Anti-Collapse Dynamics and the Emergence of Multi-Time-Scale Learning in Recurrent Neural Networks
Pith reviewed 2026-06-30 07:31 UTC · model grok-4.3
The pith
The asymptotic decay of influence in recurrent networks emerges from the coupling of state and parameter dynamics, not the architecture alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
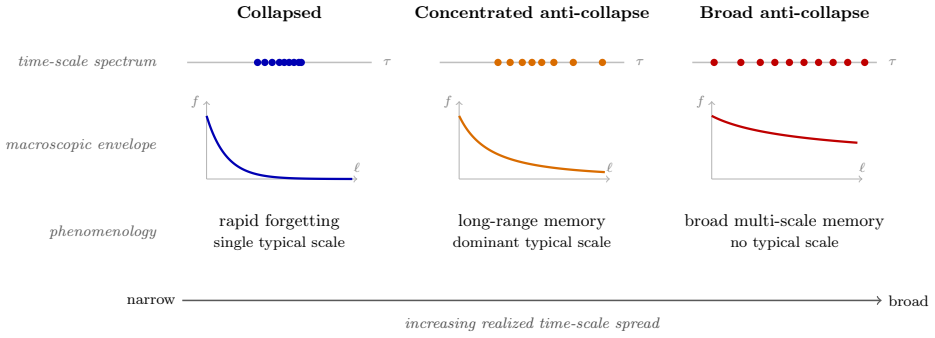
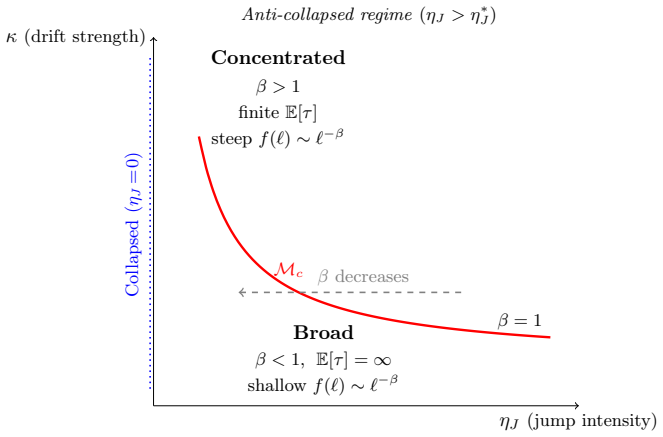
The asymptotic decay class of f(ℓ) is not fixed by the architecture but emerges from the coupling between the state dynamics and parameter dynamics, settling into either a collapsed regime with fast exponential forgetting or an extended anti-collapsed regime with slow power-law forgetting, governed by the spectral exponent β.
What carries the argument
The coarse-grained stochastic process that models the competition between training-driven contraction of time scales and heavy-tailed pushes to longer scales, with the spectral exponent β governing the resulting distribution and forgetting.
Load-bearing premise
The architecture and optimizer together must support generating and maintaining a broad spread of time scales in the network.
What would settle it
Train recurrent networks on tasks requiring long-range dependencies and measure whether the empirical influence envelope f(ℓ) follows an exponential or power-law decay under varying optimizer and architecture choices.
