FASE: Fast Adaptive Semantic Entropy for Code Quality
Pith reviewed 2026-06-27 15:16 UTC · model grok-4.3
The pith
FASE approximates functional correctness of generated code using minimum spanning trees on dissimilarity graphs, delivering 25% better correlation to ground truth at 0.3% of the computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FASE approximates functional correctness based on the minimum spanning tree of structural and semantic dissimilarity graphs. When using the Qwen3-Embedding-8B model, it achieves a 25% average improvement in Spearman correlation and a 19% increase in ROCAUC score against Pass@1 from ground-truth test cases, while requiring only approximately 0.3% of the runtime cost of traditional semantic entropy approaches.
What carries the argument
Minimum spanning tree of structural and semantic dissimilarity graphs built from embeddings, which groups code outputs into approximate functional equivalence classes without LLM entailment checks.
If this is right
- FASE can replace costly semantic entropy calculations in multi-agent workflows for better reliability.
- It enables faster uncertainty quantification for optimizing code generation agents.
- Improved metrics allow better detection of hallucinations in LLM-generated code.
- Scales to larger benchmarks like BigCodeBench with minimal overhead.
Where Pith is reading between the lines
- The method could extend to other domains beyond code, such as natural language generation where equivalence is hard to check.
- Combining FASE with other cheap metrics might further improve accuracy without added cost.
- Testing on more diverse LLMs beyond Qwen3-Embedding-8B would validate generalizability.
Load-bearing premise
The minimum spanning tree from embedding-based dissimilarity graphs accurately captures the same functional equivalence groups that LLM entailment checks would identify.
What would settle it
Run both FASE and traditional LLM-entailment semantic entropy on the same set of code samples and measure how often their equivalence groupings differ; if they frequently disagree on which outputs are equivalent, the approximation fails.
Figures
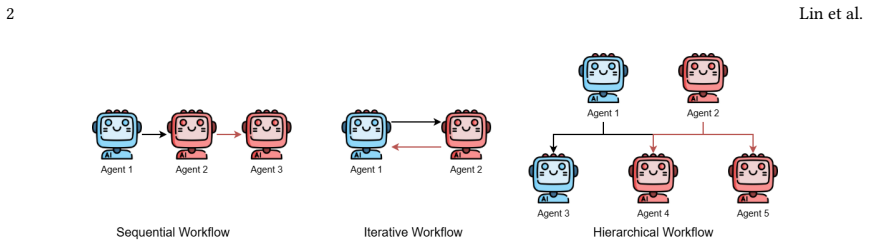
