An Exploratory Study on LLM-Generated Code and Comments in Code Repositories
Pith reviewed 2026-07-03 09:08 UTC · model grok-4.3
The pith
Detector-based analysis of active repositories from 2021 to 2025 finds that the share of code flagged as likely LLM-generated declined over time while comments stayed steady, with higher rates in company projects and minimal ties to labelle
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
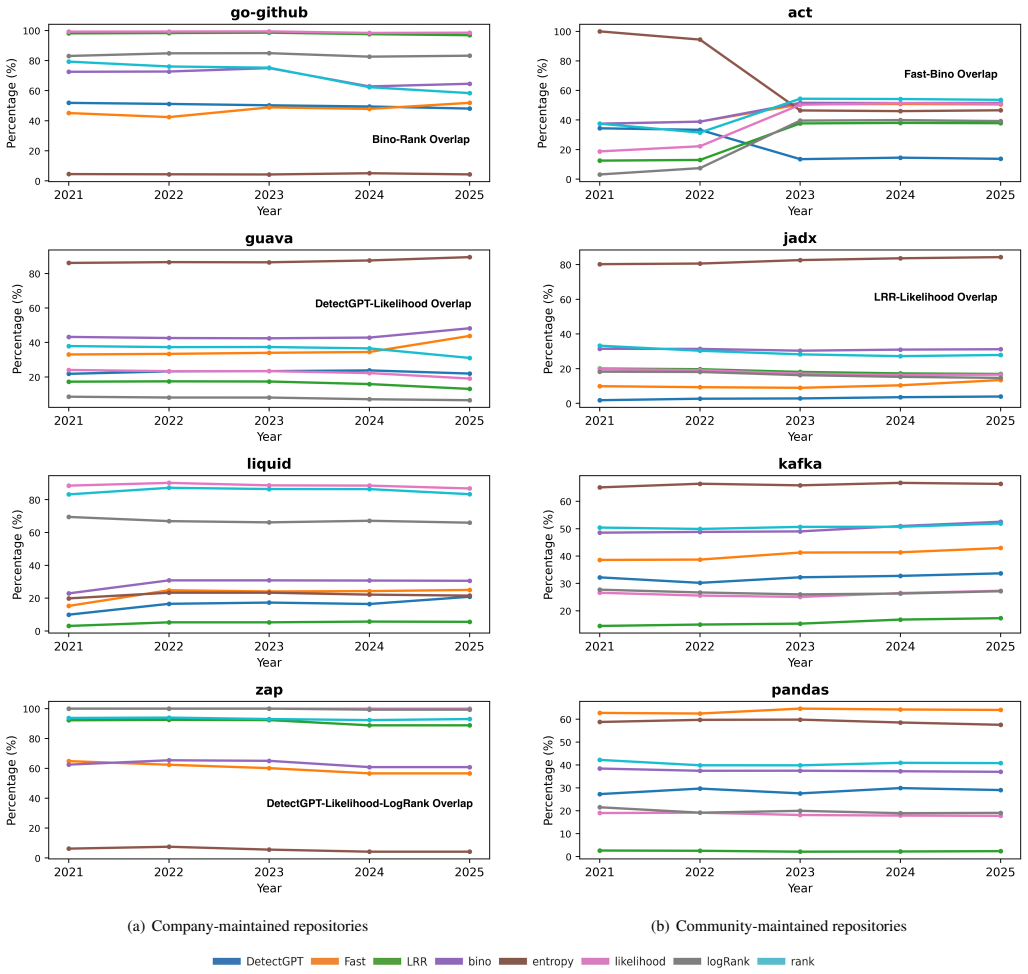
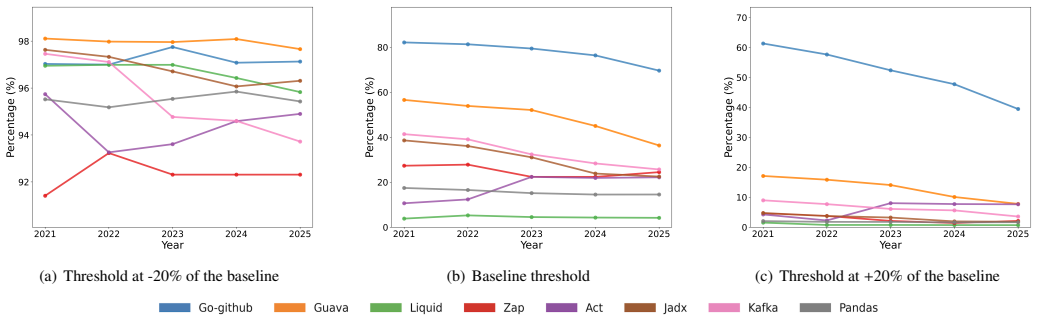
Proxy analysis with multiple LLM detectors on company- and community-maintained repositories shows detected LLM code decreasing over the 2021-2025 period and occurring frequently in test cases, while detected LLM comments remain relatively stable. Detected LLM code exhibits substantial intra-repository clones; detected LLM comments display a low proportion of grammatically correct sentences. Company repositories contain higher percentages of both detected categories, yet only a small percentage of human-labelled bugs are associated with the detected LLM code.
