On the Difficulty of Learning a Meta-network for Training Data Selection
Pith reviewed 2026-06-28 19:12 UTC · model grok-4.3
The pith
Meta-learning for data selection underperforms because of poor gradient signal-to-noise ratios tied to varying data quality, which larger batches and position-based features can fix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
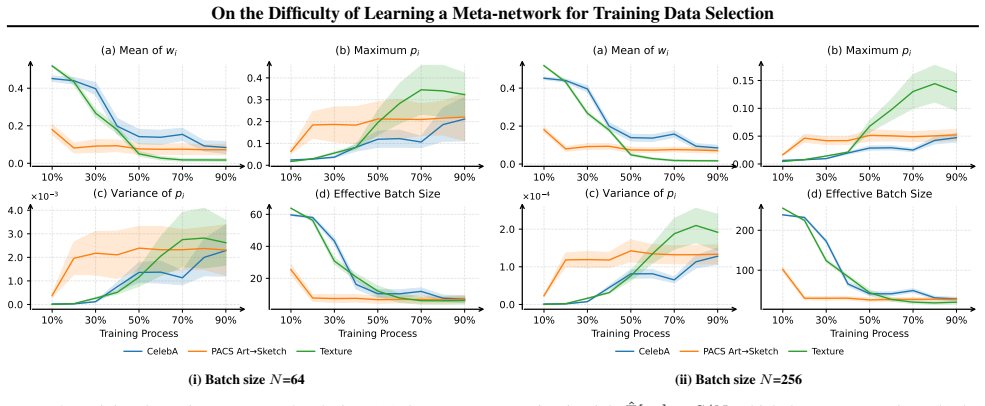
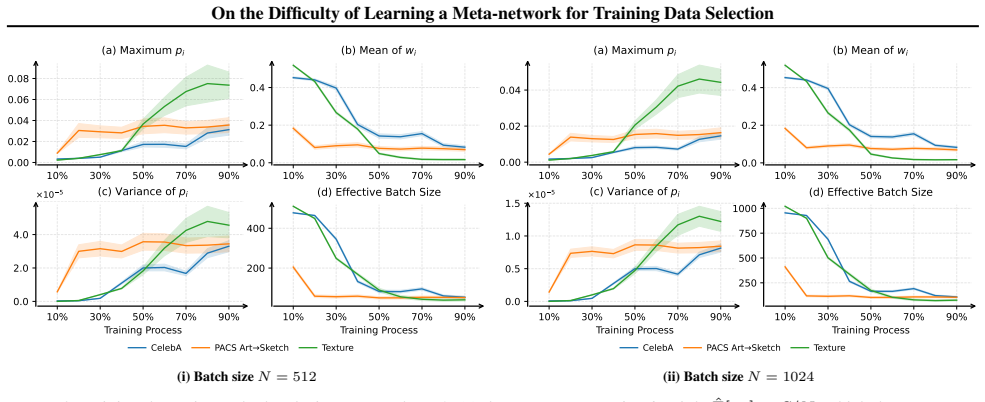
MTS suffers from poor gradient signal-to-noise ratio because data of different quality produce misaligned weight updates; the normalized weight dynamics make this explicit. Enlarging the batch size raises the signal-to-noise ratio. A new feature set that encodes each datum’s location in its empirical distribution and its training trajectory supplies the missing correlation with quality. Together these steps improve selection performance.
What carries the argument
The dynamics of normalized data weights under bi-level optimization, which expose how quality differences degrade the gradient signal-to-noise ratio (GSNR).
If this is right
- Raising batch size during the meta-optimization step improves convergence of the learned data weights.
- Features based on distributional position and training trajectory correlate more strongly with data quality than prior choices.
- The same selection procedure yields higher accuracy on downstream tasks across multiple benchmarks.
- The approach remains compatible with existing bi-level optimization pipelines for data weighting.
Where Pith is reading between the lines
- The batch-size fix may transfer to other bi-level meta-learning problems that also optimize continuous weights.
- The new features could be combined with existing difficulty or uncertainty signals to create hybrid selection criteria.
- If the GSNR analysis generalizes, similar gradient diagnostics might diagnose failures in related meta-optimization settings.
