Unlocking LLM Code Correction with Iterative Feedback Loops
Pith reviewed 2026-06-27 00:10 UTC · model grok-4.3
The pith
Reasoning LLMs improve code accuracy over iterations when given compiler errors and test feedback, outperforming non-reasoning models on syntactic and runtime issues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
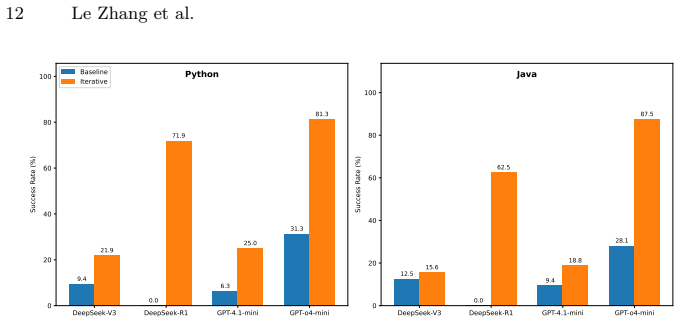
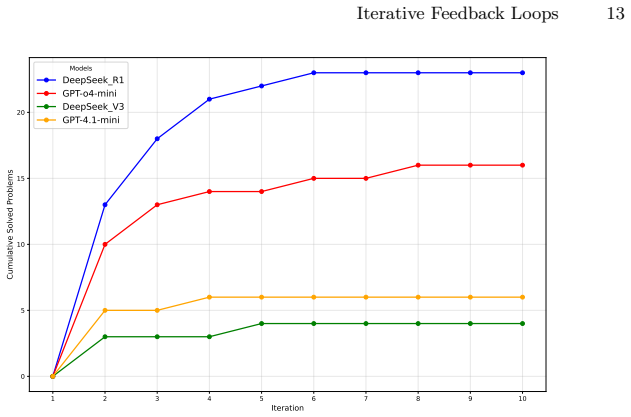
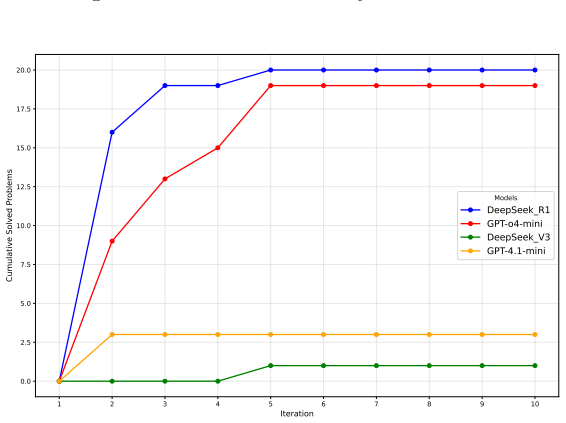
Using real-world problems across four models and two languages, the evaluation shows that reasoning models consistently improve over iterations by leveraging compiler error messages and testcase feedback after each attempt, substantially outperforming non-reasoning models, while syntactic and runtime errors are far more tractable than logical or algorithmic failures.
What carries the argument
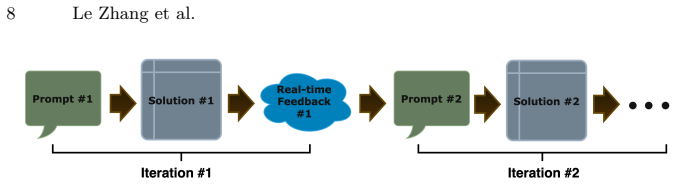
Iterative refinement framework in which each model attempt receives compiler error messages and testcase feedback before generating the next code version.
If this is right
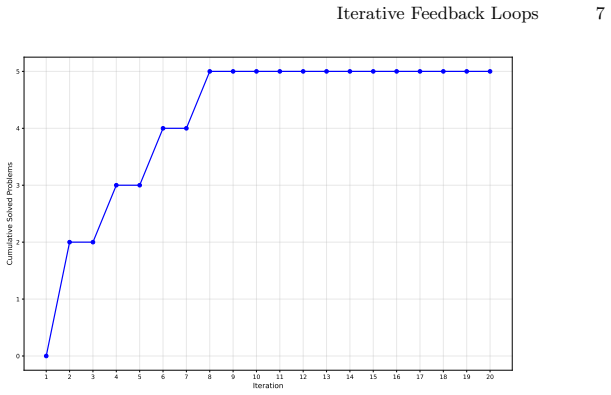
- Reasoning models reach higher final success rates through repeated feedback rounds than single-attempt generation allows.