Figures
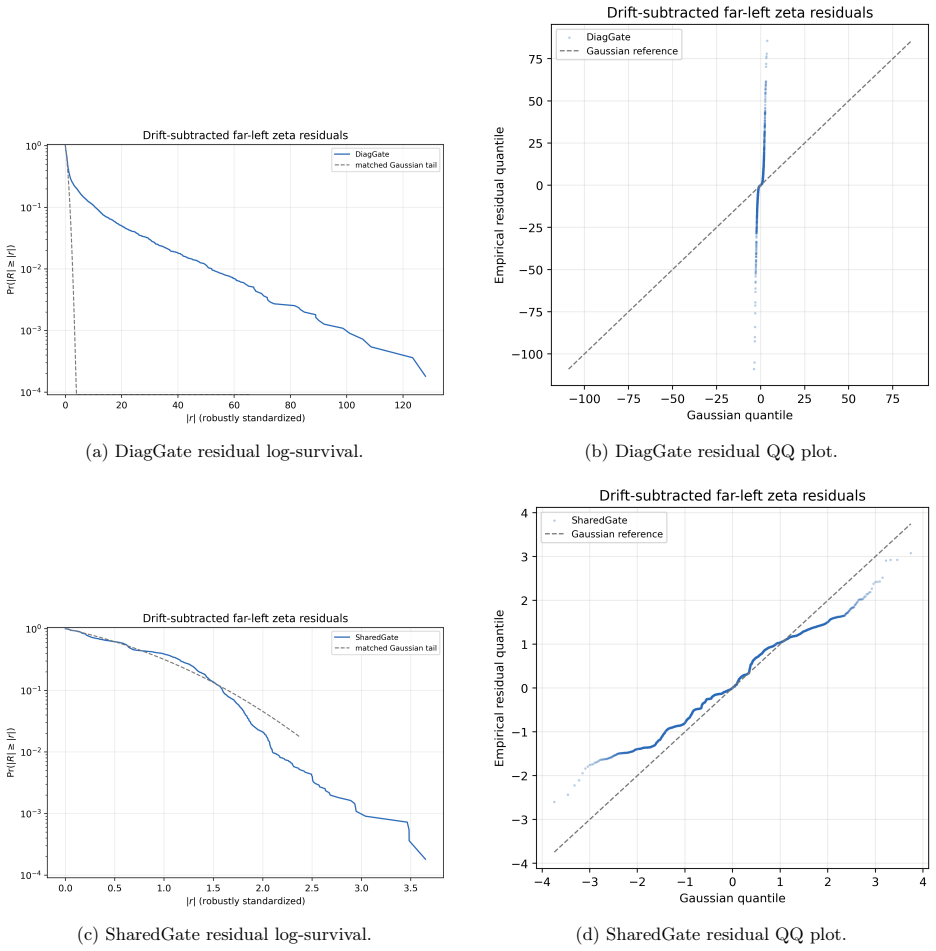
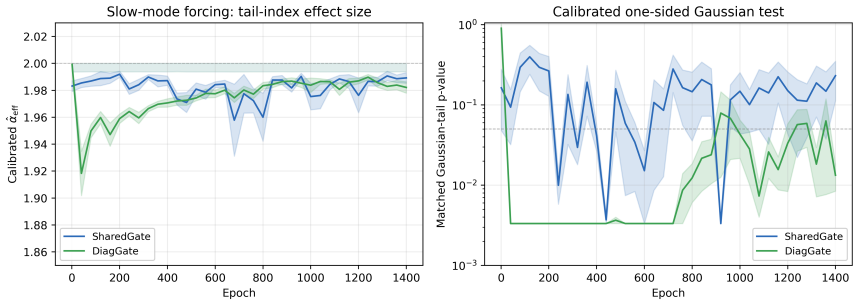
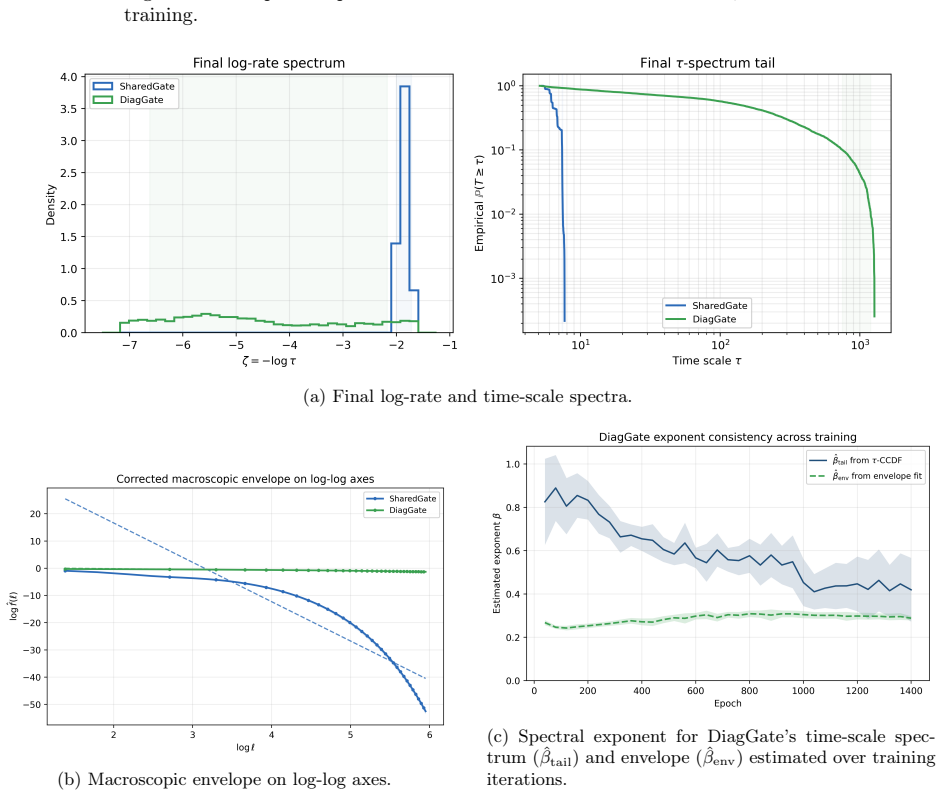
read the original abstract
Long-range learning is hard for recurrent networks trained with stochastic gradient descent, because the influence of a past input fades with the lag $\ell$, and if it fades too fast the dependence cannot be learned from finite data. This fade is captured by an envelope $f(\ell)$. An exponential fade makes the data needed to learn a lag-$\ell$ dependence grow exponentially, putting long horizons out of reach; a power-law fade keeps the cost polynomial. We show that the asymptotic decay class of $f(\ell)$ is not fixed by the architecture. Instead, it emerges from the coupling between the state dynamics and parameter dynamics, settling into either a collapsed regime (fast, exponential forgetting) or an extended, anti-collapsed regime (slow, power-law forgetting). The intuition is a competition within these coupled dynamics. Training drives the network's effective time scales toward short ones, while rare, heavy-tailed fluctuations of the learning dynamics push a few of them to very long values. The extended regime survives only when these heavy-tailed pushes are strong enough to balance the pull. We make this mathematically precise with a coarse-grained stochastic process and prove exactly when the extended regime exists. A single exponent, the spectral exponent~$\beta$, then governs both the spread of time scales and how slowly the network forgets. Realizing the regime in practice needs one more ingredient: the joint action of the architecture and the optimizer must be able to hold such a broad spread. A network whose capacity to generate broad time-scale spectra is severely constrained still collapses, even when supplied with strong heavy-tailed forcing. Heavy-tailed fluctuations thus act not as noise to be suppressed, but as the mechanism that sustains long-range learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the asymptotic decay class of the influence envelope f(ℓ) in RNNs trained by SGD is not fixed by architecture alone but emerges from the coupling of state and parameter dynamics. This coupling produces either a collapsed regime with exponential forgetting or an anti-collapsed regime with power-law forgetting; the latter is sustained when heavy-tailed fluctuations in the learning dynamics are strong enough to counteract the optimizer's pull toward short time scales. A coarse-grained stochastic process is introduced to derive an exact existence condition for the anti-collapsed regime, controlled by a single spectral exponent β that simultaneously governs the spread of time scales and the forgetting rate. Realization of the regime further requires that the architecture and optimizer together can support a sufficiently broad spectrum of time scales.
