The Role of Ambiguity in Error Prediction via Uncertainty Quantification
Pith reviewed 2026-06-28 14:43 UTC · model grok-4.3
The pith
Ambiguity labels improve error prediction scores for LLMs by separating input uncertainty from other signals in UQ metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
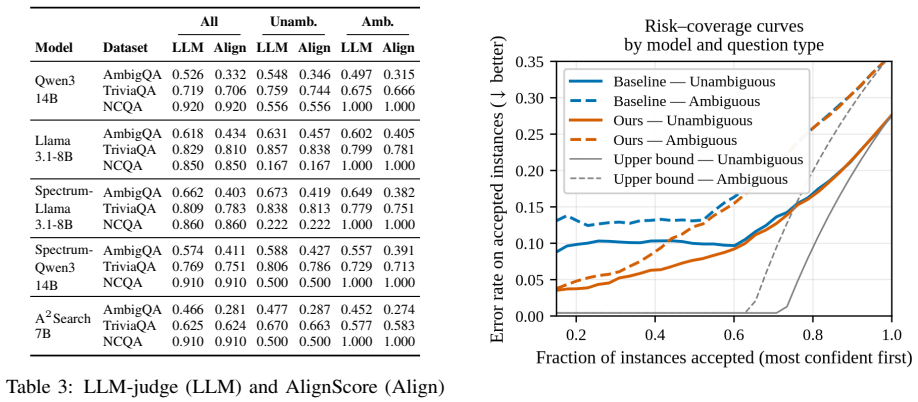
Disentangling input ambiguity from the UQ signal allows standard uncertainty metrics to more accurately predict whether an LLM output is correct; incorporating either gold or predicted ambiguity labels via gated experts and selective prediction produces consistent gains of over 10 PRR points on error prediction across six UQ metrics, multiple model families, and standard QA datasets.
What carries the argument
Gated Experts and Selective Prediction applied to gold or predicted ambiguity labels to isolate aleatoric uncertainty before error prediction with UQ metrics.
If this is right
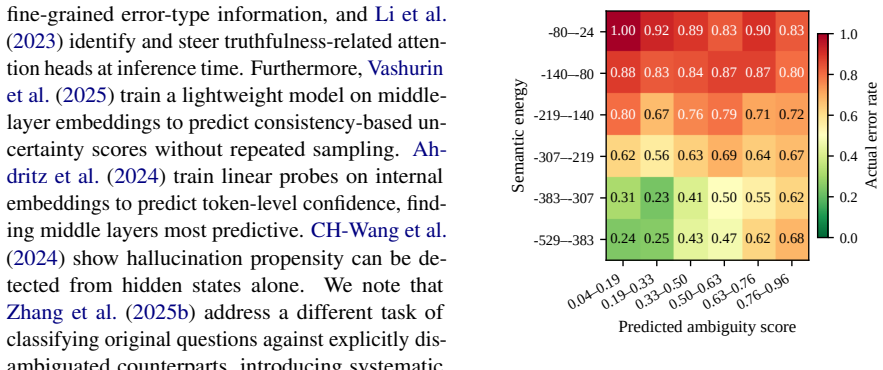
- UQ metrics exhibit higher error-prediction power on unambiguous instances than on those with multiple plausible answers.
- The same ambiguity-augmented pipeline improves scores across model families, training paradigms, and sources of aleatoric uncertainty.
- Gains exceed 10 PRR points for individual UQ metrics even on datasets previously viewed as unambiguous.
- Predicted ambiguity labels, not only gold labels, suffice to obtain the reported improvements.
Where Pith is reading between the lines
- Error prediction systems could treat ambiguity as a distinct, measurable input property rather than folding it into a single uncertainty score.
- Selective prediction thresholds might be adjusted dynamically according to detected ambiguity levels in addition to UQ values.
- The separation of ambiguity from other uncertainty sources may generalize to tasks outside QA where multiple valid outputs exist.
Load-bearing premise
Gold-standard and predicted ambiguity labels can be obtained reliably and added to the pipeline without introducing substantial new selection bias or label noise that erases the reported gains.
