AI-Associated Lexical Shifts Across 34 Languages: Cross-Lingual Convergence and Diachronic Uptake in News Writing
Pith reviewed 2026-06-29 22:53 UTC · model grok-4.3
The pith
AI lexical preferences extend across 34 languages with emphasize-type verbs recurring in 24 and rising in prevalence after ChatGPT.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
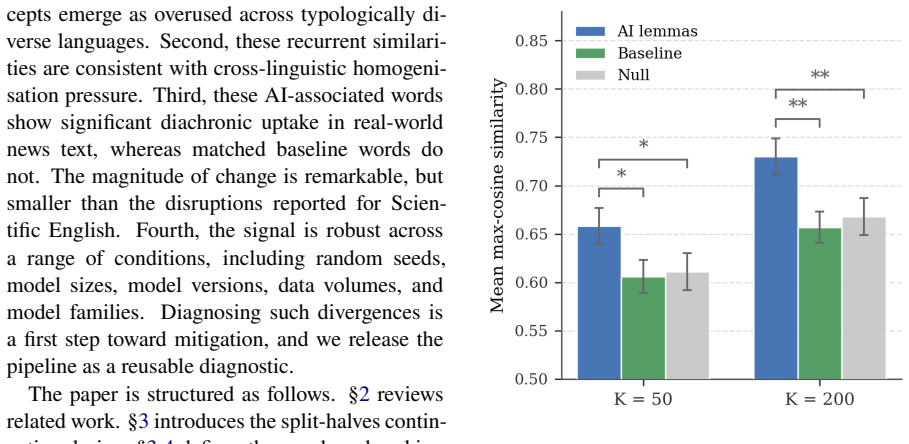
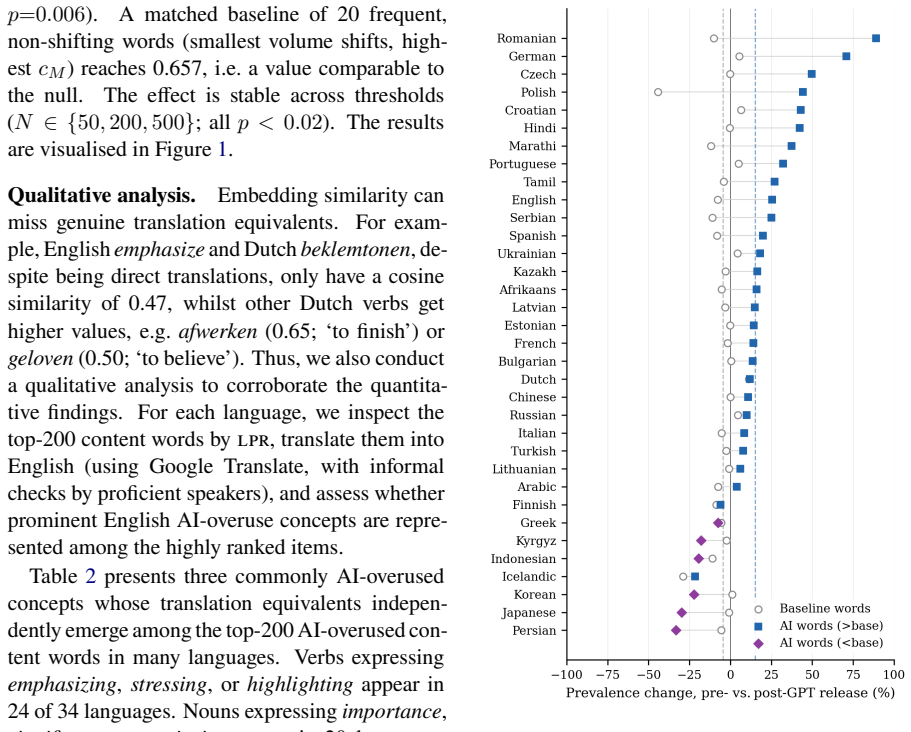
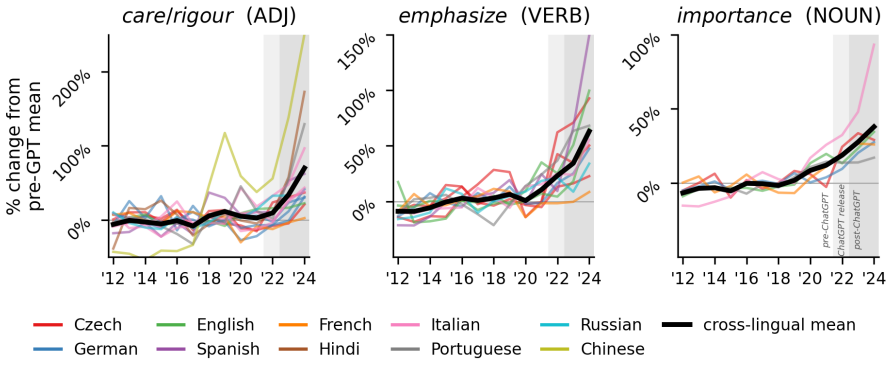
We find substantial cross-lingual semantic convergence: semantically related concepts recur across typologically diverse languages, with 'emphasize'-type verbs appearing in 24 of 34 languages. Prevalence increases in 26 of 34 languages from 2020-2021 to 2023-2024, with a mean change of +15.1%, whilst matched baseline words show no comparable increase (-4.5%). In 10 languages with longer historical coverage, longitudinal analyses show post-2022 increases that exceed the modest shifts observed in earlier periods, though with smaller effect sizes than in Scientific English.
What carries the argument
The split-halves continuation diagnostic that compares GPT-4.1 continuations with matched human gold-standard text to derive ranked AI-overused lemmas using log prevalence ratios.
If this is right
- Semantically related concepts recur across typologically diverse languages.
- Prevalence of the top 20 AI-overused items increases in 26 of 34 languages after ChatGPT release.
- Matched baseline words show no comparable increase.
- Post-2022 increases in 10 languages exceed earlier modest shifts.
- The findings are consistent with AI exerting cross-lingual homogenising pressure on global language use.
Where Pith is reading between the lines
- If the pattern holds, news writing in multiple languages may gradually align on a shared set of AI-favored terms beyond the observed emphasize cluster.
- The smaller effect sizes relative to scientific English suggest the uptake rate could vary by genre and audience.
- Extending the same diagnostic to social media or fiction corpora could reveal whether convergence appears outside news.
- Longer time series in additional languages would clarify whether the post-2022 acceleration continues or plateaus.
Load-bearing premise
The split-halves continuation diagnostic accurately isolates AI-associated lexical preferences without being driven by topic, style, or other non-AI differences between the two text sources.
