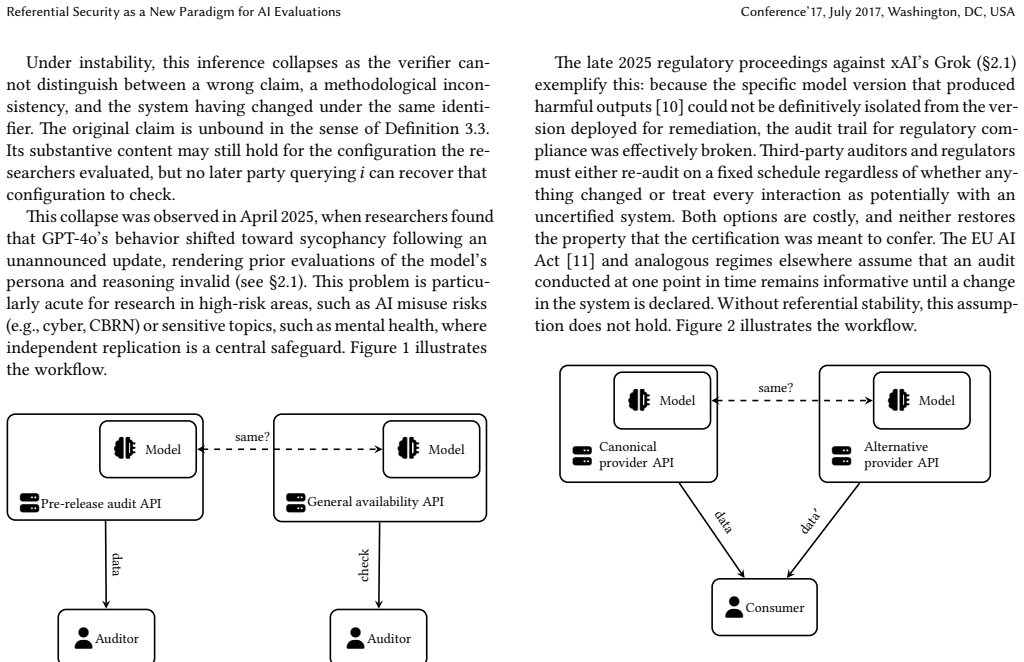
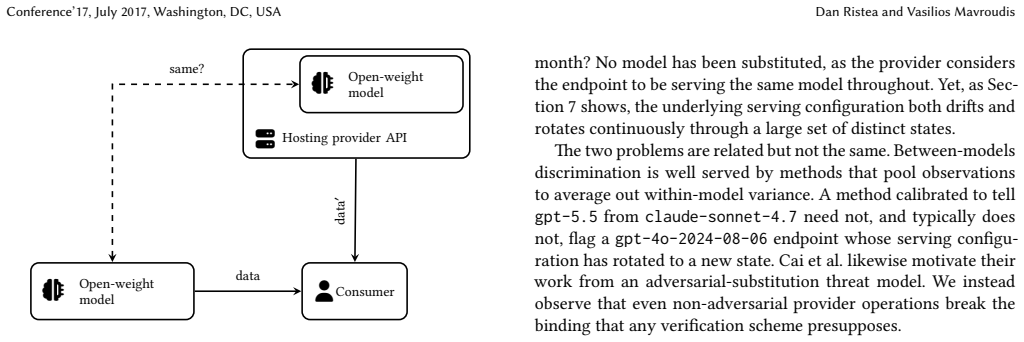
Referential Security as a New Paradigm for AI Evaluations
Pith reviewed 2026-06-29 21:56 UTC · model grok-4.3
The pith
AI safety evaluations lose their meaning when models update but their names stay fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Referential security extends the fundamental security question from whether a model is safe to whether subsequent parties can conclusively determine which system a specific safety claim addressed. Model identity is reframed as an empirically verifiable property, and referential stability is separated from the substantive security claims it conditions. By grounding evaluations in verifiable artifacts rather than static public designations, safety audits and regulatory findings retain empirical utility across the lifecycle of continuously modified systems.
What carries the argument
Referential security, the paradigm that makes model identity an empirically verifiable property distinct from the safety claims attached to it.
If this is right
- Evaluations become reproducible because each finding links to a verifiable artifact state.
- Longitudinal audits remain valid as systems evolve because identity can be checked over time.
- Cross-provider equivalence rests on matched verifiable identities rather than matching names.
- Regulatory decisions attach to identifiable systems and retain utility even after later modifications.
Where Pith is reading between the lines
- Standardized model-state capture methods would likely be needed to implement verifiable identity checks at scale.
- The same referential problem could affect non-security evaluations such as capability or performance benchmarks.
- Regulatory bodies might eventually require identity verification as a precondition for accepting any AI safety claim.
