FADA: Few-Shot Domain Adaptation via Dynamics Alignment for Humanoid Control
Pith reviewed 2026-06-30 01:24 UTC · model grok-4.3
The pith
FADA adapts humanoid controllers to target dynamics by finetuning only the inverse dynamics model on short target rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
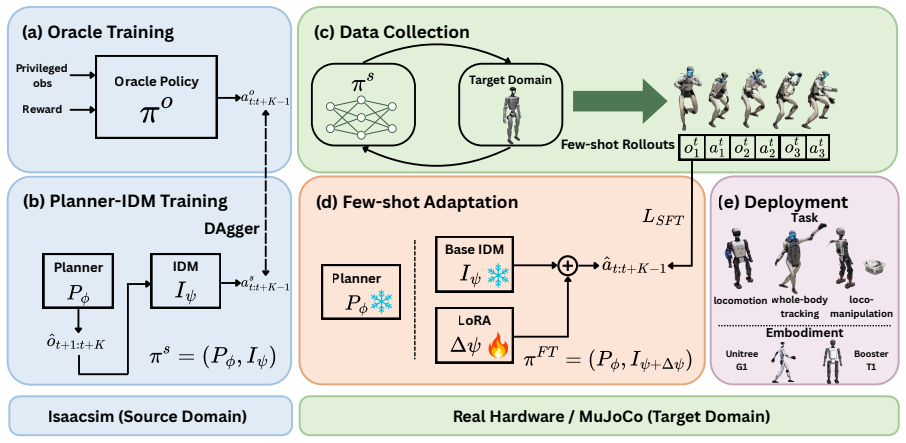
FADA is a Planner-IDM framework for few-shot domain adaptation in humanoid control. It trains an oracle policy with privileged information, distills the behavior into a deployable Planner-IDM student through DAgger, and at deployment freezes the planner while finetuning only the IDM using approximately 2 minutes of target-domain rollouts with standard supervised learning on observed action-observation pairs to align with target dynamics.
What carries the argument
The Planner-IDM architecture, where the planner generates reference trajectories and the IDM maps them to actions, with adaptation performed solely by updating the IDM via supervised learning on target rollouts.
If this is right
- FADA outperforms in-context and end-to-end adaptation baselines on task performance under dynamics shifts.
- Real humanoid robots can perform diverse high-precision whole-body tasks after adaptation.
- Adaptation uses only paired actions and observations from short rollouts without requiring optimal demonstrations or rewards.
- The planner does not need updates, allowing modular adaptation focused on dynamics alignment.
Where Pith is reading between the lines
- This separation of planner and IDM could generalize to other control systems where dynamics vary but task planning remains stable.
- Further work might test if similar few-shot alignment works for longer horizons or more complex tasks beyond the evaluated ones.
- Connecting to sim-to-real transfer, this method reduces reliance on extensive domain randomization by enabling quick post-deployment correction.
Load-bearing premise
That supervised learning on the observed action-observation pairs collected during short target rollouts is sufficient to align the IDM to the new dynamics without optimal demonstrations, rewards, or updates to the planner.
What would settle it
A test where the adapted IDM, after training on the 2-minute rollouts, produces actions that do not result in the planned motions when executed on the target robot in a repeatable dynamics shift scenario would falsify the alignment claim.
