Neural Scaling Universality: If Exponents Are Fixed, Time to Understand Coefficients
Pith reviewed 2026-06-25 23:44 UTC · model grok-4.3
The pith
The exponents of neural scaling laws are fixed by generic mechanisms, so the key to improvement is understanding the coefficients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
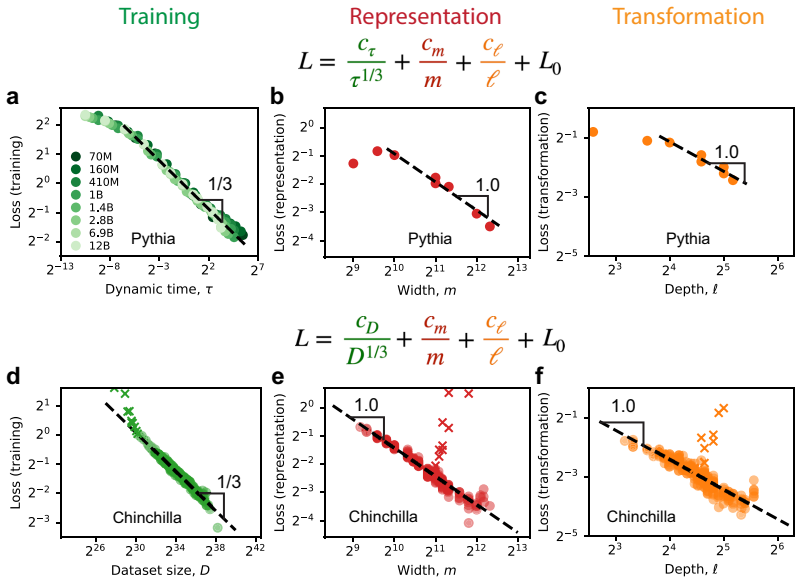
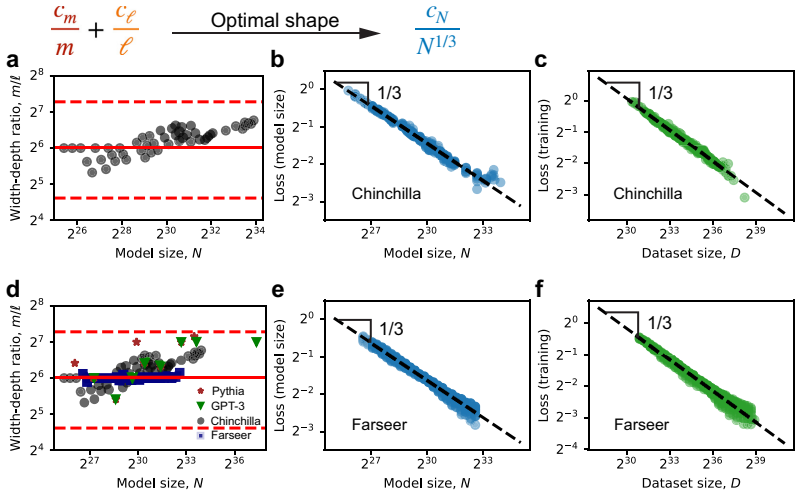
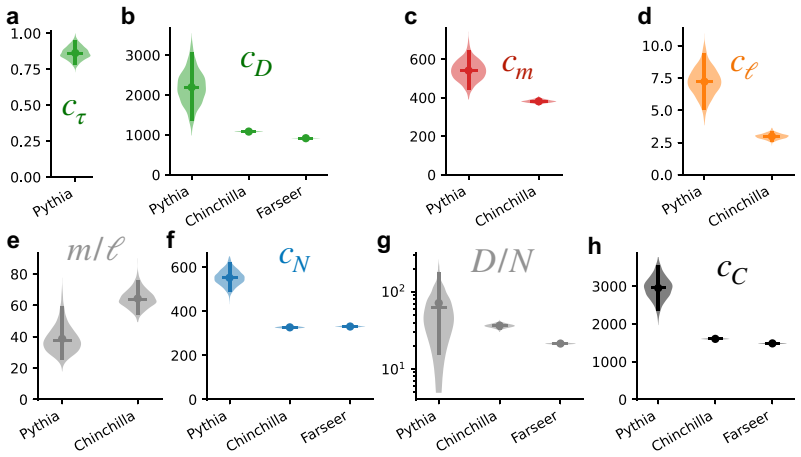
The exponents of these power laws are fixed by generic mechanisms: a one-third time scaling due to the strong nonlinearity of Softmax, an inverse width scaling due to representational superposition, and an inverse depth scaling due to ensemble averaging of Transformer layers. These mechanisms are robust to a wide range of data structures and architectural details, placing current large language models in a universality class with fixed exponents. The coefficients, however, are expected to be sensitive to data and architecture details, and directly determine practical quantities such as the optimal model shape and the compute-optimal frontier.