Load-bearing premise
Security evaluations inherently depend on stable identifiers that attach findings to specific, identifiable systems rather than superficial public labels.
What would settle it
An empirical demonstration that existing public model names already allow any subsequent party to conclusively identify the precise weights, prompts, and infrastructure addressed by a given safety evaluation.
Figures


read the original abstract
Security evaluations inherently depend on stable identifiers. Any finding, audit, or regulatory decision must remain attached to the specific artifact it pertains to. Continuously updated artificial intelligence systems violate this core assumption, with public model designations remaining static while underlying weights, prompts, retrieval mechanisms, misuse classifiers, inference settings, and serving infrastructures undergo unannounced modifications. Consequently, current evaluations frequently apply to superficial labels rather than identifiable and distinct systems. To resolve this, we propose referential security as a new paradigm for AI evaluation. The fundamental security question extends beyond whether a model is safe to whether subsequent parties can conclusively determine which system a specific safety claim addressed. This approach reframes model identity as an empirically verifiable property and separates referential stability from the substantive security claims it conditions. This framework brings tractability to three critical workflows that current practices handle poorly. Specifically, it enables reproducible evaluation, longitudinal audit validity, and cross-provider equivalence. By grounding these evaluations in verifiable artifacts, our approach ensures that safety audits and regulatory findings maintain their empirical utility across the operational lifecycle of dynamic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that AI security evaluations are undermined because continuously updated models have static public designations while their underlying components change, causing evaluations to attach to superficial labels rather than distinct systems. It proposes 'referential security' as a new paradigm that reframes model identity as an empirically verifiable property, separates referential stability from substantive safety claims, and thereby renders three workflows tractable: reproducible evaluation, longitudinal audit validity, and cross-provider equivalence.
Significance. If operationalized, the proposed separation of referential stability from substantive claims could improve the empirical utility of safety audits and regulatory findings by ensuring they remain attached to verifiable artifacts across model updates. The manuscript's definitional move is internally coherent and identifies a genuine practical problem with current identifier practices, but its significance remains prospective given the absence of any mechanism, example, or verification procedure.
major comments (1)
- [Abstract] Abstract, second paragraph: the assertion that the framework 'brings tractability' to reproducible evaluation, longitudinal audit validity, and cross-provider equivalence is presented as a direct consequence of separating referential stability from substantive claims, yet no mechanism, protocol, or illustrative case is supplied for how referential identity would be empirically verified or maintained. This absence is load-bearing for the central claim that the paradigm resolves the identified workflows.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the manuscript. The major comment identifies an important gap between the conceptual claims in the abstract and the absence of concrete mechanisms. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract, second paragraph: the assertion that the framework 'brings tractability' to reproducible evaluation, longitudinal audit validity, and cross-provider equivalence is presented as a direct consequence of separating referential stability from substantive claims, yet no mechanism, protocol, or illustrative case is supplied for how referential identity would be empirically verified or maintained. This absence is load-bearing for the central claim that the paradigm resolves the identified workflows.
Authors: We agree that the abstract overstates the immediate resolution of the workflows by claiming the framework 'brings tractability' without supplying mechanisms, protocols, or examples of empirical verification. The manuscript is a conceptual proposal that defines referential security, identifies the mismatch between static labels and dynamic systems, and argues that separating referential stability from substantive safety claims is a necessary precondition for addressing the three workflows. The tractability is presented as following from this separation in principle, rather than from any implemented verification procedure. To correct the overclaim, we will revise the abstract to state that the paradigm 'enables' or 'supports' these workflows through verifiable identity rather than directly resolving them. We will also add a short section outlining high-level approaches to empirical verification (e.g., cryptographic commitments to model artifacts or provenance logs) while noting that detailed protocols remain future work. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript is a conceptual proposal that defines referential security as a reframing of model identity and evaluation stability. Its central claims follow directly from the stated premise that public model designations are insufficiently stable for audits and that evaluations must attach to verifiable artifacts; no equations, fitted parameters, self-citations, or derivations are invoked that reduce the proposal to its own inputs by construction. The argument is self-contained as a definitional move.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Security evaluations inherently depend on stable identifiers.
invented entities (1)
-
referential security
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Florian Angermeir, Maximilian Amougou, Mark Kreitz, Andreas Bauer, Matthias Linhuber, Davide Fucci, Fabiola Moyón C., Daniel Mendez, and Tony Gorschek. 2026. Reflections on the Reproducibility of Commercial LLM Per- formance in Empirical Software Engineering Studies. In Proceedings of the 2026 IEEE/ACM 48th International Conference on Software Engineering...