What would settle it
A controlled test in which human and GPT-4.1 text are produced on identical narrow topics and styles yet still show the same ranked lemma differences, or independent news corpora showing no post-2022 rise in the identified emphasize-type lemmas.
Figures
read the original abstract
AI-associated lexical shifts have been documented mainly in Scientific English. We extend this work to 34 languages in the WMT News Crawl corpus, refining a split-halves continuation diagnostic that compares GPT-4.1 continuations with matched human gold-standard text. For each language, we derive ranked AI-overused lemmas using log prevalence ratios. We find substantial cross-lingual semantic convergence: semantically related concepts recur across typologically diverse languages, with 'emphasize'-type verbs appearing in 24 of 34 languages. Embedding-based and manual analyses support this pattern. We also examine diachronic uptake in news writing before and after ChatGPT's release. Tracking each language's top 20 AI-overused items, we find prevalence increases in 26 of 34 languages from 2020-2021 to 2023-2024, with a mean change of +15.1%, whilst matched baseline words show no comparable increase (-4.5%). In 10 languages with longer historical coverage, longitudinal analyses show post-2022 increases that exceed the modest shifts observed in earlier periods, though with smaller effect sizes than in Scientific English. We validate our approach extensively, including across seeds, model variants, data sizes, model families, and more. Our findings are consistent with the view that AI-associated lexical preferences extend beyond English and may exert cross-lingual homogenising pressure on global language use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends prior work on AI-associated lexical shifts from scientific English to 34 languages in the WMT News Crawl corpus. It introduces a split-halves continuation diagnostic that ranks lemmas by log prevalence ratio between GPT-4.1 continuations and matched human gold-standard text, then reports (i) cross-lingual semantic convergence (e.g., 'emphasize'-type verbs in 24 languages) supported by embeddings and manual checks, and (ii) diachronic uptake, with top-20 AI-overused lemmas rising +15.1% on average from 2020-2021 to 2023-2024 while matched baselines fall -4.5%. Extensive validation across seeds, model families, and data sizes is claimed.