Figures






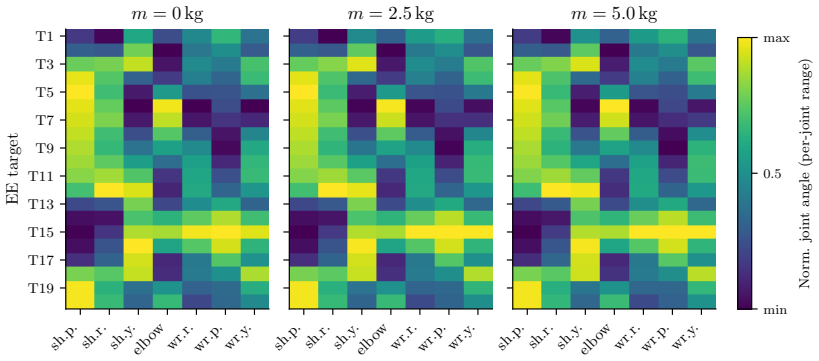
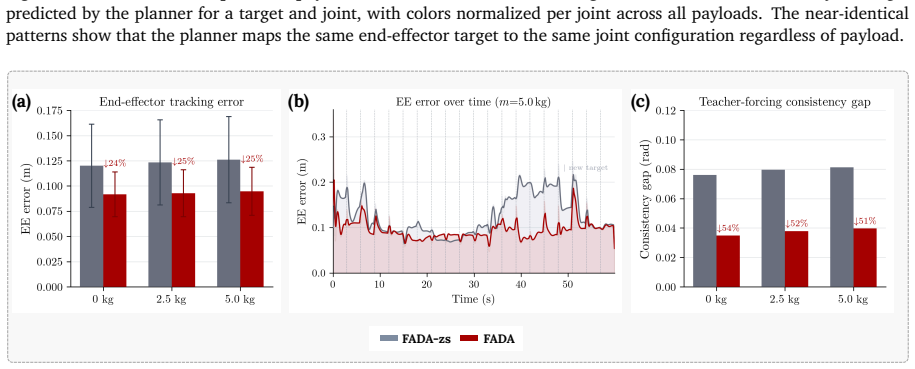

read the original abstract
High-precision humanoid control is limited by target-domain dynamics mismatch, where the same control objective can induce different realized motions under changes in terrain, payload, or actuator response. Existing methods either pursue zero-shot transfer through domain randomization or in-context adaptation without target-domain specialization, or require heavy adaptation pipelines that leverage target-domain data, such as model calibration, residual learning, or policy retraining. In this paper, we present FADA (Few-Shot Domain Adaptation via Dynamics Alignment), a three-stage Planner-Inverse Dynamics Model (Planner-IDM) framework for few-shot adaptation in humanoid control. FADA first trains an oracle policy with privileged information and then distills the oracle behavior into a deployable Planner-IDM student through DAgger. At deployment, FADA freezes the planner and finetunes only the IDM using approximately 2 minutes of target-domain rollouts with standard supervised learning. Rather than requiring optimal demonstrations or rewards, FADA uses the paired actions and observations that are observed during these rollouts as supervision, aligning the IDM's action generation with target-domain dynamics. Experiments show that FADA outperforms both in-context and end-to-end adaptation baselines, improving task performance under dynamics shifts and enabling real humanoid robots to execute diverse high-precision whole-body tasks. Implementation details and qualitative hardware rollout videos are available at https://lecar-lab.github.io/FADA-humanoid/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FADA, a three-stage Planner-IDM framework for few-shot domain adaptation in humanoid control. An oracle policy is first trained with privileged information and distilled into a deployable Planner-IDM student via DAgger. At deployment the planner is frozen and only the IDM is finetuned via standard supervised learning on paired actions and observations from approximately 2 minutes of target-domain rollouts. The paper claims this outperforms both in-context and end-to-end adaptation baselines, improves task performance under dynamics shifts, and enables real humanoid robots to execute diverse high-precision whole-body tasks.
Significance. If the central claim holds, the result would be significant for practical humanoid deployment: it demonstrates that a lightweight, reward-free adaptation step using only short uncurated rollouts can bridge dynamics mismatch while keeping the planner fixed. The real-robot experiments and the explicit separation of planner and IDM adaptation are concrete strengths that, if quantitatively supported, would distinguish the method from heavier residual-learning or full-policy-retraining pipelines.
major comments (1)
- [Deployment stage / abstract] Deployment stage (abstract and corresponding method section): the claim that supervised regression on observed (obs, action) pairs from ~2 min of target rollouts generated by the unadapted Planner-IDM suffices to produce an IDM compatible with the frozen source planner is load-bearing. The training actions are those emitted by the source IDM; the resulting (obs, action) distribution may therefore differ from the state-action distribution the planner will actually query once the adapted IDM is inserted, leaving residual dynamics error unaddressed. A direct test (e.g., comparison against rollouts collected with an oracle target IDM or closed-loop planner-IDM interaction) is needed to substantiate the assumption.
minor comments (2)
- [Abstract] Abstract: states that FADA "outperforms both in-context and end-to-end adaptation baselines" yet supplies no numerical metrics, baseline names, or ablation summary; adding at least one key quantitative result would strengthen the abstract.
- [Abstract] The manuscript provides a project page with implementation details and qualitative videos; this is helpful for reproducibility and should be retained.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the deployment stage of FADA. We address the concern regarding the distribution of training data for the IDM finetuning below and outline the planned revisions.
read point-by-point responses
-
Referee: [Deployment stage / abstract] Deployment stage (abstract and corresponding method section): the claim that supervised regression on observed (obs, action) pairs from ~2 min of target rollouts generated by the unadapted Planner-IDM suffices to produce an IDM compatible with the frozen source planner is load-bearing. The training actions are those emitted by the source IDM; the resulting (obs, action) distribution may therefore differ from the state-action distribution the planner will actually query once the adapted IDM is inserted, leaving residual dynamics error unaddressed. A direct test (e.g., comparison against rollouts collected with an oracle target IDM or closed-loop planner-IDM interaction) is needed to substantiate the assumption.