What carries the argument
The universality class of fixed scaling exponents generated by softmax nonlinearity, representational superposition, and transformer layer averaging.
If this is right
- The coefficients determine the optimal model shape.
- The coefficients determine the compute-optimal frontier.
- Near-term performance improvements require understanding coefficients.
- Current large language models share this universality class with fixed exponents.
Where Pith is reading between the lines
- Architectures that modify softmax or avoid superposition might achieve different exponents and better scaling.
- Systematic variation of data properties could map how coefficients change and suggest better training regimes.
- Testing the mechanisms in non-transformer models could reveal if the universality class extends beyond current designs.
Load-bearing premise
The generic mechanisms remain robust to a wide range of data structures and architectural details.
What would settle it
Observing different scaling exponents in a model that uses softmax, superposition, and transformer layers on standard data would contradict the fixed-exponents claim.
Figures



read the original abstract
Neural scaling laws describe how pre-training loss decays as power laws with training time, model size, and compute. This position paper argues that the exponents of these power laws are fixed by generic mechanisms: a one-third time scaling due to the strong nonlinearity of Softmax, an inverse width scaling due to representational superposition, and an inverse depth scaling due to ensemble averaging of Transformer layers. These mechanisms are robust to a wide range of data structures and architectural details, placing current large language models in a universality class with fixed exponents. The coefficients, however, are expected to be sensitive to data and architecture details, and directly determine practical quantities such as the optimal model shape and the compute-optimal frontier. We therefore argue that understanding the coefficients is the key to near-term performance improvements, and that a closer examination of the current universality class may reveal pathways to better universality classes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that the exponents of neural scaling laws are fixed by generic mechanisms: a one-third time scaling due to the strong nonlinearity of Softmax, an inverse width scaling due to representational superposition, and an inverse depth scaling due to ensemble averaging of Transformer layers. These mechanisms are robust to a wide range of data structures and architectural details, placing current large language models in a universality class with fixed exponents. The coefficients are sensitive to data and architecture details and determine practical quantities such as the optimal model shape and the compute-optimal frontier. The paper argues that understanding the coefficients is key to near-term performance improvements and that examining the current universality class may reveal pathways to better ones.
Significance. If the proposed mechanisms hold, the paper offers a conceptual framework that could usefully redirect attention from exponent fitting to coefficient analysis and optimization, with potential implications for model shape selection and compute frontiers. It also raises the prospect of identifying improved universality classes. As a position paper the significance rests on the heuristic arguments stimulating targeted empirical and theoretical follow-up rather than on new derivations or data.
major comments (2)
- [Abstract] Abstract: the claim that the three mechanisms are 'robust to a wide range of data structures and architectural details' is asserted without explicit first-principles derivations that vary the data distribution, activation function, or architectural components while recovering the same exponents; this invariance is load-bearing for the universality-class statement.
- [The section describing the time-scaling mechanism] The section describing the time-scaling mechanism: the one-third exponent is attributed to Softmax nonlinearity via a qualitative argument, but no derivation is supplied that demonstrates the exponent remains unchanged when the nonlinearity is altered or when the loss landscape statistics are varied.
minor comments (2)
- The manuscript would benefit from a short table or explicit list contrasting the three mechanisms with the scaling variables (time, width, depth) they are claimed to govern.
- Notation for the coefficients (prefactors) could be introduced more formally when they are first distinguished from the exponents.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on this position paper. The feedback highlights important points about the strength of the universality claims. We address each major comment below and will make revisions to clarify the heuristic nature of the arguments while preserving the paper's intent to stimulate further research.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the three mechanisms are 'robust to a wide range of data structures and architectural details' is asserted without explicit first-principles derivations that vary the data distribution, activation function, or architectural components while recovering the same exponents; this invariance is load-bearing for the universality-class statement.
