Evaluation-Strategy Gap in Fault Diagnosis of Deep Learning Programs
Pith reviewed 2026-06-26 04:42 UTC · model grok-4.3
The pith
Fault diagnosis techniques for deep learning programs drop 0.19 in balanced accuracy on entirely new programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
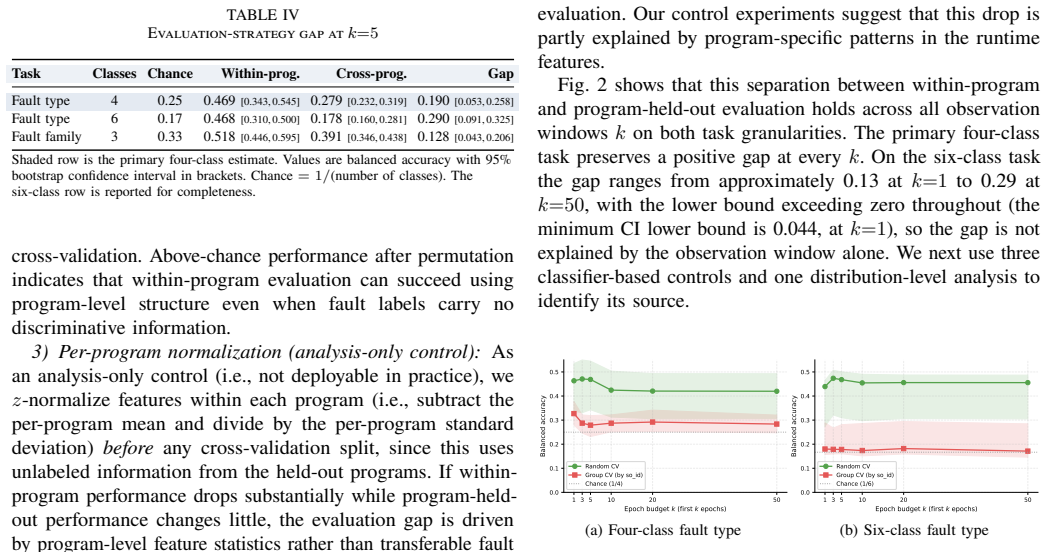
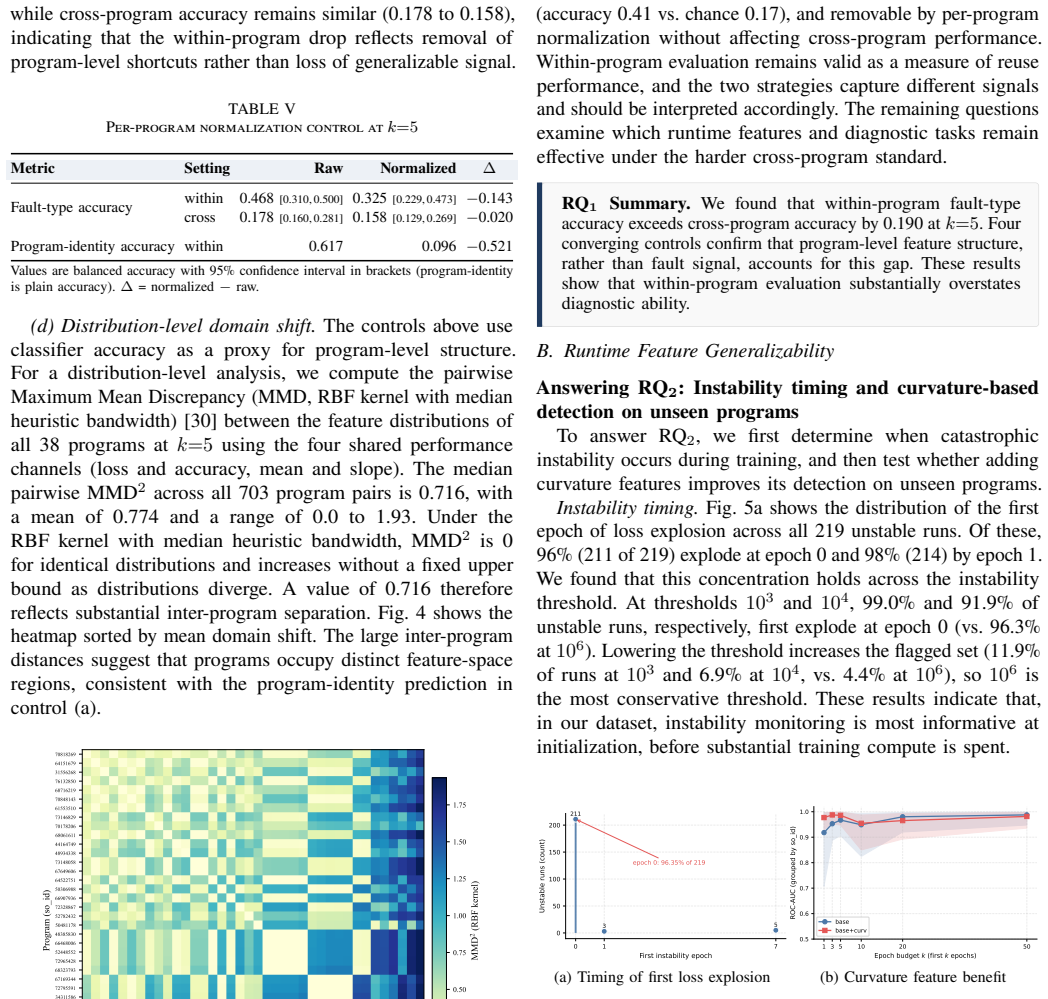
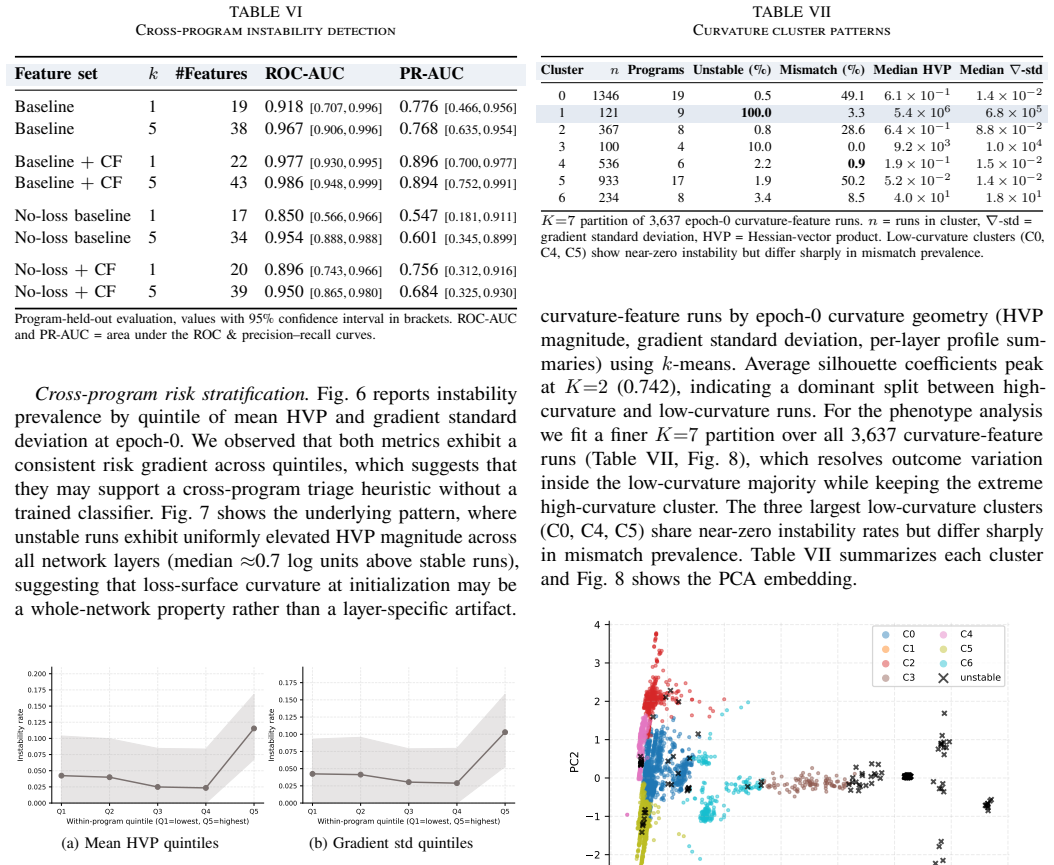
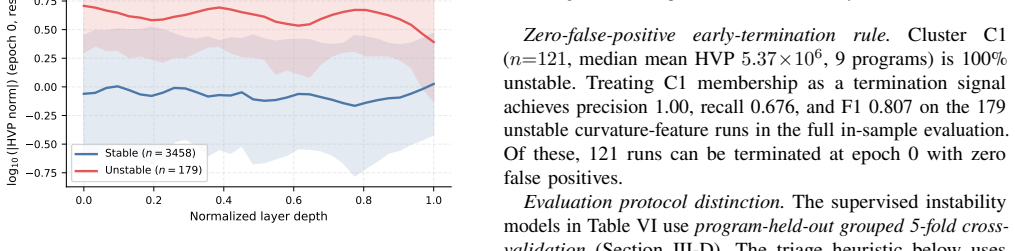
Existing fault diagnosis techniques for DL programs exhibit a gap of 0.190 in balanced accuracy when moving from within-program evaluation to holding out whole programs. The gap stems from program-level structure in the features. Curvature features remain useful for instability detection on unseen programs, whereas optimizer and activation features are effective only on programs seen during training.
What carries the argument
Program hold-out evaluation, which exposes the generalization failure caused by program-level structure in runtime trace features.
If this is right
- Diagnosis systems must be re-evaluated with program hold-out to reflect deployment conditions.
- Curvature features can be used directly for instability detection in previously unseen programs.
- Optimizer and activation features require retraining or adaptation when a new program is introduced.
- Feature selection for fault diagnosis should prioritize signals that avoid encoding program identity.
