ReGuide: From Test-Time Guidance to Self-Improving Diffusion Policies
Pith reviewed 2026-06-30 09:43 UTC · model grok-4.3
The pith
ReGuide turns one-time test-time guidance into reusable recovery data that lets diffusion policies improve themselves through fine-tuning or retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
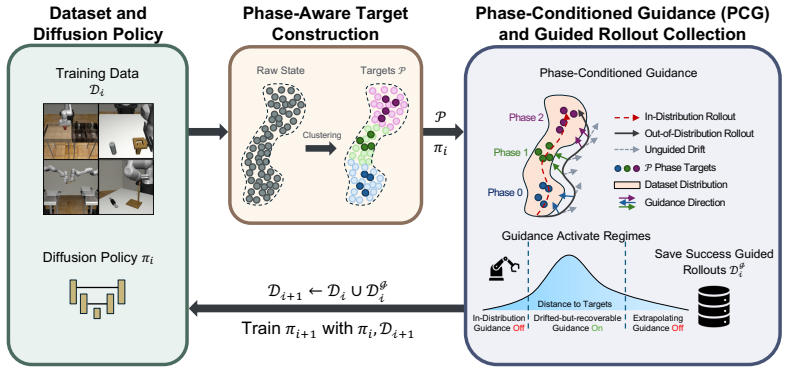
ReGuide is a self-improving loop that first applies phase-conditioned guidance to produce corrective rollouts by constructing phase-specific latent targets and guiding through estimated clean actions, then absorbs successful guided trajectories back into the policy via ReGuide-FT fine-tuning or ReGuide-FS retraining from scratch; the two absorption methods can be composed and repeated.
What carries the argument
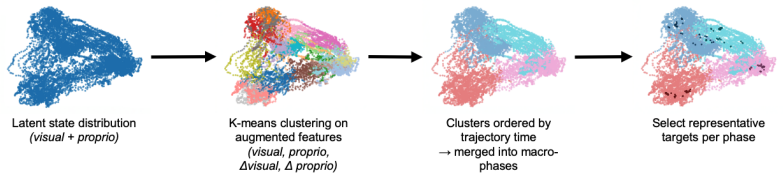
Phase-Conditioned Guidance (PCG), which builds phase-specific latent targets and restricts guidance to the drifted-but-recoverable regime to keep generated actions inside the dynamics model's training distribution.
If this is right
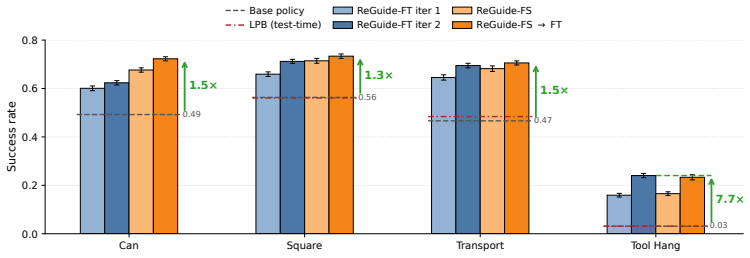
- Base diffusion policies achieve 1.3–7.7× higher success on Robomimic Can, Square, Transport, and Tool Hang tasks.
- ReGuide outperforms LPB when both are restricted to the test-time-only setting.
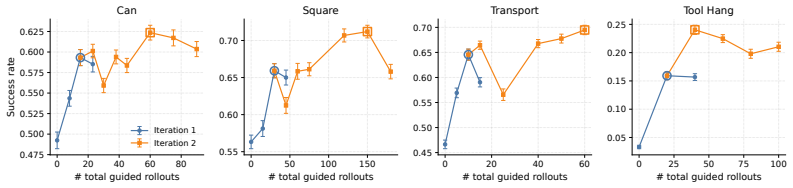
- Matched-data ablations show performance gains arise from the guided recovery trajectories rather than from simply collecting more rollouts.
- The framework supports repeated improvement by composing fine-tuning and from-scratch retraining steps.
Where Pith is reading between the lines
- Iterating the absorption loop multiple times could reduce dependence on the size of the original demonstration set.
- The recoverable-regime restriction in guidance may apply to other policy classes that exhibit partial recoverability.
- Success identification could be replaced by an automated verifier to close the loop without human labeling.
Load-bearing premise
Guided rollouts can be reliably labeled as successful and folded back into training without creating new distribution shift or compounding errors.
What would settle it
A controlled run in which success rates after absorbing the guided data are no higher than after absorbing an equal number of unguided rollouts would falsify the claim that the guidance step supplies the critical recovery signal.