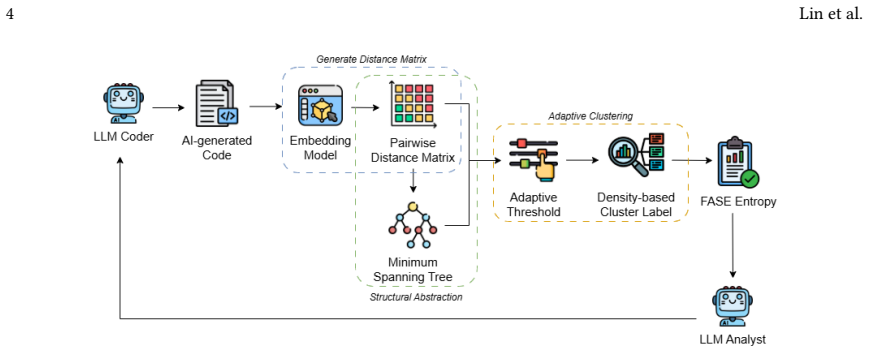
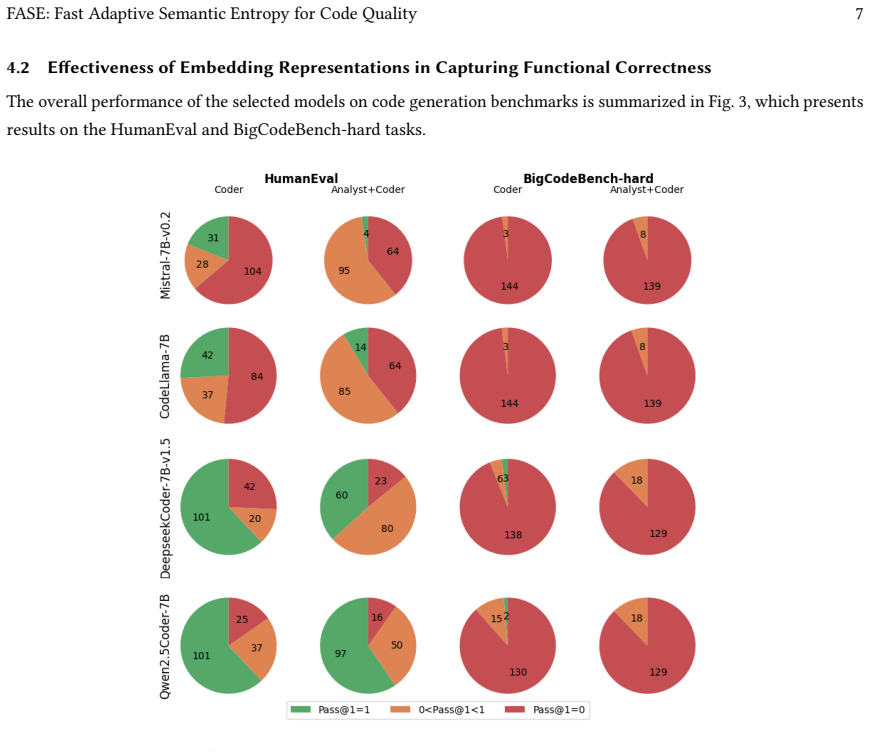
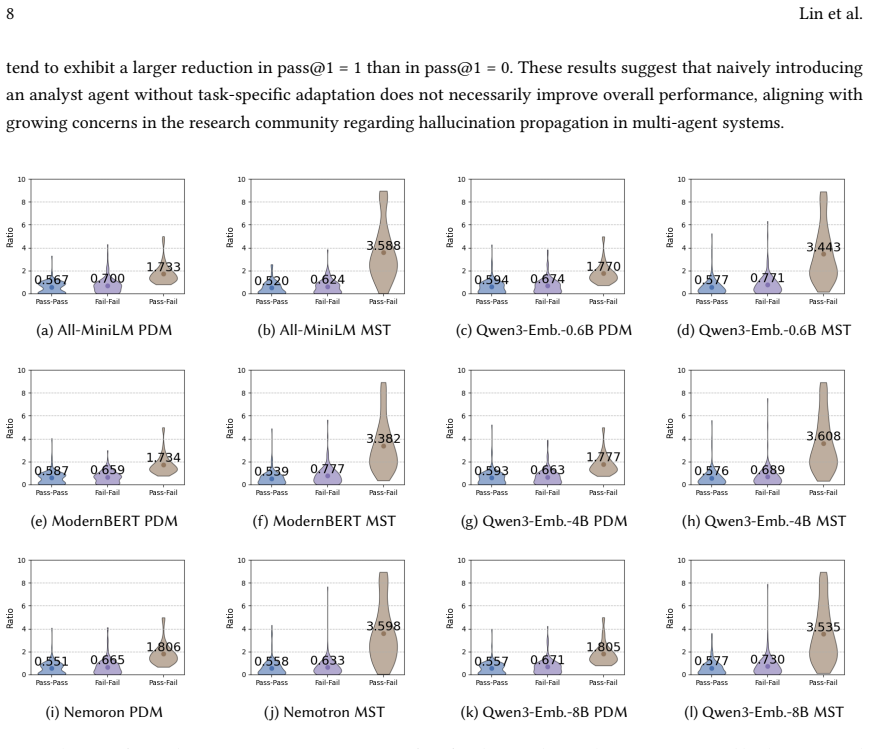
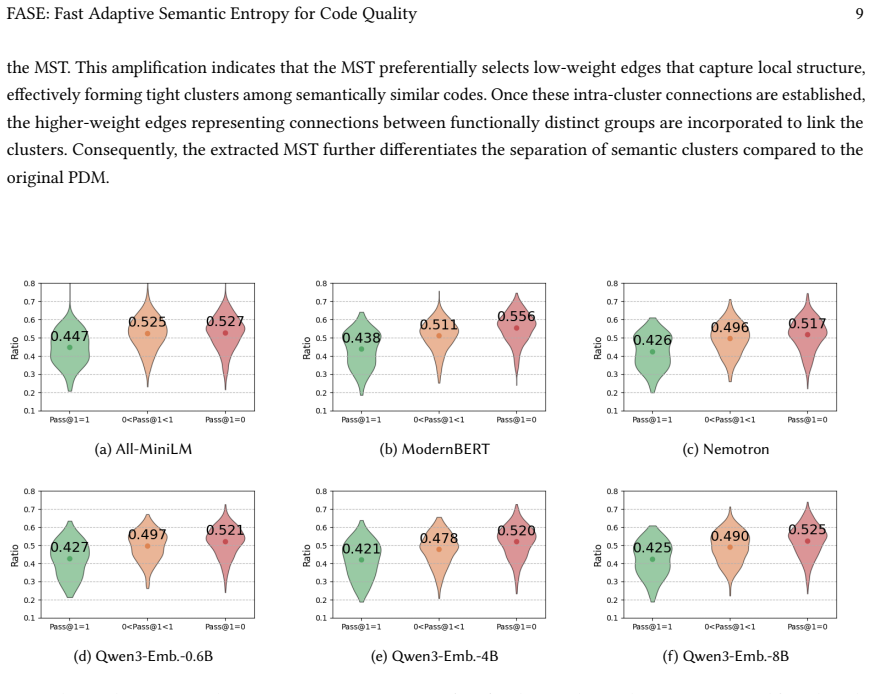
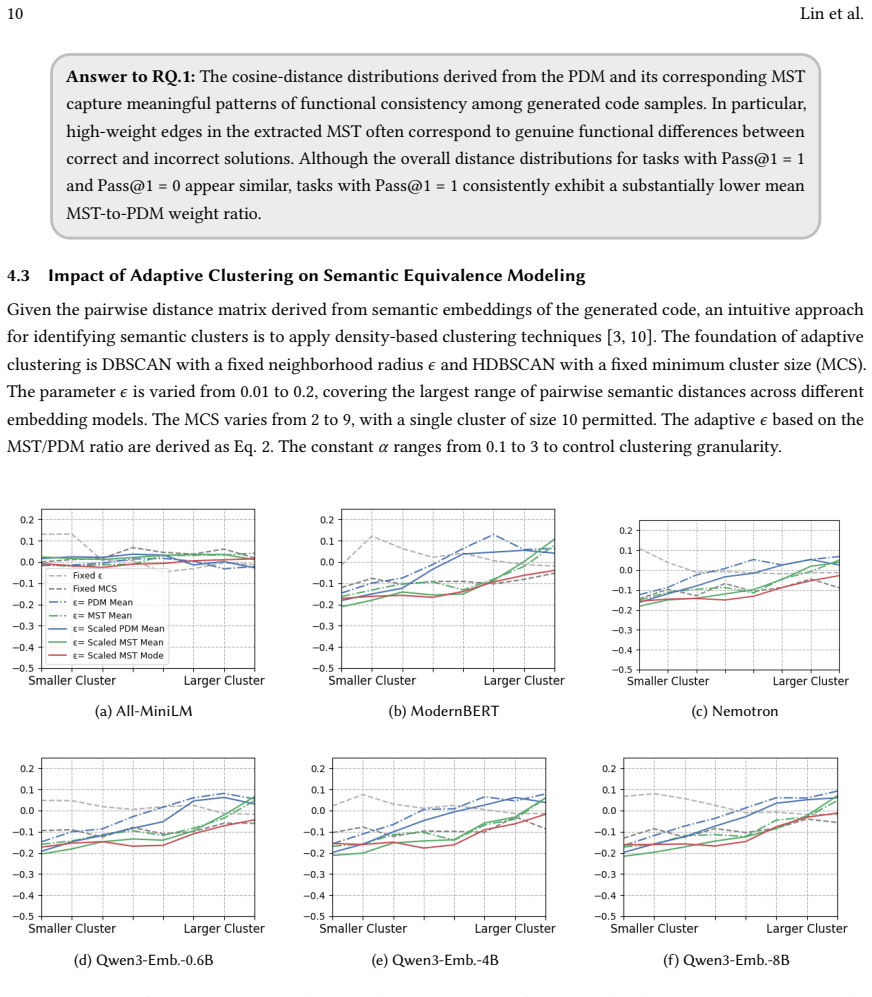
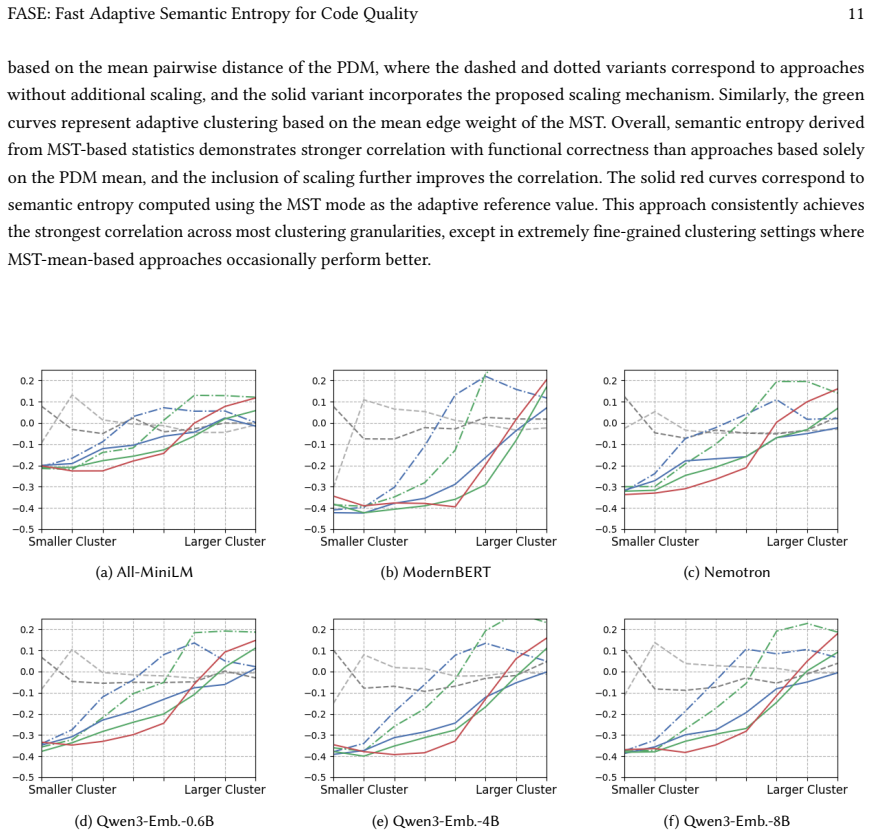
read the original abstract
Multi-agent code generation offers a promising paradigm for autonomous software development by simulating the human software engineering lifecycle. However, system reliability remains hindered by LLM hallucinations and error propagation across interacting agents. While semantic entropy provides a principled way to quantify uncertainty without ground-truth answers, current methods often rely on costly LLM-driven equivalence checks. In this work, we introduce Fast Adaptive Semantic Entropy (FASE), a novel metric that approximates functional correctness based on the minimum spanning tree of structural and semantic dissimilarity graphs. Evaluations on HumanEval and BigCodeBench demonstrate that FASE outperforms state-of-the-art semantic entropy by LLM entailment, achieving a 25% average improvement in Spearman correlation and a 19% increase in ROCAUC score against Pass@1 from ground-truth test cases when using the Qwen3-Embedding-8B model. Furthermore, by eliminating costly LLM-driven equivalence evaluation, FASE incurs negligible computational overhead, requiring only approximately 0.3% of the runtime cost of traditional semantic entropy approaches. These results position FASE as a practical, cost-effective solution for optimizing uncertainty quantification in real-world multi-agent workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Fast Adaptive Semantic Entropy (FASE), which approximates functional correctness and semantic entropy for LLM-generated code via minimum spanning trees computed on structural and semantic dissimilarity graphs built from embeddings. On HumanEval and BigCodeBench it reports a 25% average improvement in Spearman correlation and 19% increase in ROCAUC (vs. Pass@1) over LLM-entailment semantic entropy while using only ~0.3% of the runtime, positioning FASE as a low-cost alternative for multi-agent code generation uncertainty quantification.