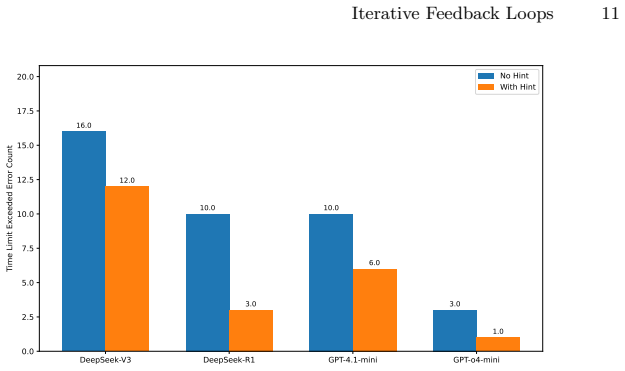
- Syntactic and runtime errors can be corrected more reliably than logical or algorithmic ones when feedback is supplied.
- Non-reasoning models derive limited benefit from the same iterative signals.
- Metrics that classify failure types and track rectification patterns can inform which models suit code correction tasks.
Where Pith is reading between the lines
- The same feedback mechanism might allow LLMs to handle larger codebases if extended beyond isolated problems.
- Training objectives that reward use of execution signals could narrow the gap between reasoning and non-reasoning models.
- Embedding this loop inside development environments could change how programmers interact with generated code.
Load-bearing premise
Compiler error messages and testcase feedback after each attempt provide sufficient and representative signals for real-world code correction, and the chosen problems, models, and languages generalize beyond the tested set.
What would settle it
A new test on additional problems or models in which reasoning models show no consistent accuracy gains across iterations would falsify the central result.
Figures






read the original abstract
Large Language Models have shown remarkable capabilities in code generation. However, most existing evaluations focus only on single-attempt accuracy and overlook the iterative refinement process that is central to real-world programming. This study presents a systematic investigation of LLMs' ability to rectify their own code through execution feedback. Using real-world programming problems across four models and two major programming languages, this study evaluates performance using iterative refinement framework where LLMs receive compiler error messages and testcase feedback after each attempt. This study introduces metrics to evaluate code failures, analyze rectification patterns, and compare the effectiveness of reasoning and non-reasoning models, offering actionable insights into both the understanding and practical application of feedback loops in LLM-driven code generation systems. Results show that reasoning models consistently improve over iterations, substantially outperforming non-reasoning models in leveraging feedback, while syntactic and runtime errors are far more tractable than logical or algorithmic failures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a systematic investigation of LLMs' ability to rectify their own code through execution feedback using an iterative refinement framework. It evaluates four models on real-world programming problems in two languages, introduces metrics for code failures and rectification patterns, and compares reasoning and non-reasoning models. The results show that reasoning models consistently improve over iterations and outperform non-reasoning models in leveraging feedback, while syntactic and runtime errors are more tractable than logical or algorithmic failures.
Significance. If the results hold, the paper contributes to the understanding of iterative code correction in LLMs, which is more representative of real-world programming than single-attempt evaluations. The distinction between reasoning and non-reasoning models and between error types offers actionable insights for improving LLM code generation systems. The introduction of specific metrics for analyzing rectification patterns is a strength.
major comments (2)
- [Abstract] Abstract: The abstract states clear results but supplies no information on experimental design, dataset size, statistical tests, error bars, or controls for confounding factors, so the claims cannot be verified from the given text. This is load-bearing for the central empirical claims about model improvement and error tractability.
- [Methodology/Results] The central claim that reasoning models substantially outperform non-reasoning models in leveraging feedback and that syntactic/runtime errors are far more tractable rests on the unexamined premise that the chosen problems, models, and languages capture general behavior; no justification or diversity analysis for problem/model selection is provided, which directly affects generalizability.
minor comments (1)
- [Introduction] The paper could include more references to prior work on iterative refinement and feedback in code generation to better contextualize the contribution.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states clear results but supplies no information on experimental design, dataset size, statistical tests, error bars, or controls for confounding factors, so the claims cannot be verified from the given text. This is load-bearing for the central empirical claims about model improvement and error tractability.
Authors: We agree the abstract is too concise for verification of claims. We will revise it to include key experimental details: evaluation on real-world problems across two languages using an iterative refinement framework with execution feedback, four models (reasoning and non-reasoning), and observed trends in success rates by error type. The study is descriptive rather than inferential, so no statistical tests or error bars were applied; we will note this explicitly. This addresses verifiability without altering the core claims. revision: yes
-
Referee: [Methodology/Results] The central claim that reasoning models substantially outperform non-reasoning models in leveraging feedback and that syntactic/runtime errors are far more tractable rests on the unexamined premise that the chosen problems, models, and languages capture general behavior; no justification or diversity analysis for problem/model selection is provided, which directly affects generalizability.