Significance. If the central derivation holds, the work supplies a dynamical-systems account of how long-range learning can arise in recurrent networks without being architecturally predetermined, with heavy-tailed optimizer fluctuations acting as the sustaining mechanism rather than noise. The explicit existence proof via the coarse-grained process and the identification of β as the governing parameter constitute a clear strength, offering falsifiable predictions about regime boundaries that could be tested in controlled simulations. This perspective may inform both theoretical analyses of memory in RNNs and practical choices of architectures/optimizers for long-horizon tasks.
major comments (2)
- [coarse-grained stochastic process section] The reduction from the coupled RNN state/parameter dynamics to the coarse-grained stochastic process (described in the section introducing the stochastic process and the existence proof) averages recurrent correlations and Jacobian effects into effective time-scale variables whose fluctuations are taken to be heavy-tailed. No explicit error bound or invariance argument is supplied showing that this averaging preserves the competition between the short-scale pull and the heavy-tailed pushes; if recurrent correlations alter the tail exponent, the proven existence condition for the anti-collapsed regime may not transfer to the original system.
- [derivation of β and decay class] The spectral exponent β is stated to govern both the spread of time scales and the asymptotic decay class of f(ℓ). The manuscript does not clarify whether this dual role follows from an independent derivation of the decay class or is built into the definition of the coarse-grained process itself; a concrete check (e.g., an auxiliary calculation showing the decay exponent is not tautological in β) would strengthen the claim that β is the single controlling parameter.
minor comments (2)
- [Introduction] Notation for the envelope f(ℓ) and the lag variable ℓ is introduced in the abstract but could be restated with a brief equation when first used in the main text to aid readers.
- [Abstract] The abstract asserts that 'the joint action of the architecture and the optimizer must be able to hold such a broad spread'; a short forward reference to the section containing the capacity constraint would improve flow.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments and the positive evaluation of the manuscript's contributions. We address the two major comments below, indicating where revisions will be made to clarify the points raised.
read point-by-point responses
-
Referee: [coarse-grained stochastic process section] The reduction from the coupled RNN state/parameter dynamics to the coarse-grained stochastic process (described in the section introducing the stochastic process and the existence proof) averages recurrent correlations and Jacobian effects into effective time-scale variables whose fluctuations are taken to be heavy-tailed. No explicit error bound or invariance argument is supplied showing that this averaging preserves the competition between the short-scale pull and the heavy-tailed pushes; if recurrent correlations alter the tail exponent, the proven existence condition for the anti-collapsed regime may not transfer to the original system.
Authors: We agree that an explicit error bound or invariance argument would strengthen the justification for the coarse-graining step. The reduction relies on a separation of timescales between fast state dynamics and slower parameter updates, under which the effective time-scale variables inherit heavy-tailed fluctuations from the SGD noise. While the manuscript validates the regime through simulations of the full system, we will add a dedicated subsection discussing the assumptions of the averaging procedure and arguing that recurrent correlations do not modify the tail exponent β in the relevant parameter regime, thereby preserving the existence condition. This will be a partial revision as a full rigorous bound may require additional technical work beyond the current scope. revision: partial
-
Referee: [derivation of β and decay class] The spectral exponent β is stated to govern both the spread of time scales and the asymptotic decay class of f(ℓ). The manuscript does not clarify whether this dual role follows from an independent derivation of the decay class or is built into the definition of the coarse-grained process itself; a concrete check (e.g., an auxiliary calculation showing the decay exponent is not tautological in β) would strengthen the claim that β is the single controlling parameter.
Authors: The dual role of β is not tautological. In the coarse-grained process, β parameterizes the heavy-tailed distribution of the time-scale fluctuations. The spread of time scales follows directly from this distribution. The asymptotic decay class of the influence envelope f(ℓ) is then obtained by integrating the contributions from the stationary distribution of time scales, yielding a power-law decay whose exponent is a function of β. This calculation is derived separately from the definition of the process. We will include an auxiliary calculation in the appendix of the revised manuscript that explicitly derives the decay exponent in terms of β, demonstrating its independent emergence. revision: yes
Circularity Check
Derivation from coarse-grained stochastic process is self-contained with no load-bearing self-definition or self-citation
full rationale
The paper constructs a coarse-grained stochastic process to capture the competition between training-driven collapse toward short time scales and heavy-tailed fluctuations that sustain long scales, then derives the existence condition for the anti-collapsed regime and the governing role of the spectral exponent β directly from the properties of that process. No quoted step reduces the claimed result to a tautological redefinition of inputs, a fitted parameter renamed as prediction, or a self-citation chain; the abstract and description present the β relation as a derived consequence of the model rather than an input assumption. The requirement that architecture plus optimizer must support broad spectra is stated as an additional practical condition, not smuggled into the mathematical claim. This is the normal case of a model-based derivation that remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The coupling between state dynamics and parameter dynamics during SGD can be coarse-grained into a stochastic process whose statistics determine the decay class of f(ℓ).