Significance. If the core approximation is validated, FASE would supply a practical, scalable substitute for expensive LLM-based equivalence checks in uncertainty estimation for code, directly addressing reliability issues in multi-agent workflows. The efficiency claim is notable and the embedding-based proxy idea is a reasonable direction, but the significance hinges on whether the MST clusters faithfully stand in for entailment-derived functional equivalence classes.
major comments (3)
- [Evaluation / Results] The central claim that FASE MST clusters reliably approximate the functional equivalence classes obtained by LLM-driven entailment checks is load-bearing, yet the manuscript provides no quantitative agreement metric (adjusted Rand index, pairwise match rate, or similar) between the two partitions. All reported gains are measured only against ground-truth Pass@1, leaving open the possibility that FASE captures a different signal.
- [Method / §3] Graph construction details are underspecified: the exact definitions of structural vs. semantic dissimilarity, the dissimilarity threshold for including edges, and the weight used to balance the two dissimilarity types are not stated (these appear among the free parameters). Without these, the method cannot be reproduced and the reported improvements cannot be assessed for robustness.
- [Experiments] Statistical significance, confidence intervals, and controls for confounds (model choice, benchmark subset, embedding model) are not reported for the 25% Spearman and 19% ROCAUC figures, making it impossible to judge whether the gains are reliable or driven by particular experimental choices.
minor comments (1)
- [Abstract] The abstract states quantitative improvements but omits any mention of the missing validation or parameter details; a short clarification sentence would help readers.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation / Results] The central claim that FASE MST clusters reliably approximate the functional equivalence classes obtained by LLM-driven entailment checks is load-bearing, yet the manuscript provides no quantitative agreement metric (adjusted Rand index, pairwise match rate, or similar) between the two partitions. All reported gains are measured only against ground-truth Pass@1, leaving open the possibility that FASE captures a different signal.
Authors: We agree that reporting a direct agreement metric between FASE-derived clusters and LLM-entailment partitions would strengthen the approximation claim. While the primary validation remains correlation with ground-truth functional correctness via Pass@1 (as this is the target signal for uncertainty quantification), we will add adjusted Rand index and pairwise agreement rates in the revised evaluation section. revision: yes
-
Referee: [Method / §3] Graph construction details are underspecified: the exact definitions of structural vs. semantic dissimilarity, the dissimilarity threshold for including edges, and the weight used to balance the two dissimilarity types are not stated (these appear among the free parameters). Without these, the method cannot be reproduced and the reported improvements cannot be assessed for robustness.
Authors: We acknowledge the underspecification. The revised manuscript will include precise mathematical definitions of the structural and semantic dissimilarity functions, the edge inclusion threshold, and the balancing weight hyperparameter, along with the specific values employed in all reported experiments. revision: yes
-
Referee: [Experiments] Statistical significance, confidence intervals, and controls for confounds (model choice, benchmark subset, embedding model) are not reported for the 25% Spearman and 19% ROCAUC figures, making it impossible to judge whether the gains are reliable or driven by particular experimental choices.