-
[2]
Sebastian Baltes, Florian Angermeir, Chetan Arora, Marvin Muñoz Barón, Chun- yang Chen, Lukas Böhme, Fabio Calefato, Neil Ernst, Davide Falessi, Brian Fitzgerald, et al. 2026. Guidelines for empirical studies in software engineering involving large language models . arXiv: 2508.15503 [cs.SE] doi:10.48550/arXiv. 2508.15503
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[3]
Bjarni Haukur Bjarnason, André Silva, and Martin Monperrus. 2026. On random- ness in agentic evals . arXiv: 2602.07150 [cs.LG] doi:10.48550/arXiv.2602.07150
-
[4]
Miles Brundage, Noemi Dreksler, Aidan Homewood, Sean McGregor, Patricia Paskov, Conrad Stosz, Girish Sastry, A. Feder Cooper, George Balston, Steven Adler, Stephen Casper, Markus Anderljung, Grace Werner, Soren Mindermann, Vasilios Mavroudis, Ben Bucknall, Charlotte Stix, Jonas Freund, Lorenzo Pac- chiardi, Jose Hernandez-Orallo, Matteo Pistillo, Michael ...
-
[5]
Will Cai, Tianneng Shi, Xuandong Zhao, and Dawn Song. 2025. Are You Getting What You Pay For? Auditing Model Substitution in LLM APIs . arXiv:2504.04715 [cs.CL] doi:10.48550/arXiv.2504.04715
-
[6]
California State Legislature. 2025. Senate Bill 53: Transparency in Frontier Ar- tificial Intelligence Act . https://leginfo.legislature.ca.gov/faces/billNavClient. xhtml?bill_id=202520260SB53 Accessed 2026-05-14
2025
-
[7]
Bing-Jyue Chen, Suppakit Waiwitlikhit, Ion Stoica, and Daniel Kang. 2024. ZKML: An Optimizing System for ML Inference in Zero-Knowledge Proofs. In Proceedings of the Nineteenth European Conference on Computer Systems (Eu- roSys ’24) . Association for Computing Machinery, Athens, Greece, 560–574. doi:10.1145/3627703.3650088
-
[8]
Lingjiao Chen, Matei Zaharia, and James Zou. 2023. How is ChatGPT’s behavior changing over time? arXiv:2307.09009 [cs.CL] doi:10.48550/arXiv.2307.09009
- [9]
-
[10]
European Commission. 2026. Commission investigates Grok and X’s recommender systems under the Digital Services Act . European Commission Press Corner. https://ec.europa.eu/commission/presscorner/detail/en/ip_26_203 Press release IP/26/203. Accessed 2026-05-15
2026
-
[11]
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 . https: //data.europa.eu/eli/reg/2024/1689/oj Accessed 2026-05-14
2024
-
[12]
Federal Senate of Brazil. 2023. Projeto de Lei No. 2338/2023: Marco Legal da In- teligência Artificial (Brazil AI Act proposal) . https://www25.senado.leg.br/web/ atividade/materias/-/materia/157233 Draft bill establishing a national AI reg- ulatory framework with risk-based obligations, transparency, and governance requirements
2023
-
[13]
Irena Gao, Percy Liang, and Carlos Guestrin. 2025. Model Equal- ity Testing: Which Model Is This API Serving?. In International Con- ference on Learning Representations , Vol. 2025. OpenReview.net, Singa- pore, 86369–86382. https://proceedings.iclr.cc/paper_files/paper/2025/file/ d73234a13815fc1f9779dd17d89be9b4-Paper-Conference.pdf Conference’17, July 20...
