Measuring Semantic Progress in Multi-turn Dialogue via Information Gain
Pith reviewed 2026-06-27 09:26 UTC · model grok-4.3
The pith
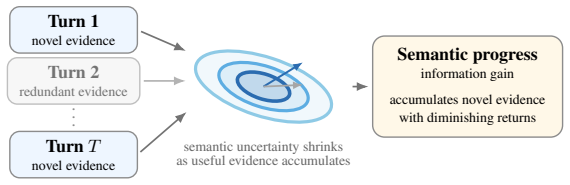
Semantic progress in multi-turn dialogues can be measured as question-conditioned information gain approximated in embedding space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
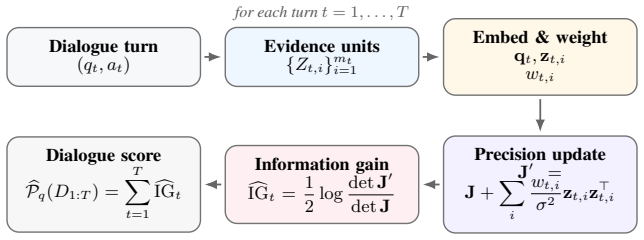
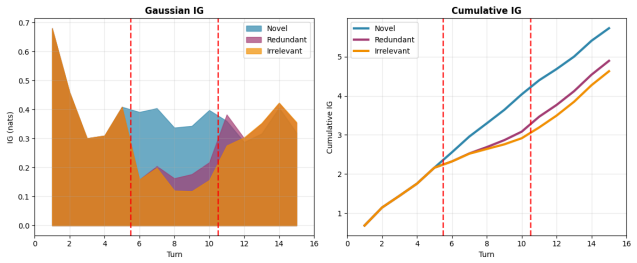
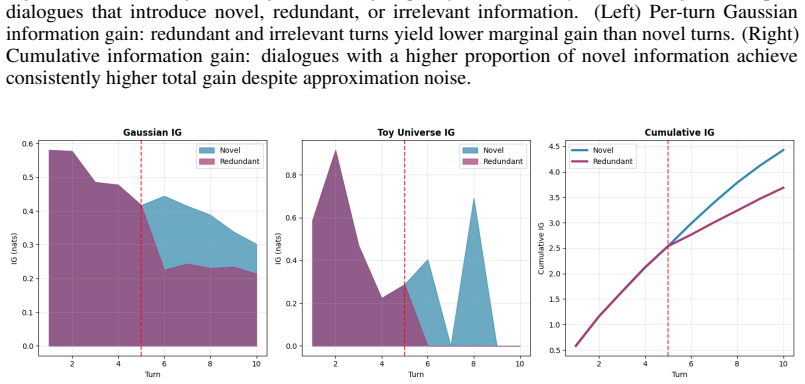
The authors establish that semantic progress equals question-conditioned uncertainty reduction and can be tracked by the log-determinant of the posterior covariance in a Gaussian embedding model; this formulation yields monotonicity, additive decomposition of total gain across turns, and automatic penalization of redundant evidence, all computed without autoregressive sampling.
What carries the argument
The tractable Gaussian estimator of question-conditioned uncertainty reduction whose covariance matrix is updated in closed form from successive embedding vectors.
If this is right
- Total semantic progress decomposes additively into per-turn contributions.
- The metric automatically assigns lower marginal gain to redundant turns.
- Agreement with human judgments remains competitive even when only lightweight embeddings are used under CPU execution.
- The approach requires no autoregressive model calls at evaluation time and is deterministic for a fixed embedding model.
Where Pith is reading between the lines
- Dialogue systems could be trained or reinforced directly against this information-gain objective to encourage accumulation of relevant facts.
- The separation of semantic progress from other qualities such as fluency or politeness may allow modular evaluation pipelines.
- The same Gaussian-update machinery could be tested on non-dialogue sequential tasks such as iterative question answering or scientific hypothesis refinement.
Load-bearing premise
That second-order statistics in a fixed embedding space suffice to capture the accumulation of question-relevant non-redundant information in a way that matches human notions of semantic progress.
