Twelve quick tips for designing AI-driven HPC workflows
Pith reviewed 2026-06-27 20:52 UTC · model grok-4.3
The pith
Twelve tips target bottlenecks like containerisation and job arrays to make AI-driven HPC workflows scalable and reproducible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
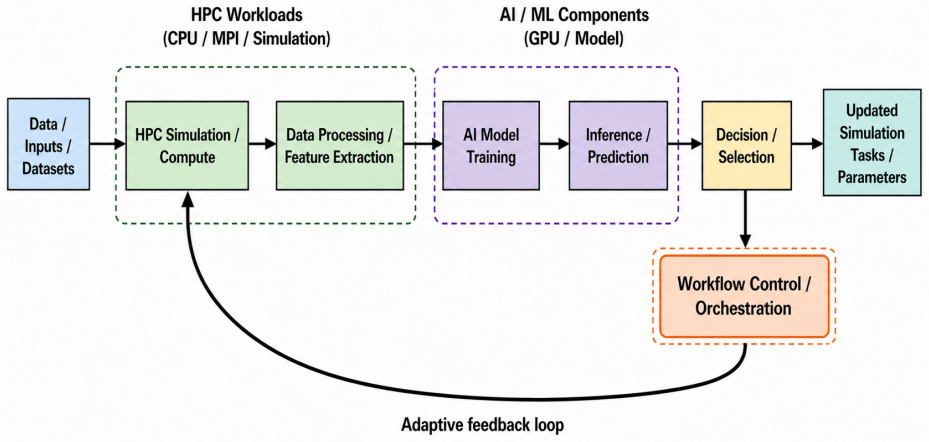
By addressing critical system-level bottlenecks such as containerisation for environment portability, strategic deployment of job arrays, explicit feedback loop mechanics, and I/O optimisation for small files, the twelve tips provide a framework for transitioning from rigid execution pipelines to adaptive, intelligent computational environments in AI-driven HPC workflows.
What carries the argument
A set of twelve practical tips that form a framework addressing data gravity, heterogeneous resources and workflow orchestration.
If this is right
- Containerisation allows the same AI workflow to run unchanged across different HPC clusters.
- Strategic job arrays improve parallel scaling of iterative AI tasks without manual intervention.
- Explicit feedback loop mechanics support the iterative, probabilistic nature of foundation-model workflows.
- I/O optimisation for small files reduces latency that otherwise stalls data-driven AI computations.
- The overall framework supports reproducible results in resource-intensive computational biology applications.
Where Pith is reading between the lines
- The same tips could be tested in non-biology domains that run AI on HPC, such as climate modelling or particle physics simulations.
- Adopting the tips might lower the engineering overhead when researchers move from traditional pipelines to AI-integrated ones.
- The emphasis on feedback loops points toward future workflow systems that self-tune based on runtime performance data.
Load-bearing premise
The identified bottlenecks are the main system-level issues that, once fixed by the tips, enable the shift to adaptive AI-driven HPC environments.
What would settle it
A controlled comparison showing that AI-driven HPC workflows built without applying these twelve tips achieve equivalent scalability, portability and reproducibility would falsify the central claim.
Figures
read the original abstract
High-performance computing (HPC) clusters remain the backbone of large-scale scientific computation, traditionally executing deterministic, linear pipelines optimised for predictable performance. However, the pervasive integration of artificial intelligence (AI) and foundation models into scientific research has introduced a fundamentally new computational paradigm. AI-driven workflows are characteristically iterative, data-driven, and probabilistic, introducing unique challenges regarding data gravity, heterogeneous resource management, and complex workflow orchestration. This guide provides twelve practical tips designed to help researchers design efficient, scalable, and reproducible AI-driven HPC workflows. By addressing critical system-level bottlenecks - such as containerisation for environment portability, strategic deployment of job arrays, explicit feedback loop mechanics, and I/O optimisation for small files - this article offers a framework for transitioning from rigid execution pipelines to adaptive, intelligent computational environments. While these architectural principles are broadly applicable across distributed environments, they are particularly tailored to the resource-intensive throughput demands of modern computational biology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents twelve practical tips for designing AI-driven HPC workflows. It claims these tips address critical system-level bottlenecks such as containerisation for environment portability, strategic deployment of job arrays, explicit feedback loop mechanics, and I/O optimisation for small files, thereby providing a framework for transitioning from rigid deterministic pipelines to adaptive, intelligent computational environments, with particular tailoring to the throughput demands of modern computational biology.