Authors: We will augment the experimental results with statistical significance tests (e.g., paired t-tests or Wilcoxon tests), bootstrap confidence intervals, and additional ablation controls varying the LLM, benchmark subsets, and embedding models to demonstrate robustness of the reported gains. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines FASE directly via construction of dissimilarity graphs from embeddings followed by MST computation, then reports empirical Spearman/ROCAUC correlations against independent ground-truth Pass@1 from test cases. No equations, fitted parameters, or self-citations are shown that would make the reported improvements reduce to the inputs by construction. The metric and its evaluation stand as an independent proposal without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- weight balancing structural vs semantic dissimilarity
- dissimilarity threshold for graph edges
axioms (1)
- domain assumption Structural and semantic dissimilarity graphs capture information relevant to functional equivalence of code
Reference graph
Works this paper leans on
- [1]
-
[2]
Babakhin, Y., Osmulski, R., Ak, R., Moreira, G., Xu, M., Schifferer, B., Liu, B., and Oldridge, E.Llama-embed-nemotron-8b: A universal text embedding model for multilingual and cross-lingual tasks, 2025
2025
-
[3]
J., Moulavi, D., and Sander, J.Density-based clustering based on hierarchical density estimates
Campello, R. J., Moulavi, D., and Sander, J.Density-based clustering based on hierarchical density estimates. InPacific-Asia conference on knowledge discovery and data mining(2013), Springer, pp. 160–172
2013
-
[4]
Cao, D., Hong, Y., Pan, Q., and Wu, J.Program interoperable large language model software testing scheme: a case study on javascript engine fuzzing.IEEE Transactions on Dependable and Secure Computing(2025)
2025
-
[5]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al.Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Chen, X., Liu, J., Zhang, Y., Hu, Q., Han, Y., Zhang, R., Ran, J., Yan, L., Huang, B., and Ma, S.Traceawareness and dual-strategy fuzz testing: Enhancing path coverage and crash localization with stochastic science and large language models.Computers and Electrical Engineering 123(2025), 110266
2025
-
[7]
Das, S., Deb, N., Chaki, N., and Cortesi, A.A multi-agent rag framework for regulatory compliance checking of software requirements.ACM Transactions on Software Engineering and Methodology(2025)
2025
-
[8]
Dong, Y., Jiang, X., Jin, Z., and Li, G.Self-collaboration code generation via chatgpt.ACM Transactions on Software Engineering and Methodology 33, 7 (2024), 1–38
2024
- [9]
-
[10]
In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining(1996), vol
Ester, M., Kriegel, H.-P., Sander, J., Xu, X., et al.A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining(1996), vol. 96, pp. 226–231
1996
-
[11]
K.Llm-based test-driven interactive code generation: User study and empirical evaluation.IEEE Transactions on Software Engineering 50, 9 (2024), 2254–2268
Fakhoury, S., Naik, A., Sakkas, G., Chakraborty, S., and Lahiri, S. K.Llm-based test-driven interactive code generation: User study and empirical evaluation.IEEE Transactions on Software Engineering 50, 9 (2024), 2254–2268
2024
-
[12]
Farqhar, S., Kossen, J., Kuhn, L., and Gal, Y.Detecting hallucinations in large language models using semantic entropy.Nature 630, 8017 (2024), 625–630
2024
-
[13]
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
Ferrag, M. A., Tihanyi, N., and Debbah, M.From llm reasoning to autonomous ai agents: A comprehensive review.arXiv preprint arXiv:2504.19678 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
-
[15]
Gagolewski, M., Cena, A., Bartoszuk, M., and Brzozowski, Ł.Clustering with minimum spanning trees: How good can it be?Journal of Classification 42, 1 (2025), 90–112
2025
-
[16]
Guo, D., Zhu, Q., Y ang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y., Li, Y., et al.Deepseek-coder: When the large language model meets programming–the rise of code intelligence.arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