What would settle it
A new collection of multi-turn dialogues in which the metric assigns high scores to conversations that human raters judge as containing little new question-relevant information, or low scores to conversations humans judge as highly progressive.
Figures
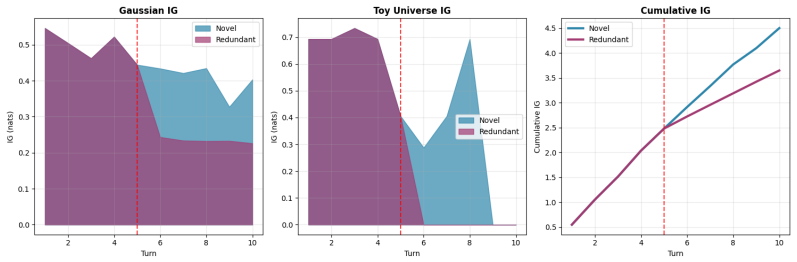
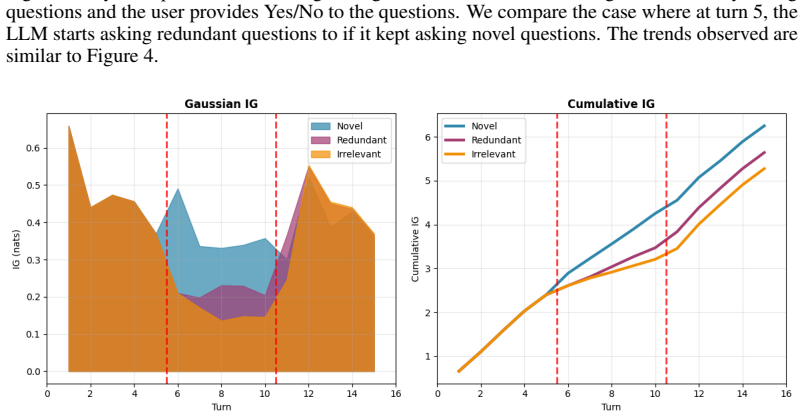
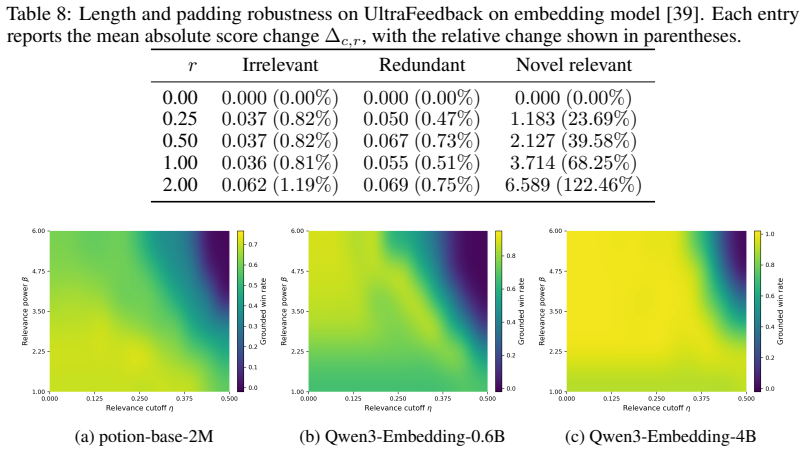
read the original abstract
Evaluating multi-turn dialogue is challenging because quality emerges across turns rather than within individual responses. We focus on a key dimension of information-seeking dialogue: semantic progress, defined as the accumulation of new, question-relevant, and non-redundant information over the course of a conversation. We formalize semantic progress as question-conditioned uncertainty reduction and introduce an information-theoretic metric that approximates it in embedding space. Our main estimator uses a tractable Gaussian formulation with closed-form updates, while a complementary maximum-entropy argument shows why log-determinant structure arises more broadly when only second-order embedding information is retained. This formulation yields desirable theoretical properties, including monotonicity, additive decomposition of total information gain across turns, and diminishing returns for redundant evidence. Unlike LLM-as-a-judge approaches, our metric requires no autoregressive inference at evaluation time and is fully reproducible for a fixed embedding model. Experiments on MT-Bench, Chatbot Arena, and UltraFeedback show that the proposed metric achieves competitive agreement with human judgments despite targeting only semantic progress, with improved alignment on MT-Bench and UltraFeedback compared to several LLM-based judges. Notably, the method remains effective with lightweight embedding models under CPU-only execution, indicating that semantic progress can be captured without reliance on large model capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes semantic progress in multi-turn information-seeking dialogue as question-conditioned uncertainty reduction and approximates it via a tractable Gaussian model in a fixed embedding space with closed-form updates; a max-entropy argument justifies the log-determinant form. The metric is shown to satisfy monotonicity, additive decomposition across turns, and diminishing returns. Experiments on MT-Bench, Chatbot Arena, and UltraFeedback report competitive agreement with human judgments (improved on two of the three benchmarks relative to several LLM judges) while remaining effective with lightweight embeddings under CPU-only execution.
