Nothing from Something: Can a Language Model Discover 0?
Pith reviewed 2026-06-27 03:19 UTC · model grok-4.3
The pith
Language models of GPT-2 size cannot discover the concept of zero without explicit training examples, though language pretraining cuts the number needed by about 50%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
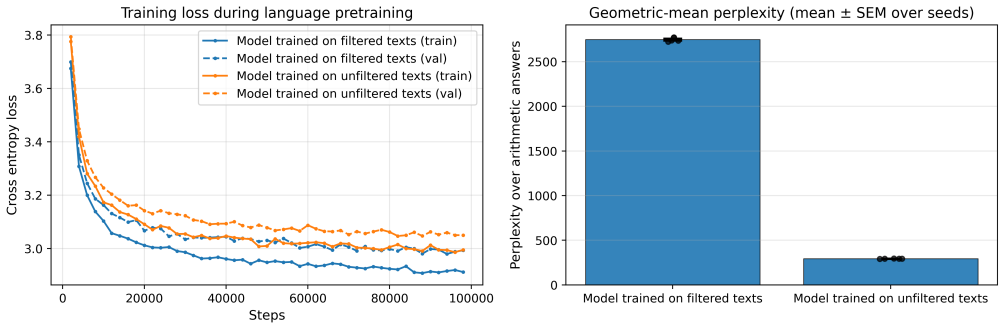
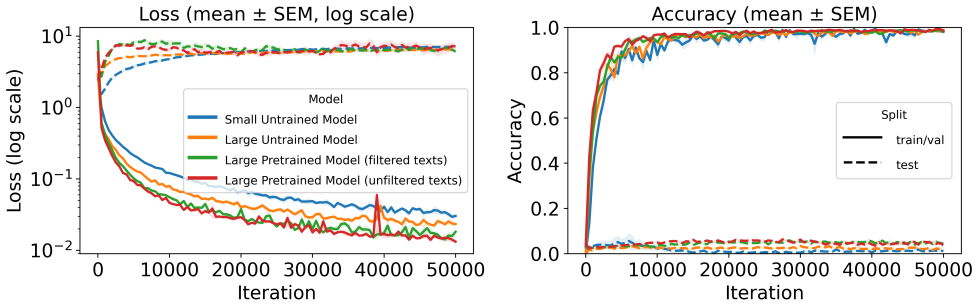
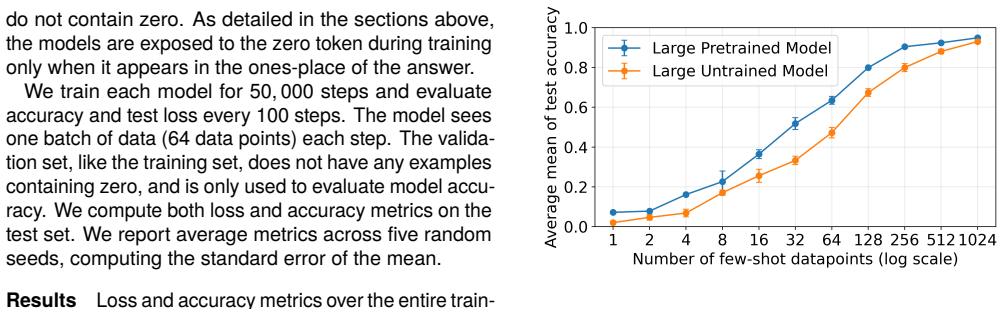
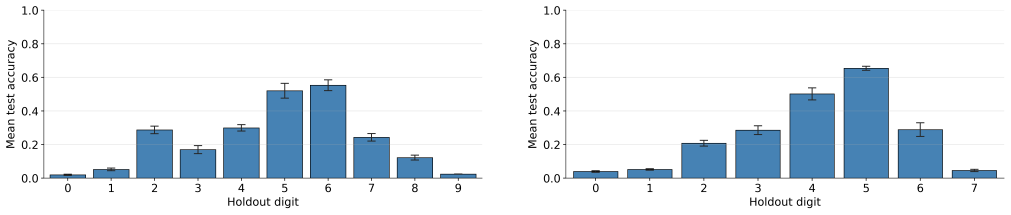
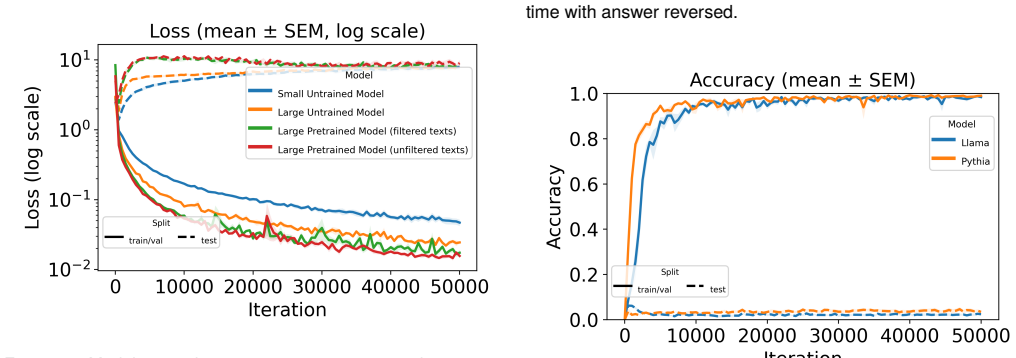
