Steer, Don't Solve: Training Small Critic Models for Large Code Agents
Pith reviewed 2026-06-26 12:16 UTC · model grok-4.3
The pith
Training a small critic model on agent trajectories lets it steer large code agents to higher success rates without retraining the agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A small critic model trained via supervised fine-tuning on trajectories from code agents supplies intra-trajectory feedback that steers the agents toward higher task completion rates on software engineering benchmarks; the critic generalizes from source-agent data to unseen target agents and delivers accuracy gains at 30-92 times lower inference cost than a strong teacher model.
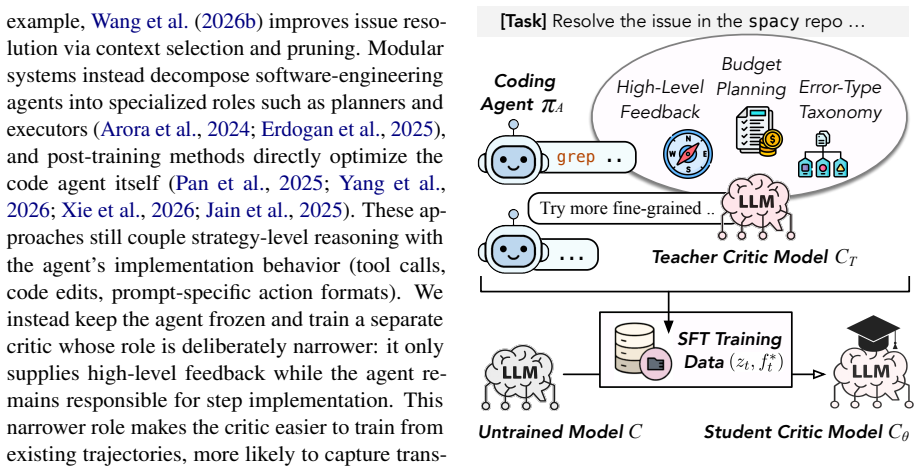
What carries the argument
Small critic model trained by supervised fine-tuning to emit intra-trajectory feedback that steers a frozen code agent.
Load-bearing premise
Feedback signals learned from trajectories of one or a few agents will generalize to steer previously unseen agents without joint optimization of the main agent.
What would settle it
A controlled test in which a critic trained only on CWM-32B trajectories produces zero or negative accuracy change when applied to a structurally different agent on the same benchmark.
Figures


read the original abstract
End-to-end code agent training is resource-intensive and plateaus on the strategy-level reasoning needed to resolve code issues, since jointly optimizing code-level execution and strategy-level reasoning leaves the latter underdeveloped. Instead, we freeze the agent and add a critic model to supply that signal. Prior code critics are post-hoc, scoring completed trajectories rather than steering the agent; we instead train a small critic that provides intra-trajectory feedback via Supervised Fine-Tuning. On SWE-bench Verified, a critic trained on CWM-32B trajectories transfers to two unseen agents (gains of +3.0 to +3.8 points), and adding target-agent trajectories to the corpus increases the gain to +3.8 on CWM-32B and +4.4 to +5.2 on two Qwen agents, at 30-92x lower critic cost than a strong teacher. On Qwen3-Next-80B-A3B, the critic-guided system is both more accurate (25.2% vs. 20.8%) and cheaper (\$0.04 vs. \$0.11) than the agent alone, because the critic also shortens trajectories. Our results show that a small, well-trained critic is a practical complement to scaling agent training. Code: https://github.com/shubhamrgandhi/critic-training. Data and models: https://huggingface.co/collections/shubhamrgandhi/critic-training-for-code-agents
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that end-to-end training of large code agents underdevelops strategy-level reasoning and that freezing the agent while training a small critic via supervised fine-tuning on trajectories to supply intra-trajectory feedback is more effective. On SWE-bench Verified, a critic trained on CWM-32B trajectories transfers to two unseen agents (+3.0 to +3.8 points); adding target-agent trajectories raises gains to +3.8 on CWM-32B and +4.4 to +5.2 on Qwen agents, at 30-92x lower cost than a strong teacher. The critic also shortens trajectories, yielding both higher accuracy (25.2% vs. 20.8%) and lower cost ($0.04 vs. $0.11) than the agent alone on Qwen3-Next-80B-A3B. Code, data, and models are released.
