Recommendation as Generation: Unifying Personalized Video Generation and Recommendation at Industrial Scale
Pith reviewed 2026-06-25 20:18 UTC · model grok-4.3
The pith
A unified framework generates personalized videos on demand by turning recommendation into video creation through shared semantic IDs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
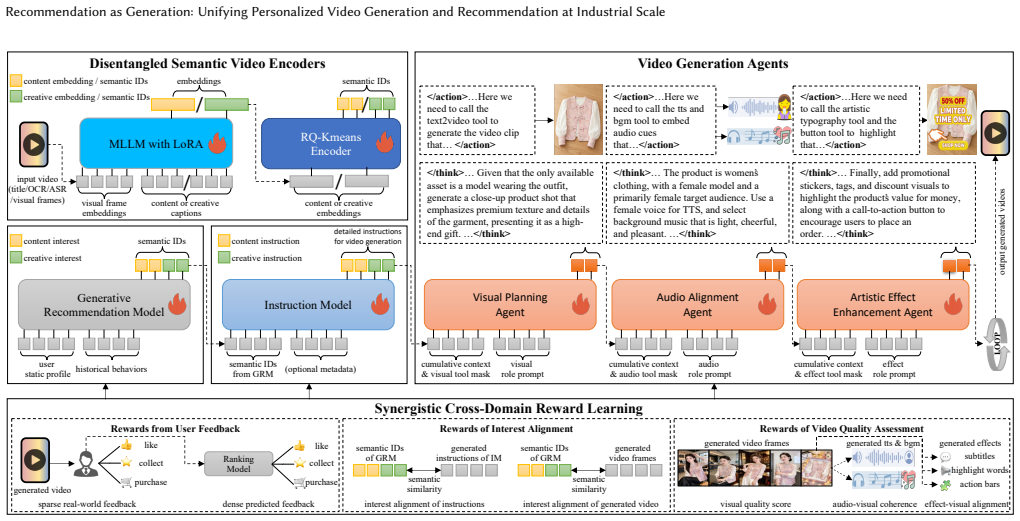
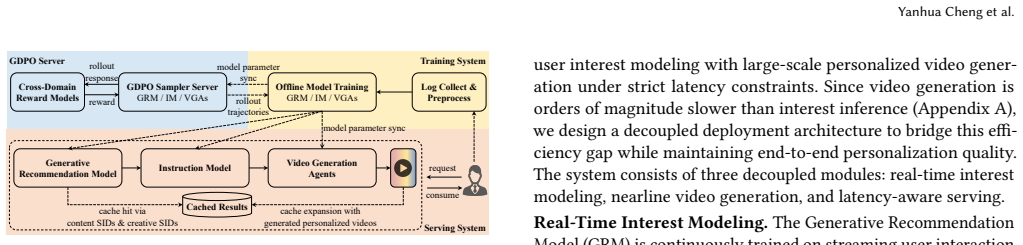
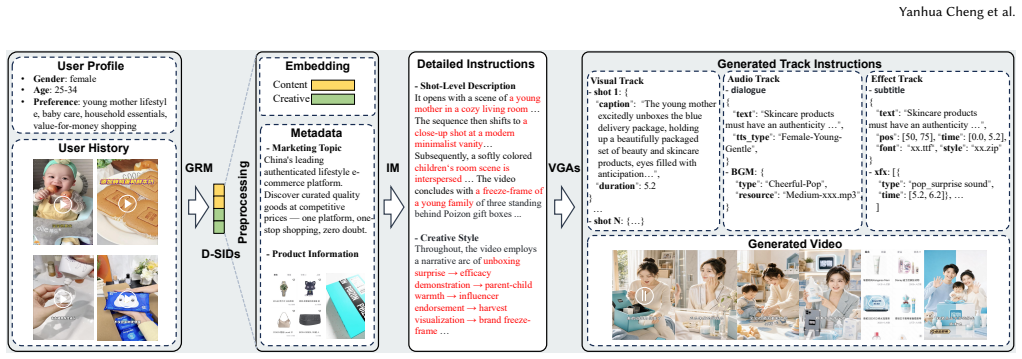
Recommendation-as-Generation unifies personalized recommendation and video generation by representing every video with shared semantic IDs that disentangle content semantics from creative style semantics; these IDs condition both user-interest modeling and a hierarchy of Video Generation Agents that plan and refine on-demand video output, optimized jointly through cross-domain reward signals for interest alignment, feedback, and quality.
What carries the argument
Shared semantic IDs (SIDs) that disentangle video representation into content semantics and creative style semantics, together with Video Generation Agents conditioned on inferred SIDs for hierarchical planning and refinement.