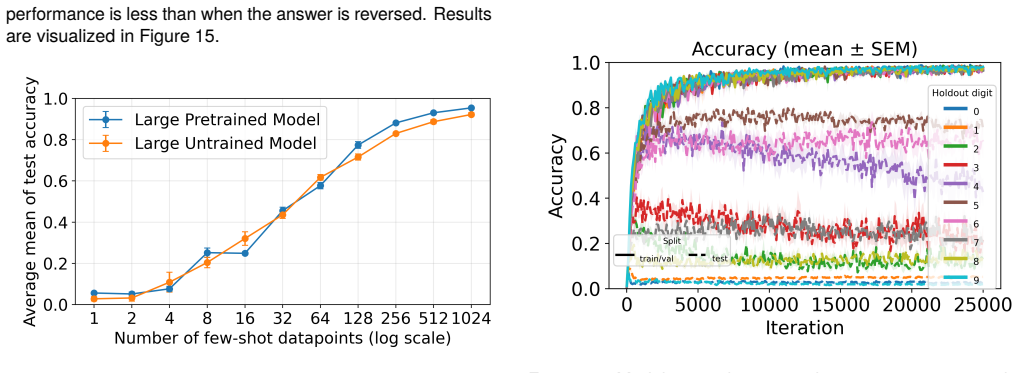
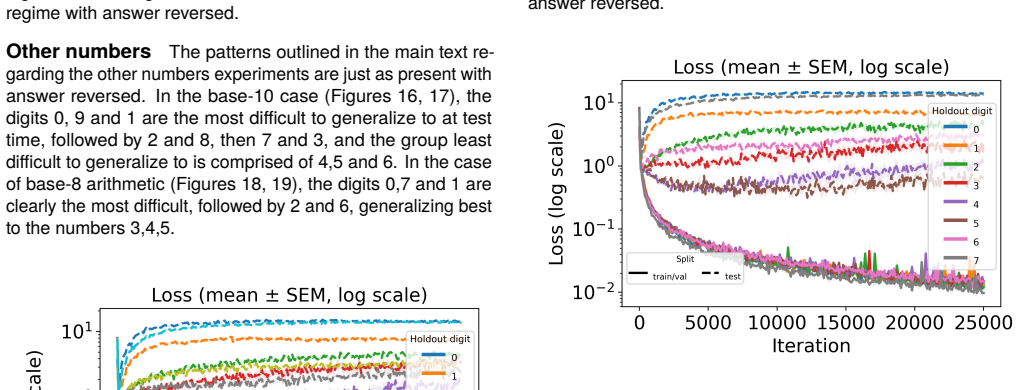
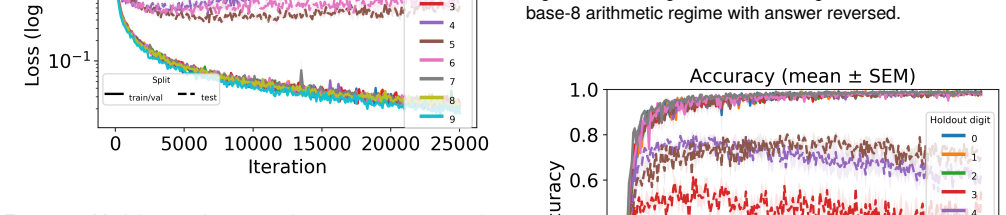
Language models of a GPT-2 size are unable to perform this generalization at test time regardless of language pretraining, but models can improve substantially after training on tens or hundreds of examples of zero. Additionally, language pretraining reduces the number of required examples by approximately 50%, showing that language abilities can scaffold mathematical discovery in neural models.