Significance. If the transfer results hold under rigorous controls, the work demonstrates a practical, low-cost complement to scaling agent training by isolating strategy feedback in a small model. The explicit release of code, data, and models is a clear strength that supports reproducibility and follow-up work.
major comments (2)
- [Abstract / Results] Abstract and experimental results: The central transfer claim (+3.0 to +3.8 points on two unseen agents from a CWM-32B-trained critic) rests on the untested assumption that SFT produces agent-agnostic feedback signals rather than signals tied to the training agent's error distribution or trajectory statistics. No quantitative measure of agent dissimilarity, ablation isolating trajectory overlap, or comparison of critic outputs across agent sources is reported, which is load-bearing for interpreting the gains as general rather than spurious.
- [Abstract] Abstract: The reported cost ratios (30-92x lower than a strong teacher) and accuracy/cost improvements on Qwen3-Next-80B-A3B are presented without error bars, data-split details, or baseline definitions for the teacher model, making it impossible to assess whether the efficiency claims are robust or sensitive to evaluation choices.
minor comments (2)
- [Abstract] The abstract states concrete numerical gains but does not define the exact SWE-bench Verified split or the precise definition of 'unseen agents' used for the transfer experiments.
- [Method] Notation for the critic's intra-trajectory feedback mechanism is introduced without an accompanying diagram or pseudocode showing how the critic output is injected into the agent's generation loop.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the transfer claims and the presentation of efficiency results. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and experimental results: The central transfer claim (+3.0 to +3.8 points on two unseen agents from a CWM-32B-trained critic) rests on the untested assumption that SFT produces agent-agnostic feedback signals rather than signals tied to the training agent's error distribution or trajectory statistics. No quantitative measure of agent dissimilarity, ablation isolating trajectory overlap, or comparison of critic outputs across agent sources is reported, which is load-bearing for interpreting the gains as general rather than spurious.
Authors: We agree that the manuscript does not currently provide quantitative measures of agent dissimilarity, trajectory overlap ablations, or direct comparisons of critic outputs. The reported gains on agents with different architectures and training regimes constitute the primary evidence offered for generalization, but additional analysis would strengthen the interpretation. In the revised manuscript we will add (1) quantitative descriptors of agent dissimilarity (model scale, architecture family, and trajectory statistics such as average length and error types), (2) an ablation that isolates the effect of trajectory overlap, and (3) side-by-side statistics or visualizations of critic output distributions when applied to the training versus evaluation agents. revision: yes
-
Referee: [Abstract] Abstract: The reported cost ratios (30-92x lower than a strong teacher) and accuracy/cost improvements on Qwen3-Next-80B-A3B are presented without error bars, data-split details, or baseline definitions for the teacher model, making it impossible to assess whether the efficiency claims are robust or sensitive to evaluation choices.
Authors: We acknowledge that the current presentation lacks error bars, explicit data-split information, and a precise definition of the teacher baseline. The revised manuscript will report standard errors or confidence intervals for all accuracy and cost figures, specify the exact train/validation/test splits and number of runs, and provide a clear description of the teacher model (size, prompting method, and cost-calculation procedure) together with the agent-alone baseline configuration. revision: yes
Circularity Check
No significant circularity; empirical transfer results are self-contained measurements
full rationale
The paper reports empirical performance gains from training a small critic via supervised fine-tuning on trajectories generated by one or more code agents, then measuring accuracy improvements when the critic steers the same or unseen agents on SWE-bench Verified. No equations, parameter-fitting procedures, or derivations are described that would reduce the reported gains to inputs by construction. The central claims rest on direct experimental measurements of transfer (including ablations that add target-agent data), not on any self-definitional loop, fitted-input prediction, or load-bearing self-citation chain. External benchmarks and cost comparisons are presented as independent observations rather than tautological outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Supervised fine-tuning on agent trajectories produces feedback that generalizes across agents
Reference graph
Works this paper leans on
-
[1]
Naman Jain, Jaskirat Singh, Manish Shetty, Tianjun Zhang, Liang Zheng, Koushik Sen, and Ion Stoica
Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738. Naman Jain, Jaskirat Singh, Manish Shetty, Tianjun Zhang, Liang Zheng, Koushik Sen, and Ion Stoica
-
[2]
InNeurIPS 2025 Fourth Workshop on Deep Learning for Code
R2e-gym: Procedural environments and hy- brid verifiers for scaling open-weights SWE agents. InNeurIPS 2025 Fourth Workshop on Deep Learning for Code. Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can language mod- els resolve real-world github issues? InInternational Conference ...