Figures
read the original abstract
Behavior-cloned diffusion policies are expressive but remain vulnerable to covariate shift: small deviations from demonstrated states can compound into task failure. Existing methods address this either by expanding the training distribution through expert corrections or synthetic augmentation, or by steering a frozen policy at test time with guidance from a learned model. The former can be expensive or assumption-dependent, while the latter discards the corrected trajectories after execution. We introduce ReGuide, a self-improving framework that treats guided rollouts as reusable on-policy recovery data. ReGuide first uses Phase-Conditioned Guidance (PCG) to generate corrective rollouts: it constructs phase-specific latent targets, applies guidance only in the drifted-but-recoverable regime, and guides through the estimated clean action to match the dynamics model's training distribution. Successful guided rollouts are then absorbed back into the policy through ReGuide-FT, which fine-tunes the current checkpoint, or ReGuide-FS, which retrains from scratch on the augmented dataset; the two can also be composed and iterated. On Robomimic Can, Square, Transport, and Tool Hang, ReGuide improves base-policy success by $1.3$--$7.7\times$, outperforms LPB in the test-time-only setting, and matched-data ablations show that the gains come from guided recovery data rather than additional rollouts alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReGuide, a self-improving framework for diffusion policies that first applies Phase-Conditioned Guidance (PCG) to produce corrective rollouts only in the drifted-but-recoverable regime while matching the dynamics model's training distribution, then absorbs successful guided trajectories back into the policy via ReGuide-FT (fine-tuning the current checkpoint) or ReGuide-FS (retraining from scratch on the augmented dataset). On Robomimic Can, Square, Transport, and Tool Hang, it reports 1.3--7.7× gains in base-policy success rate, outperforms LPB under test-time-only guidance, and uses matched-data ablations to attribute gains to the guided recovery data rather than additional rollouts.
Significance. If the empirical claims hold, the work offers a concrete bridge between test-time guidance and iterative self-improvement for behavior-cloned diffusion policies, potentially lowering the cost of expert data collection in robotic manipulation. The matched-data ablations constitute a methodological strength by isolating the contribution of guided recoveries from mere increases in rollout volume.
major comments (2)
- [Abstract] Abstract (paragraph describing ReGuide-FT/FS): the central claim that guided rollouts can be reliably identified as successful and absorbed as on-policy recovery data without introducing new distribution shift or compounding errors lacks any description of the success criterion, verification procedure, or support check against the original BC distribution; this assumption is load-bearing for the self-improvement loop.
- [Abstract] Abstract (PCG description): the statement that guidance is applied 'only in the drifted-but-recoverable regime' and 'through the estimated clean action to match the dynamics model's training distribution' is presented without the corresponding equations, phase-conditioning mechanism, or dynamics-model details needed to evaluate whether the generated actions remain inside the original training support.
minor comments (2)
- [Abstract] The abstract reports quantitative gains (1.3--7.7×) but supplies no error bars, number of seeds, or explicit success criteria; these should be added to the results summary even if full tables appear later.
- Dataset statistics (number of demonstrations, task horizons, observation/action dimensions) are referenced only implicitly; a brief table or paragraph would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the full manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing ReGuide-FT/FS): the central claim that guided rollouts can be reliably identified as successful and absorbed as on-policy recovery data without introducing new distribution shift or compounding errors lacks any description of the success criterion, verification procedure, or support check against the original BC distribution; this assumption is load-bearing for the self-improvement loop.
Authors: We agree the abstract omits these details. The full manuscript defines success via the standard Robomimic environment success flags (task completion within episode horizon) in Sections 4.1 and 4.3; verification consists of executing the rollout and recording the binary success indicator. Distribution-shift concerns are addressed via the matched-data ablations in Section 5.3, which isolate guided-recovery contributions. We will revise the abstract to include a brief clause on the success criterion and verification. revision: yes
-
Referee: [Abstract] Abstract (PCG description): the statement that guidance is applied 'only in the drifted-but-recoverable regime' and 'through the estimated clean action to match the dynamics model's training distribution' is presented without the corresponding equations, phase-conditioning mechanism, or dynamics-model details needed to evaluate whether the generated actions remain inside the original training support.