- Benchmarks relying only on within-program splits systematically overestimate reliability on new codebases.
Where Pith is reading between the lines
- Teams maintaining diagnosis tools for evolving DL code may need to gather fresh labeled traces for each major new program.
- Combining curvature features with program-agnostic reformulations of other features could narrow the observed gap.
- The gap implies that production monitoring of novel DL training runs carries higher uncertainty than current published numbers suggest.
- Extending the analysis to programs written in additional frameworks or domains would test whether the gap size is stable.
Load-bearing premise
The DynFault corpus of 5542 fault-injected traces from 38 real-world DL programs is representative of real deployment failures and program structures.
What would settle it
Re-running the same techniques on a new, independently collected set of DL programs and observing no accuracy difference between within-program and hold-out evaluation would falsify the claimed gap.
Figures


read the original abstract
Deep Learning (DL) programs can fail during training for many reasons, and diagnosing the cause is a costly and time-consuming maintenance task. Techniques for diagnosing such failures are commonly assessed using within-program cross-validation, which may be inadequate for deployment settings involving previously unseen programs. It is therefore necessary to assess how performance differs across these settings and to identify the causes of any performance gap in established fault diagnosis techniques for DL. We investigate this gap using DynFault, a corpus of 5,542 fault-injected training traces from 38 real-world DL programs. We found a gap of 0.190 in balanced accuracy for existing fault diagnosis techniques between within-program evaluation and holding out whole programs. We also found the gap comes from program-level structure in the features, which led us to examine two runtime feature sets, curvature features and optimizer features, and their behavior on unseen programs. We found that curvature features are useful for instability detection on unseen programs, while optimizer and activation features help only on programs seen during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fault diagnosis techniques for deep learning programs exhibit a 0.190 gap in balanced accuracy between within-program cross-validation and whole-program hold-out evaluation. This gap is measured on the DynFault corpus of 5,542 fault-injected training traces from 38 real-world DL programs and is attributed to program-level structure in the features. The authors further examine curvature, optimizer, and activation feature sets, concluding that curvature features remain useful for instability detection on unseen programs while optimizer and activation features help only on programs seen during training.