What carries the argument
The zero-generalization task in simple arithmetic, which measures whether models can extend their training on non-zero numbers to include the new concept of zero.
If this is right
- AI systems may need direct exposure to zero examples to acquire basic mathematical concepts.
- Language pretraining can reduce the data required for learning new arithmetic structures by half.
- Spontaneous mathematical discovery of zero does not occur in these models from non-zero training alone.
- Mathematical generalization in neural networks depends more on explicit examples than on pretraining alone.
Where Pith is reading between the lines
- Larger models or different objectives might still fail to invent zero without targeted examples.
- This pattern could apply to other missing concepts like negative numbers or fractions.
- Historical human invention of zero might parallel the need for cultural or explicit introduction rather than pure inference.
Load-bearing premise
That failure to handle zero at test time without any zero examples proves an inability to discover the concept rather than a limit of the chosen training regime or task setup.
What would settle it
A GPT-2-size model that correctly answers arithmetic questions involving zero after training only on positive numbers or non-zero operations would falsify the main claim.
Figures

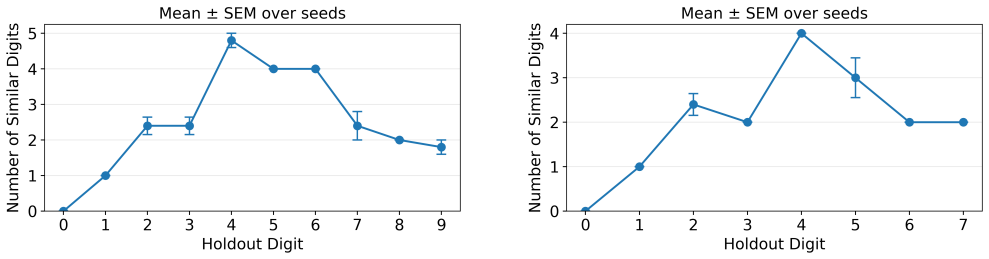

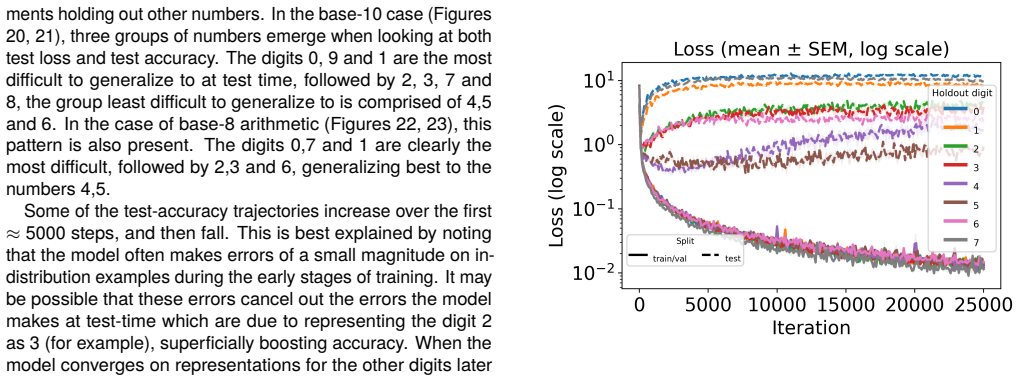
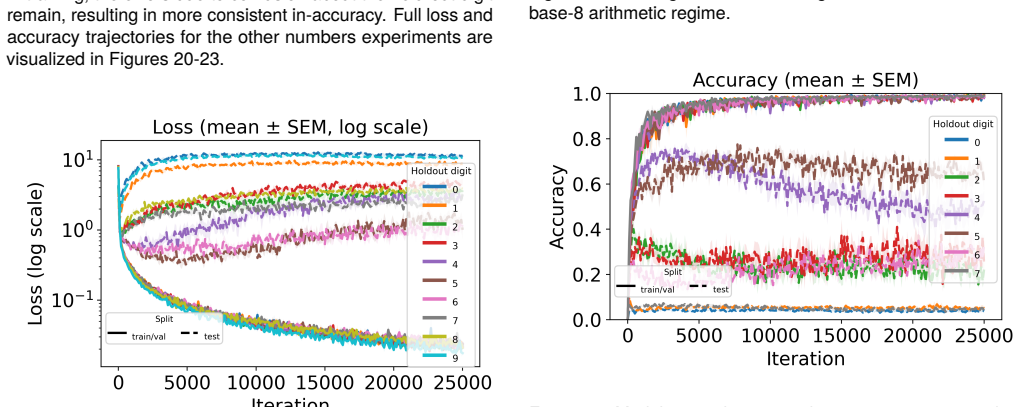
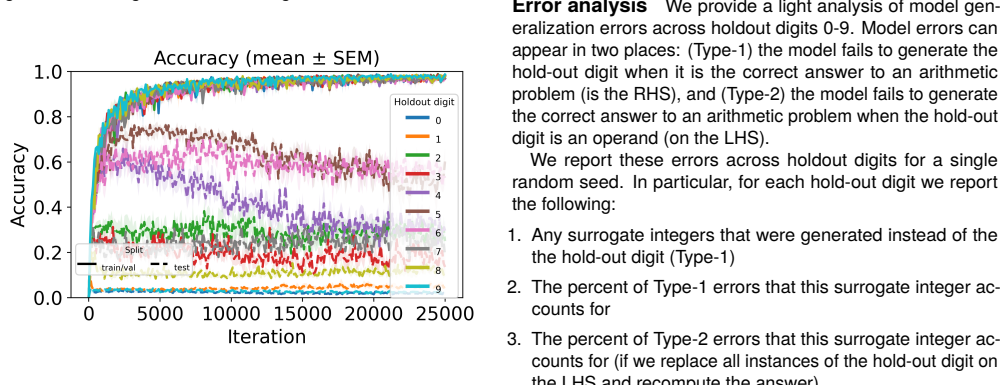
read the original abstract
AI systems based on artificial neural networks are being developed with aspirations of pushing the boundary of human mathematical knowledge. A key question for these systems is how much they can reach beyond their training data. Mathematical discovery requires a strong form of out of distribution generalization; the ability to hypothesize genuinely new - and potentially logically more powerful - mathematical structures. It has been hypothesized that language abilities support such generalizations in human cognition. In this work, we use simple arithmetic as a case study for examining how modern AI models could expand their mathematical horizons, evaluating whether these models can independently discover the concept of "zero". We show that (1) language models of a GPT-2 size are unable to perform this generalization at test time regardless of language pretraining, but (2) models can improve substantially after training on tens or hundreds of examples of zero. Additionally, we find that language pretraining reduces the number of required examples by approximately $50\%$, showing that language abilities can scaffold mathematical discovery in neural models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper uses simple arithmetic tasks as a case study to test whether GPT-2-scale language models can discover the concept of zero via out-of-distribution generalization. It claims that (1) such models fail to perform zero generalization at test time regardless of language pretraining, (2) they improve substantially after supervised training on tens or hundreds of zero examples, and (3) language pretraining reduces the number of required examples by approximately 50%.