What carries the argument
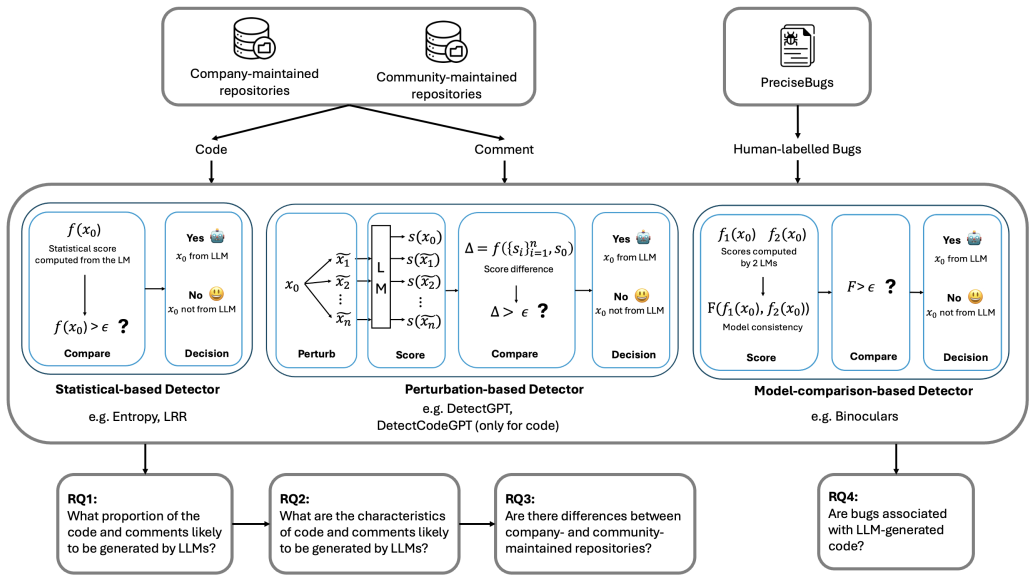
Detector-based proxy analysis that applies multiple tools to label likely LLM-generated code and comments inside active Git repositories.
If this is right
- Detected LLM code concentrates in test cases and shows high rates of duplication inside the same repository.
- Company-maintained repositories contain a larger share of detected LLM code and comments than community ones.
- Only a small fraction of human-labelled bugs link to code flagged by the detectors as LLM-generated.
- Comments flagged as likely LLM-generated display lower grammatical correctness than expected.
Where Pith is reading between the lines
- Teams may be applying greater scrutiny to LLM output in core production files than in tests over time.
- Elevated clone rates suggest generated snippets are sometimes reused without heavy modification.
- The low bug association could be tested further by comparing detector flags against automated bug-finding tools on the same commits.
Load-bearing premise
The chosen LLM detectors serve as a sufficiently accurate and stable proxy for actual LLM-generated content, such that false positives or negatives and temporal drift in detector behavior do not materially distort the reported trends and comparisons.
What would settle it
A manual audit or developer survey on a sample of the same repositories that reveals actual generation logs or self-reported AI use contradicting the observed temporal decline, clone rates, or bug associations.
Figures
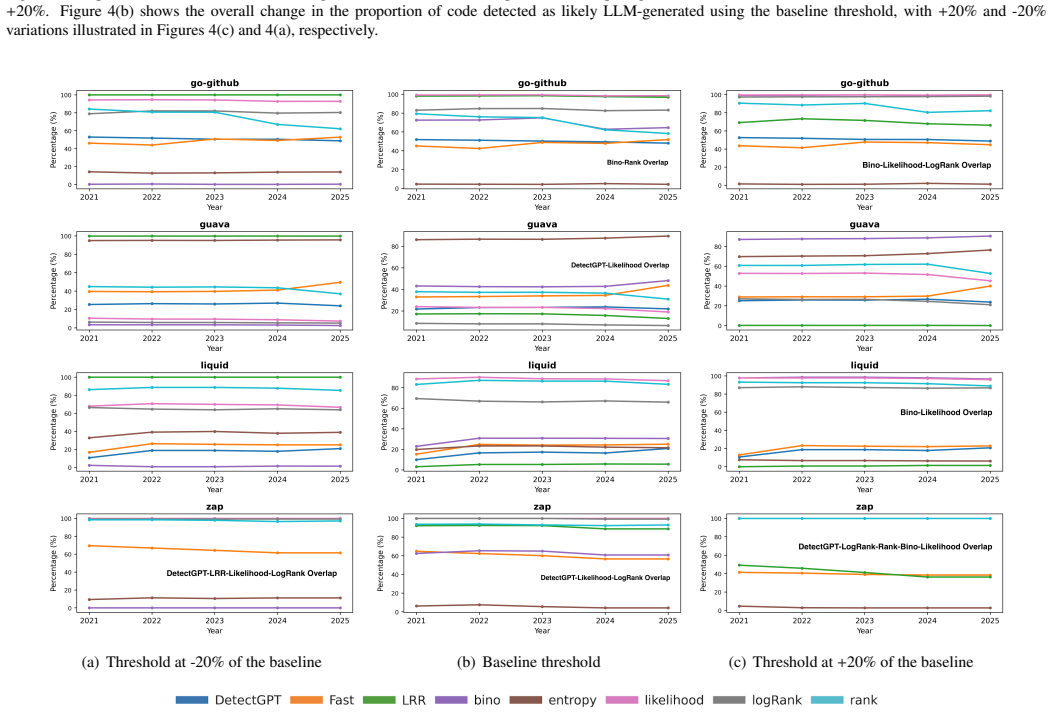
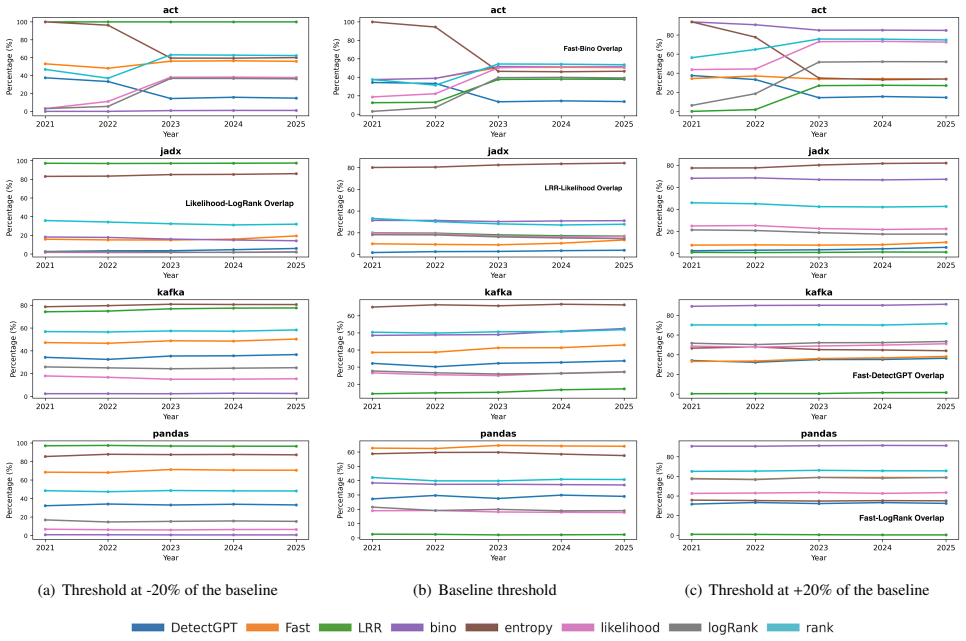
read the original abstract