He, J., Treude, C., and Lo, D.Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead.ACM Transactions on Software Engineering and Methodology 34, 5 (2025), 1–30
2025
-
[18]
InProceedings of the International Conference on Learning Representations(2024), vol
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Wang, J., Zhang, C., Yau, S., Lin, Z., Zhou, L., et al.Metagpt: Meta programming for a multi-agent collaborative framework. InProceedings of the International Conference on Learning Representations(2024), vol. 2024, pp. 23247–23275
2024
-
[19]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., W ang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al.A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems 43, 2 (2025), 1–55
2025
-
[20]
Qwen2.5-Coder Technical Report
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al.Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Ji, Z., Yu, T., Xu, Y., Lee, N., Ishii, E., and Fung, P.Towards mitigating llm hallucination via self reflection. InFindings of the Association for Computational Linguistics(2023), pp. 1827–1843. [22]Jiang, A. Q., Sablayrolles, A., Nadeau, N., Usunier, N., and Lample, G.Mistral 7b.arXiv preprint arXiv:2310.06825(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al.Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
G., Mohamad, M., and Leitner, P.The impact of prompt programming on function-level code generation.IEEE Transactions on Software Engineering(2025)
Khojah, R., de Oliveira Neto, F. G., Mohamad, M., and Leitner, P.The impact of prompt programming on function-level code generation.IEEE Transactions on Software Engineering(2025)
2025
-
[24]
Kuhn, L., Gal, Y., and Farqhar, S.Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
[27]Lindley, D
Liao, D., Pan, S., Sun, X., Ren, X., Huang, Q., Xing, Z., Jin, H., and Li, Q.A3-codgen: A repository-level code generation framework for code reuse with local-aware, global-aware, and third-party-library-aware.IEEE Transactions on Software Engineering 50, 12 (2024), 3369–3384. [27]Lindley, D. V.On a measure of the information provided by an experiment.The...
2024
-
[26]
Liu, F., Liu, Y., Shi, L., Huang, H., W ang, R., Y ang, Z., Zhang, L., Li, Z., and Ma, Y.Exploring and evaluating hallucinations in llm-powered code generation.arXiv preprint arXiv:2404.00971(2024). [29]Liu, F., Liu, Y., Shi, L., Y ang, Z., Zhang, L., Lian, X., Li, Z., and Ma, Y.Beyond functional correctness: Exploring hallucinations in llm-generated code...
-
[27]
18 Lin et al
Liu, J., Wang, K., Chen, Y., Peng, X., Chen, Z., Zhang, L., and Lou, Y.Large language model-based agents for software engineering: A survey. 18 Lin et al. ACM Transactions on Software Engineering and Methodology(2024)
2024
-
[28]
InProceedings of the 45th International Conference on Software Engineering(2023), IEEE, pp
Liu, J., Zeng, J., W ang, X., and Liang, Z.Learning graph-based code representations for source-level functional similarity detection. InProceedings of the 45th International Conference on Software Engineering(2023), IEEE, pp. 345–357
2023
-
[29]
D., and Lo, D.Refining chatgpt-generated code: Characterizing and mitigating code quality issues.ACM Transactions on Software Engineering and Methodology 33, 5 (2024), 1–26
Liu, Y., Le-Cong, T., Widyasari, R., Tantithamthavorn, C., Li, L., Le, X.-B. D., and Lo, D.Refining chatgpt-generated code: Characterizing and mitigating code quality issues.ACM Transactions on Software Engineering and Methodology 33, 5 (2024), 1–26
2024
-
[30]
F.No need to lift a finger anymore? assessing the quality of code generation by chatgpt.IEEE Transactions on Software Engineering 50, 6 (2024), 1548–1584
Liu, Z., Tang, Y., Luo, X., Zhou, Y., and Zhang, L. F.No need to lift a finger anymore? assessing the quality of code generation by chatgpt.IEEE Transactions on Software Engineering 50, 6 (2024), 1548–1584
2024
-
[31]