Authors: We appreciate this observation on the potential covariate shift in the IDM training distribution. The rollouts are generated in closed-loop by the planner commanding the source IDM in the target domain, so the observations are drawn from the target dynamics under the planner's state queries. The IDM is then trained to map these target observations to the actions that were executed, effectively learning an inverse dynamics model aligned to the target. While the adapted IDM could in principle alter the closed-loop trajectory distribution, the empirical evidence from both simulation and real-robot experiments shows substantial gains in task success rates, indicating practical compatibility. To further substantiate the assumption as suggested, we will add in the revised manuscript a simulated comparison of the adapted IDM against an oracle target IDM (trained with privileged target information) to measure any remaining dynamics error. revision: partial
Circularity Check
No significant circularity; derivation relies on external supervised learning on observed rollouts
full rationale
The paper's core pipeline (oracle policy training with privileged information, DAgger distillation to Planner-IDM, then freezing the planner and applying standard supervised regression to the IDM on ~2 minutes of target-domain (observation, action) pairs) contains no equations or claims that reduce a prediction to its own inputs by construction. The finetuning step uses externally observed data from rollouts as supervision rather than any self-referential fit or self-citation chain. This matches the default expectation of a non-circular empirical method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Huang, Weidong and Li, Zhehan and Liu, Hangxin and Hou, Biao and Su, Yao and Zhang, Jingwen , year =. Towards. doi:10.48550/ARXIV.2601.21363 , abstract =
-
[2]
and Iacobelli, Francesco and Koolen, Twan and Lambert, Alexander and Lin, Erica and Mungai, M
Sleiman, Jean Pierre and Li, He and Adu-Bredu, Alphonsus and Deits, Robin and Kumar, Arun and Bergamin, Kevin and Bhardwaj, Mohak and Biddlestone, Scott and Burger, Nicola and Estrada, Matthew A. and Iacobelli, Francesco and Koolen, Twan and Lambert, Alexander and Lin, Erica and Mungai, M. Eva and Nobles, Zach and Rozen-Levy, Shane and Shi, Yuyao and Wang...
-
[3]
Li, Chenhao and Krause, Andreas and Hutter, Marco , month = jan, year =. Uncertainty-. doi:10.48550/arXiv.2504.16680 , abstract =
-
[4]
Lee, Easop and Moore, Samuel A. and Chen, Boyuan , year =. doi:10.48550/ARXIV.2509.15412 , abstract =
-
[5]
Li, Chenhao and Krause, Andreas and Hutter, Marco , month = dec, year =. Robotic. doi:10.48550/arXiv.2501.10100 , abstract =
-
[6]
doi:10.48550/arXiv.2602.23843 , abstract =
Wang, Yunshen and Zhu, Shaohang and Zhi, Peiyuan and Li, Yuhan and Li, Jiaxin and Li, Yong-Lu and Xiao, Yuchen and Wang, Xingxing and Jia, Baoxiong and Huang, Siyuan , month = feb, year =. doi:10.48550/arXiv.2602.23843 , abstract =
-
[7]
Chase and Peng, Xue Bin and Ha, Sehoon and Tan, Jie and Levine, Sergey , year =
Smith, Laura and Kew, J. Chase and Peng, Xue Bin and Ha, Sehoon and Tan, Jie and Levine, Sergey , year =. Legged. doi:10.48550/ARXIV.2110.05457 , abstract =
-
[8]
Xie, Weiji and Bai, Chenjia and Shi, Jiyuan and Yang, Junkai and Ge, Yunfei and Zhang, Weinan and Li, Xuelong , month = feb, year =. Humanoid. doi:10.48550/arXiv.2502.17219 , abstract =
-
[9]
Jones, Joshua and Mees, Oier and Sferrazza, Carmelo and Stachowicz, Kyle and Abbeel, Pieter and Levine, Sergey , year =. Beyond. doi:10.48550/ARXIV.2501.04693 , abstract =
-
[10]
and Dai, Hongkai and Burchfiel, Benjamin and Majumdar, Anirudha , year =
Ren, Allen Z. and Dai, Hongkai and Burchfiel, Benjamin and Majumdar, Anirudha , year =. doi:10.48550/ARXIV.2302.04903 , abstract =