The use of LLMs in software development has become increasingly widespread on tasks such as code generation and summarization. Reports from large technology companies showed that around 20% to 30% of their code are generated by LLMs. However, there remains skepticism about the practical usage of LLM-generated code and comments, such as concerns on more time for debugging the generated code and the unnaturalness of the generated comments. In this paper, we study the code and comments detected as likely to be generated by LLMs and their characteristics, the differences between company- and community-maintained repositories, and how likely bugs are associated with LLM-generated code. We conduct extensive experiments on active company- and community-maintained repositories from 2021 to 2025 using various tools and techniques that detect code and comments generated by LLMs. Based on our detector-based proxy analysis, the results suggest that code detected as likely to be generated by LLMs decreased over time and appeared frequently in test cases, while that of comments remains relatively stable. Proxy results further suggest that code detected as likely to be generated by LLMs shows substantial intra-repository code clones, whereas comments exhibit a relatively low proportion of grammatically correct sentences. In addition, the company-maintained repositories show a higher percentage of code and comments detected as likely to be generated by LLMs, and only a small percentage of the human-labelled bugs are detected as being likely associated with LLM-generated code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an exploratory empirical study of code and comments in active company- and community-maintained repositories spanning 2021–2025. Using multiple unspecified LLM detection tools as proxies, it reports that the fraction of code detected as LLM-generated declines over time and is frequent in test cases, exhibits substantial intra-repository cloning, and is higher in company-maintained repositories; detected LLM comments remain stable but show low grammatical correctness; and only a small percentage of human-labeled bugs are associated with detected LLM code.