InFirst Conference on Language Modeling(2024)
Liu, Z., Zhang, Y., Li, P., Liu, Y., and Y ang, D.A dynamic llm-powered agent network for task-oriented agent collaboration. InFirst Conference on Language Modeling(2024)
2024
-
[32]
Maveli, N., Vergari, A., and Cohen, S. B.What can large language models capture about code functional equivalence?arXiv preprint arXiv:2408.11081(2024)
-
[33]
InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Mohammadi, M., Li, Y., Lo, J., and Yip, W.Evaluation and benchmarking of llm agents: A survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2(2025), pp. 6129–6139
2025
- [34]
-
[35]
Code Llama: Open Foundation Models for Code
Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y., Liu, J., Sauvestre, R., Remez, T., et al.Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Multi-Agent Collaboration: Harnessing the Power of Intelligent LLM Agents
Song, Y., Sun, T., Tang, X., Rajput, P. K., Bissyandé, T. F., and Klein, J.Measuring llm code generation stability via structural entropy. In Proceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering(2025), IEEE, pp. 3922–3926. [40]Talebirad, Y., and Nadiri, A.Multi-agent collaboration: Harnessing the power of intelligent...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Wang, G., Xu, Q., Briand, L., and Liu, K.Mutation-guided unit test generation with a large language model.IEEE Transactions on Software Engineering(2026)
2026
-
[38]
W ang, W., Wei, F., Dong, L., Bao, H., Y ang, N., and Zhou, M.Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems 33(2020), 5776–5788
2020
- [39]
-
[40]
Xu, Q., W ang, G., Briand, L., and Liu, K.Hallucination to consensus: Multi-agent llms for end-to-end junit test generation.ACM Transactions on Software Engineering and Methodology(2026)
2026
-
[41]
Y ang, B., Dang, J., Liu, H., and Jin, Z.Advancing llm-generated code reliability: A hybrid approach for hallucination detection.IEEE Transactions on Software Engineering(2025)
2025
-
[42]
Survey on Evaluation of LLM-based Agents
Yehudai, A., Eden, L., Li, A., Uziel, G., Zhao, Y., Bar-Haim, R., Cohan, A., and Shmueli-Scheuer, M.Survey on evaluation of llm-based agents. arXiv preprint arXiv:2503.16416(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track(2024), pp
Zhang, X., Zhang, Y., Long, D., Xie, W., Dai, Z., Tang, J., Lin, H., Yang, B., Xie, P., Huang, F., et al.mgte: Generalized long-context text representation and reranking models for multilingual text retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track(2024), pp. 1393–1412
2024
-
[44]
Zhang, Y., Li, M., Long, D., Zhang, X., Lin, H., Y ang, B., Xie, P., Y ang, A., Liu, D., Lin, J., Huang, F., and Zhou, J.Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Zhang, Y., Li, Y., Cui, L., Cai, D., Liu, L., Fu, T., Huang, X., Zhao, E., Zhang, Y., Chen, Y., et al.Siren’s song in the ai ocean: A survey on hallucination in large language models.Computational Linguistics(2025), 1–46
2025
-
[46]
Zhang, Z., Wang, C., Wang, Y., Shi, E., Ma, Y., Zhong, W., Chen, J., Mao, M., and Zheng, Z.Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation.ACM on Software Engineering 2, ISSTA022 (2025), 481–503
2025
-
[47]
InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(2023), pp
Zheng, Q., Xia, X., Zou, X., Dong, Y., Wang, S., Xue, Y., Shen, L., Wang, Z., Wang, A., Li, Y., et al.Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(2023), pp. 5673–5684
2023
- [48]
-
[49]
Zhu, Y., Liu, C., He, X., Ren, X., Liu, Z., Pan, R., and Zhang, H.Adacoder: An adaptive planning and multi-agent framework for function-level code generation.IEEE Transactions on Software Engineering(2025)
2025
-
[50]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Zhuo, T. Y., Vu, M. C., Chim, J., Hu, H., Yu, W., Widyasari, R., Yusuf, I. N. B., Zhan, H., He, J., Paul, I., et al.Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions.arXiv preprint arXiv:2406.15877(2024). Received 5 June 2026
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.