Significance. If the embedding-space Gaussian approximation is shown to track human notions of semantic progress, the method supplies a reproducible, inference-free evaluation tool that isolates one dimension of dialogue quality. The closed-form updates and explicit theoretical properties (monotonicity, additivity) constitute clear strengths relative to black-box LLM judges.
major comments (2)
- [§3.2] §3.2 (Gaussian formulation and max-entropy justification): the claim that second-order statistics in a fixed embedding space suffice to isolate question-relevant, non-redundant information accumulation is load-bearing yet receives no direct validation against ground-truth information gain, higher-order moments, or non-Gaussian structure; without such a check the approximation's fidelity remains untested.
- [Experiments] Experiments section (human-agreement results): the reported competitive correlations on MT-Bench and UltraFeedback are presented without error analysis, data-exclusion rules, or sensitivity to embedding dimensionality, making it impossible to assess whether the alignment is robust or driven by particular subsets of the data.
minor comments (1)
- [Abstract] Abstract: the phrase 'improved alignment … compared to several LLM-based judges' does not name the specific baselines or report the exact correlation coefficients, hindering immediate comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the theoretical properties and practical advantages of the proposed metric. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Gaussian formulation and max-entropy justification): the claim that second-order statistics in a fixed embedding space suffice to isolate question-relevant, non-redundant information accumulation is load-bearing yet receives no direct validation against ground-truth information gain, higher-order moments, or non-Gaussian structure; without such a check the approximation's fidelity remains untested.
Authors: The max-entropy argument in §3.2 shows that the log-determinant form is the unique functional that arises when only second-order moments are retained, independent of an explicit Gaussian assumption. Direct ground-truth information gain is not observable in this setting, as it would require an exhaustive posterior over all possible semantic states; human judgments of dialogue quality serve as the external validation instead. We agree that the manuscript would benefit from a clearer discussion of the approximation's scope and limitations, and we will expand §3.2 accordingly. revision: partial
-
Referee: [Experiments] Experiments section (human-agreement results): the reported competitive correlations on MT-Bench and UltraFeedback are presented without error analysis, data-exclusion rules, or sensitivity to embedding dimensionality, making it impossible to assess whether the alignment is robust or driven by particular subsets of the data.
Authors: We agree that these details are necessary for assessing robustness. In the revised version we will add bootstrap standard errors on all reported correlations, state the precise data-exclusion criteria (minimum turns, removal of truncated dialogues), and include a sensitivity table showing correlation stability across embedding dimensionalities (e.g., 384–1024). revision: yes
Circularity Check
No circularity: metric derived from information theory on embeddings, validated post-hoc against human judgments
full rationale
The paper defines semantic progress via question-conditioned uncertainty reduction, then approximates it with a Gaussian in embedding space using closed-form updates and a max-entropy argument for the log-det form. These steps are presented as first-principles constructions with stated theoretical properties (monotonicity, additivity, diminishing returns). Experiments compare the resulting metric to human judgments on MT-Bench, Chatbot Arena, and UltraFeedback, but the abstract and description give no indication that the metric itself is fitted to those judgments or that any prediction reduces by construction to its inputs. No self-citations are invoked as load-bearing for the core formalization. This is a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embedding space captures question-relevant semantic information such that uncertainty reduction can be tracked via second-order statistics
- standard math Log-determinant structure arises when only second-order embedding information is retained
Reference graph
Works this paper leans on
-
[1]
AutoConv: Automatically generating information-seeking con- versations with large language models
Siheng Li, Cheng Yang, Yichun Yin, Xinyu Zhu, Zesen Cheng, Lifeng Shang, Xin Jiang, Qun Liu, and Yujiu Yang. AutoConv: Automatically generating information-seeking con- versations with large language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki 9 Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Compu- tational Lingu...