Significance. If the detector proxies prove reliable and temporally stable, the work supplies one of the first large-scale observational datasets on LLM adoption patterns across real repositories, including company vs. community differences and clone/bug associations. The purely empirical design offers no parameter-free derivations or falsifiable predictions, but the scale of the repository sample could serve as a useful baseline for subsequent validation studies.
major comments (1)
- [Methodology] Methodology / detector section: No calibration, precision, recall, or inter-annotator agreement figures are provided for the LLM detectors on ground-truth data drawn from the studied repositories. Without such validation, all central trends (temporal decline in detected code, company vs. community differences, clone rates, bug associations) rest on an untested assumption that detector outputs remain stable proxies across 2021–2025; known drift in detector behavior could fully explain the reported patterns.
minor comments (1)
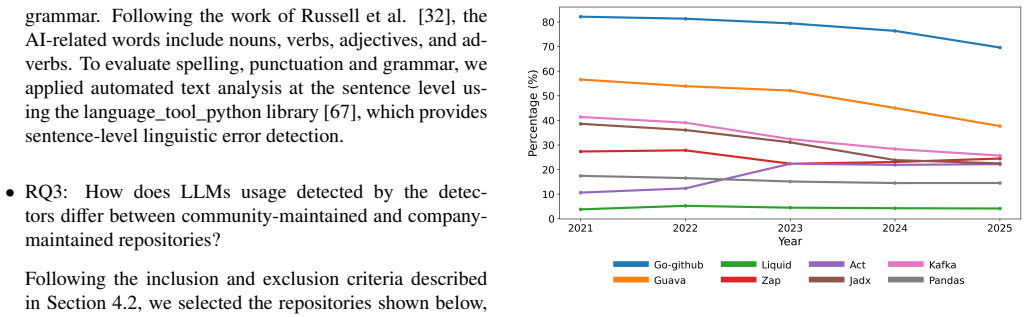
- [Abstract] Abstract: the phrase 'various tools and techniques' is repeated without naming the specific detectors or citing their original papers; this should be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting this important methodological point. The study is exploratory and uses detector outputs strictly as proxies; we address the concern directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Methodology / detector section: No calibration, precision, recall, or inter-annotator agreement figures are provided for the LLM detectors on ground-truth data drawn from the studied repositories. Without such validation, all central trends (temporal decline in detected code, company vs. community differences, clone rates, bug associations) rest on an untested assumption that detector outputs remain stable proxies across 2021–2025; known drift in detector behavior could fully explain the reported patterns.
Authors: We agree that explicit validation on repository-specific ground truth would be ideal. However, constructing such ground truth at scale is not possible: determining whether a given commit was authored with LLM assistance requires internal developer logs that are unavailable for the studied public repositories. The detectors we employ are established tools from the literature, and we will expand the methodology section to report the performance figures published by their authors, cite the specific detector versions and configurations used, and add a dedicated limitations subsection that explicitly discusses the proxy nature of the analysis, the risk of temporal drift, and the consequent exploratory character of all reported trends. These changes will make the evidential basis of the claims transparent without overstating certainty. revision: partial
Circularity Check
No significant circularity; purely empirical observational study
full rationale
The paper conducts an exploratory empirical analysis of code and comments in repositories using external LLM detection tools as proxies. No mathematical derivations, first-principles predictions, fitted parameters, or self-referential definitions appear in the text. All reported trends (temporal changes, clone rates, company vs. community differences) are direct outputs of the applied detectors on the collected data, with no step reducing by construction to a quantity defined inside the paper. Self-citations, if present, are not load-bearing for any central claim. The study is self-contained against external detector benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM detectors provide a valid proxy for identifying LLM-generated code and comments
Reference graph
Works this paper leans on
-
[1]
A Survey of Large Language Models
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Min, B. Zhang, J. Zhang, Z. Donget al., “A survey of large language models,”arXiv preprint arXiv:2303.18223, vol. 1, no. 2, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Examining the use and impact of an ai code assistant on developer productivity and experience in the enterprise,
J. D. Weisz, S. V . Kumar, M. Muller, K.-E. Browne, A. Goldberg, K. E. Heintze, and S. Bajpai, “Examining the use and impact of an ai code assistant on developer productivity and experience in the enterprise,” inProceed- ings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2025, pp. 1–13
2025
-
[3]
An empirical study on the usage of transformer models for code completion,
M. Ciniselli, N. Cooper, L. Pascarella, A. Mastropaolo, E. Aghajani, D. Poshyvanyk, M. Di Penta, and G. Bavota, “An empirical study on the usage of transformer models for code completion,”IEEE Transactions on Software En- gineering, vol. 48, no. 12, pp. 4818–4837, 2021
2021
-
[4]
Few-shot training llms for project-specific code-summarization,
T. Ahmed and P. Devanbu, “Few-shot training llms for project-specific code-summarization,” inProceedings of the 37th IEEE/ACM international conference on auto- mated software engineering, 2022, pp. 1–5
2022
-
[5]
A Survey on Large Language Models for Code Generation
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A sur- vey on large language models for code generation,”arXiv preprint arXiv:2406.00515, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Execution-based code generation using deep reinforce- ment learning,
P. Shojaee, A. Jain, S. Tipirneni, and C. K. Reddy, “Execution-based code generation using deep reinforce- ment learning,”arXiv preprint arXiv:2301.13816, 2023
