Improving Visual Representation Alignment Generation with GRPO
Pith reviewed 2026-06-28 19:22 UTC · model grok-4.3
The pith
VRPO replaces static alignment losses in diffusion transformers with adaptive reward-guided optimization to improve image quality and speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
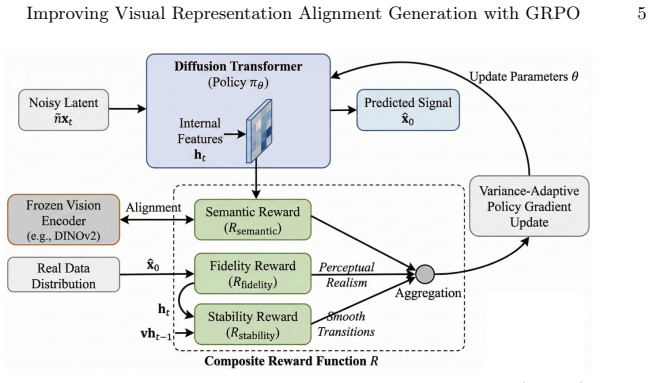
VRPO treats representation alignment as a reward-guided process where the model receives adaptive rewards based on generation fidelity, perceptual quality, and semantic coherence between the diffusion features and pretrained visual embeddings, enabling the generator to continuously refine its internal representations toward semantically meaningful directions while improving image quality.
What carries the argument
VRPO, a reinforcement-based optimization strategy that replaces REPA's static alignment loss with a generative representation policy optimization objective using adaptive rewards.
If this is right
- VRPO integrates seamlessly into diffusion transformers with negligible computation cost.
- It preserves full compatibility with SiT and DiT architectures.
- It achieves up to +1.8 FID improvement on ImageNet-256x256 compared to REPA.
- It enables 2.3x faster training than REPA under identical compute budgets.
Where Pith is reading between the lines
- The reward formulation could extend to other generative tasks where static alignment objectives limit adaptivity.
- Similar policy optimization might reduce reliance on large pretrained encoders in future diffusion variants.
- Task-adaptive rewards could help when training on datasets with varying semantic complexity.
Load-bearing premise
Rewards defined from generation fidelity, perceptual quality, and semantic coherence can be computed stably and optimized without introducing training instability or hidden computational costs.
What would settle it
Run VRPO training on ImageNet-256x256 with a DiT model and check whether the reported +1.8 FID improvement and 2.3x speedup fail to appear or training becomes unstable.
Figures


read the original abstract
Recent diffusion transformers have demonstrated strong image synthesis capabilities but remain inefficient to train due to weak alignment between generative and discriminative representations. While representation alignment frameworks such as REPA improve convergence by aligning noisy denoising features with pretrained visual encoders, their externally supervised alignment loss is static and lacks adaptivity during training and inference. Existing methods rely on fixed cosine alignment or contrastive objectives, which cannot dynamically balance representation consistency and generation quality, resulting in limited discriminative benefit and failing to optimize alignment in a task-adaptive manner. To address this, we propose VRPO, a reinforcement-based optimization strategy that replaces REPA's static alignment loss with a generative representation policy optimization objective. Instead of enforcing a fixed similarity constraint, VRPO treats representation alignment as a reward-guided process: the model receives adaptive rewards based on generation fidelity, perceptual quality, and semantic coherence between the diffusion features and pretrained visual embeddings. This formulation enables the generator to continuously refine its internal representations toward semantically meaningful directions while improving image quality. Our VRPO-driven training seamlessly integrates into diffusion transformers, introducing negligible computation cost and preserving full compatibility with SiT and DiT architectures. Extensive experiments on ImageNet-256x256 demonstrate that our VRPO-Alignment substantially enhances both convergence and fidelity, achieving up to +1.8 FID improvement and 2.3x faster training compared to REPA under identical compute budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VRPO (also referred to as GRPO in the title), a reinforcement learning-based optimization method that replaces the static alignment loss in frameworks like REPA with an adaptive, reward-guided objective for representation alignment in diffusion transformers (DiT/SiT). Rewards are defined from three components—generation fidelity, perceptual quality, and semantic coherence between diffusion features and pretrained embeddings—enabling task-adaptive refinement. The method claims seamless integration with negligible overhead and reports up to +1.8 FID improvement and 2.3× faster training versus REPA on ImageNet-256×256 under identical compute.
