for geometric accuracy and cross-view consistency produces results that outperform 2D-lifting baselines on sharpness, multi-view consistency, and inference speed.
What carries the argument
Residual transformation head that predicts 3D geometric displacements, guided by depth-synchronized text injection to maintain semantic grounding and background stability.
If this is right
- Edited scenes exhibit sharper object details than those produced by independent 2D edits followed by lifting.
- Multi-view consistency improves because changes are predicted directly in 3D rather than reconciled after the fact.
- Inference runs at near-instant speed suitable for interactive use.
- The same feed-forward backbone can both reconstruct and edit complex environments without separate reconstruction steps.
Where Pith is reading between the lines
- The residual prediction pattern may transfer to other feed-forward 3D tasks such as text-driven object insertion or removal.
- Integration with existing generalizable reconstruction models could add editing as a lightweight add-on module.
- The method's speed advantage supports real-time applications in AR or simulation environments where users issue repeated text instructions.
Load-bearing premise
The residual transformation head can accurately predict 3D geometric displacements that deform selected objects while leaving the background unchanged.
What would settle it
Quantitative comparison on held-out scenes showing that multi-view renders of the edited output contain geometric drift or texture blur exceeding the levels reported for the 2D-lifting baselines.
Figures






read the original abstract
High-quality 3D scene reconstruction has recently advanced toward generalizable feed-forward architectures, enabling the generation of complex environments in a single forward pass. However, despite their strong performance in static scene perception, these models remain limited in responding to dynamic human instructions, which restricts their use in interactive applications. Existing editing methods typically rely on a 2D-lifting strategy, where individual views are edited independently and then lifted back into 3D space. This indirect pipeline often leads to blurry textures and inconsistent geometry, as 2D editors lack the spatial awareness required to preserve structure across viewpoints. To address these limitations, we propose VGGT-Edit, a feed-forward framework for text-conditioned native 3D scene editing. VGGT-Edit introduces depth-synchronized text injection to align semantic guidance with the backbone's spatial poses, ensuring stable instruction grounding. This semantic signal is then processed by a residual transformation head, which directly predicts 3D geometric displacements to deform the scene while preserving background stability. To ensure high-fidelity results, we supervise the framework with a multi-term objective function that enforces geometric accuracy and cross-view consistency. We also construct the DeltaScene Dataset, a large-scale dataset generated through an automated pipeline with 3D agreement filtering to ensure ground-truth quality. Experiments show that VGGT-Edit substantially outperforms 2D-lifting baselines, producing sharper object details, stronger multi-view consistency, and near-instant inference speed. The project page is https://chriszkxxx.github.io/VGGT-Edit/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents VGGT-Edit, a feed-forward framework for text-conditioned native 3D scene editing built on the VGGT backbone. It introduces depth-synchronized text injection to align semantic guidance with spatial poses and a residual transformation head that predicts 3D geometric displacements to deform the scene while preserving background stability. The framework is supervised by a multi-term objective enforcing geometric accuracy and cross-view consistency, trained on the newly constructed DeltaScene Dataset generated via an automated pipeline with 3D agreement filtering. The central claim is that VGGT-Edit substantially outperforms 2D-lifting baselines, yielding sharper object details, stronger multi-view consistency, and near-instant inference speed.
Significance. If the empirical outperformance claims hold under detailed evaluation, this work would advance 3D scene editing by enabling direct native 3D manipulation rather than indirect 2D-lifting pipelines, reducing inconsistencies in geometry and texture. The feed-forward design and DeltaScene Dataset could support real-time interactive applications in computer vision and graphics.
major comments (2)
- [Experiments] Experiments section: the claim of substantial outperformance over 2D-lifting baselines is stated without accompanying quantitative metrics (e.g., PSNR, SSIM, or multi-view consistency scores), ablation studies on the residual head or objective terms, or error bars, which is load-bearing for verifying the central empirical result.
- [Method] Method description: the multi-term objective relies on free parameters for term balancing with no reported values, sensitivity analysis, or details on how geometric accuracy and cross-view consistency terms are weighted, undermining reproducibility of the claimed fidelity.
minor comments (1)
- [Abstract] The abstract would be strengthened by including one or two key quantitative results supporting the outperformance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript to strengthen the empirical validation and reproducibility.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the claim of substantial outperformance over 2D-lifting baselines is stated without accompanying quantitative metrics (e.g., PSNR, SSIM, or multi-view consistency scores), ablation studies on the residual head or objective terms, or error bars, which is load-bearing for verifying the central empirical result.
Authors: We agree that quantitative metrics are essential to substantiate the performance claims. Although the manuscript currently emphasizes qualitative comparisons to illustrate improvements in detail sharpness and consistency, the revised version will incorporate PSNR, SSIM, and multi-view consistency scores. We will also add ablation studies on the residual transformation head and objective terms, along with error bars from repeated runs. revision: yes
-
Referee: [Method] Method description: the multi-term objective relies on free parameters for term balancing with no reported values, sensitivity analysis, or details on how geometric accuracy and cross-view consistency terms are weighted, undermining reproducibility of the claimed fidelity.