-
[7]
Source code summariza- tion in the era of large language models,
W. Sun, Y . Miao, Y . Li, H. Zhang, C. Fang, Y . Liu, G. Deng, Y . Liu, and Z. Chen, “Source code summariza- tion in the era of large language models,”arXiv preprint arXiv:2407.07959, 2024. 17
-
[8]
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
S. Lu, D. Guo, S. Ren, J. Huang, A. Svyatkovskiy, A. Blanco, C. Clement, D. Drain, D. Jiang, D. Tanget al., “Codexglue: A machine learning benchmark dataset for code understanding and generation,”arXiv preprint arXiv:2102.04664, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Jetbrains developer ecosystem survey,
“Jetbrains developer ecosystem survey,” 2023. [Online]. Available: https://www.jetbrains.com/lp/ devecosystem-2023/ai/
2023
-
[10]
Google ceo says more than a quarter of the company’s new code is created by ai,
“Google ceo says more than a quarter of the company’s new code is created by ai,” 2024. [Online]. Available: https://news.ycombinator.com/item?id=41991291
2024
-
[11]
Up to 30% of microsoft’s code is now written by ai: Ceo satya nadella,
“Up to 30% of microsoft’s code is now written by ai: Ceo satya nadella,” 2025. [Online]. Available: https://shorturl.at/be0vn
2025
-
[12]
Dora report,
Google, “Dora report,” 2025. [Online]. Available: https://cloud.google.com/blog/products/ ai-machine-learning/announcing-the-2025-dora-report
2025
-
[13]
Asleep at the keyboard? assessing the security of github copilot’s code contributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? assessing the security of github copilot’s code contributions,”Commun. ACM, vol. 68, no. 2, p. 96–105, Jan. 2025. [Online]. Available: https://doi.org/10.1145/3610721
-
[14]
Copilot hosted by github
“Copilot hosted by github.” [Online]. Avail- able: https://github.blog/news-insights/product-news/ introducing-github-copilot-ai-pair-programmer/
-
[15]
Copilot hosted by microsoft,
“Copilot hosted by microsoft,” 2025. [Online]. Available: https://copilot.microsoft.com/
2025
-
[16]
A large-scale survey on the usability of ai programming assistants: Successes and challenges,
J. T. Liang, C. Yang, and B. A. Myers, “A large-scale survey on the usability of ai programming assistants: Successes and challenges,” inProceedings of the 46th IEEE/ACM international conference on software engi- neering, 2024, pp. 1–13
2024
-
[17]
Us- ing ai-based coding assistants in practice: State of affairs, perceptions, and ways forward,
A. Sergeyuk, Y . Golubev, T. Bryksin, and I. Ahmed, “Us- ing ai-based coding assistants in practice: State of affairs, perceptions, and ways forward,”Information and Soft- ware Technology, vol. 178, p. 107610, 2025
2025
-
[18]
Y . Shi, H. Zhang, C. Wan, and X. Gu,Between Lines of Code: Unraveling the Distinct Patterns of Machine and Human Programmers. IEEE Press, 2025, p. 1628–1639. [Online]. Available: https://doi.org/10.1109/ICSE55347. 2025.00005
-
[19]
Distinguishing ai- and human-generated code: A case study,
S. Bukhari, B. Tan, and L. De Carli, “Distinguishing ai- and human-generated code: A case study,” in Proceedings of the 2023 Workshop on Software Supply Chain Offensive Research and Ecosystem Defenses, ser. SCORED ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 17–25. [Online]. Available: https://doi.org/10.1145/3605770.3625215
-
[20]
GLTR: Statistical Detection and Visualization of Generated Text
S. Gehrmann, H. Strobelt, and A. M. Rush, “Gltr: Statis- tical detection and visualization of generated text,”arXiv preprint arXiv:1906.04043, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[21]
Detectgpt: Zero-shot machine-generated text detection using probability curvature,
E. Mitchell, Y . Lee, A. Khazatsky, C. D. Manning, and C. Finn, “Detectgpt: Zero-shot machine-generated text detection using probability curvature,” inInternational conference on machine learning. PMLR, 2023, pp. 24 950–24 962
2023
-
[22]
G. Bao, Y . Zhao, Z. Teng, L. Yang, and Y . Zhang, “Fast-detectgpt: Efficient zero-shot detection of machine- generated text via conditional probability curvature,” arXiv preprint arXiv:2310.05130, 2023
-
[23]
Spotting llms with binoculars: zero-shot detection of machine-generated text,
A. Hans, A. Schwarzschild, V . Cherepanova, H. Kazemi, A. Saha, M. Goldblum, J. Geiping, and T. Goldstein, “Spotting llms with binoculars: zero-shot detection of machine-generated text,” inProceedings of the 41st Inter- national Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[24]
Release Strategies and the Social Impacts of Language Models
I. Solaiman, M. Brundage, J. Clark, A. Askell, A. Herbert- V oss, J. Wu, A. Radford, G. Krueger, J. W. Kim, S. Kreps et al., “Release strategies and the social impacts of lan- guage models,”arXiv preprint arXiv:1908.09203, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[25]
Detecting fake con- tent with relative entropy scoring
T. Lavergne, T. Urvoy, and F. Yvon, “Detecting fake con- tent with relative entropy scoring.”Pan, vol. 8, no. 27-31, p. 4, 2008
2008
-
[26]
DetectLLM: Leveraging log rank information for zero-shot detec- tion of machine-generated text,
J. Su, T. Zhuo, D. Wang, and P. Nakov, “DetectLLM: Leveraging log rank information for zero-shot detec- tion of machine-generated text,” inFindings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Sin- gapore: Association for Computational Linguistics, Dec. 2023, pp. 12 395–12 412. [Online]. Available: h...