Significance. If the empirical results hold under rigorous controls, the finding that language pretraining can scaffold acquisition of a new mathematical primitive (zero) by halving the number of examples needed would be a concrete, falsifiable contribution to understanding how pretraining affects mathematical discovery in neural models. The work also supplies a minimal testbed for probing whether models can hypothesize logically stronger structures beyond their training distribution.
major comments (2)
- [Abstract / §3] Abstract and §3 (experimental setup): the claim that test-time failure demonstrates an inability to 'discover' zero is load-bearing but rests on the untested assumption that the chosen arithmetic task and prompting regime would elicit the concept if an internal representation existed. No negative controls are described that hold all other factors fixed while varying only the presence/absence of zero, leaving open the possibility that the observed failure reflects task formulation or elicitation limits rather than conceptual absence.
- [Abstract / Results] Abstract and results section: no details are supplied on experimental design, data splits, number of runs, statistical tests, or variance across random seeds. Without these, it is impossible to assess whether the reported improvement after 'tens or hundreds of examples' and the 50% reduction due to pretraining are robust or could be artifacts of particular splits or prompting choices.
minor comments (1)
- [Abstract] Abstract: the phrase 'language pretraining reduces the number of required examples by approximately 50%' should be accompanied by the precise baseline (e.g., from-scratch vs. pretrained) and the exact metric (examples to reach a given accuracy threshold) used to compute the reduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will incorporate revisions to improve experimental rigor and reporting.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (experimental setup): the claim that test-time failure demonstrates an inability to 'discover' zero is load-bearing but rests on the untested assumption that the chosen arithmetic task and prompting regime would elicit the concept if an internal representation existed. No negative controls are described that hold all other factors fixed while varying only the presence/absence of zero, leaving open the possibility that the observed failure reflects task formulation or elicitation limits rather than conceptual absence.