Significance. If the diagnostic isolates AI-specific lexical preferences rather than generation artifacts, the results would indicate that AI lexical biases operate cross-lingually and exert measurable pressure on news writing after ChatGPT's release, extending beyond English and scientific domains. The parameter-free nature of the prevalence-ratio construction and the reported reproducibility across model variants are strengths.
major comments (1)
- [Methods / abstract] The split-halves continuation diagnostic (abstract and methods): the claim that prefix-matched GPT-4.1 continuations versus human gold-standard text isolates AI word-choice biases rests on the untested assumption that systematic differences in output properties (sentence length, formality, discourse structure, or residual topic mismatch) do not drive the observed log prevalence ratios. Because both the cross-lingual convergence count (24/34 languages) and the diachronic +15.1% vs. -4.5% contrast are derived directly from these ratios, any residual confound would undermine the central interpretation that the patterns reflect AI influence rather than generation artifacts.
minor comments (2)
- [Abstract] The abstract reports a mean prevalence change of +15.1% without accompanying standard deviation, confidence interval, or per-language distribution; adding these would strengthen the diachronic claim.
- [Abstract] The phrase 'matched baseline words' is used without an explicit definition of the matching procedure (e.g., frequency, length, or semantic similarity); a brief clarification would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key assumption in the split-halves diagnostic. We address the concern directly below and outline targeted revisions.
read point-by-point responses
-
Referee: [Methods / abstract] The split-halves continuation diagnostic (abstract and methods): the claim that prefix-matched GPT-4.1 continuations versus human gold-standard text isolates AI word-choice biases rests on the untested assumption that systematic differences in output properties (sentence length, formality, discourse structure, or residual topic mismatch) do not drive the observed log prevalence ratios. Because both the cross-lingual convergence count (24/34 languages) and the diachronic +15.1% vs. -4.5% contrast are derived directly from these ratios, any residual confound would undermine the central interpretation that the patterns reflect AI influence rather than generation artifacts.
Authors: We agree that the diagnostic rests on an assumption that merits explicit testing. Prefix matching from the same human news texts substantially reduces topic mismatch, and the use of log prevalence ratios within continuations further focuses on word choice rather than global properties. Our reported validations across seeds, model families, and data sizes show stable lemma rankings, which would be unlikely if the signal were driven primarily by uniform generation artifacts. Nevertheless, we did not directly measure or control for differences in sentence length, formality, or discourse structure. In revision we will add (i) length-normalized prevalence ratios, (ii) formality scoring of continuations versus human text, and (iii) a comparison of discourse markers to quantify any residual stylistic differences. These controls will be reported alongside the existing cross-lingual and diachronic results. If the patterns persist after these adjustments, the interpretation that the shifts reflect AI lexical preferences will be strengthened; if not, we will qualify the claims accordingly. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's central quantities are log prevalence ratios computed directly from GPT-4.1 continuations versus matched human gold-standard text drawn from the external WMT News Crawl corpus. Convergence counts (e.g., 'emphasize'-type verbs in 24 languages) and diachronic prevalence changes (+15.1% vs. -4.5% baseline) are simple empirical tallies and comparisons of these ratios across languages and time periods. No equations, fitted parameters, or self-citations reduce these observations to the input data by construction; the split-halves diagnostic is presented as an empirical method whose outputs are then measured against independent benchmarks. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The WMT News Crawl corpus provides representative samples of news writing for each of the 34 languages.
- domain assumption The split-halves continuation diagnostic using GPT-4.1 produces text whose lexical differences from human gold-standard text are attributable to AI generation rather than other factors.
Reference graph
Works this paper leans on
-
[1]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Ai suggestions homogenize writing toward western styles and diminish cultural nuances. In Pro- ceedings of the 2025 CHI conference on human fac- tors in computing systems, pages 1–21. Barrett R Anderson, Jash Hemant Shah, and Max Kreminski. 2024. Homogenization effects of large 11 language models on human creative ideation. In Pro- ceedings of the 16th co...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2506.05339 , year =
Examining linguistic shifts in academic writ- ing before and after the launch of chatgpt: a study on preprint papers. Scientometrics, 130(7):3597–3627. Michele Bevilacqua and Roberto Navigli. 2020. Break- ing through the 80% glass ceiling: Raising the state of the art in word sense disambiguation by incorpo- rating knowledge graph information. In Proceedi...