Authors: We agree explicit justification is needed. The problems were drawn from standard real-world programming benchmarks to reflect practical error distributions, and models were selected to contrast reasoning vs. non-reasoning architectures. In revision we will add a dedicated paragraph in Methodology explaining selection criteria (problem diversity in error types and difficulty; model representativeness) and a Limitations subsection discussing threats to generalizability and scope of claims. revision: yes
Circularity Check
No circularity: purely empirical evaluation without derivations or self-referential definitions
full rationale
The paper is an empirical study evaluating LLMs on iterative code correction using compiler and testcase feedback across models and languages. It reports performance observations, introduces metrics for failures and patterns, and compares reasoning vs. non-reasoning models. No equations, derivations, fitted parameters presented as predictions, or self-citations justifying uniqueness/ansatzes appear in the abstract or described content. Central claims rest on experimental results rather than reducing to inputs by construction, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
& Rouvoy, R
Coignion, T., Quinton, C. & Rouvoy, R. A performance study of llm-generated code on leetcode.Proceedings Of The 28th International Conference On Evaluation And Assessment In Software Engineering. pp. 79-89 (2024)
2024
-
[2]
& Combemale, B
D¨ oderlein, J., Kouadio, N., Acher, M., Khelladi, D. & Combemale, B. Piloting Copilot, Codex, and StarCoder2: Hot temperature, cold prompts, or black magic?. Journal Of Systems And Software. pp. 112562 (2025)
2025
-
[3]
& Chang, K
Zheng, S., Zhang, Y., Zhu, Y., Xi, C., Gao, P., Xun, Z. & Chang, K. Gpt-fathom: Benchmarking large language models to decipher the evolutionary path towards gpt-4 and beyond.Findings Of The Association For Computational Linguistics: NAACL 2024. pp. 1363-1382 (2024)
2024
-
[4]
& Choi, Y
Holtzman, A., Buys, J., Du, L., Forbes, M. & Choi, Y. The Curious Case of Neural Text Degeneration.International Conference On Learning Representations. (2020)
2020
-
[5]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G. & Others Evaluating large language models trained on code.https://doi.org/10.48550/arXiv.2107.03374. (2021)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
-
[6]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q. & Others Program synthesis with large language models. https://doi.org/10.48550/arXiv.2108.07732. (2021)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07732 2021
-
[7]
& Xiong, C
Nijkamp, E., Pang, B., Hayashi, H., Tu, L., Wang, H., Zhou, Y., Savarese, S. & Xiong, C. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis.The Eleventh International Conference On Learning Represen- tations. (2023)
2023
-
[8]
Jiang, J., Wang, F., Shen, J., Kim, S. & Kim, S. A Survey on Large Lan- guage Models for Code Generation.ACM Trans. Softw. Eng. Methodol.. (2025,7), https://doi.org/10.1145/3747588
-
[9]
Jiang, S., Wang, Y. & Wang, Y. Selfevolve: A code evolution framework via large language models.https://doi.org/10.48550/arXiv.2306.02907. (2023)
-
[10]
& Zhang, S
Yu, Z., Gu, W., Wang, Y., Jiang, X., Zeng, Z., Wang, J., Ye, W. & Zhang, S. Reasoning Through Execution: Unifying Process and Outcome Rewards for Code Generation.Forty-second International Conference On Machine Learning. (2025)
2025
-
[11]
& Shang, J
Zhong, L., Wang, Z. & Shang, J. Debug like a Human: A Large Language Model Debugger via Verifying Runtime Execution Step by Step.Findings Of The Asso- ciation For Computational Linguistics ACL 2024. pp. 851-870 (2024)
2024
-
[12]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Gou, Z., Shao, Z., Gong, Y., Shen, Y., Yang, Y., Duan, N. & Chen, W. Critic: Large language models can self-correct with tool-interactive critiquing. https://doi.org/10.48550/arXiv.2305.11738. (2023)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.11738 2023
-
[13]
& Cohen, T
Butt, N., Manczak, B., Wiggers, A., Rainone, C., Zhang, D., Defferrard, M. & Cohen, T. CodeIt: Self-Improving Language Models with Prioritized Hindsight Replay.ICML. (2024) 18 Le Zhang et al
2024
-
[14]
Nadimi, B., Boutaib, G. & Zheng, H. Verimind: Agentic llm for automated verilog generation with a novel evaluation metric. https://doi.org/10.48550/arXiv.2503.16514. (2025)
-
[15]
& Chen, Y