Reference graph
Works this paper leans on
-
[1]
Applebaum.Lévy Processes and Stochastic Calculus
D. Applebaum.Lévy Processes and Stochastic Calculus. Cambridge Studies in Advanced Mathematics. Cambridge University Press, Cambridge, UK, 2nd edition, 2009. ISBN 9780511809781
2009
-
[2]
T. Asabuki and C. Clopath. Taming the chaos gently: a predictive alignment learning rule in recurrent neural networks.Nature Communications, 16(1):6784, 2025. doi: 10.1038/s41467-025-61309-9
-
[3]
Barsbey, M
M. Barsbey, M. Sefidgaran, M. A. Erdogdu, G. Richard, and U. Şimşekli. Heavy tails in SGD and compressibilityofoverparametrizedneuralnetworks. InProceedings of the 35th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 2021. Curran Associates Inc
2021
- [4]
-
[5]
N. Bertschinger and T. Natschläger. Real-time computation at the edge of chaos in recurrent neural networks.Neural Computation, 16(7):1413–1436, 2004. doi: 10.1162/089976604323057443
-
[6]
N. H. Bingham, C. M. Goldie, and J. L. Teugels.Regular Variation, volume 27 ofEncyclopedia of Math- ematics and Its Applications. Cambridge University Press, Cambridge, UK, 1989. ISBN 9780511721434
1989
-
[7]
T. Bonnaire, D. Ghio, K. Krishnamurthy, F. Mignacco, A. Yamamura, and G. Biroli. High-dimensional non-convex landscapes and gradient descent dynamics.Journal of Statistical Mechanics: Theory and Experiment, 2024(10):104004, Oct 2024. doi: 10.1088/1742-5468/ad2929
-
[8]
T. Can, K. Krishnamurthy, and D. J. Schwab. Gating creates slow modes and controls phase-space complexity in GRUs and LSTMs. InProceedings of The First Mathematical and Scientific Machine Learning Conference, volume 107, pages 476–511. PMLR, 2020
2020
-
[9]
P. Carr, H. Geman, D. B. Madan, and M. Yor. The fine structure of asset returns: An empirical investigation.The Journal of Business, 75(2):305–332, Apr 2002. doi: 10.1086/338705
-
[10]
A. Ceni, P. Ashwin, L. Livi, and C. Postlethwaite. The echo index and multistability in input-driven recurrent neural networks.Physica D: Nonlinear Phenomena, 412:132609, 2020. doi: 10.1016/j.physd. 2020.132609
-
[11]
Chemnitz and M
D. Chemnitz and M. Engel. Characterizing dynamical stability of stochastic gradient descent in over- parameterized learning.Journal of Machine Learning Research, 26(134):1–46, 2025
2025
-
[12]
M. Chen, J. Pennington, and S. S. Schoenholz. Dynamical isometry and a mean field theory of RNNs: Gating enables signal propagation in recurrent neural networks. InProceedings of the 35th International Conference on Machine Learning, pages 873–882, Stockholm, Sweden, 2018. PMLR
2018
-
[13]
K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, pages 1724– 1734, Doha, Qatar, 2014
2014
-
[14]
Cont and P
R. Cont and P. Tankov.Financial Modelling with Jump Processes. Chapman and Hall/CRC, Boca Raton, FL, USA, 2004. ISBN 9781584884132
2004
-
[15]
Şimşekli, L
U. Şimşekli, L. Sagun, and M. Gurbuzbalaban. A tail-index analysis of stochastic gradient noise in deep neural networks. InProceedings of the 36th International Conference on Machine Learning, pages 5827–5837, Long Beach, California, USA, 2019. PMLR. 59
2019
-
[16]
de Bruijn.Asymptotic Methods in Analysis
N. de Bruijn.Asymptotic Methods in Analysis. Dover Books on Mathematics. Dover Publications, Garden City, NY, USA, 2010. ISBN 9780486642215
2010
-
[17]
