The Calibrated Deepfake Trust Score (CDTS): Competence-Coupled Trust Degradation Across Deepfake Detectors
Pith reviewed 2026-06-30 07:08 UTC · model grok-4.3
The pith
As deepfake detectors lose their ability to tell fakes from real, their output probabilities stop being well-calibrated trust measures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
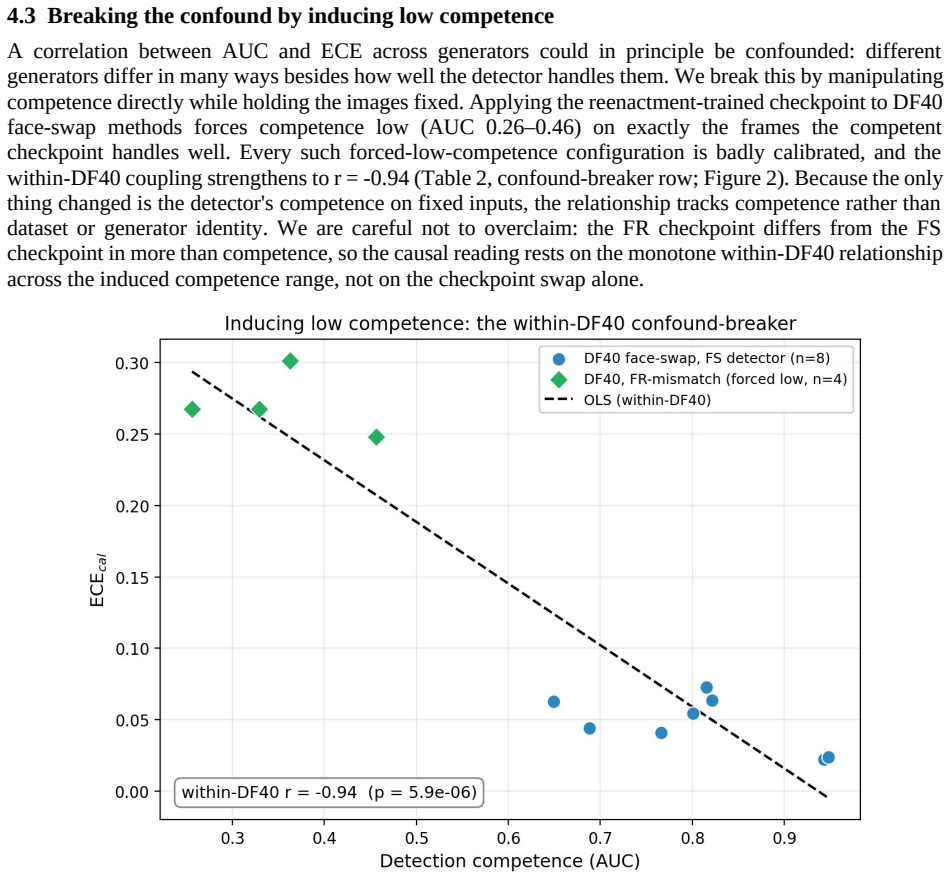
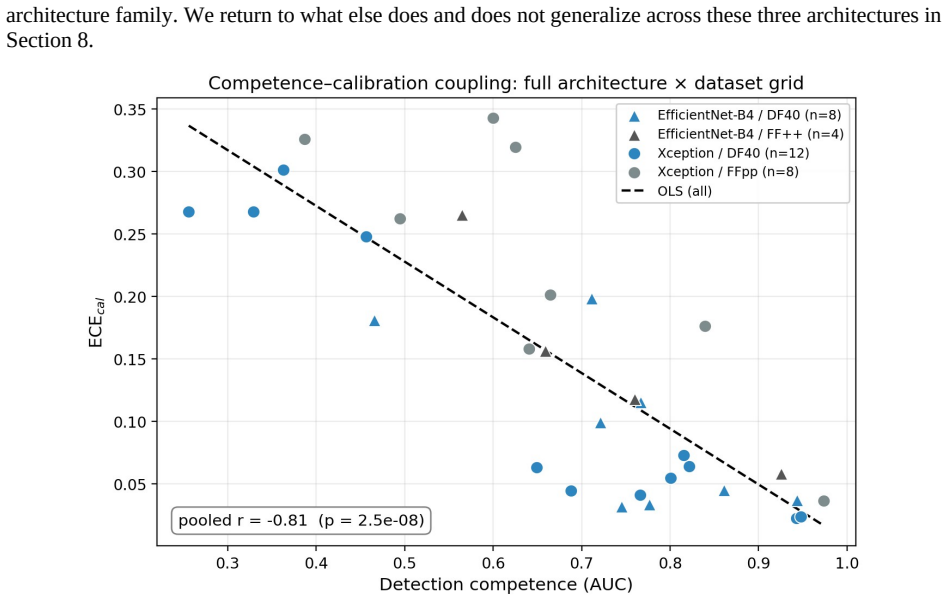
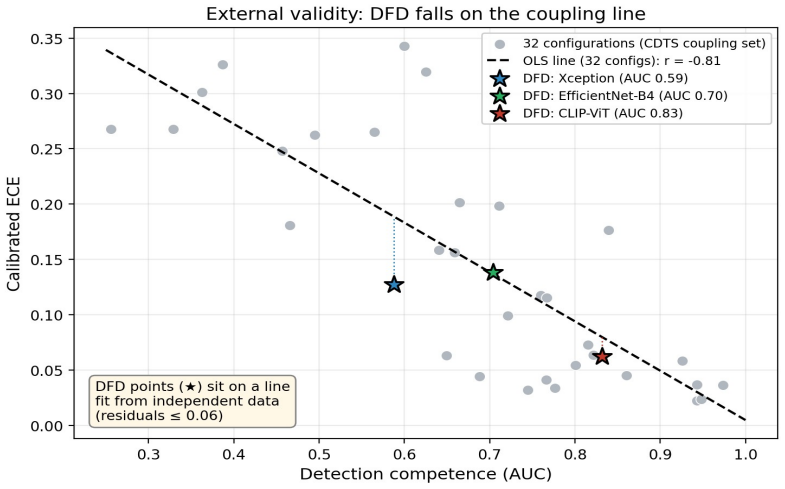
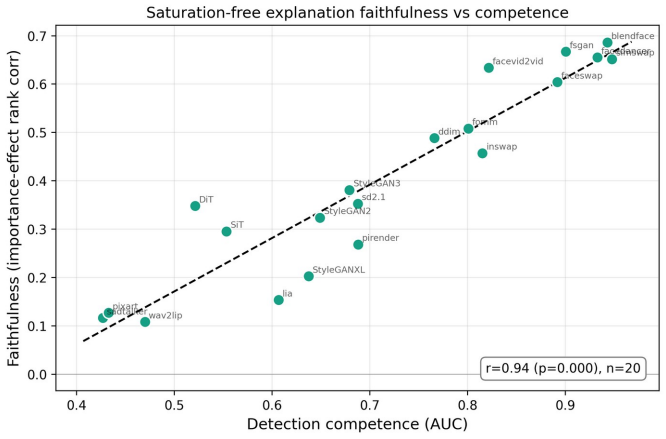
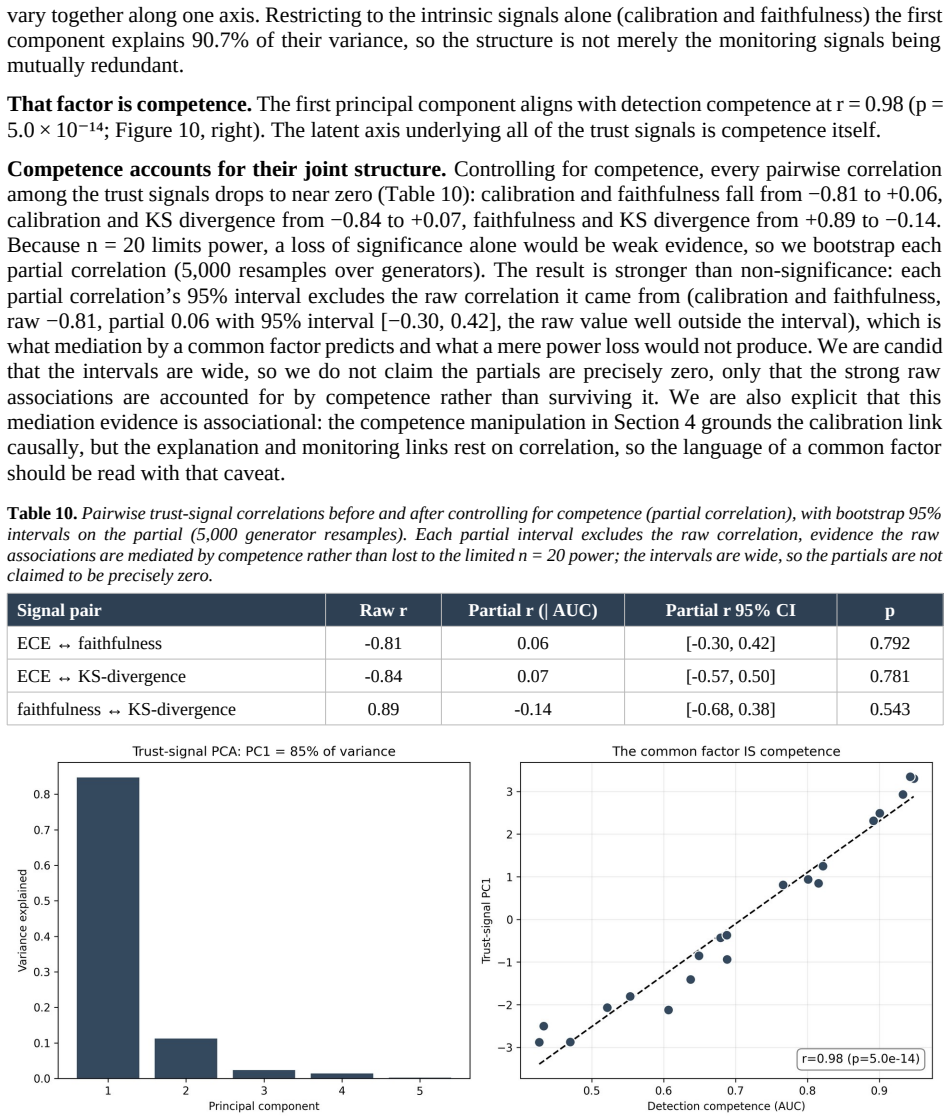
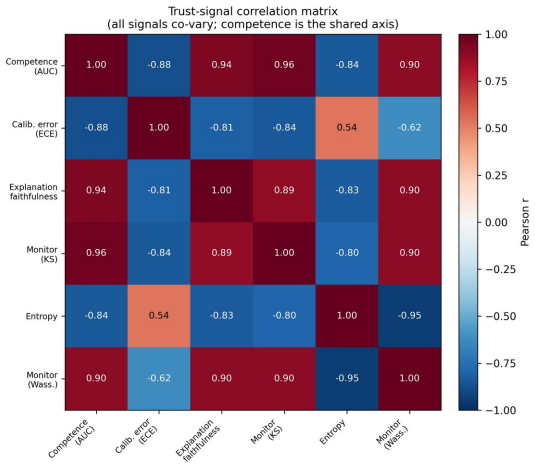
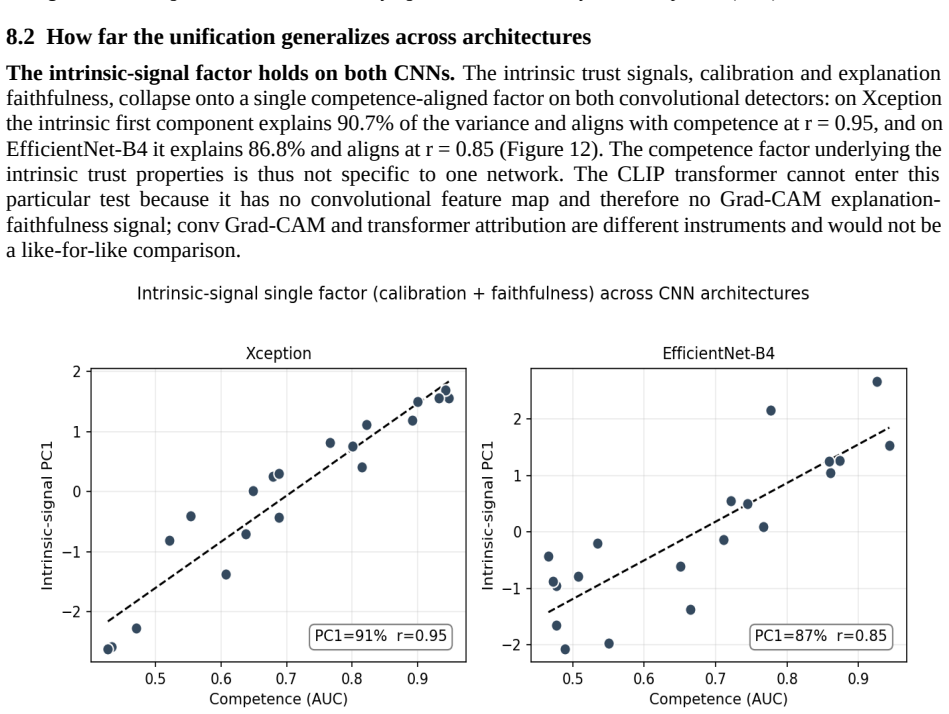