2025
-
[3]
InInternational Conference on Learning Representations, volume 2024, pages 39578–39601
Let's verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Simiao Liu, Fang Liu, Liehao Li, Xin Tan, Yinghao Zhu, Xiaoli Lian, and Li Zhang. 2025. An empirical study on failures in automated issue solving.Preprint, arXiv:2509.13941. Nat McAleese, Rai Michael Pokorny, Juan Felipe Ceron Uribe, Evgenia ...
arXiv 2024
-
[4]
Ming Shen, Raphael Shu, Anurag Pratik, James Gung, Yubin Ge, Monica Sunkara, and Yi Zhang
Direct preference optimization: Your lan- guage model is secretly a reward model.Preprint, arXiv:2305.18290. Ming Shen, Raphael Shu, Anurag Pratik, James Gung, Yubin Ge, Monica Sunkara, and Yi Zhang. 2025. Op- timizing llm-based multi-agent system with textual feedback: A case study on software development. arXiv preprint arXiv:2505.16086. Noah Shinn, Fed...
Pith/arXiv arXiv 2025
-
[5]
backseat drives
SWE-smith: Scaling data for software en- gineering agents. InThe Thirty-ninth Annual Con- ference on Neural Information Processing Systems Datasets and Benchmarks Track. 11 A Additional Related Work Textual feedback for prompt optimization.A related line of work uses textual feedback not as the output of a standalone critic model, but as a signal for impr...
2025
-
[6]
Task Specification Violations Definition: Agent fails to adhere to task constraints or requirements
-
[7]
Role Specification Violations Definition: Agent behaves outside its defined role/responsibilities
-
[8]
Step Repetition Definition: Unnecessary repetition of completed steps or actions
-
[9]
Termination Condition Unawareness Definition: Agent continues working when task completion criteria are met REASONING ERRORS:
-
[10]
Problem Misidentification Definition: Agent misunderstands the core problem or current subtask
-
[11]
Tool Selection Errors Definition: Agent uses inappropriate tools for the current task
-
[12]
Hallucinations Definition: Agent generates false information or fabricates tool outputs
-
[13]
Information Processing Failures 14 Definition: Poor retrieval of relevant information or misinterpretation COORDINATION ERRORS:
-
[14]
Task Derailment Definition: Agent deviates from intended objective or loses focus
-
[15]
Goal Deviation Definition: Agent pursues goals that don't serve the main objective
-
[16]
Context Handling Failures Definition: Agent loses important context or forgets previous findings
-
[17]
On track
Verification Failures Definition: Inadequate checking of work quality or correctness ===================================================== RESPONSE FORMAT ===================================================== For each error category, respond with: DETECTED: Yes/No EVIDENCE: (if detected) One sentence. RECOVERY_ACTION: (if detected) One sentence. No code, ...
-
[20]
RECOVERY_ACTION: Stop repeating and analyze the existing test output
Step Repetition: DETECTED: Yes EVIDENCE: Agent ran the same test command three times with identical results. RECOVERY_ACTION: Stop repeating and analyze the existing test output
-
[23]
Tool Selection Errors: DETECTED: No
-
[29]
Analyze the output you already ,→have and proceed to the next step
Verification Failures: DETECTED: No TASK_STATUS: Needs correction OVERALL_GUIDANCE: You are repeating the same test. Analyze the output you already ,→have and proceed to the next step. Now review the agent's trajectory and provide your supervisor feedback. C.2 Detailed Prompt The detailed prompt below is reproduced verbatim from Gandhi et al. (2025) for r...
2025
-
[30]
Task Specification Violations Definition: Agent fails to adhere to task constraints or requirements Recovery: Redirect agent to original task requirements
-
[31]
Role Specification Violations Definition: Agent behaves outside its defined role/responsibilities Recovery: Remind agent of its specific role and boundaries
-
[32]
Step Repetition Definition: Unnecessary repetition of completed steps or actions Recovery: Acknowledge completed work and guide to next logical step
-
[33]
Termination Condition Unawareness Definition: Agent continues working when task completion criteria are met Recovery: Signal completion criteria and instruct to finalize REASONING ERRORS (Decision Making Issues)
-
[34]
Problem Misidentification Definition: Agent misunderstands the core problem or current subtask Recovery: Clarify the actual problem and expected approach
-
[35]
Tool Selection Errors Definition: Agent uses inappropriate tools for the current task Recovery: Suggest correct tools and explain their appropriate usage
-
[36]
Hallucinations Definition: Agent generates false information or fabricates tool outputs Recovery: Request verification of claims against actual evidence
-
[37]
Information Processing Failures Definition: Poor retrieval of relevant information or misinterpretation Recovery: Guide agent to correct information sources and interpretation COORDINATION ERRORS (Process Management Issues)
-
[38]
Task Derailment Definition: Agent deviates from intended objective or loses focus Recovery: Realign agent with original objectives and priorities
-
[39]
Goal Deviation Definition: Agent pursues goals that don't serve the main objective Recovery: Refocus on primary goals and expected outcomes
-
[40]
Context Handling Failures Definition: Agent loses important context or forgets previous findings Recovery: Provide context summary and key information recap
-
[41]
Verification Failures Definition: Inadequate checking of work quality or correctness Recovery: Instruct specific verification steps and quality checks ===================================================== RESPONSE FORMAT ===================================================== For each error category, respond with: DETECTED: Yes/No EVIDENCE: Specific quote o...