Wang, J. & Chen, Y. A review on code generation with llms: Application and evaluation.2023 IEEE International Conference On Medical Artificial Intelligence (MedAI). pp. 284-289 (2023)
2023
-
[17]
& Chen, K
Liu, J., Liu, H., Xiao, L., Wang, Z., Liu, K., Gao, S., Zhang, W., Zhang, S. & Chen, K. Are Your LLMs Capable of Stable Reasoning?.Findings Of The Association For Computational Linguistics: ACL 2025. pp. 17594-17632 (2025)
2025
-
[18]
Chen, Z., Qin, X., Wu, Y., Ling, Y., Ye, Q., Zhao, W. & Shi, G. Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models. https://doi.org/10.48550/arXiv.2506.20807. (2025)
-
[19]
Shukla, S., Joshi, H. & Syed, R. Security Degradation in Itera- tive AI Code Generation–A Systematic Analysis of the Paradox. https://doi.org/10.48550/arXiv.2506.11022. (2025)
-
[20]
Wang, Z., Li, J., Li, G. & Jin, Z. ChatCoder: Chat-based refine requirement im- proves LLMs’ code generation.https://doi.org/10.48550/arXiv.2311.00272. (2023)
-
[21]
& Milanova, M
Davis, D. & Milanova, M. Parsing Requirements for Automatic Prompting of Large Language Models for Requirements Validation.Intelligent Computing-Proceedings Of The Computing Conference. pp. 1-19 (2025)
2025
-
[22]
Niu, C., Zhang, T., Li, C., Luo, B. & Ng, V. On evaluating the efficiency of source code generated by llms.Proceedings Of The 2024 IEEE/ACM First In- ternational Conference On AI Foundation Models And Software Engineering. pp. 103-107 (2024)
2024
-
[23]
& Mehta, R
Dougherty, Q. & Mehta, R. Proving the coding interview: A benchmark for for- mally verified code generation.2025 IEEE/ACM International Workshop On Large Language Models For Code (LLM4Code). pp. 72-79 (2025)
2025
-
[24]
Guimaraes, E., Nascimento, N., Shivalingaiah, C. & Nelapati, A. Analyzing promi- nent llms: An empirical study of performance and complexity in solving leetcode problems.https://doi.org/10.48550/arXiv.2508.03931. (2025)
-
[25]
& Karkhanis, D
Walder, C. & Karkhanis, D. Pass@K Policy Optimization: Solving Harder Re- inforcement Learning Problems.The Thirty-ninth Annual Conference On Neural Information Processing Systems. (2025)
2025
-
[26]
Code Generation with LLMs: Practical Challenges, Gotchas, and Nuances
Masood, A. Code Generation with LLMs: Practical Challenges, Gotchas, and Nuances. (2025), https://medium.com/@adnanmasood/code-generation-with- llms-practical-challenges-gotchas-and-nuances-7b51d394f588, [Online; posted 28- Feburary-2025]
2025
-
[27]
& Bile, A
Pawar, V., Gawande, M., Kollu, A. & Bile, A. Exploring the Potential of Prompt Engineering: A Comprehensive Analysis of Interacting with Large Language Mod- els.2024 8th International Conference On Computing, Communication, Control And Automation (ICCUBEA). pp. 1-9 (2024)
2024
-
[28]
& Mikkonen, T
Uusn¨ akki, J., Ihantola, P. & Mikkonen, T. Exploring Prompt Engineering with Large Language Models in the Context of Software Maintenance.Intelligent Computing-Proceedings Of The Computing Conference. pp. 166-177 (2025)
2025
-
[29]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D. & Others DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.https://doi.org/10.48550/arXiv.2501.12948. (2025) Iterative Feedback Loops 19
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[30]
Is there an optimal temperature and top-p for code generation with paid LLM APIs?
Siml, J. Is there an optimal temperature and top-p for code generation with paid LLM APIs?. (2023), https://forem.julialang.org/svilupp/is-there-an-optimal- temperature-and-top-p-for-code-generation-with-paid-llm-apis-15am
2023
-
[31]
& Itkonen, J
Lappi, V., Tirronen, V. & Itkonen, J. A replication study on the intuitiveness of programming language syntax.Software Quality Journal.31, 1211-1240 (2023)
2023
-
[32]
Gradual Typing in an Open World
Vitousek, M. & Siek, J. Gradual typing in an open world. https://doi.org/10.48550/arXiv.1610.08476. (2016)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.08476 2016
-
[33]
The Top Programming Languages 2025.IEEE Spectrum
Cass, S. The Top Programming Languages 2025.IEEE Spectrum. (2025,10), https://spectrum.ieee.org/top-programming-languages-2025
2025
-
[34]
Minimum Cost to Equal- ize Array
Zhang, L. & Kothari, S. Holistic Evaluation of State-of-the-Art LLMs for Code Generation.ArXiv E-prints. (2025) A Tables Table 6: pass@1 scores across different models and datasets. Dataset Language DeepSeek-V3 DeepSeek-R1 GPT-4.1-mini GPT-o4-mini Core dataset Python 72.4 84.0 76.289.1 Java 71.6 82.4 75.187.3 Strain dataset Python 55.5 79.0 67.087.0 Java ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.