-
[3]
arXiv preprint arXiv:2304.04736
On the possibilities of ai-generated text de- tection. arXiv preprint arXiv:2304.04736. Jay Chooi. 2026. Stylistic transfer from annotator com- munities to large language models. In Proceedings of the 10th Joint SIGHUM Workshop on Computa- tional Linguistics for Cultural Heritage, Social Sci- ences, Humanities and Literature 2026 , pages 135– 145. Paul F ...
-
[4]
In Pro- ceedings of the 24th conference on computational natural language learning, pages 609–619
Cloze distillation: Improving neural language models with human next-word prediction. In Pro- ceedings of the 24th conference on computational natural language learning, pages 609–619. Sarah Fitterer, Dominik Gangl, and Jannes Ulbrich
-
[5]
In Proceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 4: Student Research Workshop) , pages 1239–1245
Testing english news articles for lexical ho- mogenization due to widespread use of large lan- guage models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 4: Student Research Workshop) , pages 1239–1245. 12 Iason Gabriel. 2020. Artificial intelligence, values, and alignment: I. gabriel. Minds and mach...
2020
-
[6]
Exploring the structure of ai-induced lan- guage change in scientific english. arXiv preprint arXiv:2506.21817. Sebastian Gehrmann, Hendrik Strobelt, and Alexan- der M Rush. 2019. Gltr: Statistical detection and visualization of generated text. In Proceedings of the 57th annual meeting of the association for com- putational linguistics: system demonstrati...
-
[7]
arXiv preprint arXiv:2603.25638
Beyond via: Analysis and estimation of the impact of large language models in academic papers. arXiv preprint arXiv:2603.25638. Mingmeng Geng and Thierry Poibeau. 2025. On the de- tectability of llm-generated text: What exactly is llm- generated text? arXiv preprint arXiv:2510.20810. Mingmeng Geng and Roberto Trotta. 2024. Is chat- gpt transforming academ...
-
[8]
Diachronic word embeddings reveal statisti- cal laws of semantic change. In Proceedings of the 54th Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers) , pages 1489–1501. Hans W A Hanley and Zakir Durumeric. 2024. Machine-made media: Monitoring the mobilization of machine-generated articles on misinformation and mains...
-
[9]
Scientific re- ports, 13(1):5487
Artificial intelligence in communication im- pacts language and social relationships. Scientific re- ports, 13(1):5487. Yifei Huang, Jiuxin Cao, Hanyu Luo, Xin Guan, and Bo Liu. 2025. Magret: Machine-generated text detection with rewritten texts. In Proceedings of the 31st International Conference on Computational Linguistics, pages 8336–8346. Yueyue Huan...
2025
-
[10]
Proceedings of the National Academy of Sciences, 120(11):e2208839120
Human heuristics for ai-generated language are flawed. Proceedings of the National Academy of Sciences, 120(11):e2208839120. Houji Jin, Negin Ashrafi, Armin Abdollahi, Wei Liu, Jian Wang, Ganyu Gui, Maryam Pishgar, and Huang- hao Feng. 2025a. Llm encoder vs. decoder: Ro- bust detection of chinese ai-generated text with lora. arXiv preprint arXiv:2509.0073...
-
[11]
Lengua y Sociedad , 23(2):895–910
Análisis léxico de textos generados por mod- elos de lenguaje: reflejo de sus modelos de mundo. Lengua y Sociedad , 23(2):895–910. Kayvan Kousha and Mike Thelwall. 2025. How much are llms changing the language of academic papers after chatgpt? a multi-database and full text analysis. arXiv preprint arXiv:2509.09596. Raphail Krichevsky and Victor Trofimov....
-
[12]
Detecting fake content with relative entropy scoring. Pan, 8(27-31):4. Christoph Leiter, Jonas Belouadi, Y anran Chen, Ran Zhang, Daniil Larionov, Aida Kostikova, and Steffen Eger. 2024. Nllg quarterly arxiv report 09/24: What are the most influential current ai papers? arXiv preprint arXiv:2412.12121. Chih- Yuan Li, Soon Ae Chun, and James Geller. 2024a....