-
[2]
doi: 10.18653/v1/2023.acl-short.149
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-short.149. URL https://aclanthology.org/2023.acl-short.149/
-
[3]
Enhancing conversational search: Large language model-aided informative query rewriting
Fanghua Ye, Meng Fang, Shenghui Li, and Emine Yilmaz. Enhancing conversational search: Large language model-aided informative query rewriting. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5985–6006, Singapore, December 2023. Association for Computational Linguis- tics. d...
-
[4]
Large language models meet knowledge graphs for question answering: Synthesis and opportunities
Chuangtao Ma, Yongrui Chen, Tianxing Wu, Arijit Khan, and Haofen Wang. Large language models meet knowledge graphs for question answering: Synthesis and opportunities. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2458...
-
[5]
Evaluating open-domain question answering in the era of large language models
Ehsan Kamalloo, Nouha Dziri, Charles Clarke, and Davood Rafiei. Evaluating open-domain question answering in the era of large language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5591–5606, Toronto, Canada, July
-
[6]
doi: 10.18653/v1/2023.acl-long.307
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.307. URL https://aclanthology.org/2023.acl-long.307/
-
[7]
Zeqiu Wu, Ryu Parish, Hao Cheng, Sewon Min, Prithviraj Ammanabrolu, Mari Ostendorf, and Hannaneh Hajishirzi. InSCIt: Information-seeking conversations with mixed-initiative interactions.Transactions of the Association for Computational Linguistics, 11:453–468, 2023. doi: 10.1162/tacl_a_00559. URLhttps://aclanthology.org/2023.tacl-1.27/
-
[8]
Primack, Summer Yue, and Chen Xing
Kaustubh Deshpande, Ved Sirdeshmukh, Johannes Baptist Mols, Lifeng Jin, Ed-Yeremai Hernandez-Cardona, Dean Lee, Jeremy Kritz, Willow E. Primack, Summer Yue, and Chen Xing. MultiChallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier LLMs. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, ed...
-
[9]
Mismatch between multi-turn dialogue and its evaluation metric in dialogue state tracking
Takyoung Kim, Hoonsang Yoon, Yukyung Lee, Pilsung Kang, and Misuk Kim. Mismatch between multi-turn dialogue and its evaluation metric in dialogue state tracking. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 297–30...
2022
-
[10]
From generation to judgment: Opportunities and challenges of LLM-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. From generation to judgment: Opportunities and challenges of LLM-as-a-judge. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings...
-
[11]
Evaluating llm-based agents for multi-turn conversations: A survey, 2025
Shengyue Guan, Haoyi Xiong, Jindong Wang, Jiang Bian, Bin Zhu, and Jian guang Lou. Evaluating llm-based agents for multi-turn conversations: A survey, 2025. URL https: //arxiv.org/abs/2503.22458. 10
arXiv 2025
-
[12]
Sarah E. Finch, James D. Finch, and Jinho D. Choi. Don’t forget your ABC’s: Evaluating the state-of-the-art in chat-oriented dialogue systems. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15044–15071, Toronto, Canada, J...
-
[13]
ConsistencyChecker: Tree-based evaluation of LLM generalization capabilities
Zhaochen Hong, Haofei Yu, and Jiaxuan You. ConsistencyChecker: Tree-based evaluation of LLM generalization capabilities. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 33039–33075, Vienna, Austria,...