2023
-
[27]
Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow,
S. Black, G. Leo, P. Wang, C. Leahy, and S. Biderman, “Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow,”Zenodo, 2021
2021
-
[28]
Detectrl: Benchmarking llm-generated text de- tection in real-world scenarios,
J. Wu, R. Zhan, D. Wong, S. Yang, X. Yang, Y . Yuan, and L. Chao, “Detectrl: Benchmarking llm-generated text de- tection in real-world scenarios,”Advances in Neural Infor- mation Processing Systems, vol. 37, pp. 100 369–100 401, 2024
2024
-
[29]
J. Katzy, Y . Huang, G.-R. Panchu, M. Ziemlewski, P. Loizides, S. Vermeulen, A. van Deursen, and M. Izadi, “A qualitative investigation into llm-generated multilingual code comments and automatic evaluation metrics,” inProceedings of the 21st International Conference on Predictive Models and Data Analytics in Software Engineering, ser. PROMISE ’25. New Yo...
-
[30]
An empirical study of code clones from commercial ai code generators,
W. Wu, H. Hu, Z. Fan, Y . Qiao, Y . Huang, Y . Li, Z. Zheng, and M. Lyu, “An empirical study of code clones from commercial ai code generators,”Proceedings of the ACM on Software Engineering, vol. 2, no. FSE, pp. 2874–2896, 2025
2025
-
[31]
Gptclonebench: A comprehen- sive benchmark of semantic clones and cross-language clones using gpt-3 model and semanticclonebench,
A. I. Alam, P. R. Roy, F. Al-Omari, C. K. Roy, B. Roy, and K. A. Schneider, “Gptclonebench: A comprehen- sive benchmark of semantic clones and cross-language clones using gpt-3 model and semanticclonebench,” in 2023 IEEE International Conference on Software Main- tenance and Evolution (ICSME). IEEE, 2023, pp. 1–13
2023
-
[32]
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text,
J. Russell, M. Karpinska, and M. Iyyer, “People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Co...
2025
-
[33]
Available: https://aclanthology.org/2025
[Online]. Available: https://aclanthology.org/2025. acl-long.267/
2025
-
[34]
Y . He, Z. Chen, and C. Le Goues, “Precisebugcollector: Extensible, executable and precise bug-fix collection: So- lution for challenge 8: Automating precise data collection for code snippets with bugs, fixes, locations, and types,” in2023 38th IEEE/ACM International Conference on Au- tomated Software Engineering (ASE). IEEE, 2023, pp. 1899–1910
2023
-
[35]
Defects4j: A database of existing faults to enable controlled testing studies for java programs,
R. Just, D. Jalali, and M. D. Ernst, “Defects4j: A database of existing faults to enable controlled testing studies for java programs,” inProceedings of the 2014 international symposium on software testing and analysis, 2014, pp. 437–440
2014
-
[36]
Inferfix: End-to-end pro- gram repair with llms,
M. Jin, S. Shahriar, M. Tufano, X. Shi, S. Lu, N. Sun- daresan, and A. Svyatkovskiy, “Inferfix: End-to-end pro- gram repair with llms,” inProceedings of the 31st ACM joint european software engineering conference and sym- posium on the foundations of software engineering, 2023, pp. 1646–1656
2023
-
[37]
A survey on LLM-generated text detection: Necessity, methods, and future directions,
J. Wu, S. Yang, R. Zhan, Y . Yuan, L. S. Chao, and D. F. Wong, “A survey on LLM-generated text detection: Necessity, methods, and future directions,” Computational Linguistics, vol. 51, no. 1, pp. 275–338, Mar. 2025. [Online]. Available: https://aclanthology.org/ 2025.cl-1.8/
2025
-
[38]
Practices and challenges of using github copilot: An em- pirical study,
B. Zhang, P. Liang, X. Zhou, A. Ahmad, and M. Waseem, “Practices and challenges of using github copilot: An em- pirical study,”arXiv preprint arXiv:2303.08733, 2023
-
[39]
M. Jaworski and D. Piotrkowski, “Study of software developers’ experience using the github copilot tool in the software development process,”arXiv preprint arXiv:2301.04991, 2023
-
[40]
Measur- ing github copilot’s impact on productivity,
A. Ziegler, E. Kalliamvakou, X. A. Li, A. Rice, D. Rifkin, S. Simister, G. Sittampalam, and E. Aftandilian, “Measur- ing github copilot’s impact on productivity,”Communica- tions of the ACM, vol. 67, no. 3, pp. 54–63, 2024
2024
-