Authors: The abstract is intentionally high-level; the phase-conditioning mechanism, equations for constructing phase-specific latent targets, and clean-action guidance are fully specified in Section 3.2, together with the dynamics model (identical to the one used for the base diffusion policy). We will add a short clarifying phrase to the abstract referencing these elements while keeping the abstract equation-free. revision: partial
Circularity Check
No significant circularity; empirical framework with independent experimental validation
full rationale
The paper describes an empirical self-improving framework (ReGuide with PCG, ReGuide-FT/FS) for diffusion policies, supported by success-rate improvements on Robomimic tasks and matched-data ablations that isolate the contribution of guided recovery data. No equations, derivations, or first-principles predictions appear; claims do not reduce to fitted parameters renamed as outputs or to self-citation chains. The method is self-contained against external benchmarks (task success rates), with no load-bearing uniqueness theorems or ansatzes imported from prior author work. This is the normal case of an applied ML paper whose central results are falsifiable via replication rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 15 ofProceedings of Machine Learning Research, pages 627–635, 2011
2011
-
[2]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023. doi:10.15607/RSS.2023.XIX.026
- [3]
- [4]
-
[5]
L. Ke, Y . Zhang, A. Deshpande, S. Srinivasa, and A. Gupta. CCIL: Continuity-based data augmentation for corrective imitation learning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[6]
In: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp
L. Ankile, A. Simeonov, I. Shenfeld, and P. Agrawal. Juicer: Data-efficient imitation learning for robotic assembly. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5096–5103, 2024. doi:10.1109/IROS58592.2024.10802498
-
[7]
M. Jia, D. Wang, G. Su, D. Klee, X. Zhu, R. Walters, and R. Platt. SEIL: Simulation-augmented equivariant imitation learning. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 1845–1851, 2023
2023
- [8]
- [9]
-
[10]
Y . He, N. Murata, C.-H. Lai, Y . Takida, T. Uesaka, D. Kim, W.-H. Liao, Y . Mitsufuji, J. Z. Kolter, R. Salakhutdinov, and S. Ermon. Manifold preserving guided diffusion. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[11]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation. InProceedings of the 5th Conference on Robot Learning (CoRL), volume 164 ofProceedings of Machine Learning Research, pages 1678–1690, 2022
2022
- [12]
- [13]
-
[14]
S. A. Mehta, Y . U. Ciftci, B. Ramachandran, S. Bansal, and D. P. Losey. Stable-bc: Controlling covariate shift with stable behavior cloning.IEEE Robotics and Automation Letters, 10(2): 1952–1959, 2025. doi:10.1109/LRA.2025.3526439
-
[15]
Dhariwal and A
P. Dhariwal and A. Nichol. Diffusion models beat GANs on image synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), volume 34, pages 8780–8794, 2021. 10
2021
-
[16]
Ho and T
J. Ho and T. Salimans. Classifier-free diffusion guidance. InNeurIPS Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[17]
Diffusion guidance is a controllable policy improvement operator
K. Frans, S. Park, P. Abbeel, and S. Levine. Diffusion guidance is a controllable policy improvement operator, 2025. URLhttps://arxiv.org/abs/2505.23458
-
[18]
C. Lu, H. Chen, J. Chen, H. Su, C. Li, and J. Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. InProceedings of the 40th International Conference on Machine Learning (ICML), volume 202 ofProceedings of Machine Learning Research, pages 22825–22855, 2023
2023
-
[19]
Hansen-Estruch, I
P. Hansen-Estruch, I. Kostrikov, M. Janner, J. G. Kuba, and S. Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies, 2023. URLhttps://arxiv.org/abs/2304. 10573
2023
-
[20]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. DINO-WM: World models on pre-trained visual features enable zero-shot planning. InProceedings of the 42nd International Conference on Machine Learning (ICML), volume 267 ofProceedings of Machine Learning Research, pages 79115–79135, 2025
2025
-
[21]
Mandlekar, F
A. Mandlekar, F. Ramos, B. Boots, S. Savarese, L. Fei-Fei, A. Garg, and D. Fox. IRIS: Implicit reinforcement without interaction at scale for learning control from offline robot manipulation data. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 4414–4420, 2020
2020
-
[22]
Gupta, V
A. Gupta, V . Kumar, C. Lynch, S. Levine, and K. Hausman. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. InProceedings of the Conference on Robot Learning (CoRL), volume 100 ofProceedings of Machine Learning Research, pages 1025–1037, 2020
2020
-
[23]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InProceedings of the Conference on Robot Learning (CoRL), volume 205 of Proceedings of Machine Learning Research, pages 785–799, 2022
2022
-
[24]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. MimicGen: A data generation system for scalable robot learning using human demonstrations. InProceedings of the Conference on Robot Learning (CoRL), volume 229 ofProceedings of Machine Learning Research, pages 1820–1864, 2023
2023
-
[25]
Xie, M.-T
Q. Xie, M.-T. Luong, E. Hovy, and Q. V . Le. Self-training with noisy student improves imagenet classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[26]
Rebuffi, A
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert. icarl: Incremental classifier and representation learning. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
2017
-
[27]
what counts as in-distribution
P. Buzzega, M. Boschini, A. Porrello, D. Abati, and S. Calderara. Dark experience for general continual learning: a strong, simple baseline. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. A Extended Related Work This section expands on the related work discussion in Section 2, providing additional detail on individual methods and cov...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.