A. L. M. Dekkers, J. H. J. Einmahl, and L. De Haan. A Moment Estimator for the Index of an Extreme- Value Distribution.The Annals of Statistics, 17(4):1833–1855, 1989. doi: 10.1214/aos/1176347397
-
[18]
Durrett.Probability: Theory and Examples
R. Durrett.Probability: Theory and Examples. Cambridge Series in Statistical and Probabilistic Math- ematics. Cambridge University Press, Cambridge, UK, 5th edition, 2019. ISBN 9781108591034
2019
-
[19]
R. Engelken, F. Wolf, and L. F. Abbott. Lyapunov spectra of chaotic recurrent neural networks.Physical Review Research, 5(4):043044, 2023. doi: 10.1103/PhysRevResearch.5.043044
-
[20]
N. B. Erichson, S. H. Lim, and M. W. Mahoney. Gated recurrent neural networks with weighted time-delay feedback. InProceedings of the 28th International Conference on Artificial Intelligence and Statistics, volume 258, pages 3646–3654, Mai Khao, Thailand, 2025. PMLR
2025
-
[21]
Feller.An Introduction to Probability Theory and Its Applications
W. Feller.An Introduction to Probability Theory and Its Applications. Vol. II. John Wiley & Sons, New York, USA, 2nd edition, 1971. ISBN 9780471257097
1971
-
[22]
C. Gerbelot, E. Troiani, F. Mignacco, F. Krzakala, and L. Zdeborová. Rigorous dynamical mean-field theory for stochastic gradient descent methods.SIAM Journal on Mathematics of Data Science, 6(2): 400–427, 2024. doi: 10.1137/23M1594388
-
[23]
A. Gloter, D. Loukianova, and H. Mai. Jump filtering and efficient drift estimation for Lévy-driven SDEs.The Annals of Statistics, 46(4):1445–1480, 2018. doi: 10.1214/17-AOS1591
-
[24]
K. Greff, R. K. Srivastava, J. Koutnik, B. R. Steunebrink, and J. Schmidhuber. LSTM: A search space odyssey.IEEE Transactions on Neural Networks and Learning Systems, 28(10):2222–2232, 2017. doi: 10.1109/TNNLS.2016.2582924
-
[25]
Gürbüzbalaban, U
M. Gürbüzbalaban, U. Şimşekli, and L. Zhu. The heavy-tail phenomenon in SGD. InProceedings of the 38th International Conference on Machine Learning, volume 139, pages 3964–3975. PMLR, 2021
2021
-
[26]
J. Hesse and T. Gross. Self-organized criticality as a fundamental property of neural systems.Frontiers in Systems Neuroscience, 8:166, 2014. doi: 10.3389/fnsys.2014.00166
-
[27]
B. M. Hill. A simple general approach to inference about the tail of a distribution.The Annals of Statistics, 3(5):1163–1174, 1975. doi: 10.1214/aos/1176343247
-
[28]
Hodgkinson and M
L. Hodgkinson and M. W. Mahoney. Multiplicative noise and heavy tails in stochastic optimization. In Proceedings of the 38th International Conference on Machine Learning, volume 139, pages 4262–4274. PMLR, 2021
2021
-
[29]
P. Imkeller and I. Pavlyukevich. First exit times of SDEs driven by stable Lévy processes.Stochastic Processes and their Applications, 116(4):611–642, 2006. doi: 10.1016/j.spa.2005.11.006
-
[30]
J. Kadmon and H. Sompolinsky. Transition to chaos in random neuronal networks.Physical Review X, 5:041030, Nov 2015. doi: 10.1103/PhysRevX.5.041030
-
[31]
T. D. Kim, T. Can, and K. Krishnamurthy. Trainability, expressivity and interpretability in gated neural ODEs. InProceedings of the 40th International Conference on Machine Learning, Honolulu, Hawaii, USA, 2023. PMLR
2023
-
[32]
K. Krishnamurthy, T. Can, and D. J. Schwab. Theory of gating in recurrent neural networks.Physical Review X, 12:011011, Jan 2022. doi: 10.1103/PhysRevX.12.011011
-
[33]