-
[13]
Computers in Human Behavior: Artificial Humans , page 100207
Homogenizing effect of large language mod- els (llms) on creative diversity: An empirical com- parison of human and chatgpt writing. Computers in Human Behavior: Artificial Humans , page 100207. Sonia Krishna Murthy, Tomer Ullman, and Jennifer Hu
-
[14]
One fish, two fish, but not the whole sea: Alignment reduces language models’ conceptual di- versity. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associ- ation for Computational Linguistics: Human Lan- guage Technologies (Volume 1: Long Papers), pages 11241–11258. Roberto Navigli and Simone Paolo Ponzetto. 2012. Ba-...
-
[15]
Advances in neural information processing systems, 36:53728– 53741
Direct preference optimization: Y our lan- guage model is secretly a reward model. Advances in neural information processing systems, 36:53728– 53741. Rolf Reber, Norbert Schwarz, and Piotr Winkielman
-
[16]
Can AI-Generated Text be Reliably Detected?
Processing fluency and aesthetic pleasure: Is beauty in the perceiver’s processing experience? Personality and social psychology review, 8(4):364– 382. Nils Reimers and Iryna Gurevych. 2020. Making monolingual sentence embeddings multilingual us- ing knowledge distillation. In Proceedings of the 2020 conference on empirical methods in natural lan- guage p...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
International Journal of Speech Technology, 27(4):935–956
Classification of human-and ai-generated texts for different languages and domains. International Journal of Speech Technology, 27(4):935–956. Dominik Schlechtweg, Barbara McGillivray, Simon Hengchen, Haim Dubossarsky, and Nina Tahmasebi
-
[18]
Towards Understanding Sycophancy in Language Models
Semeval-2020 task 1: Unsupervised lexical semantic change detection. In Proceedings of the fourteenth workshop on semantic evaluation , pages 1–23. V Schmalz and Anaïs Tack. 2025. Can gptzero’s ai vocabulary distinguish between llm-generated and student-written essays. Kochmar, E.; Alhafni, B.; Bexte, M.; Burstein, J, pages 937–952. Mrinank Sharma, Meg To...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
The Curse of Recursion: Training on Generated Data Makes Models Forget
The curse of recursion: Training on gen- erated data makes models forget. arXiv preprint arXiv:2305.17493. Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nico- las Papernot, Ross Anderson, and Y arin Gal. 2024. Ai models collapse when trained on recursively gen- erated data. Nature, 631(8022):755–759. Olivia Sidoti and Colleen McClain. 2025. 34% of u.s. ad...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Antonio Marcio Da Silva and Lucia Rottava
Pew Research Center. Antonio Marcio Da Silva and Lucia Rottava. 2024. Densidade lexical em textos gerados pelo chatgpt: implicações da inteligência artificial para a escrita em línguas adicionais. Texto Livre, 17:e47836. Zhivar Sourati, Alireza S Ziabari, and Morteza De- hghani. 2025. The homogenizing effect of large language models on human expression an...
-
[21]
Simple synthetic data reduces sycophancy in large language models
Testing of detection tools for ai-generated text. International Journal for Educational Integrity, 19(1):1–39. Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V Le. 2023. Simple synthetic data reduces sycophancy in large language models. arXiv preprint arXiv:2308.03958. Emily Wenger and Y oed Kenett. 2025. We’re different, we’re the same: Creative ho...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Do NOT repeat the input text
-
[23]
If the input text is machine-formatted or technical data, output an empty string ("") and nothing else
-
[24]
Here is the continuation
Do NOT provide any conversational preface or acknowledgments (e.g., "Here is the continuation...")
-
[25]
Output ONLY natural language
-
[26]
User prompts
Output ONLY the continuation text. User prompts. English: Provide a continuation of this English news text, without preamble, continue directly:\n\n[prompt text ] Dutch: Schrijf het vervolg van deze Nederlandse nieuwstekst, zonder inleiding, ga direct door:\n\n[ prompt text] Language-specific user prompts are provided in the GitHub repository. C Diachroni...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.