What would settle it
A replication in which adding predicted ambiguity labels produces no PRR improvement on held-out data, or in which the reported gains disappear once ambiguity annotation noise exceeds a low threshold.
Figures

read the original abstract
The task of Error Prediction, namely predicting whether a model output is correct, is commonly tackled with Uncertainty Quantification (UQ). However, while uncertainty metrics capture when models lack knowledge or capacity to make a prediction, they also reflect aleatoric uncertainty, which is inherent in the model input and context. This paper presents a method for improving error prediction for Large Language Models (LLMs), by disentangling input ambiguity from UQ signal. We conduct experiments on the task of Question Answering (QA) with six UQ metrics and show that UQ metrics are more predictive of errors on unambiguous instances than on questions with multiple plausible answers. We use Gated Experts and Selective Prediction to incorporate gold and predicted ambiguity labels into the error prediction pipeline. We find that ambiguity information improves error prediction scores across model families, training and evaluation paradigms, datasets (including allegedly unambiguous ones), and sources of aleatoric uncertainty, yielding improvements of over 10 points of PRR for individual UQ metrics on standard datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that disentangling input ambiguity from UQ signals improves error prediction for LLMs on QA tasks. UQ metrics are shown to be more predictive of errors on unambiguous instances than on those with multiple plausible answers; incorporating gold and predicted ambiguity labels via Gated Experts and Selective Prediction yields >10 PRR point gains for individual UQ metrics across model families, training/evaluation paradigms, datasets (including allegedly unambiguous ones), and aleatoric uncertainty sources.
Significance. If the central empirical claims hold after addressing label quality and bias concerns, the work would establish ambiguity as a separable factor in UQ-based error prediction, with practical value for selective prediction and reliable LLM deployment. The breadth of experiments across six UQ metrics, multiple models, and datasets is a positive feature that strengthens generalizability claims.
major comments (3)
- [Method (Gated Experts and Selective Prediction) and Experiments] The central claim depends on reliable gold-standard ambiguity labels and their incorporation without introducing selection bias or label noise that erases the reported PRR gains. The manuscript must provide the exact procedure for obtaining these labels, inter-annotator agreement statistics, and controls showing that gated-expert/selective-prediction steps do not confound the UQ signal (e.g., via ablation on label noise levels).
- [Experiments and Results] The assertion that gains hold on 'allegedly unambiguous' datasets and across sources of aleatoric uncertainty is load-bearing for the disentanglement narrative, yet the manuscript provides no explicit definition, labeling protocol, or quantitative check that ambiguity labels in those datasets are independent of model error rates.
- [Experiments] Full experimental details (data splits, statistical significance tests for the >10 PRR improvements, and exact definitions of the six UQ metrics) are required to verify that post-hoc choices or dataset artifacts do not drive the consistent gains reported in the abstract.
minor comments (2)
- The abstract refers to 'six UQ metrics' without naming them; an explicit list in the main text would aid reproducibility.
- Clarify the precise formula or reference for the PRR metric used to quantify improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for clarification. We respond to each major comment below and will revise the manuscript to incorporate additional details and controls as needed.
read point-by-point responses
-
Referee: [Method (Gated Experts and Selective Prediction) and Experiments] The central claim depends on reliable gold-standard ambiguity labels and their incorporation without introducing selection bias or label noise that erases the reported PRR gains. The manuscript must provide the exact procedure for obtaining these labels, inter-annotator agreement statistics, and controls showing that gated-expert/selective-prediction steps do not confound the UQ signal (e.g., via ablation on label noise levels).
Authors: We agree that precise documentation of the gold-standard labels is essential. The manuscript provides a high-level description of the labeling process, but we will revise to include the full annotation protocol, inter-annotator agreement statistics, and new ablation experiments that vary label noise levels to confirm the Gated Experts and Selective Prediction components do not confound the UQ signals or erase the reported gains. revision: yes
-
Referee: [Experiments and Results] The assertion that gains hold on 'allegedly unambiguous' datasets and across sources of aleatoric uncertainty is load-bearing for the disentanglement narrative, yet the manuscript provides no explicit definition, labeling protocol, or quantitative check that ambiguity labels in those datasets are independent of model error rates.