The authors identify a competence-calibration coupling in which the calibration of the trust score degrades as the detector's discriminative competence falls. This relation appears with a pooled Pearson correlation of -0.81 across 32 configurations, persists across three architecturally distinct detectors, and replicates on a fourth held-out dataset.
What carries the argument
The competence-calibration coupling, which organizes detector trustworthiness and is implemented through the Calibrated Deepfake Trust Score wrapper that turns detector output into a self-auditing trust instrument.
If this is right
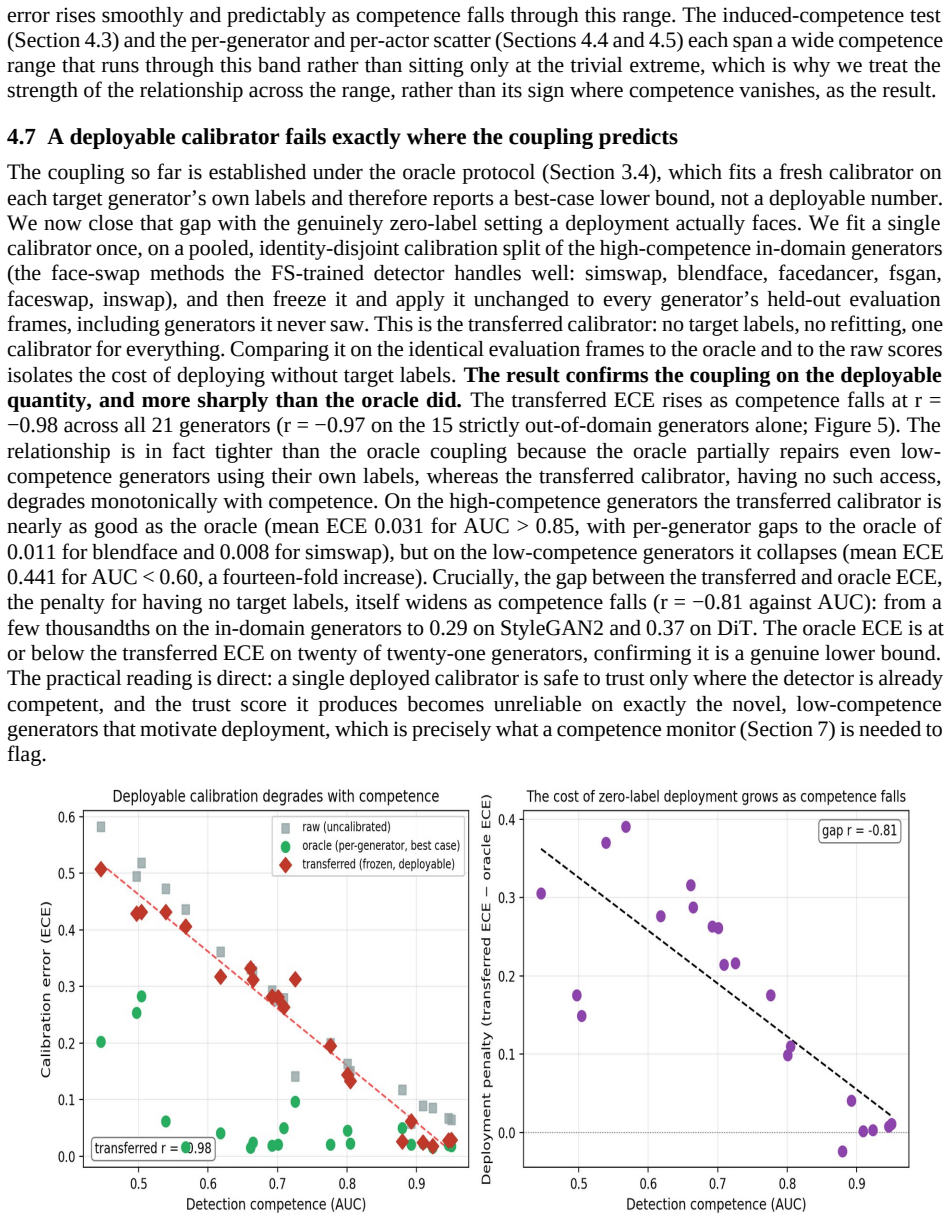