U. Küchler and S. Tappe. Tempered stable distributions and processes.Stochastic Processes and their Applications, 123(12):4256–4293, 2013. doi: 10.1016/j.spa.2013.06.012. 60
-
[34]
Q. Li, C. Tai, and W. E. Stochastic modified equations and adaptive stochastic gradient algorithms. InProceedings of the 34th International Conference on Machine Learning, volume 70, pages 2101–2110, Sydney, Australia, 2017. PMLR
2017
-
[35]
L. Livi. Time-scale coupling between states and parameters in recurrent neural networks.arXiv preprint arXiv:2508.12121, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [36]
-
[37]
L. Livi, F. M. Bianchi, and C. Alippi. Determination of the edge of criticality in echo state networks through Fisher information maximization.IEEE Transactions on Neural Networks and Learning Sys- tems, 29(3):706–717, 2018. doi: 10.1109/TNNLS.2016.2644268
-
[38]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.International Conference on Learning Representations, 2019
2019
-
[39]
Mandt, M
S. Mandt, M. D. Hoffman, and D. M. Blei. Stochastic gradient descent as approximate bayesian infer- ence.Journal of Machine Learning Research, 18(134):1–35, 2017
2017
-
[40]
C. H. Martin and M. W. Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165): 1–73, 2021
2021
-
[41]
Massar and S
M. Massar and S. Massar. Mean-field theory of echo state networks.Physical Review E, 87(4):042809,
-
[42]
doi: 10.1103/PhysRevE.87.042809
-
[43]
F. Mastrogiuseppe and S. Ostojic. Linking connectivity, dynamics, and computations in low-rank recurrent neural networks.Neuron, 99(3):609–623, 2018. doi: 10.1016/j.neuron.2018.07.003
-
[44]
M. M. Meerschaert, Y. Zhang, and B. Baeumer. Tempered anomalous diffusion in heterogeneous sys- tems.Geophysical Research Letters, 35(17):L17403, 2008. doi: 10.1029/2008GL034899
-
[45]
S. Mei, A. Montanari, and P.-M. Nguyen. A mean field view of the landscape of two-layer neural networks.Proceedings of the National Academy of Sciences, 115(33):E7665–E7671, 2018. doi: 10.1073/ pnas.1806579115
2018
-
[46]
P.-M. Nguyen and H. T. Pham. A rigorous framework for the mean field limit of multilayer neural networks.Mathematical Statistics and Learning, 6(3):201–357, 2023. doi: 10.4171/MSL/42
-
[47]
T. H. Nguyen, U. Şimşekli, M. Gürbüzbalaban, and G. Richard. First exit time analysis of stochastic gradient descent under heavy-tailed gradient noise. InProceedings of the 33rd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 2019. Curran Associates Inc
2019
- [48]
-
[49]
Pascanu, T
R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, volume 28, pages 1310–1318, Atlanta, Georgia, USA, 2013. PMLR
2013
-
[50]
Poole, S
B. Poole, S. Lahiri, M. Raghu, J. Sohl-Dickstein, and S. Ganguli. Exponential expressivity in deep neural networks through transient chaos. InProceedings of the 30th Advances in Neural Information Processing Systems, volume 29, Barcelona, Spain, 2016. Curran Associates, Inc
2016
-
[51]
Rosiński
J. Rosiński. Tempering stable processes.Stochastic Processes and their Applications, 117(6):677–707,
-
[52]
doi: 10.1016/j.spa.2006.10.003. 61
-
[53]
S. Ruder. An overview of gradient descent optimization algorithms.arXiv preprint arXiv:1609.04747, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[54]
Sato.Lévy Processes and Infinitely Divisible Distributions, volume 68 ofCambridge Studies in Advanced Mathematics