If this is right
- User interest can be modeled at finer granularity because the same representation supports both matching and creation.
- Videos can be generated that align with dynamic preferences without waiting for new pre-produced content.
- A single training loop jointly optimizes interest alignment, user feedback, and video quality through cross-domain rewards.
- The approach scales to hundreds of millions of daily active users in a revenue-critical advertising setting.
Where Pith is reading between the lines
- If the disentanglement holds, the same SIDs could support other media types such as images or audio clips without separate representation pipelines.
- The closed-loop nature suggests that generated videos could be fed back as new training data to further refine future interest predictions.
- Controllability over style separate from content may allow platforms to test creative variations while holding the recommended message fixed.
Load-bearing premise
Semantic IDs can be learned so that they cleanly separate content from style while supporting both accurate user-interest prediction and high-quality controllable video generation at industrial scale.
What would settle it
An online A/B test in which videos generated from the inferred SIDs produce no statistically significant lift in ad revenue or user engagement metrics relative to a strong generative-recommendation baseline that only ranks existing videos.
Figures

read the original abstract
Traditional short-video recommendation systems match user interest to a fixed pool of pre-produced videos, which limits their ability to capture fine-grained and dynamic preferences. We propose Recommendation-as-Generation (RaG), a new paradigm that generates personalized videos on demand from inferred user interest. Our framework unifies generative recommendation and video generation through shared semantic IDs (SIDs), which disentangle video representation into content semantics and creative style semantics, enabling both fine-grained modeling of user interest and controllable generation of interest-aligned videos. We further develop Video Generation Agents (VGAs) that are conditioned on inferred SIDs to drive hierarchical planning and refinement for video creation, including visual composition, audio alignment, and artistic effect enhancement. To optimize the framework, we effectively introduce a synergistic cross-domain reward learning mechanism that jointly enforces interest alignment, user feedback, and video quality assessment. We deploy RaG on an industrial-scale platform with over 400 million daily active users and evaluate it in a revenue-critical advertising scenario. Online A/B tests show up to 1.87% ad revenue improvement compared to a strong production GRM baseline, demonstrating its effectiveness in driving further revenue gains beyond generative recommendation. Our results highlight a closed-loop generative system as a promising paradigm for integrating personalized video generation into recommendation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Recommendation-as-Generation (RaG), a paradigm that generates personalized videos on demand from inferred user interest by unifying generative recommendation and video generation. It relies on shared semantic IDs (SIDs) to disentangle video representations into content semantics and creative style semantics, Video Generation Agents (VGAs) for hierarchical planning and refinement (visual composition, audio alignment, artistic effects), and a synergistic cross-domain reward learning mechanism that jointly optimizes interest alignment, user feedback, and video quality. The system is deployed at industrial scale (>400M DAU) in a revenue-critical advertising scenario, with online A/B tests reporting up to 1.87% ad revenue lift over a strong production generative recommendation model baseline.
Significance. If the technical claims hold, the work could advance the integration of controllable generative models into large-scale recommendation systems by enabling on-demand personalized content rather than retrieval from a fixed pool. The reported revenue improvement in a live advertising setting indicates potential practical impact. However, the absence of any equations, architecture diagrams, training objectives, ablation studies, or statistical details in the provided text prevents assessment of whether the SIDs achieve clean disentanglement or whether the gains are robust and independent of reward-parameter fitting.
major comments (2)
- [Abstract] Abstract: The central technical claim—that shared SIDs cleanly disentangle content semantics from creative style semantics to simultaneously support accurate user-interest modeling and controllable high-quality generation—is load-bearing for the entire paradigm and the reported 1.87% revenue gain. No equations, loss functions, training procedure, or ablation results are supplied to demonstrate that this separation is achieved or that it is not an artifact of the reward balancing weights.
- [Abstract] Abstract: The cross-domain reward learning mechanism is described as jointly enforcing interest alignment, user feedback, and video quality, yet no formulation, weighting scheme, or evidence is given that the reported gains remain after controlling for the free parameters in the reward function. This leaves open whether the improvement is independent of the fitted reward parameters.
minor comments (2)
- [Abstract] Abstract: The description of VGAs as driving 'hierarchical planning and refinement' is high-level; a concrete outline of the planning stages or conditioning mechanism on SIDs would aid readability.
- [Abstract] Abstract: The baseline is referred to only as 'a strong production GRM baseline'; specifying its architecture or key differences from RaG would help contextualize the 1.87% lift.