Authors: We agree that the abstract asserts robustness without supplying explicit first-principles derivations that test invariance under changes to data distributions, activation functions, or architectural components. As a position paper, the claims rest on heuristic reasoning drawn from known properties of the mechanisms rather than formal proofs of universality. We will revise the abstract to state that the mechanisms are proposed as generic on the basis of qualitative arguments and prior literature, and we will add a dedicated paragraph in the discussion section that explicitly flags the absence of such derivations and calls for targeted theoretical and empirical follow-up to test the claimed invariance. revision: yes
-
Referee: [The section describing the time-scaling mechanism] The section describing the time-scaling mechanism: the one-third exponent is attributed to Softmax nonlinearity via a qualitative argument, but no derivation is supplied that demonstrates the exponent remains unchanged when the nonlinearity is altered or when the loss landscape statistics are varied.
Authors: The observation is accurate: the time-scaling section offers a qualitative argument connecting the one-third exponent to the strong nonlinearity of Softmax but does not include a derivation establishing that the exponent is invariant when the nonlinearity or loss-landscape statistics are changed. We will revise the section to label the argument explicitly as heuristic, to note the lack of a formal invariance proof, and to outline concrete directions (e.g., controlled ablations or mean-field analyses) that would be needed to verify stability of the exponent under such variations. revision: yes
Circularity Check
No circularity: position paper advances qualitative mechanisms without self-referential derivations or fitted inputs renamed as predictions.
full rationale
The manuscript is a position paper whose central argument consists of naming three mechanisms (Softmax nonlinearity for 1/3 time exponent, superposition for inverse-width, layer ensembling for inverse-depth) and asserting their robustness. No equations, parameter fits, or self-citations are supplied in the abstract or described structure that would reduce any claimed exponent to an input by construction. The universality-class statement is therefore an interpretive claim rather than a closed loop of the form 'exponent E is predicted from mechanism M which was itself fitted to E'. Because the text supplies no load-bearing self-citation chain, no ansatz smuggled via prior work, and no renaming of known results as new derivations, the derivation chain does not collapse. This is the expected outcome for a position paper that does not attempt quantitative first-principles derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The listed mechanisms (Softmax nonlinearity, superposition, ensemble averaging) fix the scaling exponents and are robust across data structures and architectures
Reference graph
Works this paper leans on
-
[1]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020. 10
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[6]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Asymptotic learning curves of kernel methods: empirical data versus teacher–student paradigm.Journal of Statistical Mechanics: Theory and Experiment, 2020(12):124001, 2020
Stefano Spigler, Mario Geiger, and Matthieu Wyart. Asymptotic learning curves of kernel methods: empirical data versus teacher–student paradigm.Journal of Statistical Mechanics: Theory and Experiment, 2020(12):124001, 2020
2020
-
[8]
Learning curve theory.arXiv preprint arXiv:2102.04074, 2021
Marcus Hutter. Learning curve theory.arXiv preprint arXiv:2102.04074, 2021
-
[9]
A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
Alexander Maloney, Daniel A Roberts, and James Sully. A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
-
[10]
Scaling laws from the data manifold dimension.Journal of Machine Learning Research, 23(9):1–34, 2022
Utkarsh Sharma and Jared Kaplan. Scaling laws from the data manifold dimension.Journal of Machine Learning Research, 23(9):1–34, 2022
2022
-
[11]
The quantization model of neural scaling.Advances in Neural Information Processing Systems, 36:28699–28722, 2023
Eric Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling.Advances in Neural Information Processing Systems, 36:28699–28722, 2023
2023
-
[12]
Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121, 2024