Authors: We will add explicit definitions of ambiguity, the complete labeling protocol applied to all datasets (including those labeled as allegedly unambiguous), and quantitative checks demonstrating that the ambiguity labels are independent of model error rates. These additions will directly support the claims regarding gains across aleatoric uncertainty sources. revision: yes
-
Referee: [Experiments] Full experimental details (data splits, statistical significance tests for the >10 PRR improvements, and exact definitions of the six UQ metrics) are required to verify that post-hoc choices or dataset artifacts do not drive the consistent gains reported in the abstract.
Authors: We will expand the experimental section to report all data splits, results from statistical significance tests on the PRR improvements, and the precise mathematical definitions of each of the six UQ metrics. This will enable verification that the gains are robust. revision: yes
Circularity Check
No circularity: purely empirical study with no derivations or load-bearing self-citations
full rationale
The paper is an empirical investigation of ambiguity's role in error prediction for LLMs on QA tasks. It reports experimental results using six standard UQ metrics, gated experts, and selective prediction across model families, datasets, and paradigms, with no equations, derivations, or mathematical claims present. No self-citations are invoked to justify uniqueness theorems or ansatzes that would reduce the central claim to prior author work. The reported PRR improvements are measured outcomes rather than fitted inputs renamed as predictions, and the work remains self-contained against external benchmarks without reducing any step to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , year =
Ran El-Yaniv and Yair Wiener , title =. Journal of Machine Learning Research , year =
-
[2]
Selective Classification for Deep Neural Networks , url =
Geifman, Yonatan and El-Yaniv, Ran , booktitle =. Selective Classification for Deep Neural Networks , url =. Advances in neural information processing systems , year =
-
[3]
Interpreting Predictive Probabilities: Model Confidence or Human Label Variation?
Baan, Joris and Fern \'a ndez, Raquel and Plank, Barbara and Aziz, Wilker. Interpreting Predictive Probabilities: Model Confidence or Human Label Variation?. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.eacl-short.24
-
[4]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , publisher=
2024
-
[5]
Consensus or conflict? Fine-grained evaluation of conflicting answers in question-answering
Nachshoni, Eviatar and Cattan, Arie and Amar, Shmuel and Shapira, Ori and Dagan, Ido. Consensus or Conflict? Fine-Grained Evaluation of Conflicting Answers in Question-Answering. Proceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025). 2025. doi:10.18653/v1/2025.uncertainlp-main.13
-
[6]
A lign S core: Evaluating Factual Consistency with A Unified Alignment Function
Zha, Yuheng and Yang, Yichi and Li, Ruichen and Hu, Zhiting. A lign S core: Evaluating Factual Consistency with A Unified Alignment Function. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.634
-
[7]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
-
[8]
arXiv preprint arXiv:2403.08295 , year=
Gemma: Open Models Based on Gemini Research and Technology , author=. arXiv preprint arXiv:2403.08295 , year=
-
[9]
T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[10]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[11]
AmbigQA: Answering ambigu- ous open-domain questions
Min, Sewon and Michael, Julian and Hajishirzi, Hannaneh and Zettlemoyer, Luke. A mbig QA : Answering Ambiguous Open-domain Questions. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.466
-
[12]
Sparse Neurons Carry Strong Signals of Question Ambiguity in LLM s