[41]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
S. Peng, E. Kalliamvakou, P. Cihon, and M. Demirer, “The impact of ai on developer productivity: Evidence from github copilot,”arXiv preprint arXiv:2302.06590, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Trade-offs for substituting a human with an agent in a pair program- ming context: the good, the bad, and the ugly,
S. K. Kuttal, B. Ong, K. Kwasny, and P. Robe, “Trade-offs for substituting a human with an agent in a pair program- ming context: the good, the bad, and the ugly,” inPro- ceedings of the 2021 CHI Conference on Human Factors in Computing Systems, 2021, pp. 1–20
2021
-
[43]
Is github copilot a substitute for human pair- programming? an empirical study,
S. Imai, “Is github copilot a substitute for human pair- programming? an empirical study,” inProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, 2022, pp. 319– 321
2022
-
[44]
A watermark for large language models,
J. Kirchenbauer, J. Geiping, Y . Wen, J. Katz, I. Miers, and T. Goldstein, “A watermark for large language models,” in International Conference on Machine Learning. PMLR, 2023, pp. 17 061–17 084
2023
-
[45]
Provable ro- bust watermarking for ai-generated text,
X. Zhao, P. Ananth, L. Li, and Y .-X. Wang, “Provable ro- bust watermarking for ai-generated text,”arXiv preprint arXiv:2306.17439, 2023
-
[46]
Monitoring ai-modified content at scale: a case study on the impact of chatgpt on ai conference peer re- views,
W. Liang, Z. Izzo, Y . Zhang, H. Lepp, H. Cao, X. Zhao, L. Chen, H. Ye, S. Liu, Z. Huang, D. A. McFarland, and J. Y . Zou, “Monitoring ai-modified content at scale: a case study on the impact of chatgpt on ai conference peer re- views,” inProceedings of the 41st International Confer- ence on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[47]
New evaluation metrics cap- ture quality degradation due to llm watermarking,
K. Singh and J. Zou, “New evaluation metrics cap- ture quality degradation due to llm watermarking,”arXiv preprint arXiv:2312.02382, 2023
-
[48]
Automatic detection of generated text is easiest when humans are fooled,
D. Ippolito, D. Duckworth, C. Callison-Burch, and D. Eck, “Automatic detection of generated text is easiest when humans are fooled,”arXiv preprint arXiv:1911.00650, 2019
-
[49]
What is a paraphrase?
R. Bhagat and E. Hovy, “What is a paraphrase?”Compu- tational linguistics, vol. 39, no. 3, pp. 463–472, 2013
2013
-
[50]
Authorship at- tribution for neural text generation,
A. Uchendu, T. Le, K. Shu, and D. Lee, “Authorship at- tribution for neural text generation,” inProceedings of the 2020 conference on empirical methods in natural lan- guage processing (EMNLP), 2020, pp. 8384–8395
2020
-
[51]
Defending against neural fake news,
R. Zellers, A. Holtzman, H. Rashkin, Y . Bisk, A. Farhadi, F. Roesner, and Y . Choi, “Defending against neural fake news,”Advances in neural information processing sys- tems, vol. 32, 2019. 19
2019
-
[52]
Tweepfake: About detecting deepfake tweets,
T. Fagni, F. Falchi, M. Gambini, A. Martella, and M. Tesconi, “Tweepfake: About detecting deepfake tweets,”Plos one, vol. 16, no. 5, p. e0251415, 2021
2021
-
[53]
How close is chatgpt to human ex- perts? comparison corpus, evaluation, and detection,
B. Guo, X. Zhang, Z. Wang, M. Jiang, J. Nie, Y . Ding, J. Yue, and Y . Wu, “How close is chatgpt to human ex- perts? comparison corpus, evaluation, and detection,” arXiv preprint arXiv:2301.07597, 2023
-
[54]
Is this snippet written by chatgpt? an empirical study with a codebert-based classi- fier,
P. T. Nguyen, J. Di Rocco, C. Di Sipio, R. Rubei, D. Di Ruscio, and M. Di Penta, “Is this snippet written by chatgpt? an empirical study with a codebert-based classi- fier,”arXiv preprint arXiv:2307.09381, 2023
-
[55]
Automated repair of programs from large language models,
Z. Fan, X. Gao, M. Mirchev, A. Roychoudhury, and S. H. Tan, “Automated repair of programs from large language models,” in2023 IEEE/ACM 45th International Confer- ence on Software Engineering (ICSE). IEEE, 2023, pp. 1469–1481
2023
-
[56]
Github copilot ai pair programmer: Asset or liability?