Significance. If the central claims hold with stable, low-variance rewards and verifiable implementation details, the work could meaningfully advance adaptive representation alignment in generative models by moving beyond fixed cosine/contrastive losses. However, the absence of reward equations, normalization, advantage estimation, or ablation on variance in the provided text limits assessment of whether the reported speedups and FID gains are robust or artifactual.
major comments (3)
- [Abstract] Abstract: No equations or pseudocode are supplied for the reward formulation (how fidelity, perceptual quality, and semantic coherence terms are computed, weighted, or normalized), the policy gradient objective, or advantage estimation. This directly undermines evaluation of the central claim that rewards yield stable signals without introducing instability or hidden costs, as flagged by the stress-test concern on variance scaling with feature dimension.
- [Abstract] Abstract: The performance claims (+1.8 FID, 2.3× speedup) are stated without reference to baselines, error bars, data splits, or training curves. Without these, it is impossible to determine whether the improvements are load-bearing for the VRPO contribution or could arise from unstated hyperparameter differences versus REPA.
- [Abstract] Abstract: The description of rewards derived from 'generation quality' creates a potential circularity risk (rewards computed from model outputs feeding back into the same model) that is not addressed with independent grounding or variance analysis; this is load-bearing for the 'negligible overhead' and 'no instability' premises.
minor comments (2)
- [Title] Title uses 'GRPO' while the abstract and body consistently use 'VRPO'; this notation inconsistency should be resolved.
- [Abstract] The abstract refers to 'extensive experiments' but provides no table or figure references; adding a high-level results table in the abstract or introduction would improve readability.
Simulated Author's Rebuttal
We thank the referee for their detailed feedback. We address each major comment below and will revise the manuscript to improve clarity on the points raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: No equations or pseudocode are supplied for the reward formulation (how fidelity, perceptual quality, and semantic coherence terms are computed, weighted, or normalized), the policy gradient objective, or advantage estimation. This directly undermines evaluation of the central claim that rewards yield stable signals without introducing instability or hidden costs, as flagged by the stress-test concern on variance scaling with feature dimension.
Authors: The full manuscript details the reward formulation, objective, and advantage estimation in Section 3 (including explicit equations for the weighted reward components using fixed external models, the GRPO policy gradient, and GAE for advantages). We agree the abstract would benefit from a concise reference to these and will add a high-level reward equation plus section pointer in the revision. revision: yes
-
Referee: [Abstract] Abstract: The performance claims (+1.8 FID, 2.3× speedup) are stated without reference to baselines, error bars, data splits, or training curves. Without these, it is impossible to determine whether the improvements are load-bearing for the VRPO contribution or could arise from unstated hyperparameter differences versus REPA.
Authors: The claims are substantiated by the experiments in Section 4, which include direct REPA comparisons under matched compute, error bars from multiple seeds, standard ImageNet splits, and training curves. We will revise the abstract to explicitly reference these experimental details and the matched setting. revision: yes
-
Referee: [Abstract] Abstract: The description of rewards derived from 'generation quality' creates a potential circularity risk (rewards computed from model outputs feeding back into the same model) that is not addressed with independent grounding or variance analysis; this is load-bearing for the 'negligible overhead' and 'no instability' premises.
Authors: Generation fidelity uses independent fixed metrics and frozen pretrained components (distinct from the diffusion model outputs), as do the perceptual and semantic terms. Variance stability is analyzed in the appendix. We will revise the abstract to clarify the independent grounding of all reward terms. revision: yes
Circularity Check
No circularity: VRPO introduces independent reward signals from external metrics.
full rationale
The abstract describes VRPO as replacing a static alignment loss with a policy optimization objective driven by rewards computed from generation fidelity, perceptual quality, and semantic coherence with pretrained embeddings. These reward components are defined via external metrics (e.g., perceptual and semantic distances) rather than being tautologically derived from the model's own outputs or fitted parameters. No equations are provided that reduce the claimed improvements (+1.8 FID, 2.3x speedup) to the inputs by construction, nor is there self-citation of a uniqueness theorem or ansatz smuggling. The derivation chain remains self-contained against external benchmarks such as REPA, with the central claim resting on empirical integration rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward balancing coefficients for fidelity, perceptual quality, and semantic coherence
axioms (1)
- domain assumption Pretrained visual encoders supply embeddings that remain semantically meaningful when aligned with noisy diffusion features.