K. Sato.Lévy Processes and Infinitely Divisible Distributions, volume 68 ofCambridge Studies in Advanced Mathematics. Cambridge University Press, Cambridge, UK, 1999. ISBN 978-1107656499
1999
-
[55]
R. L. Schilling. An introduction to Lévy and feller processes. advanced courses in mathematics-CRM Barcelona 2014.arXiv preprint arXiv:1603.00251, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[56]
Sieber, C
J. Sieber, C. Amo Alonso, A. Didier, M. N. Zeilinger, and A. Orvieto. Understanding the differences in foundation models: Attention, state space models, and recurrent neural networks. InAdvances in Neural Information Processing Systems, volume 37, Vancouver, BC, Canada, 2024
2024
-
[57]
There Will Be a Scientific Theory of Deep Learning
J. Simon, D. Kunin, A. Atanasov, E. Boix-Adserà, B. Bordelon, J. Cohen, N. Ghosh, F. Guth, A. Jacot, M. Kamb, D. Karkada, E. J. Michaud, B. Ottlik, and J. Turnbull. There will be a scientific theory of deep learning.arXiv preprint arXiv:2604.21691, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Meanfieldanalysisofdeepneuralnetworks.Mathematics of Operations Research, 47(1):120–152, 2022
J.SirignanoandK.Spiliopoulos. Meanfieldanalysisofdeepneuralnetworks.Mathematics of Operations Research, 47(1):120–152, 2022. doi: 10.1287/moor.2020.1118
-
[59]
S. L. Smith, B. Dherin, D. G. T. Barrett, and S. De. On the origin of implicit regularization in stochastic gradient descent. InInternational Conference on Learning Representations, 2021
2021
-
[60]
A. Stanislavsky, K. Weron, and A. Weron. Diffusion and relaxation controlled by temperedα-stable processes.Physical Review E, 78(5):051106, 2008. doi: 10.1103/PhysRevE.78.051106
-
[61]
D. Sussillo and O. Barak. Opening the black box: Low-dimensional dynamics in high-dimensional recurrent neural networks.Neural Computation, 25(3):626–649, 2013. doi: 10.1162/NECO_a_00409
-
[62]
Tallec and Y
C. Tallec and Y. Ollivier. Can recurrent neural networks warp time? InInternational Conference on Learning Representations, Vancouver, BC, Canada, 2018
2018
-
[63]
Cambridge University Press, Cambridge, UK, 2014
M.Viana.Lectures on Lyapunov Exponents, volume145ofCambridge Studies in Advanced Mathematics. Cambridge University Press, Cambridge, UK, 2014. ISBN 9781139976602
2014
-
[64]
Z. Xie, I. Sato, and M. Sugiyama. A diffusion theory for deep learning dynamics: Stochastic gradient descent exponentially favors flat minima. InInternational Conference on Learning Representations, 2021
2021
-
[65]
S. Yaida. Fluctuation-dissipation relations for stochastic gradient descent.arXiv preprint arXiv:1810.00004, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[66]
X.-Y. Zhang and C. Tang. Heavy-tailed update distributions arise from information-driven self- organization in nonequilibrium learning.Proceedings of the National Academy of Sciences, 122(51): e2523012122, 2025. doi: 10.1073/pnas.2523012122
-
[67]
L. Ziyin, H. Li, and M. Ueda. Noise balance and stationary distribution of stochastic gradient descent. Physical Review E, 111(6):065303, 2025. doi: 10.1103/PhysRevE.111.065303
-
[68]
Zucchet and A
N. Zucchet and A. Orvieto. Recurrent neural networks: vanishing and exploding gradients are not the end of the story. InProceedings of the 38th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 2024. Curran Associates Inc. 62
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.