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121, 2024
2024
-
[13]
How feature learning can improve neural scaling laws.Journal of Statistical Mechanics: Theory and Experiment, 2025(8):084002, 2025
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. How feature learning can improve neural scaling laws.Journal of Statistical Mechanics: Theory and Experiment, 2025(8):084002, 2025
2025
-
[14]
Blake Bordelon, Mary I Letey, and Cengiz Pehlevan. Theory of scaling laws for in-context regression: Depth, width, context and time.arXiv preprint arXiv:2510.01098, 2025
-
[15]
Universal One-third Time Scaling in Learning Peaked Distributions
Yizhou Liu, Ziming Liu, Cengiz Pehlevan, and Jeff Gore. Universal one-third time scaling in learning peaked distributions.arXiv preprint arXiv:2602.03685, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Superposition Yields Robust Neural Scaling
Yizhou Liu, Ziming Liu, and Jeff Gore. Superposition yields robust neural scaling.arXiv preprint arXiv:2505.10465, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Inverse Depth Scaling From Most Layers Being Similar
Yizhou Liu, Sara Kangaslahti, Ziming Liu, and Jeff Gore. Inverse depth scaling from most layers being similar.arXiv preprint arXiv:2602.05970, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Neural scaling laws trilogy: Representation, transformation, and training
Yizhou Liu. Neural scaling laws trilogy: Representation, transformation, and training. https://liuyz0.github.io/blog/, 2026
2026
-
[19]
Maissam Barkeshli, Alberto Alfarano, and Andrey Gromov. On the origin of neural scaling laws: from random graphs to natural language.arXiv preprint arXiv:2601.10684, 2026
-
[20]
Linear algebraic structure of word senses, with applications to polysemy.Transactions of the Association for Computational Linguistics, 6:483–495, 2018
Sanjeev Arora, Yuanzhi Li, Yingyu Liang, Tengyu Ma, and Andrej Risteski. Linear algebraic structure of word senses, with applications to polysemy.Transactions of the Association for Computational Linguistics, 6:483–495, 2018. 11
2018
-
[21]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread, 2022
2022
-
[22]
The unreasonable ineffectiveness of the deeper layers.arXiv preprint arXiv:2403.17887, 2024
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Daniel A Roberts. The unreasonable ineffectiveness of the deeper layers.arXiv preprint arXiv:2403.17887, 2024
-
[23]
Sunny Sanyal, Ravid Shwartz-Ziv, Alexandros G Dimakis, and Sujay Sanghavi. When attention collapses: How degenerate layers in llms enable smaller, stronger models.arXiv preprint arXiv:2404.08634, 2024
-
[24]
The curse of depth in large language models.arXiv preprint arXiv:2502.05795, 2025
Wenfang Sun, Xinyuan Song, Pengxiang Li, Lu Yin, Yefeng Zheng, and Shiwei Liu. The curse of depth in large language models.arXiv preprint arXiv:2502.05795, 2025
-
[25]
Shortgpt: Layers in large language models are more redundant than you expect
Xin Men, Mingyu Xu, Qingyu Zhang, Qianhao Yuan, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. Shortgpt: Layers in large language models are more redundant than you expect. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20192–20204, 2025
2025
-
[26]
Do language models use their depth efficiently?arXiv preprint arXiv:2505.13898, 2025
Róbert Csordás, Christopher D Manning, and Christopher Potts. Do language models use their depth efficiently?arXiv preprint arXiv:2505.13898, 2025
-
[27]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023
2023
-
[28]
nanochat: The best chatgpt that $100 can buy, 2025
Andrej Karpathy. nanochat: The best chatgpt that $100 can buy, 2025
2025
-
[29]
Power lines: Scaling laws for weight decay and batch size in LLM pre-training
Shane Bergsma, Nolan Dey, Gurpreet Gosal, Gavia Gray, Daria Soboleva, and Joel Hestness. Power lines: Scaling laws for weight decay and batch size in llm pre-training.arXiv preprint arXiv:2505.13738, 2025
-
[30]
Chinchilla scaling: A replication attempt.arXiv preprint arXiv:2404.10102, 2024
Tamay Besiroglu, Ege Erdil, Matthew Barnett, and Josh You. Chinchilla scaling: A replication attempt.arXiv preprint arXiv:2404.10102, 2024
-
[31]
Houyi Li, Wenzhen Zheng, Qiufeng Wang, Zhenyu Ding, Haoying Wang, Zili Wang, Shijie Xuyang, Ning Ding, Shuigeng Zhou, Xiangyu Zhang, et al. Predictable scale: Part ii, farseer: A refined scaling law in large language models.arXiv preprint arXiv:2506.10972, 2025
-