Authors: We agree that explicit negative controls would strengthen the causal interpretation of the test-time failure. In the revised manuscript we will add a new subsection in §3 describing negative-control experiments that hold the arithmetic task, prompting format, and model architecture fixed while systematically varying only the presence or absence of zero in the training distribution. These controls will be reported alongside the original results. revision: yes
-
Referee: [Abstract / Results] Abstract and results section: no details are supplied on experimental design, data splits, number of runs, statistical tests, or variance across random seeds. Without these, it is impossible to assess whether the reported improvement after 'tens or hundreds of examples' and the 50% reduction due to pretraining are robust or could be artifacts of particular splits or prompting choices.
Authors: We acknowledge that the original submission omitted these methodological details. The revised version will include a new 'Experimental Details' subsection that specifies: (i) the exact train/validation/test splits and how zero examples were held out, (ii) the number of independent runs (five random seeds), (iii) the statistical tests used (paired t-tests with reported p-values), and (iv) all results reported as means ± standard deviation across seeds. These additions will allow readers to evaluate robustness directly. revision: yes
Circularity Check
No circularity: empirical study with no derivation chain
full rationale
The paper is an empirical investigation of language model generalization on arithmetic tasks involving zero. It reports experimental results on GPT-2 scale models with and without pretraining, showing failure at test time without examples and improvement after fine-tuning. No mathematical derivation, equations, or theoretical chain is presented that could reduce to its inputs by construction. Claims rest on observable training outcomes and data splits, which are externally falsifiable via replication. Self-citations, if present, are not load-bearing for any central premise that would create circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Some Thoughts on Automation and Mathematical Research , author=
-
[2]
Language Models are Unsupervised Multitask Learners , author=
-
[3]
The Guardian , author =
Nirvana by. The Guardian , author =. 2013 , keywords =
2013
-
[4]
Children's understanding of counting , volume =. Cognition , author =. 1990 , pages =. doi:10.1016/0010-0277(90)90003-3 , abstract =
-
[5]
Psychological Review , author =
The logical primitives of thought:. Psychological Review , author =. 2016 , pmid =. doi:10.1037/a0039980 , abstract =
-
[6]
Bootstrapping & the origin of concepts , volume =. Daedalus , author =. 2004 , pages =. doi:10.1162/001152604772746701 , language =
-
[7]
Nature625, 476–482 (2024).https://doi.org/ 10.1038/s41586-023-06747-5
Solving olympiad geometry without human demonstrations , volume =. Nature , author =. 2024 , keywords =. doi:10.1038/s41586-023-06747-5 , abstract =
-
[8]
Zero: the biography of a dangerous idea , isbn =
-
[9]
Language and learning: the debate between
-
[10]
Structuralism , isbn =
Piaget, Jean , editor =. Structuralism , isbn =
-
[11]
The origin of concepts , isbn =
Carey, Susan , year =. The origin of concepts , isbn =
-
[12]
The nothing that is: a natural history of zero , isbn =
Kaplan, Robert , year =. The nothing that is: a natural history of zero , isbn =
-
[13]
Spelke, Elizabeth S. , year =. What makes us smart?. Language in mind:. doi:10.7551/mitpress/4117.001.0001 , keywords =
-
[14]
doi: 10.1007/978-3-030-79876-5_37
The Lean 4 Theorem Prover and Programming Language , author =. Automated Deduction – CADE 28: 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021, Proceedings , pages =. 2021 , isbn =. doi:10.1007/978-3-030-79876-5_37 , abstract =
-
[15]
Nye, Maxwell and Andreassen, Anders Johan and Gur-Ari, Guy and Michalewski, Henryk and Austin, Jacob and Bieber, David and Dohan, David and Lewkowycz, Aitor and Bosma, Maarten and Luan, David and Sutton, Charles and Odena, Augustus , month = nov, year =. Show. doi:10.48550/arXiv.2112.00114 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.00114