-
[42]
Task Specification Violations: DETECTED: No
-
[43]
Role Specification Violations: DETECTED: No
-
[44]
Agent ran the same test command three times: 'pytest test_file.py'
Step Repetition: DETECTED: Yes EVIDENCE: "Agent ran the same test command three times: 'pytest test_file.py'" RECOVERY_ACTION: "The test has already been executed successfully. Proceed to ,→analyze the results and move to the next development step."
-
[45]
Termination Condition Unawareness: DETECTED: No REASONING ERRORS:
-
[46]
Problem Misidentification: DETECTED: No
-
[47]
Agent used text editor to run Python code instead of using the Python ,→interpreter
Tool Selection Errors: DETECTED: Yes EVIDENCE: "Agent used text editor to run Python code instead of using the Python ,→interpreter" RECOVERY_ACTION: "Use the Python interpreter tool for code execution. The text ,→editor is for viewing and modifying files only."
-
[48]
Hallucinations: DETECTED: No
-
[49]
Information Processing Failures: DETECTED: No COORDINATION ERRORS:
-
[50]
Task Derailment: DETECTED: No
-
[51]
Goal Deviation: DETECTED: No
-
[52]
Context Handling Failures: DETECTED: No
-
[53]
,→Specifically:
Verification Failures: DETECTED: No TASK_STATUS: Needs correction OVERALL_GUIDANCE: You are repeating actions unnecessarily and using incorrect tools. ,→Specifically:
-
[54]
Stop running the same test command repeatedly - the test 'pytest test_file.py' ,→has already been executed successfully three times with the same result
-
[55]
Use the Python interpreter tool for executing Python code, not the text editor ,→which is only for viewing and modifying files
-
[56]
Now focus on analyzing the test results you already obtained to determine what ,→the next development step should be
-
[57]
Review the test output to identify any failing tests or areas that need ,→improvement
-
[58]
If all tests are passing, proceed to verify your implementation meets the ,→original requirements before considering the task complete ===================================================== INSTRUCTIONS =====================================================
-
[59]
Focus on errors that can be corrected through guidance
-
[60]
Provide specific, actionable recovery instructions
-
[61]
Be concise but precise in evidence citations
-
[62]
DETECTED: Yes
Only mark "DETECTED: Yes" if you have clear evidence
-
[63]
Sub.” is the submission rate; “Res. on Sub
Prioritize errors that most threaten task completion Now review the agent's trajectory and provide your supervisor feedback. C.3 Budget-Aware Instructions After the agent passes step 100 of its 150-step budget, the following budget-aware instructions are appended to whichever critic prompt is in use: NOTE: The agent has used {{current_step}} of its {{step...
-
[64]
RECOVERY_ACTION: Stop using sed append commands and instead rewrite the file using a heredoc or a different approach
Step Repetition: DETECTED: Yes EVIDENCE: Agent has repeatedly applied the same sed append command, each time creating duplicate`__iter__`methods inside the`Paginator`class. RECOVERY_ACTION: Stop using sed append commands and instead rewrite the file using a heredoc or a different approach
-
[65]
or if a new . . . class is needed
Tool Selection Errors: DETECTED: Yes EVIDENCE: Agent is using`sed -i '/def page_range(self):/a'` ... but this creates multiple duplicate method definitions each time it's run because the pattern matches multiple times after the first insertion. RECOVERY_ACTION: Use a different editing strategy: write the entire file using a heredoc, or use a Python script...
-
[66]
Implementation approach: After matching a numeric literal and consuming any standard suffixes (`uUlLfF`), also try to match an identifier suffix (the ud-suffix)
-
[67]
Check the AST classes - look at`ASTNumberLiteral`, `ASTStringLiteral`,`ASTCharLiteral`to see if they need modification, or if a new`ASTUserDefinedLiteral`class wrapping them is needed. G.4 Where the trained critic still falls short The resolve gain is uniform across agent models, but on the trajectory-process side stuck-in-loop rate increases by 17.4 poin...
1942
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.