Authors: We acknowledge that explicit reporting of the balancing weights is necessary for reproducibility. In the revised manuscript, we will specify the exact parameter values used for each term in the multi-term objective. We will additionally include a sensitivity analysis demonstrating the impact of these weights on geometric accuracy and cross-view consistency. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a feed-forward editing framework that extends an existing VGGT backbone with new modules (depth-synchronized text injection and residual transformation head) trained on a newly constructed DeltaScene dataset under a multi-term consistency objective. The central claims concern empirical outperformance on sharpness, multi-view consistency, and speed; these are presented as experimental results rather than derivations that reduce by construction to fitted inputs or self-referential definitions. No equations are shown that equate a prediction to its own supervision signal, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The architecture and evaluation pipeline remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights for multi-term objective
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a residual transformation head, which directly predicts 3D geometric displacements to deform the scene while preserving background stability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Pf3plat: Pose-free feed-forward 3d gaussian splatting.arXiv preprint arXiv:2410.22128,
Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jisang Han, Jiaolong Yang, Chong Luo, and Seungryong Kim. Pf3plat: Pose-free feed-forward 3d gaussian splatting.arXiv preprint arXiv:2410.22128,
-
[4]
Jiyuan Hu, Zechuan Zhang, Zongxin Yang, and Yi Yang. Trace: High-fidelity 3d scene editing via tangible reconstruction and geometry-aligned contextual video masking.arXiv preprint arXiv:2604.01207,
-
[5]
Edit3r: Instant 3d scene editing from sparse unposed images.arXiv preprint arXiv:2512.25071,
Jiageng Liu, Weijie Lyu, Xueting Li, Yejie Guo, and Ming-Hsuan Yang. Edit3r: Instant 3d scene editing from sparse unposed images.arXiv preprint arXiv:2512.25071,
-
[6]
Omni-3dedit: Generalized versatile 3d editing in one-pass.arXiv preprint arXiv:2603.17841,
Chen Liyi, Wang Pengfei, Zhang Guowen, Ma Zhiyuan, and Zhang Lei. Omni-3dedit: Generalized versatile 3d editing in one-pass.arXiv preprint arXiv:2603.17841,
-
[7]
VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold
13 Dominic Maggio, Hyungtae Lim, and Luca Carlone. Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.arXiv preprint arXiv:2505.12549,
work page internal anchor Pith review arXiv
-
[8]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. In International Conference on Learning Representations, volume 2025, pages 28085–28128,
work page 2025
-
[9]
Speed3r: Sparse feed-forward 3d reconstruction models.arXiv preprint arXiv:2603.08055,
Weining Ren, Xiao Tan, and Kai Han. Speed3r: Sparse feed-forward 3d reconstruction models.arXiv preprint arXiv:2603.08055,
-
[10]
The Replica Dataset: A Digital Replica of Indoor Spaces
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, et al. The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[11]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. InEuropean Conference on Computer Vision, pages 1–18. Springer, 2024a. Yiwen Tang, Ray Zhang, Zoey Guo, Xianzheng Ma, Bin Zhao, Zhigang Wang, Dong Wang, and Xuelong Li. Point-peft: Parameter-effic...
-
[12]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025a. Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made eas...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Ling Yang, Kaixin Zhu, Juanxi Tian, Bohan Zeng, Mingbao Lin, Hongjuan Pei, Wentao Zhang, and Shuicheng Yan. Widerange4d: Enabling high-quality 4d reconstruction with wi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Infinitevggt: Visual geometry grounded transformer for endless streams,
Shuai Yuan, Yantai Yang, Xiaotian Yang, Xupeng Zhang, Zhonghao Zhao, Lingming Zhang, and Zhipeng Zhang. Infinitevggt: Visual geometry grounded transformer for endless streams.arXiv preprint arXiv:2601.02281,
-
[15]
Trans4d: Realistic geometry-aware transition for compositional text-to-4d synthesis
Bohan Zeng, Ling Yang, Siyu Li, Jiaming Liu, Zixiang Zhang, Juanxi Tian, Kaixin Zhu, Yongzhen Guo, Fu-Yun Wang, Minkai Xu, et al. Trans4d: Realistic geometry-aware transition for compositional text-to-4d synthesis. arXiv preprint arXiv:2410.07155,
-
[16]
Bohan Zeng, Kaixin Zhu, Daili Hua, Bozhou Li, Chengzhuo Tong, Yuran Wang, Xinyi Huang, Yifan Dai, Zixiang Zhang, Yifan Yang, et al. Research on world models is not merely injecting world knowledge into specific tasks.arXiv preprint arXiv:2602.01630,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.