2025
-
[14]
Llms-as-judges: A comprehensive survey on llm-based evaluation methods, 2024
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. Llms-as-judges: A comprehensive survey on llm-based evaluation methods, 2024. URL https://arxiv.org/abs/2412.05579
Pith/arXiv arXiv 2024
-
[15]
MultiWOZ - a large-scale multi-domain Wizard-of-Oz dataset for task-oriented dialogue modelling
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gaši´c. MultiWOZ - a large-scale multi-domain Wizard-of-Oz dataset for task-oriented dialogue modelling. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Nat...
-
[16]
τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024. URL https://arxiv.org/abs/ 2406.12045
Pith/arXiv arXiv 2024
-
[17]
TD-EV AL: Revisiting task-oriented dialogue evaluation by combining turn-level precision with dialogue-level comparisons
Emre Can Acikgoz, Carl Guo, Suvodip Dey, Akul Datta, Takyoung Kim, Gokhan Tur, and Dilek Hakkani-Tur. TD-EV AL: Revisiting task-oriented dialogue evaluation by combining turn-level precision with dialogue-level comparisons. In Frédéric Béchet, Fabrice Lefèvre, Nicholas Asher, Seokhwan Kim, and Teva Merlin, editors,Proceedings of the 26th Annual Meeting of...
-
[18]
URL https://aclanthology.org/2025
Association for Computational Linguistics. URL https://aclanthology.org/2025. sigdial-1.7/
2025
-
[19]
Towards fair evaluation of dialogue state tracking by flexible incorporation of turn-level performances
Suvodip Dey, Ramamohan Kummara, and Maunendra Desarkar. Towards fair evaluation of dialogue state tracking by flexible incorporation of turn-level performances. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 318–324...
2022
-
[20]
What is wrong with you?: Leveraging user sentiment for automatic dialog evaluation
Sarik Ghazarian, Behnam Hedayatnia, Alexandros Papangelis, Yang Liu, and Dilek Hakkani- Tur. What is wrong with you?: Leveraging user sentiment for automatic dialog evaluation. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Findings of the Association for Computational Linguistics: ACL 2022, pages 4194–4204, Dublin, Ireland, May 2022...
-
[21]
Bao Chen, Yuanjie Wang, Zeming Liu, and Yuhang Guo. Automatic evaluate dialogue ap- propriateness by using dialogue act. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7361–7372, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023. f...
-
[22]
In: Cao, Y., Feng, Y., Xiong, D
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 11 page...
-
[23]
Leveraging LLMs for dialogue quality measurement
Jinghan Jia, Abi Komma, Timothy Leffel, Xujun Peng, Ajay Nagesh, Tamer Soliman, Aram Galstyan, and Anoop Kumar. Leveraging LLMs for dialogue quality measurement. In Yi Yang, Aida Davani, Avi Sil, and Anoop Kumar, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno...
-
[24]
Di- alogBench: Evaluating LLMs as human-like dialogue systems
Jiao Ou, Junda Lu, Che Liu, Yihong Tang, Fuzheng Zhang, Di Zhang, and Kun Gai. Di- alogBench: Evaluating LLMs as human-like dialogue systems. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 1: L...
-
[25]
Paireval: Open-domain dialogue evaluation metric with pairwise comparisons
ChaeHun Park, Minseok Choi, Dohyun Lee, and Jaegul Choo. Paireval: Open-domain dialogue evaluation metric with pairwise comparisons. InFirst Conference on Language Modeling, 2024. URLhttps://openreview.net/forum?id=y6aGT625Lk
2024
-
[26]
An LLM feature-based framework for dialogue constructiveness assessment
Lexin Zhou, Youmna Farag, and Andreas Vlachos. An LLM feature-based framework for dialogue constructiveness assessment. In Yaser Al-Onaizan, Mohit Bansal, and Yun- Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natu- ral Language Processing, pages 5389–5409, Miami, Florida, USA, November 2024. As- sociation for Computational...