A. M. Dakhel, V . Majdinasab, A. Nikanjam, F. Khomh, M. C. Desmarais, and Z. M. J. Jiang, “Github copilot ai pair programmer: Asset or liability?”Journal of Systems and Software, vol. 203, p. 111734, 2023
2023
-
[57]
Refining chatgpt- generated code: Characterizing and mitigating code qual- ity issues,
Y . Liu, T. Le-Cong, R. Widyasari, C. Tantithamtha- vorn, L. Li, X.-B. D. Le, and D. Lo, “Refining chatgpt- generated code: Characterizing and mitigating code qual- ity issues,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 5, pp. 1–26, 2024
2024
-
[58]
Bugs in large lan- guage models generated code: An empirical study,
F. Tambon, A. Moradi-Dakhel, A. Nikanjam, F. Khomh, M. C. Desmarais, and G. Antoniol, “Bugs in large lan- guage models generated code: An empirical study,”Em- pirical Software Engineering, vol. 30, no. 3, p. 65, 2025
2025
-
[59]
Ccfinder: A mul- tilinguistic token-based code clone detection system for large scale source code,
T. Kamiya, S. Kusumoto, and K. Inoue, “Ccfinder: A mul- tilinguistic token-based code clone detection system for large scale source code,”IEEE transactions on software engineering, vol. 28, no. 7, pp. 654–670, 2002
2002
-
[60]
Github graphql api,
“Github graphql api,” 2024. [Online]. Available: https: //docs.github.com/en/graphql
2024
-
[61]
Grounded copilot: How programmers interact with code-generating models,
S. Barke, M. B. James, and N. Polikarpova, “Grounded copilot: How programmers interact with code-generating models,”Proc. ACM Program. Lang., vol. 7, no. OOPSLA1, Apr. 2023. [Online]. Available: https: //doi.org/10.1145/3586030
-
[62]
Evaluating Large Language Models Trained on Code
M. Chen, “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[63]
The meaning and use of the area under a receiver operating characteristic (roc) curve
J. A. Hanley and B. J. McNeil, “The meaning and use of the area under a receiver operating characteristic (roc) curve.”Radiology, vol. 143, no. 1, pp. 29–36, 1982
1982
-
[64]
On the possibilities of ai-generated text detection,
S. Chakraborty, A. S. Bedi, S. Zhu, B. An, D. Manocha, and F. Huang, “On the possibilities of ai-generated text detection,”arXiv preprint arXiv:2304.04736, 2023
-
[65]
Listening to program- mers—taxonomies and characteristics of comments in op- erating system code,
Y . Padioleau, L. Tan, and Y . Zhou, “Listening to program- mers—taxonomies and characteristics of comments in op- erating system code,” in2009 IEEE 31st International Conference on Software Engineering. IEEE, 2009, pp. 331–341
2009
-
[66]
Demysti- fying issues, challenges, and solutions for multilingual software development,
H. Yang, W. Lian, S. Wang, and H. Cai, “Demysti- fying issues, challenges, and solutions for multilingual software development,” in2023 IEEE/ACM 45th Inter- national Conference on Software Engineering (ICSE). IEEE, 2023, pp. 1840–1852
2023
-
[67]
How good is that agreement?
T. Byrtet al., “How good is that agreement?”Epidemiol- ogy, vol. 7, no. 5, p. 561, 1996
1996
-
[68]
language_tool_python,
“language_tool_python,” 2025. [Online]. Available: https://pypi.org/project/language-tool-python/
2025
-
[69]
go-github,
Google, “go-github,” 2025. [Online]. Available: https: //github.com/google/go-github
2025
-
[70]
[Online]
——, “Guava,” 2025. [Online]. Available: https: //github.com/google/guava
2025
-
[71]
[Online]
Shopify, “Liquid,” 2025. [Online]. Available: https: //github.com/Shopify/liquid
2025
-
[72]
[Online]
Uber, “Zap,” 2025. [Online]. Available: https://github. com/uber-go/zap
2025
-
[73]
[Online]
“act,” 2025. [Online]. Available: https://github.com/ nektos/act
2025
-
[74]
[Online]
“jadx,” 2025. [Online]. Available: https://github.com/ skylot/jadx
2025
-
[75]
[Online]
Apache, “Kafka,” 2025. [Online]. Available: https: //github.com/apache/kafka
2025
-
[76]
[Online]
“Pandas,” 2025. [Online]. Available: https://github.com/ pandas-dev/pandas
2025
-
[77]
Surveys considered harmful? re- flecting on the use of surveys in ai research, development, and governance,
M. Tahaei, D. Wilkinson, A. Frik, M. Muller, R. Abu- Salma, and L. Wilcox, “Surveys considered harmful? re- flecting on the use of surveys in ai research, development, and governance,” inProceedings of the AAAI/ACM Con- ference on AI, Ethics, and Society, vol. 7, 2024, pp. 1416– 1433. 20
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.