2025
-
[14]
International Organization for Standardization. 2025. Information and documen- tation — Digital object identifier system . Standard ISO 26324:2025. International Organization for Standardization, Geneva, Switzerland. https://www.iso.org/ standard/88862.html
2025
-
[15]
Jed Liu and Andrew C Myers. 2014. Defining and enforcing referential security. In International Conference on Principles of Security and Trust. Springer, Grenoble, France, 199–219. doi:10.1007/978-3-642-54792-8_11
-
[16]
Microsoft. 2026. Foundry Models sold directly by Azure . Microsoft Foundry | Microsoft Learn. https://learn.microsoft.com/en-us/azure/foundry/foundry- models/concepts/models-sold-directly-by-azure Accessed 2026-05-13
2026
-
[17]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasser- man, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru
-
[18]
Model Cards for Model Reporting. In Proceedings of the Conference on Fair- ness, Accountability, and Transparency (FAT* ’19) . Association for Computing Machinery, Atlanta, GA, USA, 220–229. doi:10.1145/3287560.3287596
-
[19]
MITRE Corporation. 1999. Common Vulnerabilities and Exposures (CVE) . https: //www.cve.org
1999
-
[20]
Anshul Nasery, Edoardo Contente, Alkin Kaz, Pramod Viswanath, and Se- woong Oh. 2025. Are Robust LLM Fingerprints Adversarially Robust? arXiv:2509.26598 [cs.CR] doi:10.48550/arXiv.2509.26598
-
[21]
Shradha Neupane, Grant Holmes, Elizabeth Wyss, Drew Davidson, and Lorenzo De Carli. 2023. Beyond typosquatting: an in-depth look at package confu- sion. In 32nd USENIX security symposium (USENIX security 23) . USENIX Asso- ciation, Anaheim, CA, USA, Article 193, 18 pages. https://dl.acm.org/doi/10. 5555/3620237.3620430
-
[22]
OpenAI. 2025. Sycophancy in GPT-4o . https://openai.com/index/sycophancy- in-gpt-4o/ Accessed 2026-05-13
2025
-
[23]
OpenAI. 2026. API Reference | Chat . OpenAI Developers. https: //developers.openai.com/api/reference/python/resources/chat#(resource) %20chat.completions%20%3E%20(model)%20chat_completion%20%3E% 20(schema)%20%3E%20(property)%20system_fingerprint Accessed 2026-05-13
2026
-
[24]
OpenAI. 2026. API Reference | Conversation . OpenAI Developers. https: //developers.openai.com/api/reference/resources/responses/methods/create Ac- cessed 2026-05-13
2026
-
[25]
Kornaropoulos, and Giuseppe Ateniese
Dario Pasquini, Evgenios M. Kornaropoulos, and Giuseppe Ateniese. 2025. LLMmap: Fingerprinting for Large Language Models. In 34th USENIX Security Symposium (USENIX Security 25) . USENIX Association, Seattle, W A, Article 16, 20 pages. https://dl.acm.org/doi/10.5555/3766078.3766094
-
[26]
Zhizhi Peng, Chonghe Zhao, Taotao Wang, Guofu Liao, Zibin Lin, Yifeng Liu, Bin Cao, Long Shi, Qing Yang, and Shengli Zhang. 2026. A survey of zero-knowledge proof based verifiable machine learning. Artificial Intelligence Review 59 (13 Apr 2026), 56 pages. doi:10.1007/s10462-026-11557-y
-
[27]
Mark Russinovich, Yanan Cai, and Ahmed Salem. 2026. Hey, that’s my model! Introducing Chain & Hash, an LLM fingerprinting technique. In International Conference on Learning Representations . OpenReview.net, Rio de Janeiro, Brazil, 16 pages. https://openreview.net/pdf?id=UWi94bRsgm
2026
-
[28]
Dylan Sam, Marc Finzi, and J Zico Kolter. 2025. Predicting the Performance of Black-box LLMs through Follow-up Queries. In Advances in Neural Informa- tion Processing Systems , Vol. 38. OpenReview.net, Mexico City, Mexico, 158819– 158854. https://neurips.cc/virtual/2025/loc/san-diego/poster/118840
2025
-
[29]
Shyamal Anadkat (OpenAI). 2023. How to make your completions outputs consistent with the new seed parameter . OpenAI Developers. https://developers.openai.com/cookbook/examples/reproducible_outputs_ with_the_seed_parameter#implementing-consistent-outputs Accessed 2026- 05-13
2023
-
[30]
Haochen Sun, Jason Li, and Hongyang Zhang. 2024. zkLLM: Zero Knowledge Proofs for Large Language Models. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security (CCS ’24) . Association for Computing Machinery, Salt Lake City, UT, USA, 4405–4419. doi:10.1145/ 3658644.3670334
-
[31]
Mingjie Sun, Yida Yin, Zhiqiu Xu, J Zico Kolter, and Zhuang Liu. 2025. Idiosyn- crasies in Large Language Models. InProceedings of the 42nd International Confer- ence on Machine Learning (Proceedings of Machine Learning Research, Vol. 267) . PMLR, Vancouver, Canada, 57854–57885. https://proceedings.mlr.press/v267/ sun25z.html
2025
-
[32]
Linus Torvalds and Junio C. Hamano. 2005. Git. https://git-scm.com
2005
-
[33]
Matt Weinberger. 2016. One programmer almost broke the internet by deleting 11 lines of code. Business Insider. https://www.businessinsider.com/npm-left-pad- controversy-explained-2016-3
2016
-
[34]
Hui Xu, Chi Liu, Congcong Zhu, Minghao Wang, Youyang Qu, and Longxiang Gao. 2026. Causal Fingerprints of AI Generative Models. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, Barcelona, Spain, 13982–13986. doi:10.1109/ICASSP55912.2026.11463097
-
[35]
Xiaoyuan Zhu, Yaowen Ye, Tianyi Qiu, Hanlin Zhu, Sijun Tan, Ajraf Mannan, Jonathan Michala, Raluca Ada Popa, and Willie Neiswanger. 2025. Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test. arXiv:2506.06975 [cs.CR] doi:10.48550/arXiv.2506.06975
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.06975 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.