-
[16]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed and Le, Quoc and Zhou, Denny , month = jan, year =. Chain-of-. doi:10.48550/arXiv.2201.11903 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.11903
-
[17]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2005
-
[18]
Scaling Laws for Neural Language Models
Kaplan, Jared and McCandlish, Sam and Henighan, Tom and Brown, Tom B. and Chess, Benjamin and Child, Rewon and Gray, Scott and Radford, Alec and Wu, Jeffrey and Amodei, Dario , month = jan, year =. Scaling. doi:10.48550/arXiv.2001.08361 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[19]
2025 , eprint=
From System 1 to System 2: A Survey of Reasoning Large Language Models , author=. 2025 , eprint=
2025
-
[20]
doi:10.48550/arXiv.2507.03876 , abstract =
Loo, Alyssa and Pavlick, Ellie and Feiman, Roman , month = jul, year =. doi:10.48550/arXiv.2507.03876 , abstract =
-
[21]
Learning to reason with
-
[22]
Google DeepMind , author =
Advanced version of. Google DeepMind , author =
-
[23]
The story of
Tao, Terry , abstract =. The story of. What's new , month = dec, year =
-
[24]
Lin, Yong and Tang, Shange and Lyu, Bohan and Yang, Ziran and Chung, Jui-Hui and Zhao, Haoyu and Jiang, Lai and Geng, Yihan and Ge, Jiawei and Sun, Jingruo and Wu, Jiayun and Gesi, Jiri and Lu, Ximing and Acuna, David and Yang, Kaiyu and Lin, Hongzhou and Choi, Yejin and Chen, Danqi and Arora, Sanjeev and Jin, Chi , month = aug, year =. Goedel-. doi:10.48...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.03613
-
[25]
Ren, Z. Z. and Shao, Zhihong and Song, Junxiao and Xin, Huajian and Wang, Haocheng and Zhao, Wanjia and Zhang, Liyue and Fu, Zhe and Zhu, Qihao and Yang, Dejian and Wu, Z. F. and Gou, Zhibin and Ma, Shirong and Tang, Hongxuan and Liu, Yuxuan and Gao, Wenjun and Guo, Daya and Ruan, Chong , month = jul, year =. doi:10.48550/arXiv.2504.21801 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.21801
-
[26]
doi:10.48550/arXiv.2402.03822 , abstract =
Shen, Si and Shen, Peijun and Zhu, Danhao , month = feb, year =. doi:10.48550/arXiv.2402.03822 , abstract =
-
[27]
2018 , eprint=
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks , author=. 2018 , eprint=
2018
-
[28]
Frieder, Simon and Pinchetti, Luca and Chevalier, Alexis and Griffiths, Ryan-Rhys and Salvatori, Tommaso and Lukasiewicz, Thomas and Petersen, Philipp Christian and Berner, Julius , month = jul, year =. Mathematical. doi:10.48550/arXiv.2301.13867 , abstract =
-
[29]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , month = nov, year =. Measuring. doi:10.48550/arXiv.2103.03874 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.03874
-
[30]
Llemma: An Open Language Model For Mathematics
Azerbayev, Zhangir and Schoelkopf, Hailey and Paster, Keiran and Santos, Marco Dos and McAleer, Stephen and Jiang, Albert Q. and Deng, Jia and Biderman, Stella and Welleck, Sean , month = mar, year =. Llemma:. doi:10.48550/arXiv.2310.10631 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.10631
-
[31]
Ayers, Dragomir Radev, and Jeremy Avigad
Azerbayev, Zhangir and Piotrowski, Bartosz and Schoelkopf, Hailey and Ayers, Edward W. and Radev, Dragomir and Avigad, Jeremy , month = feb, year =. doi:10.48550/arXiv.2302.12433 , abstract =
-
[32]
Lightman, Hunter and Kosaraju, Vineet and Burda, Yura and Edwards, Harri and Baker, Bowen and Lee, Teddy and Leike, Jan and Schulman, John and Sutskever, Ilya and Cobbe, Karl , month = may, year =. Let's. doi:10.48550/arXiv.2305.20050 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.20050
-
[33]
Scientific American , author =
Ancient. Scientific American , author =
-
[34]
OpenWebText Corpus , author=
-
[35]
Scientific American , author =
-
[36]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[37]
2023 , eprint=
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling , author=. 2023 , eprint=
2023
-
[38]
Initializing
Hewitt, John , date =. Initializing
-
[39]
2020 , eprint=
The Pile: An 800GB Dataset of Diverse Text for Language Modeling , author=. 2020 , eprint=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.