Significance. If the result holds, the work provides a concrete empirical demonstration that standard within-program evaluation overestimates performance for DL fault diagnosis in deployment settings involving new programs. The distinction between feature sets (curvature vs. optimizer/activation) offers a actionable direction for designing more generalizable diagnosis methods. The scale of the corpus (38 programs, >5k traces) supplies a measurable baseline that future studies can build upon or replicate.
major comments (3)
- [Abstract / DynFault corpus description] Abstract and methods description of DynFault: the reported 0.190 balanced-accuracy gap and its attribution to program-level feature structure rest on the corpus of 5,542 injected faults, yet no details are supplied on fault-injection procedure, program selection criteria, trace collection protocol, or any statistical controls for program identity. Without these, it is impossible to determine whether the gap reflects genuine program-level structure or an artifact of the injection process.
- [Abstract] Abstract: the central explanatory claim that 'the gap comes from program-level structure in the features' is presented without supporting quantitative evidence (e.g., feature-distribution statistics across programs, ablation of program identity, or cross-program variance decomposition). This attribution is load-bearing for the subsequent feature-set analysis.
- [Abstract] Abstract: the evaluation is performed exclusively on artificially injected faults; no comparison against a set of naturally occurring (non-injected) DL training failures is reported. Consequently, both the magnitude of the gap and the differential utility of curvature features on unseen programs rest on an untested assumption that injected faults produce representative runtime traces.
minor comments (1)
- [Abstract] The abstract states a precise numerical gap (0.190) but does not indicate whether this is an average across multiple techniques or a single aggregate; clarifying the exact aggregation would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of clarity and evidence in our work on the evaluation-strategy gap for DL fault diagnosis. We address each major comment below with specific plans for revision where appropriate.
read point-by-point responses
-
Referee: [Abstract / DynFault corpus description] Abstract and methods description of DynFault: the reported 0.190 balanced-accuracy gap and its attribution to program-level feature structure rest on the corpus of 5,542 injected faults, yet no details are supplied on fault-injection procedure, program selection criteria, trace collection protocol, or any statistical controls for program identity. Without these, it is impossible to determine whether the gap reflects genuine program-level structure or an artifact of the injection process.
Authors: We agree that the abstract lacks sufficient detail on corpus construction. The full manuscript describes the DynFault corpus in Section 3, including program selection from popular open-source DL repositories, fault types injected via targeted code mutations, and trace collection using runtime instrumentation. To address the concern directly, we will revise the abstract to include a concise summary of these elements and add explicit statistical controls (e.g., program-stratified sampling and identity ablation checks) in the methods section of the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the central explanatory claim that 'the gap comes from program-level structure in the features' is presented without supporting quantitative evidence (e.g., feature-distribution statistics across programs, ablation of program identity, or cross-program variance decomposition). This attribution is load-bearing for the subsequent feature-set analysis.
Authors: We acknowledge that the abstract presents the attribution concisely without inline quantitative support. The manuscript body includes supporting analyses (feature distributions and cross-program comparisons), but to strengthen the load-bearing claim, we will incorporate additional quantitative evidence such as per-program feature distribution statistics, program-identity ablation results, and variance decomposition in a new subsection of the revised paper. revision: yes
-
Referee: [Abstract] Abstract: the evaluation is performed exclusively on artificially injected faults; no comparison against a set of naturally occurring (non-injected) DL training failures is reported. Consequently, both the magnitude of the gap and the differential utility of curvature features on unseen programs rest on an untested assumption that injected faults produce representative runtime traces.