- A single calibrator frozen on in-domain data fails exactly on the low-competence generators the coupling identifies, with its error tracking competence at r = -0.98.
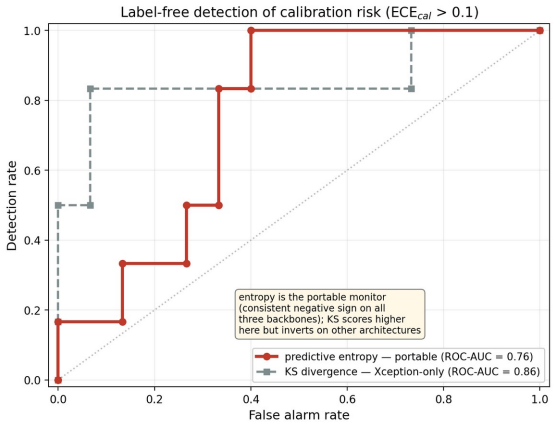
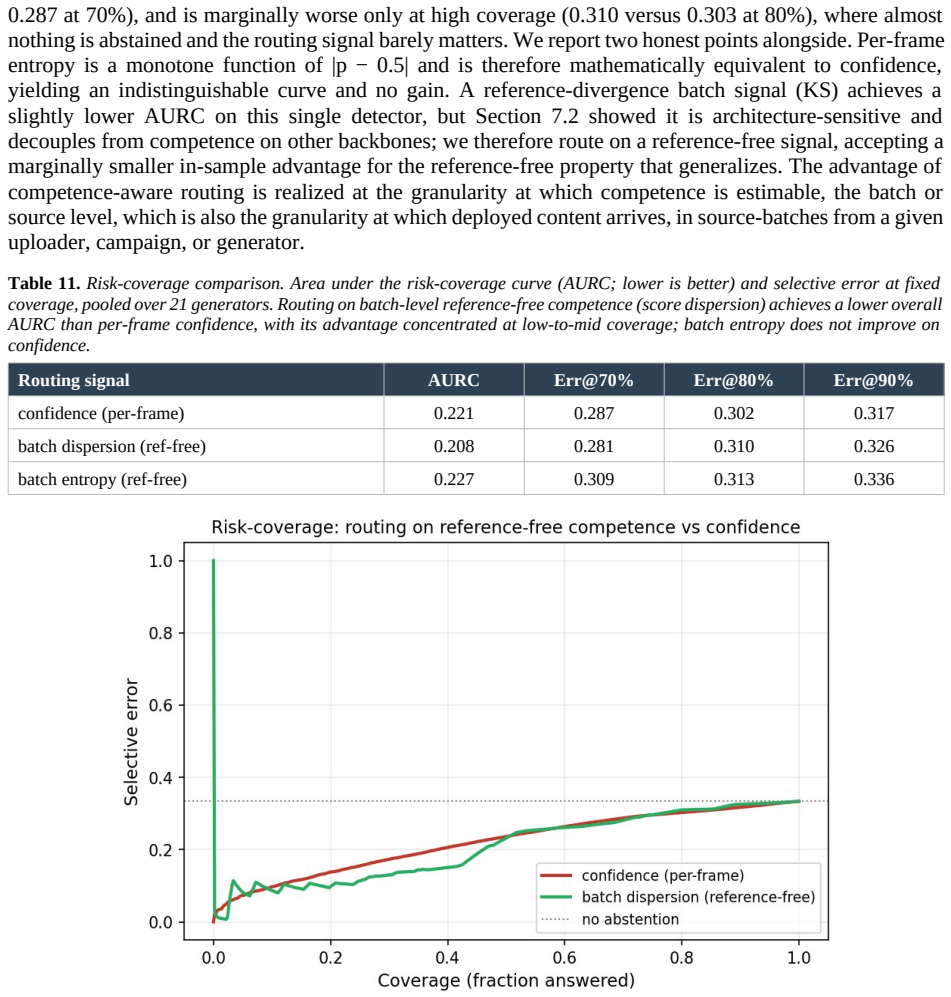
- Competence estimated without labels can flag calibration risk on unseen generators.