Significance. If the tips prove effective in practice, the work could offer actionable guidance for researchers integrating AI and foundation models into HPC environments, highlighting issues like data gravity, heterogeneous resources, and workflow orchestration. As a synthesis of practical heuristics rather than a contribution with new models, empirical results, or formal derivations, its significance is limited to practitioner utility and depends on the unvalidated applicability of the advice.
major comments (1)
- [Abstract] Abstract: The central claim that the twelve tips address 'critical system-level bottlenecks' and 'offer a framework for transitioning' from rigid to adaptive environments rests entirely on untested advisory content. The manuscript supplies no data, validation, examples, case studies, or performance metrics to support the effectiveness of the tips or the identified bottlenecks (containerisation, job arrays, feedback loops, I/O).
Simulated Author's Rebuttal
We thank the referee for their review. The manuscript is a practical 'quick tips' guide synthesizing experience-based heuristics for AI-driven HPC workflows, not an empirical research contribution. We address the concern about validation below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the twelve tips address 'critical system-level bottlenecks' and 'offer a framework for transitioning' from rigid to adaptive environments rests entirely on untested advisory content. The manuscript supplies no data, validation, examples, case studies, or performance metrics to support the effectiveness of the tips or the identified bottlenecks (containerisation, job arrays, feedback loops, I/O).
Authors: The manuscript is explicitly positioned as a set of twelve practical tips, consistent with the established 'quick tips' format in computational biology and related fields. These articles provide actionable guidance derived from practitioner experience rather than new experimental results, formal proofs, or performance benchmarks. The bottlenecks referenced (containerisation for portability, job arrays, feedback loops, small-file I/O) are standard, widely reported challenges in HPC literature for data-intensive AI workloads; the tips describe established strategies for mitigating them. The abstract language frames the tips as offering a framework, which is appropriate for a synthesis paper. We can revise the abstract to more explicitly qualify the content as experience-based heuristics without new validation data. revision: partial
Circularity Check
No significant circularity
full rationale
The manuscript is a descriptive 'quick tips' guide offering practical heuristics for AI-driven HPC workflows. It contains no equations, derivations, fitted parameters, models, or quantitative claims. No load-bearing steps exist that could reduce to self-definition, fitted inputs, or self-citation chains. The central content is advisory and does not assert testable results or invoke uniqueness theorems, rendering circularity analysis inapplicable. The derivation chain is empty by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fifteen quick tips for success with HPC, i.e., responsibly BASHing that Linux cluster
Alnasir JJ. Fifteen quick tips for success with HPC, i.e., responsibly BASHing that Linux cluster. PLoS Computational Biology. 2021;17(8):e1009207. doi:10.1371/journal.pcbi.1009207
-
[2]
Nine quick tips for software containerization
Moreau D, Wiebels K. Nine quick tips for software containerization. PLoS Computational Biology. 2026;22(4):e1014197. doi:10.1371/journal.pcbi.1014197
-
[3]