Authors: The work deliberately employs controlled fault injection to enable reproducible, large-scale evaluation across 38 programs while isolating specific fault effects. We recognize that this leaves the representativeness of injected faults as an assumption. In the revision, we will add an explicit limitations subsection discussing this assumption, its rationale, and implications for deployment on natural failures, without claiming equivalence. revision: partial
- Direct empirical comparison of injected versus naturally occurring DL training failures, as no such natural-fault corpus was collected or available for this study.
Circularity Check
No circularity: purely empirical measurement study
full rationale
The paper reports direct empirical measurements of balanced accuracy gaps on a fixed corpus of 5542 injected-fault traces across 38 programs. No derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described claims. The 0.190 gap is a computed statistic on held-out programs, not a quantity forced by construction from the inputs. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fault injection into training traces produces failures representative of natural DL program faults
Reference graph
Works this paper leans on
-
[1]
A comprehensive study on deep learning bug characteristics,
M. J. Islam, G. Nguyen, R. Pan, and H. Rajan, “A comprehensive study on deep learning bug characteristics,” inProceedings of the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2019, pp. 510–520.doi: 10.1145/3338906.3338955
-
[2]
Taxonomy of real faults in deep learning systems,
N. Humbatova et al., “Taxonomy of real faults in deep learning systems,” inProceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE), 2020, pp. 1110–1121.doi: 10.1145/ 3377811.3380395
arXiv 2020
-
[3]
Visualizing the loss landscape of neural nets,
H. Li et al., “Visualizing the loss landscape of neural nets,” inAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[4]
Ferreira, Rui Abreu, and Pedro Cruz
R. Zhang et al., “An empirical study on program failures of deep learning jobs,” inProceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE), 2020, pp. 1159–1170. doi: 10.1145/3377811.3380362
-
[5]
Repairing deep neural networks: Fix patterns and challenges,
M. J. Islam, R. Pan, G. Nguyen, and H. Rajan, “Repairing deep neural networks: Fix patterns and challenges,” inProceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE), 2020, pp. 1135–1146.doi: 10.1145/3377811.3380378
-
[6]
M. Wardat, B. D. Cruz, W. Le, and H. Rajan, “Deepdiagnosis: Automatically diagnosing faults and recommending actionable fixes in deep learning programs,” inProceedings of the 44th International Conference on Software Engineering (ICSE), 2022, pp. 561–572.doi: 10.1145/3510003.3510071
-
[7]
Deepfd: Automated fault diagnosis and localization for deep learning programs,
J. Cao, Y. Lu, M. Wen, and S. Cheung, “Deepfd: Automated fault diagnosis and localization for deep learning programs,” inProceedings of the 44th International Conference on Software Engineering (ICSE), 2022, pp. 573–585.doi: 10.1145/3510003.3510099
-
[8]
S. Jahan, M. B. Shah, P. Mahbub, and M. M. Rahman, “Improved detection and diagnosis of faults in deep neural networks using hierarchical and explainable classification,” inProceedings of the IEEE/ACM 47th International Conference on Software Engineering (ICSE), 2025, pp. 2944–2956.doi: 10.1109/ICSE55347.2025.00224
-
[9]
X. Qi, T. Zhu, and Y. Li, “Coverage-enhanced fault diagnosis for deep learning programs: A learning-based approach with hybrid metrics,” Information and Software Technology, vol. 173, p. 107 488, 2024.doi: 10.1016/j.infsof.2024.107488