Reference graph
Works this paper leans on
-
[1]
In: IEEE Conference on Computer Vision and Pattern Recognition (2023)
Assran, M., Duval, Q., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., Le- Cun, Y., Ballas, N.: Self-supervised learning from images with a joint-embedding predictive architecture. In: IEEE Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[2]
OpenAI Blog (2024)
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., Ng, C., Wang, R., Ramesh, A.: Video gener- ation models as world simulators. OpenAI Blog (2024)
2024
-
[3]
In: International Conference on Machine Learning (2020)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: International Conference on Machine Learning (2020)
2020
-
[4]
arXiv preprint arXiv:2401.14404 (2024)
Chen, X., Liu, Z., Xie, S., He, K.: Deconstructing denoising diffusion models for self-supervised learning. arXiv preprint arXiv:2401.14404 (2024)
-
[5]
In: IEEE International Conference on Computer Vision (2021)
Chen, X., Xie, S., He, K.: An empirical study of training self-supervised vision transformers. In: IEEE International Conference on Computer Vision (2021)
2021
-
[6]
In: Advances in Neural Information Processing Systems (NeurIPS) 30
Christiano, P.F., Leike, J., Brown, T.B., Martic, M., Legg, S., Amodei, D.: Deep re- inforcement learning from human preferences. In: Advances in Neural Information Processing Systems (NeurIPS) 30. pp. 4299–4307 (2017)
2017
-
[7]
In: IEEE Conference on Computer Vision and Pattern Recognition (2009)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A large- scale hierarchical image database. In: IEEE Conference on Computer Vision and Pattern Recognition (2009)
2009
-
[8]
In: International Conference on Machine Learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: International Conference on Machine Learning (2024)
2024
-
[9]
In: Advances in Neural Information Processing Systems (2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs trained by a two time-scale update rule converge to a local nash equilibrium. In: Advances in Neural Information Processing Systems (2017)
2017
-
[10]
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J.: Video diffusion models. arXiv preprint arXiv:2204.03458 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
In: Advances in Neural Information Processing Systems (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems (2020)
2020
-
[12]
In: International Conference on Machine Learning (2024)
Huh, M., Cheung, B., Wang, T., Isola, P.: The platonic representation hypothesis. In: International Conference on Machine Learning (2024)
2024
-
[13]
arXiv preprint arXiv:2504.10483 (2025)
Leng, X., Singh, J., Hou, Y., Xing, Z., Xie, S., Zheng, L.: Repa-e: Unlock- ing vae for end-to-end tuning with latent diffusion transformers. arXiv preprint arXiv:2504.10483 (2025)
-
[14]
In: IEEE International Conference on Computer Vision (2023)
Li, A.C., Prabhudesai, M., Duggal, S., Brown, E., Pathak, D.: Your diffusion model is secretly a zero-shot classifier. In: IEEE International Conference on Computer Vision (2023)
2023
-
[15]
In: European Conference on Computer Vision (2024)
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: SiT: Exploring flow and diffusion-based generative models withscalable interpolant transformers. In: European Conference on Computer Vision (2024)
2024
-
[16]
Transactions on Machine Learning Research (2024) 16 S
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[17]
In: IEEE Inter- national Conference on Computer Vision (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: IEEE Inter- national Conference on Computer Vision (2023)
2023
-
[18]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
MetaAI Blog Post (2024),https://ai.meta.com/blog/movie-gen-media-foundation- models-generative-ai-video/
Polyak, A., Zohar, A., Brown, A., Tjandra, A., Sinha, A., Lee, A., Vyas, A., Shi, B., Ma, C.Y., Chuang, C.Y., Yan, D., Choudhary, D., Wang, D., Sethi, G., Pang, G., Ma, H., Misra, I., Hou, J., Wang, J., Jagadeesh, K., Li, K., Zhang, L., Singh, M., Williamson, M., Le, M., Singh, M.K., Zhang, P., Vajda, P., Duval, Q., Gird- har, R., Sumbaly, R., Rambhatla, ...