-
[11]
Lei, Yu and Liu, Minghuan and Maddukuri, Abhiram and Jiang, Zhenyu and Zhu, Yuke , month = apr, year =. A. doi:10.48550/arXiv.2604.13645 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.13645
-
[12]
Maddukuri, Abhiram and Jiang, Zhenyu and Chen, Lawrence Yunliang and Nasiriany, Soroush and Xie, Yuqi and Fang, Yu and Huang, Wenqi and Wang, Zu and Xu, Zhenjia and Chernyadev, Nikita and Reed, Scott and Goldberg, Ken and Mandlekar, Ajay and Fan, Linxi and Zhu, Yuke , year =. Sim-and-. doi:10.48550/ARXIV.2503.24361 , abstract =
-
[13]
Cha, Woohyun and Cha, Junhyeok and Shin, Jaeyong and Kim, Donghyeon and Park, Jaeheung , month = apr, year =. Sim-to-. doi:10.48550/arXiv.2504.06585 , abstract =
-
[14]
Seo, Younggyo and Sferrazza, Carmelo and Chen, Juyue and Shi, Guanya and Duan, Rocky and Abbeel, Pieter , month = dec, year =. Learning. doi:10.48550/arXiv.2512.01996 , abstract =
-
[15]
Proceedings of The 8th Conference on Robot Learning , series =
Adapting Humanoid Locomotion over Challenging Terrain via Two-Phase Training , author =. Proceedings of The 8th Conference on Robot Learning , series =. 2025 , publisher =
2025
-
[16]
Sun, Wandong and Chen, Long and Su, Yongbo and Cao, Baoshi and Liu, Yang and Xie, Zongwu , month = feb, year =. Learning. doi:10.48550/arXiv.2502.16230 , abstract =
-
[17]
Karen and Abbeel, Pieter and Shi, Guanya and Duan, Rocky , month = oct, year =
Zhao, Siheng and Ze, Yanjie and Wang, Yue and Liu, C. Karen and Abbeel, Pieter and Shi, Guanya and Duan, Rocky , month = oct, year =. doi:10.48550/arXiv.2510.05070 , abstract =
-
[18]
Biomimetics , author =. 2026 , keywords =. doi:10.3390/biomimetics11010040 , abstract =
-
[19]
doi:10.48550/arXiv.2505.24068 , abstract =
Krishna, Lokesh and Cheng, Sheng and Li, Junheng and Hovakimyan, Naira and Nguyen, Quan , month = jun, year =. doi:10.48550/arXiv.2505.24068 , abstract =
-
[20]
doi:10.48550/arXiv.2502.01143 , abstract =
He, Tairan and Gao, Jiawei and Xiao, Wenli and Zhang, Yuanhang and Wang, Zi and Wang, Jiashun and Luo, Zhengyi and He, Guanqi and Sobanbab, Nikhil and Pan, Chaoyi and Yi, Zeji and Qu, Guannan and Kitani, Kris and Hodgins, Jessica and Fan, Linxi "Jim" and Zhu, Yuke and Liu, Changliu and Shi, Guanya , month = apr, year =. doi:10.48550/arXiv.2502.01143 , abstract =
-
[21]
Lei, Kun and He, Zhengmao and Lu, Chenhao and Hu, Kaizhe and Gao, Yang and Xu, Huazhe , month = mar, year =. Uni-. doi:10.48550/arXiv.2311.03351 , abstract =
-
[22]
Zhang, Zhikai and Guo, Jun and Chen, Chao and Wang, Jilong and Lin, Chenghuai and Lian, Yunrui and Xue, Han and Wang, Zhenrong and Liu, Maoqi and Lyu, Jiangran and Liu, Huaping and Wang, He and Yi, Li , month = oct, year =. Track. doi:10.48550/arXiv.2509.13833 , abstract =
-
[23]
doi:10.48550/arXiv.2509.23745 , abstract =
Liu, Min and Pathak, Deepak and Agarwal, Ananye , month = sep, year =. doi:10.48550/arXiv.2509.23745 , abstract =
-
[24]
doi:10.48550/arXiv.2503.16806 , abstract =
Lyu, Jiangran and Li, Ziming and Shi, Xuesong and Xu, Chaoyi and Wang, Yizhou and Wang, He , month = jul, year =. doi:10.48550/arXiv.2503.16806 , abstract =
-
[25]
Chen, Sirui and Werling, Keenon and Wu, Albert and Liu, C. Karen , year =. Real-time. doi:10.48550/ARXIV.2202.09834 , abstract =
-
[26]
doi:10.48550/ARXIV.2504.06662 , abstract =
Cheng, Jin and Kang, Dongho and Fadini, Gabriele and Shi, Guanya and Coros, Stelian , year =. doi:10.48550/ARXIV.2504.06662 , abstract =
-
[27]
doi:10.48550/ARXIV.2405.10315 , abstract =
Jiang, Yunfan and Wang, Chen and Zhang, Ruohan and Wu, Jiajun and Fei-Fei, Li , year =. doi:10.48550/ARXIV.2405.10315 , abstract =
-
[28]
RMA: Rapid Motor Adaptation for Legged Robots