-
[10]
Shortcut learning in deep neural networks,
R. Geirhos et al., “Shortcut learning in deep neural networks,”Nature Machine Intelligence, vol. 2, pp. 665–673, 2020.doi: 10.1038/s42256- 020-00257-z
-
[11]
Cross-project defect prediction: A large scale experiment on data vs. domain vs. process,
T. Zimmermann et al., “Cross-project defect prediction: A large scale experiment on data vs. domain vs. process,” inProceedings of the Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, 2009, pp. 91–100.doi: 10.1145/1595696.1595713
-
[12]
An empirical comparison of model validation techniques for defect prediction models,
C. Tantithamthavorn, S. McIntosh, A. E. Hassan, and K. Matsumoto, “An empirical comparison of model validation techniques for defect prediction models,”IEEE Transactions on Software Engineering, vol. 43, no. 1, pp. 1–18, 2017.doi: 10.1109/TSE.2016.2584050
-
[13]
D. R. Roberts et al., “Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure,”Ecography, vol. 40, no. 8, pp. 913–929, 2017.doi: 10.1111/ecog.02881
-
[14]
An empirical study of the impact of data splitting decisions on the performance of AIOps solutions,
Y. Lyu et al., “An empirical study of the impact of data splitting decisions on the performance of AIOps solutions,”ACM Transactions on Software Engineering and Methodology, vol. 30, no. 4, pp. 1–38, 2021.doi: 10.1145/3447876
-
[15]
DeepLocalize: Fault localization for deep neural networks,
X. Zhang, J. Zhai, S. Ma, and C. Shen, “AutoTrainer: An automatic DNN training problem detection and repair system,” inProceedings of the IEEE/ACM 43rd International Conference on Software Engineering (ICSE), 2021, pp. 359–371.doi: 10.1109/ICSE43902.2021.00043
-
[16]
UMLAUT: Debugging deep learning programs using program structure and model behavior,
E. Schoop, F. Huang, and B. Hartmann, “UMLAUT: Debugging deep learning programs using program structure and model behavior,” inProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI), 2021.doi: 10.1145/3411764.3445538
-
[17]
Jahan,Replication Package for the Evaluation Strategy Gap Study, https : / / github
S. Jahan,Replication Package for the Evaluation Strategy Gap Study, https : / / github . com / SigmaJahan / Evaluation - Strategy- Gap - Study, Accessed: 2026-06-24, 2026
2026
-
[18]
The impact of using biased performance metrics on software defect prediction research
Y. Yang, T. He, Z. Xia, and Y. Feng, “A comprehensive empirical study on bug characteristics of deep learning frameworks,”Information and Software Technology, p. 107 004, 2022.doi: 10.1016/j.infsof. 2022.107004
-
[19]
Automated patch backporting in Linux (experience paper),
N. Humbatova, G. Jahangirova, and P. Tonella, “Deepcrime: Mutation testing of deep learning systems based on real faults,” inProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), 2021, pp. 67–78.doi: 10.1145/3460319.3464825
-
[20]
Generalized linear models,
J. A. Nelder and R. W. Wedderburn, “Generalized linear models,” Journal of the Royal Statistical Society Series A: Statistics in Society, vol. 135, no. 3, pp. 370–384, 1972
1972
-
[21]
An investigation into neural net optimization via hessian eigenvalue density,
B. Ghorbani, S. Krishnan, and Y. Xiao, “An investigation into neural net optimization via hessian eigenvalue density,” inProceedings of the International Conference on Machine Learning (ICML), 2019, pp. 2232–2241
2019
-
[22]
Can hessian-based insights support fault diagnosis in attention-based models?