Simulated Author's Rebuttal
We thank the referee for their comments on our manuscript. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central technical claim—that shared SIDs cleanly disentangle content semantics from creative style semantics to simultaneously support accurate user-interest modeling and controllable high-quality generation—is load-bearing for the entire paradigm and the reported 1.87% revenue gain. No equations, loss functions, training procedure, or ablation results are supplied to demonstrate that this separation is achieved or that it is not an artifact of the reward balancing weights.
Authors: The manuscript presents RaG as an industrial system paper, focusing on the overall paradigm, the deployment at scale, and the online A/B test results. Due to the proprietary nature of the production system, we do not disclose the specific equations, loss functions, or training procedures used for learning the shared SIDs or for achieving the disentanglement between content and style semantics. The reported 1.87% revenue lift is measured in a live advertising scenario against a strong baseline, providing empirical support for the approach in a real-world setting. We do not intend to revise the manuscript to include these details. revision: no
-
Referee: [Abstract] Abstract: The cross-domain reward learning mechanism is described as jointly enforcing interest alignment, user feedback, and video quality, yet no formulation, weighting scheme, or evidence is given that the reported gains remain after controlling for the free parameters in the reward function. This leaves open whether the improvement is independent of the fitted reward parameters.
Authors: Likewise, the exact formulation and weighting scheme for the synergistic cross-domain reward learning are not provided in the manuscript for confidentiality reasons. The mechanism is described conceptually as jointly optimizing the three objectives. The online experiments reflect the performance with the tuned parameters in the deployed system. We cannot supply additional evidence on robustness to parameter choices without disclosing proprietary information. revision: no
- Requests for specific equations, loss functions, training procedures, ablation studies, formulations, and weighting schemes for the SIDs and cross-domain reward mechanism, which cannot be provided due to industrial proprietary constraints.
Circularity Check
No significant circularity detected
full rationale
The abstract and context describe the RaG paradigm, shared SIDs for semantic disentanglement, VGAs, and a cross-domain reward mechanism, but present no equations, derivation steps, or self-citations that reduce any prediction or result to its own inputs by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citation chains are visible. External online A/B tests on 400M+ users provide independent validation, confirming the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward balancing weights
axioms (1)
- domain assumption Semantic IDs can be learned to disentangle content semantics from creative style semantics
invented entities (2)
-
Semantic IDs (SIDs)
no independent evidence
-
Video Generation Agents (VGAs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introducing Claude 4.5 Sonnet
Anthropic. Introducing Claude 4.5 Sonnet. https://www.anthropic.com/news/ claude-4-5-sonnet, September 2025. Anthropic announcement
2025
-
[2]
Junyi Chen, Lu Chi, Siliang Xu, Shiwei Ran, Bingyue Peng, and Zehuan Yuan. Hllm-creator: Hierarchical llm-based personalized creative generation.arXiv preprint arXiv:2508.18118, 2025
-
[3]
Wide & deep learning for recommender systems
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016
2016
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodal- ity, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Deep neural networks for youtube recommendations
Paul Covington, Jay Adams, and Emre Sargin. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems, pages 191–198, 2016
2016
-
[6]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[7]
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Veo 3: Our most capable video generation model
Google DeepMind. Veo 3: Our most capable video generation model. https: //deepmind.google/models/veo/, May 2025. Google DeepMind product announce- ment
2025
-
[9]
Learn: knowledge adaptation from large language model to recommendation for practical industrial application
Jian Jia, Yipei Wang, Yan Li, Honggang Chen, Xuehan Bai, Zhaocheng Liu, Jian Liang, Quan Chen, Han Li, Peng Jiang, et al. Learn: knowledge adaptation from large language model to recommendation for practical industrial application. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11861–11869, 2025
2025
-
[10]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
QARM: quantitative alignment multi-modal recommen- dation at kuaishou
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, Changqing Qiu, Jiaqi Zhang, Xu Zhang, Zhiheng Yan, Jingming Zhang, Simin Zhang, Mingxing Wen, Zhaojie Liu, and Guorui Zhou. QARM: quantitative alignment multi-modal recommen- dation at kuaishou. InCIKM, pages 5915–5922. ACM, 2025
2025
-
[12]
VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, et al. Vlm2vec-v2: Advancing multi- modal embedding for videos, images, and visual documents.arXiv preprint arXiv:2507.04590, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Deep Learning Recommendation Model for Personalization and Recommendation Systems
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole- Jean Wu, Alisson G Azzolini, et al. Deep learning recommendation model for personalization and recommendation systems.arXiv preprint arXiv:1906.00091, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[14]
GPT-5.1 Instant and GPT-5.1 Thinking system card adden- dum
OpenAI. GPT-5.1 Instant and GPT-5.1 Thinking system card adden- dum. https://cdn.openai.com/pdf/4173ec8d-1229-47db-96de-06d87147e07e/5_1_ system_card.pdf, November 2025. OpenAI technical report addendum
2025
-
[15]
Sora 2 system card
OpenAI. Sora 2 system card. https://cdn.openai.com/pdf/50d5973c-c4ff-4c2d- 986f-c72b5d0ff069/sora_2_system_card.pdf, 2025
2025
-
[16]
Recommender systems with generative retrieval.Advances in Neural Information Processing Systems, 36:10299–10315, 2023
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al. Recommender systems with generative retrieval.Advances in Neural Information Processing Systems, 36:10299–10315, 2023
2023
-
[17]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Team Seedance, Heyi Chen, Siyan Chen, Xin Chen, Yanfei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Tianheng Cheng, Xinqi Cheng, et al. Seedance 1.5 pro: A native audio-visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Pmg: Personalized multimodal generation with large language models
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, and Xi Xiao. Pmg: Personalized multimodal generation with large language models. InProceedings of the ACM Web Conference 2024, pages 3833–3843, 2024
2024
-
[19]
Responsive safety in reinforce- ment learning by PID lagrangian methods
Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforce- ment learning by PID lagrangian methods. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 9133–9143. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.pre...