Kumar, Ashish and Fu, Zipeng and Pathak, Deepak and Malik, Jitendra , month = jul, year =. doi:10.48550/arXiv.2107.04034 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.04034
-
[29]
2025 IEEE International Conference on Robotics and Automation (ICRA) , year =
Beyond Robustness: Learning Unknown Dynamic Load Adaptation for Quadruped Locomotion on Rough Terrain , author =. 2025 IEEE International Conference on Robotics and Automation (ICRA) , year =. doi:10.1109/ICRA55743.2025.11128639 , url =
-
[30]
doi:10.48550/ARXIV.2508.00939 , abstract =
Huang, Haodong and Sun, Shilong and Wang, Yuanpeng and Li, Chiyao and Huang, Hailin and Xu, Wenfu , year =. doi:10.48550/ARXIV.2508.00939 , abstract =
-
[31]
Kumar, Ashish and Li, Zhongyu and Zeng, Jun and Pathak, Deepak and Sreenath, Koushil and Malik, Jitendra , month = sep, year =. Adapting. doi:10.48550/arXiv.2205.15299 , abstract =
-
[32]
Da, Longchao and Turnau, Justin and Kutralingam, Thirulogasankar Pranav and Velasquez, Alvaro and Shakarian, Paulo and Wei, Hua , year =. A. doi:10.48550/ARXIV.2502.13187 , abstract =
-
[33]
Long, Junfeng and Wang, Zirui and Li, Quanyi and Gao, Jiawei and Cao, Liu and Pang, Jiangmiao , year =. Hybrid. doi:10.48550/ARXIV.2312.11460 , abstract =
-
[34]
Kumar, Visak and Ha, Sehoon and Liu, C. Karen , month = mar, year =. Error-. doi:10.48550/arXiv.2103.07732 , abstract =
-
[35]
Made Aswin and Yu, Byeongho and Myung, Hyun , month = mar, year =
Nahrendra, I. Made Aswin and Yu, Byeongho and Myung, Hyun , month = mar, year =. doi:10.48550/arXiv.2301.10602 , abstract =
-
[36]
arXiv preprint arXiv:2509.02815 , year=
Multi-Embodiment Locomotion at Scale with Extreme Embodiment Randomization , author=. arXiv preprint arXiv:2509.02815 , year=
-
[37]
arXiv preprint arXiv:2402.16796 , year=
Expressive Whole-Body Control for Humanoid Robots , author=. arXiv preprint arXiv:2402.16796 , year=
-
[38]
arXiv preprint arXiv:2406.10454 , year=
HumanPlus: Humanoid Shadowing and Imitation from Humans , author=. arXiv preprint arXiv:2406.10454 , year=
-
[39]
arXiv preprint arXiv:2404.05695 , year=
Humanoid-Gym: Reinforcement Learning for Humanoid Robot with Zero-Shot Sim2Real Transfer , author=. arXiv preprint arXiv:2404.05695 , year=
-
[40]
arXiv preprint arXiv:2410.21229 , year=
HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots , author=. arXiv preprint arXiv:2410.21229 , year=
-
[41]
arXiv preprint arXiv:2406.08858 , year=
OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning , author=. arXiv preprint arXiv:2406.08858 , year=
-
[42]
arXiv preprint arXiv:2508.12252 , year=
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids , author=. arXiv preprint arXiv:2508.12252 , year=
-
[43]
Proceedings of The 9th Conference on Robot Learning , pages=
Sampling-based System Identification with Active Exploration for Legged Sim2Real Learning , author=. Proceedings of The 9th Conference on Robot Learning , pages=. 2025 , editor=
2025
-
[44]
arXiv preprint arXiv:2505.06776 , year=
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation , author=. arXiv preprint arXiv:2505.06776 , year=
-
[45]
IEEE Robotics and Automation Letters , volume=
Orbit: A Unified Simulation Framework for Interactive Robot Learning Environments , author=. IEEE Robotics and Automation Letters , volume=. 2023 , doi=
2023
-
[46]
2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
MuJoCo: A physics engine for model-based control , author=. 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2012 , doi=
2012
-
[47]
Simulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation
Simulation Distillation: Pretraining World Models in Simulation for Rapid Real-World Adaptation , author=. 2026 , eprint=. doi:10.48550/arXiv.2603.15759 , note=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.15759 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.