- Routing source batches by a reference-free competence estimate lowers overall AURC and improves the low-to-mid coverage region relative to confidence-based routing.
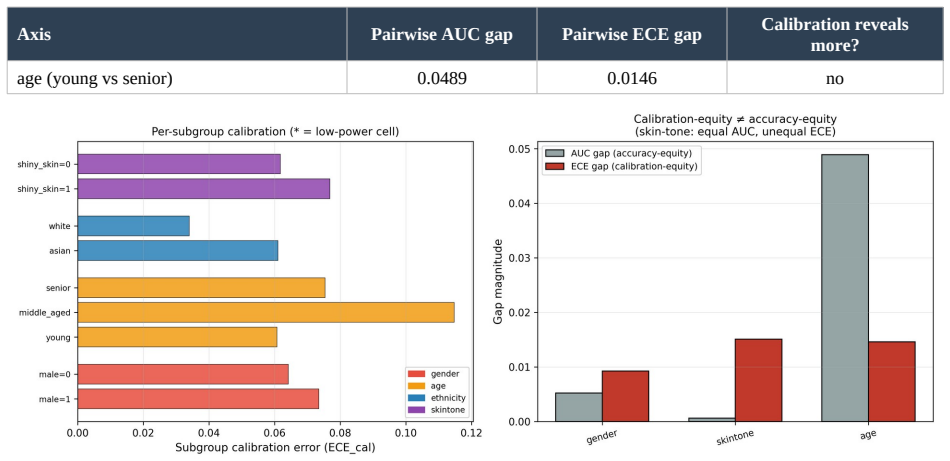
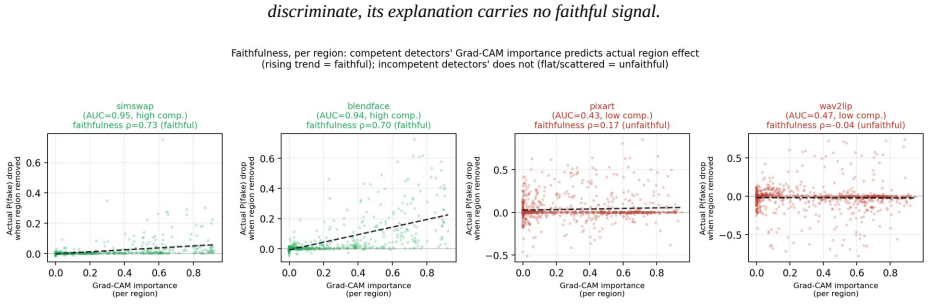
- The same competence factor drives calibration inequity across demographic subgroups and affects explanation faithfulness.