S. Jahan and M. M. Rahman, “Can hessian-based insights support fault diagnosis in attention-based models?” InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering (FSE), New York, NY, USA: Association for Computing Machinery, 2025, pp. 676–680.doi: 10.1145/3696630.3728522
-
[23]
A survey on deep learning for multimodal data fusion,
B. A. Pearlmutter, “Fast exact multiplication by the hessian,”Neural Computation, vol. 6, no. 1, pp. 147–160, 1994.doi: 10.1162/neco. 1994.6.1.147
-
[24]
Deep learning via hessian-free optimization,
J. Martens, “Deep learning via hessian-free optimization,” inPro- ceedings of the 27th International Conference on Machine Learning (ICML), 2010, pp. 735–742
2010
-
[25]
Gradient descent on neural networks typically occurs at the edge of stability,
J. M. Cohen et al., “Gradient descent on neural networks typically occurs at the edge of stability,”arXiv preprint arXiv:2103.00065, 2021
arXiv 2021
-
[26]
Understanding gradient descent on the edge of stability in deep learning,
S. Arora, Z. Li, and A. Panigrahi, “Understanding gradient descent on the edge of stability in deep learning,” inProceedings of the 39th International Conference on Machine Learning (ICML), PMLR, 2022, pp. 948–1024
2022
-
[27]
A loss curvature perspective on training instability in deep learning,
J. Gilmer et al., “A loss curvature perspective on training instability in deep learning,”arXiv preprint arXiv:2110.04369, 2021
arXiv 2021
-
[28]
Cockpit: A practical debugging tool for the training of deep neural networks,
F. Schneider, F. Dangel, and P. Hennig, “Cockpit: A practical debugging tool for the training of deep neural networks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[29]
Bootstrap-based improvements for inference with clustered errors,
A. C. Cameron, J. B. Gelbach, and D. L. Miller, “Bootstrap-based improvements for inference with clustered errors,”The Review of Economics and Statistics, vol. 90, no. 3, pp. 414–427, 2008.doi: 10.1162/rest.90.3.414
-
[30]
A kernel two-sample test,
A. Gretton et al., “A kernel two-sample test,”Journal of Machine Learning Research, vol. 13, no. 25, pp. 723–773, 2012
2012
-
[31]
Hidden technical debt in machine learning systems,
D. Sculley et al., “Hidden technical debt in machine learning systems,” inAdvances in Neural Information Processing Systems, 2015, pp. 2503– 2511
2015
-
[32]
An empirical study on TensorFlow program bugs,
Y. Zhang et al., “An empirical study on TensorFlow program bugs,” inProceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA), 2018, pp. 129–140.doi: 10.1145/3213846.3213866
-
[33]
DeepLocalize: Fault localization for deep neural networks,
M. Wardat, W. Le, and H. Rajan, “DeepLocalize: Fault localization for deep neural networks,” inProceedings of the IEEE/ACM 43rd International Conference on Software Engineering (ICSE), 2021, pp. 251–262.doi: 10.1109/ICSE43902.2021.00034
-
[34]
Detecting numerical bugs in neural network architectures,
Y. Zhang et al., “Detecting numerical bugs in neural network architectures,” inProceedings of the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE), 2020.doi: 10 . 1145 / 3368089 . 3409720
2020
-
[35]
In: Chandra, S., Blincoe, K., Tonella, P
S. Ahmed et al., “Design by contract for deep learning apis,” in Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineer- ing (ESEC/FSE), 2023.doi: 10.1145/3611643.3616247
-
[36]
Deepmutation: Mutation testing of deep learning systems,
L. Ma et al., “Deepmutation: Mutation testing of deep learning systems,” inProceedings of the IEEE 29th International Symposium on Software Reliability Engineering (ISSRE), 2018, pp. 100–111.doi: 10.1109/ ISSRE.2018.00021
arXiv 2018
-
[37]
An empirical study of the realism of mutants in deep learning,
Z. Ahmed, P. Makedonski, and J. Grabowski, “An empirical study of the realism of mutants in deep learning,”arXiv preprint arXiv:2512.16741, 2025
arXiv 2025
-
[38]
A comparative study to benchmark cross-project defect prediction approaches,
S. Herbold, A. Trautsch, and J. Grabowski, “A comparative study to benchmark cross-project defect prediction approaches,”IEEE Transactions on Software Engineering, vol. 44, no. 9, pp. 811–833, 2018.doi: 10.1109/TSE.2017.2724538
-
[39]
Software engineering for machine learning: A case study,
S. Amershi et al., “Software engineering for machine learning: A case study,” in2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE-SEIP), 2019.doi: 10.1109/ICSE-SEIP.2019.00042
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.