2024
-
[20]
In: International Conference on Machine Learning (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (2021)
2021
-
[21]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafailov, R., Sharma, A., Mitchell, E., Finn, C., Ermon, S.: Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290 (2024),https://arxiv.org/abs/2305.18290
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022).https://doi.org/10.48550/arXiv.2204.06125
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.06125 2022
-
[23]
In: IEEE Conference on Computer Vision and Pattern Recognition (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: IEEE Conference on Computer Vision and Pattern Recognition (2022)
2022
-
[24]
In: Advances in Neural Information Processing Systems (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K.,GontijoLopes,R.,KaragolAyan,B.,Salimans,T.,etal.:Photorealistictext-to- image diffusion models with deep language understanding. In: Advances in Neural Information Processing Systems (2022)
2022
-
[25]
In: Advances in Neural Information Pro- cessing Systems (2016)
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved techniques for training GANs. In: Advances in Neural Information Pro- cessing Systems (2016)
2016
-
[26]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimizationalgorithms.CoRRabs/1707.06347(2017),http://arxiv.org/abs/ 1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
In: Interna- tional Conference on Learning Representations (2021)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. In: Interna- tional Conference on Learning Representations (2021)
2021
-
[28]
arXiv preprint arXiv:2507.01467 (2025)
Wu, G., Zhang, S., Shi, R., Gao, S., Cheng, M.M., Li, X.: Representation entangle- ment for generation: Training diffusion transformers is much easier than you think. arXiv preprint arXiv:2507.01467 (2025)
-
[29]
arXiv preprint arXiv:2509.08826 (2025),https://arxiv.org/abs/2509.08826
Wu, J., Gao, Y., Ye, Z., Li, M., Li, L., Guo, H., Liu, J., Xue, Z., Hou, X., Liu, W., Zeng, Y., Weilin, H.: Rewarddance: Reward scaling in visual generation. arXiv preprint arXiv:2509.08826 (2025),https://arxiv.org/abs/2509.08826
-
[30]
In: IEEE International Conference on Computer Vision (2023) Improving Visual Representation Alignment Generation with GRPO 17
Xiang, W., Yang, H., Huang, D., Wang, Y.: Denoising diffusion autoencoders are unified self-supervised learners. In: IEEE International Conference on Computer Vision (2023) Improving Visual Representation Alignment Generation with GRPO 17
2023
-
[31]
Xu, Z., Zhang, S., Li, X., Sun, X., Gao, P., Li, H., Qiao, Y.: Imagereward: Learn- ing and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems (NeurIPS) (2024),https://arxiv.org/ abs/2304.05977, arXiv preprint arXiv:2304.05977
-
[32]
In: IEEE Interna- tional Conference on Computer Vision (2023)
Yang, X., Wang, X.: Diffusion model as representation learner. In: IEEE Interna- tional Conference on Computer Vision (2023)
2023
-
[33]
In: International Conference on Learning Representations (2025)
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. In: International Conference on Learning Representations (2025)
2025
-
[34]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
2018
-
[35]
Flow-GRPO: Training Flow Matching Models via Online RL
Zhang, Y., Ye, T., Zhang, H., Shi, Y., Lu, Y., Xie, E., Li, Z.: Flow-grpo: Training diffusion models towards better rewards with generative flow policy optimization. arXiv preprint arXiv:2505.05470 (2024),https://arxiv.org/abs/2505.05470
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Fine-Tuning Language Models from Human Preferences
Ziegler, D.M., Stiennon, N., Wu, J., Brown, T.B., Radford, A., Amodei, D., Chris- tiano, P.F., Irving, G.: Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593 (2019),https://arxiv.org/abs/1909.08593 18 S. Mo and S. Yun Appendix In this appendix, we provide the following material: –Additional implementation and dataset detai...
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[37]
(17) Taking the partial derivatives and setting them to zero gives2ασ2 f −λ= 0 =⇒ α= λ 2σ2 f
We define the Lagrangian: L(α, β, γ, λ) =α 2σ2 f +β 2σ2 se +γ 2σ2 st −λ(α+β+γ−1). (17) Taking the partial derivatives and setting them to zero gives2ασ2 f −λ= 0 =⇒ α= λ 2σ2 f . By symmetry,β= λ 2σ2se andγ= λ 2σ2 st . Substituting these into the constraintα+β+γ= 1yieldsλ= 2 1 σ2 f + 1 σ2se + 1 σ2 st −1 . Therefore, the optimal weights are strictly proporti...
-
[38]
All-layer alignment: applying rewards across all transformer layers
-
[39]
Early-layer alignment: first 25–50% of blocks
-
[40]
As shown in Table 5, aligning only early layers achieves the best trade-off, im- proving FID by+0.8while reducing training cost by 35%
Mid-layer alignment: middle 25–75% of blocks. As shown in Table 5, aligning only early layers achieves the best trade-off, im- proving FID by+0.8while reducing training cost by 35%. This validates our Improving Visual Representation Alignment Generation with GRPO 23 Table 5:Effect of reward gradient injection across layers. Early-layer alignment achieves ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.