Where Pith is reading between the lines
- The coupling may appear in other classification settings where model probabilities are used as trust or confidence signals.
- One could test whether deliberately lowering competence in unrelated models reproduces the same drop in calibration.
- Extending the analysis to audio or video deepfakes would check whether competence remains the central driver outside image detectors.
Load-bearing premise
The label-free competence estimate remains independent of the calibration metric and is not confounded by dataset-specific artifacts or how competence is measured.
What would settle it
A new experiment on fresh deepfake generators that finds the correlation between measured competence and calibration error is near zero or positive.
Figures

read the original abstract
Modern deepfake detectors are rarely consumed as bare classifiers. In moderation, provenance, and verification pipelines their output probability is read as a degree of trust, so its calibration matters as much as raw accuracy. We reframe deepfake detection as a calibrated, self-auditing trust instrument, the Calibrated Deepfake Trust Score (CDTS), and identify what governs its trustworthiness. Our central finding is a competence-calibration coupling: the calibration of the trust score degrades as the detector's discriminative competence falls. We establish it across 32 configurations (pooled Pearson r = -0.81), demonstrate it within a single dataset, reinforce it by inducing low competence directly, and replicate it on a fourth held-out dataset the detectors never trained on. It holds across three architecturally distinct detectors, two convolutional networks and a CLIP vision transformer (r = -0.88, -0.83, -0.86). The result is also deployable: a single calibrator frozen on in-domain data fails on exactly the low-competence generators the coupling flags (its error tracks competence at r = -0.98), and competence is estimable without labels, so a label-free monitor flags calibration risk on unseen generators and routing source-batches on a reference-free competence estimate lowers overall AURC and improves the low-to-mid coverage operating region relative to confidence-based routing. The same competence factor also drives calibration inequity across demographic subgroups (distinct from accuracy inequity) and explanation faithfulness. We therefore argue that detector trustworthiness is organized by competence as a shared driver, that competence is the right quantity to estimate and condition on, and that trust scoring must be competence-aware. We offer the CDTS wrapper as the mechanism, and report openly where the unification is tight and where it is architecture-specific.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Calibrated Deepfake Trust Score (CDTS) wrapper for deepfake detectors and claims a competence-calibration coupling: calibration of the trust score degrades as the detector's discriminative competence falls. This is established across 32 configurations (pooled Pearson r = -0.81), holds across three architecturally distinct detectors (r = -0.88, -0.83, -0.86), is reinforced by direct induction of low competence, and replicated on a held-out dataset never seen in training. The result is presented as deployable via a frozen calibrator whose error tracks competence at r = -0.98, with label-free competence estimation enabling routing that improves AURC and addressing calibration inequity across demographics.
Significance. If the independence of the label-free competence proxy from the calibration metric is demonstrated, the result would be significant for trust scoring in deepfake moderation and verification pipelines by identifying competence as a shared driver of calibration, inequity, and explanation faithfulness. The manuscript earns credit for its multiple replications, held-out dataset test, direct competence induction, and open reporting of where the unification is tight versus architecture-specific.
major comments (2)
- [Abstract] Abstract: The central claim of a competence-calibration coupling (pooled r = -0.81) depends on the label-free competence estimate being independent of the calibration metric (Brier score, ECE, or reliability diagrams). The abstract asserts independence and generalization to unseen generators but supplies no operational definition, ablation, or proof of orthogonality; if the proxy shares detector output statistics with the calibration error, the observed correlation can arise mechanically rather than reflect an independent property.
- [Replication and held-out test sections] The held-out dataset replication and low-competence induction: while these are presented as strengthening the result, the manuscript must explicitly show that the competence proxy construction and the calibration error computation remain independent under these interventions; without this, the r = -0.98 tracking by the frozen calibrator does not resolve the potential circularity for the generalization claim.
minor comments (2)
- [Abstract] The abstract introduces the CDTS but could more explicitly state its mathematical formulation as a wrapper (e.g., how the calibrated probability is computed from the base detector output) before discussing empirical results.