Zhang, Zhuoxuan and Duan, Jinhao and Kim, Edward and Xu, Kaidi. Sparse Neurons Carry Strong Signals of Question Ambiguity in LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.813
-
[13]
Proceedings of the 42nd international acm sigir conference on research and development in information retrieval , pages=
Asking clarifying questions in open-domain information-seeking conversations , author=. Proceedings of the 42nd international acm sigir conference on research and development in information retrieval , pages=
-
[14]
arXiv preprint arXiv:2002.07650 , year=
Uncertainty estimation in autoregressive structured prediction , author=. arXiv preprint arXiv:2002.07650 , year=
arXiv 2002
-
[15]
An introduction to ROC analysis , journal =
Tom Fawcett , keywords =. An introduction to ROC analysis , journal =. 2006 , note =. doi:https://doi.org/10.1016/j.patrec.2005.10.010 , url =
-
[16]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[17]
arXiv preprint arXiv:2309.16609 , year=
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
-
[18]
arXiv preprint arXiv:2602.11938 , year=
Who is the richest club in the championship? Detecting and Rewriting Underspecified Questions Improve QA Performance , author=. arXiv preprint arXiv:2602.11938 , year=
-
[19]
arXiv preprint arXiv:1904.09751 , year=
The curious case of neural text degeneration , author=. arXiv preprint arXiv:1904.09751 , year=
Pith/arXiv arXiv 1904
-
[20]
, title =
Ahdritz, Gustaf and Qin, Tian and Vyas, Nikhil and Barak, Boaz and Edelman, Benjamin L. , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[21]
2025 , url=
Zhang, Fengji and Niu, Xinyao and Ying, Chengyang and Lin, Guancheng and Hao, Zhongkai and Fan, Zhou and Huang, Chengen and Keung, Jacky and Chen, Bei and Lin, Junyang , journal=. 2025 , url=
2025
-
[22]
arXiv preprint arXiv:2510.06084 , year=
Spectrum tuning: Post-training for distributional coverage and in-context steerability , author=. arXiv preprint arXiv:2510.06084 , year=
-
[23]
Exploring Concept Depth: How Large Language Models Acquire Knowledge and Concept at Different Layers?
Jin, Mingyu and Yu, Qinkai and Huang, Jingyuan and Zeng, Qingcheng and Wang, Zhenting and Hua, Wenyue and Zhao, Haiyan and Mei, Kai and Meng, Yanda and Ding, Kaize and Yang, Fan and Du, Mengnan and Zhang, Yongfeng. Exploring Concept Depth: How Large Language Models Acquire Knowledge and Concept at Different Layers?. Proceedings of the 31st International C...
2025
-
[24]
To Believe or Not to Believe Your LLM: Iterative Prompting for Estimating Epistemic Uncertainty , url =
Yadkori, Yasin Abbasi and Kuzborskij, Ilja and Gy\". To Believe or Not to Believe Your LLM: Iterative Prompting for Estimating Epistemic Uncertainty , url =. Advances in Neural Information Processing Systems , doi =
-
[25]
CoCoA: A Minimum Bayes Risk Framework Bridging Confidence and Consistency for Uncertainty Quantification in LLMs , url =
Vashurin, Roman and Goloburda, Maiya and Ilina, Albina and Rubashevskii, Aleksandr and Nakov, Preslav and Shelmanov, Artem and Panov, Maxim , booktitle =. CoCoA: A Minimum Bayes Risk Framework Bridging Confidence and Consistency for Uncertainty Quantification in LLMs , url =
-
[26]
Do Androids Know They ' re Only Dreaming of Electric Sheep?
CH-Wang, Sky and Van Durme, Benjamin and Eisner, Jason and Kedzie, Chris. Do Androids Know They ' re Only Dreaming of Electric Sheep?. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.260
-
[27]
doi: 10.18653/v1/2023.emnlp-main.330
Tian, Katherine and Mitchell, Eric and Zhou, Allan and Sharma, Archit and Rafailov, Rafael and Yao, Huaxiu and Finn, Chelsea and Manning, Christopher. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. Proceedings of the 2023 Conference on Empirical Methods in Natural Langua...