2020
-
[20]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report. arXiv preprint arXiv:2512.16776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Qwen Team. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Wenjie Wang, Xinyu Lin, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Genera- tive recommendation: Towards next-generation recommender paradigm.arXiv preprint arXiv:2304.03516, 2023
-
[24]
Learnable item tokenization for generative recommendation
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 2400–2409, 2024
2024
-
[25]
Personalized visual content generation in conver- sational systems
Xianquan Wang, Zhaocheng Du, Huibo Xu, Shukang Yin, Yupeng Han, Jieming Zhu, Kai Zhang, and Qi Liu. Personalized visual content generation in conver- sational systems. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS 2025), 2025
2025
-
[26]
Yiyan Xu, Ruoxuan Xia, Wuqiang Zheng, Fengbin Zhu, Wenjie Wang, and Fuli Feng. Nextads: Towards next-generation personalized video advertising.arXiv preprint arXiv:2603.02137, 2026
-
[27]
Generative recom- mendation for large-scale advertising.arXiv preprint arXiv:2602.22732, 2026
Ben Xue, Dan Liu, Lixiang Wang, Mingjie Sun, Peng Wang, Pengfei Zhang, Shaoyun Shi, Tianyu Xu, Yunhao Sha, Zhiqiang Liu, et al. Generative recom- mendation for large-scale advertising.arXiv preprint arXiv:2602.22732, 2026
-
[28]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024. Yanhua Cheng et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
A new creative generation pipeline for click-through rate with stable diffusion model
Hao Yang, Jianxin Yuan, Shuai Yang, Linhe Xu, Shuo Yuan, and Yifan Zeng. A new creative generation pipeline for click-through rate with stable diffusion model. InCompanion Proceedings of the ACM Web Conference 2024, pages 180–189, 2024
2024
-
[31]
Unleash llms potential for sequential recommendation by coordinating dual dynamic index mechanism
Jun Yin, Zhengxin Zeng, Mingzheng Li, Hao Yan, Chaozhuo Li, Weihao Han, Jianjin Zhang, Ruochen Liu, Hao Sun, Weiwei Deng, et al. Unleash llms potential for sequential recommendation by coordinating dual dynamic index mechanism. InProceedings of the ACM on Web Conference 2025, pages 216–227, 2025
2025
-
[32]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Adapting large language models by integrating collaborative semantics for recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 1435–1448. IEEE, 2024
2024
-
[34]
Deep interest network for click-through rate prediction
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1059–1068, 2018
2018
-
[35]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, Pengfei Zheng, Qiang Luo, Qianqian Wang, Qigen Hu, Rui Huang, Ruiming Tang, Shiyao Wang, Shujie Yang, Tao Wu, Wuchao Li, Xinchen Luo, Xingmei Wang, Yi Su, Yunfan Wu, Zexuan Cheng, Zhanyu Liu, Zixing Zhang, Bin Zhang, Boxuan Wang, Chaoyi ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
content_fidelity
Han Zhu, Xiang Li, Pengye Zhang, Guozheng Li, Jie He, Han Li, and Kun Gai. Learning tree-based deep model for recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1079–1088, 2018. Recommendation as Generation: Unifying Personalized Video Generation and Recommendation at Industrial S...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.