FerreiradaSilvaR,BadiaRM,BalisB,ColemanT,CoppensF,DiNataleF,etal.FrontiersinScientificWorkflows: Pervasive Integration With High-Performance Computing Computer. 2024. doi:10.1109/MC.2024.3401542
-
[4]
Enabling dynamic and intelligent workflows for HPC, data analytics and AI convergence
Ejarque J, Badia RM, Albertin L, Aloisio G, Baglione E, Becerra Y, et al. Enabling dynamic and intelligent workflows for HPC, data analytics and AI convergence. Future Generation Computer Systems. 2022;130:245–262. doi:10.1016/j.future.2022.01.019
-
[5]
Singularity: Scientific containers for mobility of compute
Kurtzer GM, Sochat V, Bauer MW. Singularity: Scientific containers for mobility of compute. PLoS ONE. 2017;12(5):e0177459. doi:10.1371/journal.pone.0177459
-
[6]
Accelerating the machine learning lifecycle with MLflow
Zaharia M, Chen A, Davidson A, Ghodsi A, Hong SA, Konwinski A, et al. Accelerating the machine learning lifecycle with MLflow. IEEE Data Engineering Bulletin. 2018;41(4):39–45
2018
-
[7]
Proceedings of the EDBT/ICDT 2011 Workshop on Array Databases
FolkM,HeberG,KoziolQ,PourmalE,RobinsonD.AnoverviewoftheHDF5technologysuiteanditsapplications. Proceedings of the EDBT/ICDT 2011 Workshop on Array Databases. 2011
2011
-
[8]
ADIOS 2: The Adaptable Input Output System
Godoy WF, Podhorszki N, Wang R, Atkins C, Eisenhauer G, Gu J, et al. ADIOS 2: The Adaptable Input Output System. A framework for high-performance data management. SoftwareX. 2020;12:100561. doi:10.1016/j.softx.2020.100561
-
[9]
Nextflow enables reproducible computational workflows
Di Tommaso P, Chatzou M, Floden EW, Barja PP, Palumbo E, Notredame C. Nextflow enables reproducible computational workflows. Nature Biotechnology. 2017;35(4):316–319. doi:10.1038/nbt.3820
-
[10]
Sustainable data analysis with Snakemake
Mölder F, Jablonski KP, Letcher B, Hall MB, Tomkins-Tinch CH, Sochat V, et al. Sustainable data analysis with Snakemake. F1000Research. 2021;10:33. doi:10.12688/f1000research.29032.3
-
[11]
Common Workflow Language, v1.0
Amstutz P, Crusoe MR, Tijanić N, Chapman B, Chilton J, Heuer M, et al. Common Workflow Language, v1.0. figshare. 2016. doi:10.6084/m9.figshare.3115156.v2
-
[12]
Parsl: Pervasive parallel programming in Python
Babuji Y, Woodard A, Li Z, Katz DS, Clifford B, Kumar R, et al. Parsl: Pervasive parallel programming in Python. Proceedings of the 28th ACM International Symposium on High-Performance Parallel and Distributed Computing. 2019;25–36. doi:10.1145/3307681.3325400
-
[13]
Pegasus, a workflow management system for science automation
Deelman E, Vahi K, Juve G, Rynge M, Callaghan S, Maechling PJ, et al. Pegasus, a workflow management system for science automation. Future Generation Computer Systems. 2015;46:17–35. doi:10.1016/j.future.2014.10.008. 8
-
[14]
Concurrency and Computation: Practice and Experience
JainA,OngSP,ChenW,MedasaniB,QuX,KocherM,etal.FireWorks: Adynamicworkflowsystemdesignedfor high-throughput applications. Concurrency and Computation: Practice and Experience. 2015;27(17):5037–5059. doi:10.1002/cpe.3505
-
[15]
Dask: Parallel computation with blocked algorithms and task scheduling
Rocklin M. Dask: Parallel computation with blocked algorithms and task scheduling. Proceedings of the 14th Python in Science Conference. 2015;126–132. doi:10.25080/Majora-7b98e3ed-013
-
[16]
Ray: A distributed framework for emerging AI applications
Moritz P, Nishihara R, Wang S, Tumanov A, Liaw R, Liang E, et al. Ray: A distributed framework for emerging AI applications. Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation. 2018;561–577. 9
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.