- [Results tables/figures] Table or figure reporting the per-detector r values (-0.88, -0.83, -0.86) should include exact sample sizes and confidence intervals to allow assessment of the pooled r = -0.81.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on the need to explicitly demonstrate independence of the label-free competence proxy from calibration metrics. We address each point below and will revise the manuscript accordingly to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a competence-calibration coupling (pooled r = -0.81) depends on the label-free competence estimate being independent of the calibration metric (Brier score, ECE, or reliability diagrams). The abstract asserts independence and generalization to unseen generators but supplies no operational definition, ablation, or proof of orthogonality; if the proxy shares detector output statistics with the calibration error, the observed correlation can arise mechanically rather than reflect an independent property.
Authors: We agree that the manuscript would benefit from an explicit operational definition and ablation to rule out mechanical correlations arising from shared detector output statistics. The current abstract relies on the label-free construction of the proxy (which uses no ground-truth labels, unlike Brier/ECE) to claim independence, but does not provide the requested ablations or orthogonality tests. In revision we will add a dedicated methods subsection with the proxy definition and an ablation that orthogonalizes the proxy from output statistics before recomputing the pooled correlation with calibration error. revision: yes
-
Referee: [Replication and held-out test sections] The held-out dataset replication and low-competence induction: while these are presented as strengthening the result, the manuscript must explicitly show that the competence proxy construction and the calibration error computation remain independent under these interventions; without this, the r = -0.98 tracking by the frozen calibrator does not resolve the potential circularity for the generalization claim.
Authors: We concur that explicit independence checks are required under the held-out dataset and direct competence-induction settings to support the generalization and frozen-calibrator claims. The manuscript does not currently include these targeted verifications. In the revised version we will expand the relevant sections with partial-correlation analyses and independence tests between proxy and calibration error under each intervention, confirming that the r = -0.98 tracking is not due to circularity. revision: yes
Circularity Check
No significant circularity; empirical correlations reported as independent measurements
full rationale
The paper reports observed Pearson correlations (pooled r = -0.81 across 32 configurations, with per-detector values -0.88/-0.83/-0.86) between a label-free competence estimate and calibration degradation metrics. It further states that a frozen calibrator's error tracks competence at r = -0.98 and that competence is estimable without labels, with replication on held-out data. No equations, definitions, or self-citations are supplied in the provided text that reduce the competence proxy to the calibration error (or vice versa) by construction. The central claims rest on statistical associations across detectors and datasets rather than definitional equivalence or fitted-input renaming. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Pearson correlation is an appropriate measure for the relationship between competence and calibration degradation
invented entities (1)
-
CDTS
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Brown, R., & Russell, C. (2026). Face-Feature Tuning: Post-hoc calibration for fair and accurate deepfake detection. International Conference on Learning Representations (ICLR). Face-Fairness (FF). Chandra, N. A., Murtfeldt, R., Qiu, L., Karmakar, A., Lee, H., Tanumihardja, E., Farhat, K., Caffee, B., Paik, S., Lee, C., Choi, J., Kim, A., & Etzioni, O. (2...
2026
-
[2]
Deepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024
arXiv preprint. arXiv:2503.02857. Chollet, F. (2017). Xception: Deep learning with depthwise separable convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1251–1258. DeYoung, J., Jain, S., Rajani, N. F., Lehman, E., Xiong, C., Socher, R., & Wallace, B. C. (2020). ERASER: A benchmark to evaluate rationalized ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s44267-025-00100-2 2017
-
[3]
DiCE. Nadimpalli, A. V., & Rattani, A. (2022). GBDF: Gender balanced DeepFake dataset towards fair DeepFake detection. arXiv preprint. arXiv:2207.10246. Platt, J. (1999). Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in Large Margin Classifiers, 61–74. Radford, A., Kim, J. W., Hallacy, C., Ra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.