[32]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv preprint arXiv:1312.6120, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[33]
Learning curves for sgd on structured features.arXiv preprint arXiv:2106.02713, 2021
Blake Bordelon and Cengiz Pehlevan. Learning curves for sgd on structured features.arXiv preprint arXiv:2106.02713, 2021
-
[34]
Scaling laws in linear regression: Compute, parameters, and data.Advances in Neural Information Processing Systems, 37:60556–60606, 2024
Licong Lin, Jingfeng Wu, Sham M Kakade, Peter L Bartlett, and Jason D Lee. Scaling laws in linear regression: Compute, parameters, and data.Advances in Neural Information Processing Systems, 37:60556–60606, 2024
2024
-
[35]
A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092, 2024
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A dynamical model of neural scaling laws.arXiv preprint arXiv:2402.01092, 2024
-
[36]
Roman Worschech and Bernd Rosenow. Analyzing neural scaling laws in two-layer networks with power-law data spectra.arXiv preprint arXiv:2410.09005, 2024
-
[37]
An exactly solvable model for emergence and scaling laws in the multitask sparse parity problem.Advances in Neural Information Processing Systems, 37:39632–39693, 2024
Nayara Fonseca, Seok Hyeong Lee, Chris Mingard, Ard Louis, et al. An exactly solvable model for emergence and scaling laws in the multitask sparse parity problem.Advances in Neural Information Processing Systems, 37:39632–39693, 2024
2024
-
[38]
4+ 3 phases of compute-optimal neural scaling laws.Advances in Neural Information Processing Systems, 37:16459–16537, 2024
Elliot Paquette, Courtney Paquette, Lechao Xiao, and Jeffrey Pennington. 4+ 3 phases of compute-optimal neural scaling laws.Advances in Neural Information Processing Systems, 37:16459–16537, 2024. 12
2024
-
[39]
Scaling Laws and Spectra of Shallow Neural Networks in the Feature Learning Regime
Leonardo Defilippis, Yizhou Xu, Julius Girardin, Emanuele Troiani, Vittorio Erba, Lenka Zdeborová, Bruno Loureiro, and Florent Krzakala. Scaling laws and spectra of shallow neural networks in the feature learning regime.arXiv preprint arXiv:2509.24882, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
A theory for emergence of complex skills in language models.arXiv preprint arXiv:2307.15936, 2023
Sanjeev Arora and Anirudh Goyal. A theory for emergence of complex skills in language models.arXiv preprint arXiv:2307.15936, 2023
-
[41]
Ziming Liu, Yizhou Liu, Eric J Michaud, Jeff Gore, and Max Tegmark. Physics of skill learning. arXiv preprint arXiv:2501.12391, 2025
-
[42]
Francesco Cagnetta, Allan Raventós, Surya Ganguli, and Matthieu Wyart. Deriving neural scaling laws from the statistics of natural language.arXiv preprint arXiv:2602.07488, 2026
-
[43]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[45]
Unified scaling laws for routed language models
Aidan Clark, Diego de Las Casas, Aurelia Guy, Arthur Mensch, Michela Paganini, Jordan Hoffmann, Bogdan Damoc, Blake Hechtman, Trevor Cai, Sebastian Borgeaud, et al. Unified scaling laws for routed language models. InInternational conference on machine learning, pages 4057–4086. PMLR, 2022
2022
-
[46]
Looped transformers for length generalization.arXiv preprint arXiv:2409.15647, 2024
Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped transformers for length generalization.arXiv preprint arXiv:2409.15647, 2024
-
[47]
Parcae: Scaling Laws For Stable Looped Language Models
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y Fu. Parcae: Scaling laws for stable looped language models.arXiv preprint arXiv:2604.12946, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, et al. Attention residuals.arXiv preprint arXiv:2603.15031, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Superposition unifies power-law training dynamics.arXiv preprint arXiv:2602.01045, 2026
Zixin Jessie Chen, Hao Chen, Yizhou Liu, and Jeff Gore. Superposition unifies power-law training dynamics.arXiv preprint arXiv:2602.01045, 2026
-
[50]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[51]
The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37:30811–30849, 2024
Guilherme Penedo, Hynek Kydlí ˇcek, Anton Lozhkov, Margaret Mitchell, Colin A Raffel, Leandro V on Werra, Thomas Wolf, et al. The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37:30811–30849, 2024. A Pythia models We fit the scaling law L= cτ τ 1/3 + cm m + cℓ ℓ +L 0 (14) to loss d...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.