-
[28]
arXiv preprint arXiv:2508.14496 , year=
Semantic energy: Detecting llm hallucination beyond entropy , author=. arXiv preprint arXiv:2508.14496 , year=
-
[29]
e , Ieva Raminta and Vlachos, Andreas
Stali \= u nait \. e , Ieva Raminta and Vlachos, Andreas. Uncertain (Mis)Takes at L e W i D i-2025: Modeling Human Label Variation With Semantic Entropy. Proceedings of the The 4th Workshop on Perspectivist Approaches to NLP. 2025. doi:10.18653/v1/2025.nlperspectives-1.23
-
[30]
Journal of Artificial Intelligence Research , volume=
Learning from disagreement: A survey , author=. Journal of Artificial Intelligence Research , volume=. 2021 , url=
2021
-
[31]
Trust Me, I ' m Wrong: LLM s Hallucinate with Certainty Despite Knowing the Answer
Simhi, Adi and Itzhak, Itay and Barez, Fazl and Stanovsky, Gabriel and Belinkov, Yonatan. Trust Me, I ' m Wrong: LLM s Hallucinate with Certainty Despite Knowing the Answer. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.792
-
[32]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Hou, Bairu and Liu, Yujian and Qian, Kaizhi and Andreas, Jacob and Chang, Shiyu and Zhang, Yang , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Fine-grained uncertainty decomposition in large language models: A spectral approach , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2026 , url=
2026
-
[34]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , url =
Li, Kenneth and Patel, Oam and Vi\'. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , url =. Advances in Neural Information Processing Systems , editor =
-
[35]
ArXiv , year=
INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection , author=. ArXiv , year=
-
[36]
ArXiv , year=
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations , author=. ArXiv , year=
-
[37]
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , url =
Kendall, Alex and Gal, Yarin , journal =. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , url =
-
[38]
arXiv preprint arXiv:2511.04418 , year=
The Illusion of Certainty: Uncertainty quantification for LLMs fails under ambiguity , author=. arXiv preprint arXiv:2511.04418 , year=
-
[39]
The ``problem'' of human label variation: On ground truth in data, modeling and evaluation
Plank, Barbara. The ``Problem'' of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.731
-
[40]
International Conference on Learning Representations , volume=
Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts , author=. International Conference on Learning Representations , volume=
-
[41]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Knowledge conflicts for llms: A survey , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[42]
MAQA : Evaluating Uncertainty Quantification in LLM s Regarding Data Uncertainty
Yang, Yongjin and Yoo, Haneul and Lee, Hwaran. MAQA : Evaluating Uncertainty Quantification in LLM s Regarding Data Uncertainty. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.325
-
[43]
Selectively Answering Ambiguous Questions
Cole, Jeremy and Zhang, Michael and Gillick, Daniel and Eisenschlos, Julian and Dhingra, Bhuwan and Eisenstein, Jacob. Selectively Answering Ambiguous Questions. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.35
-
[44]
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
Mostafazadeh Davani, Aida and D \'i az, Mark and Prabhakaran, Vinodkumar. Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00449
-
[45]
Ambiguity Meets Uncertainty: Investigating Uncertainty Estimation for Word Sense Disambiguation
Liu, Zhu and Liu, Ying. Ambiguity Meets Uncertainty: Investigating Uncertainty Estimation for Word Sense Disambiguation. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.245
-
[46]
Machine learning , volume=
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods , author=. Machine learning , volume=. 2021 , publisher=
2021
-
[47]
Duan, Jinhao and Cheng, Hao and Wang, Shiqi and Zavalny, Alex and Wang, Chenan and Xu, Renjing and Kailkhura, Bhavya and Xu, Kaidi. Shifting Attention to Relevance: Towards the Predictive Uncertainty Quantification of Free-Form Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa...
-
[48]
SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models
Manakul, Potsawee and Liusie, Adian and Gales, Mark. S elf C heck GPT : Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.557
-
[49]
arXiv preprint arXiv:1610.02136 , year=
A baseline for detecting misclassified and out-of-distribution examples in neural networks , author=. arXiv preprint arXiv:1610.02136 , year=
-
[50]
arXiv preprint arXiv:2305.19187 , year=
Generating with confidence: Uncertainty quantification for black-box large language models , author=. arXiv preprint arXiv:2305.19187 , year=
-
[51]
arXiv preprint arXiv:2207.05221 , year=
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[52]
e , Ieva Raminta and Cheng, Julius and Vlachos, Andreas
Stali \= u nait \. e , Ieva Raminta and Cheng, Julius and Vlachos, Andreas. Uncertainty Quantification for Evaluating Gender Bias in Machine Translation. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.116
-
[53]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[54]
Publications Manual , year = "1983", publisher =
1983
-
[55]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[56]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[57]
Dan Gusfield , title =. 1997
1997
-
[58]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[59]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.