-
[27]
Exploring the reliability of large language models as customized evaluators for diverse NLP tasks
Qintong Li, Leyang Cui, Lingpeng Kong, and Wei Bi. Exploring the reliability of large language models as customized evaluators for diverse NLP tasks. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, pages 10325...
2025
-
[28]
Chen Zhang, Luis Fernando D’Haro, Yiming Chen, Malu Zhang, and Haizhou Li. A com- prehensive analysis of the effectiveness of large language models as automatic dialogue eval- uators. InProceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteent...
-
[29]
Introducing mistral 3.https://mistral.ai/news/mistral-3, 2025
Mistral AI. Introducing mistral 3.https://mistral.ai/news/mistral-3, 2025
2025
-
[30]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
Pith/arXiv arXiv 2025
-
[31]
Introducing gpt-oss
OpenAI. Introducing gpt-oss. https://openai.com/index/introducing-gpt-oss/, 2025
2025
-
[32]
Claude 3.7 sonnet and claude code
Anthropic. Claude 3.7 sonnet and claude code. https://www.anthropic.com/news/ claude-3-7-sonnet, February 2025
2025
-
[33]
Introducing claude 4
Anthropic. Introducing claude 4. https://www.anthropic.com/news/claude-4, May 2025
2025
-
[34]
Introducing claude sonnet 4.5
Anthropic. Introducing claude sonnet 4.5. https://www.anthropic.com/news/ claude-sonnet-4-5, Sep 2025
2025
-
[35]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openre...
2023
-
[36]
Ultrafeedback: boosting language models with scaled ai feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: boosting language models with scaled ai feedback. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[37]
Model2vec: Fast state-of-the-art static embeddings,
Stephan Tulkens and Thomas van Dongen. Model2vec: Fast state-of-the-art static embeddings,
-
[38]
URLhttps://github.com/MinishLab/model2vec
-
[39]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers, 2020. URL https://arxiv.org/abs/2002.10957
arXiv 2020
-
[40]
Arctic-embed: Scalable, efficient, and accurate text embedding models, 2024
Luke Merrick, Danmei Xu, Gaurav Nuti, and Daniel Campos. Arctic-embed: Scalable, efficient, and accurate text embedding models, 2024. URLhttps://arxiv.org/abs/2405.05374
arXiv 2024
-
[41]
Morris, Brandon Duderstadt, and Andriy Mulyar
Zach Nussbaum, John X. Morris, Brandon Duderstadt, and Andriy Mulyar. Nomic embed: Training a reproducible long context text embedder, 2024
2024
-
[42]
Microllama: A 300m-parameter language model trained from scratch
Zixiao Ken Wang. Microllama: A 300m-parameter language model trained from scratch. https://github.com/keeeeenw/MicroLlama, https://huggingface.co/keeeeenw/ MicroLlama, 2024. GitHub and Hugging Face repositories
2024
-
[43]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embed- ding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
Pith/arXiv arXiv 2025
-
[44]
Cover and J
T. Cover and J. Thomas.Elements of Information Theory. Wileys Series in Telecommunications, New York, 2 edition, 2006. 13
2006
-
[45]
projection like
OpenAI. Introducing GPT-5.4 mini and nano, March 2026. URL https://openai.com/ index/introducing-gpt-5-4-mini-and-nano/. 14 Appendix A Queries as One-dimensional Measurements We model an embedding direction, such as a query or evidence embedding, as a one-dimensional (rank-one) measurement of the latent semantic state S∈R d. A text span x∈ A ∗ induces a d...
2026
-
[46]
A fixed random seed is used to select and order evaluation examples
-
[47]
Timing starts immediately before the first scoring call
-
[48]
Each dialogue pair is scored sequentially
-
[49]
We report total elapsed time and normalized runtime (seconds per dialogue pair), averaged over R= 5 runs
Timing stops after the final prediction is produced. We report total elapsed time and normalized runtime (seconds per dialogue pair), averaged over R= 5 runs. We further verify that overhead from data access and prediction logic is negligible relative to scoring time. The standard deviations for the runtimes are reported in Table 5. Judge Prompt: You are ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.