Load-bearing premise
The mathematical link between data-quality differences and low GSNR holds, and the new position-and-dynamics features remain informative outside the four tested benchmarks.
What would settle it
An experiment that measures GSNR while varying batch size and finds no improvement, or that shows the proposed features do not predict which data points most help final accuracy.
Figures

read the original abstract
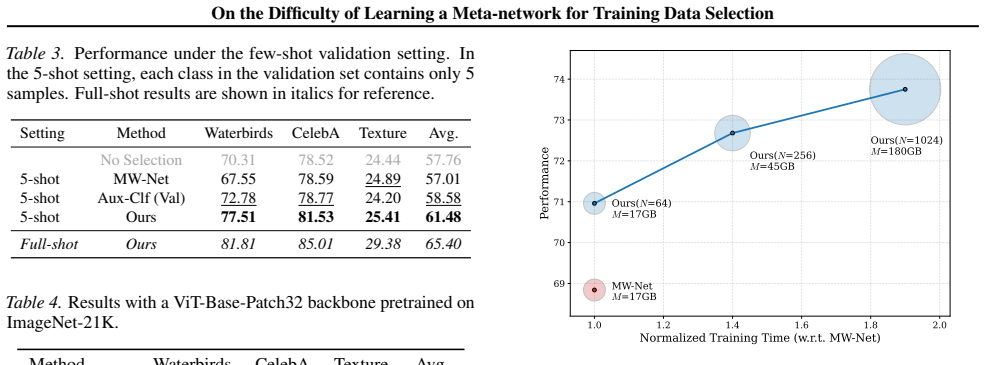
Synthetic data are increasingly used to train neural networks, yet distributional mismatch with real data limits their effectiveness when used indiscriminately. A common strategy is to learn data weights via bi-level optimization, which we refer to as Meta-learning for Training-data Selection (MTS). Interestingly, in practice, MTS often performs below expectation. We identify two obstacles in properly training MTS: a poor gradient signal-to-noise ratio (GSNR), which causes optimization difficulties, and lack of informative features that correlates with data quality. We present a mathematical analysis of MTS, which reveals the dynamics of normalized data weights and the relation between disparate data quality and poor GSNR. The analysis suggests a a simple yet effective solution: increasing the batch size. Further, we propose a set of informative features that capture the positions of training data in their distributions and training dynamics. Experiments across four benchmarks show consistent improvements, achieving average gains of 5.49% over training without selection and 2.89% over the strongest baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines why Meta-learning for Training-data Selection (MTS) via bi-level optimization often underperforms when selecting training data to address distributional mismatch between synthetic and real data. It identifies two obstacles: poor gradient signal-to-noise ratio (GSNR) causing optimization issues and a lack of informative features correlated with data quality. A mathematical analysis of normalized data weight dynamics is presented that relates disparate data quality to degraded GSNR; this leads to the recommendation of increasing batch size. A set of features based on data positions within distributions and training dynamics is proposed. Experiments across four benchmarks report average gains of 5.49% over training without selection and 2.89% over the strongest baseline.
Significance. If the mathematical analysis correctly derives the GSNR issue from the normalized weight dynamics under bi-level optimization and the proposed features prove generalizable, the work supplies both an explanatory account of MTS difficulties and immediately actionable improvements (larger batches plus new features). The consistent empirical gains on multiple benchmarks would then constitute reproducible evidence of practical value for data selection methods.
major comments (1)
- [Mathematical analysis section] The mathematical analysis of normalized data weight dynamics and its claimed link to poor GSNR (the section presenting the bi-level optimization analysis): this derivation is load-bearing for the central recommendation to increase batch size. The analysis must be checked for omitted higher-order terms, the precise handling of normalization, and assumptions on the inner-loop loss landscape; any gap here would leave the causal claim and the batch-size prescription unsupported.
minor comments (2)
- [Abstract] Abstract contains the typo 'suggests a a simple'.
- [Abstract] Abstract: 'lack of informative features that correlates with data quality' should read 'correlate' for subject-verb agreement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for carefully examining the mathematical analysis, which underpins our recommendation to increase batch size. We address the concern below.
read point-by-point responses
-
Referee: [Mathematical analysis section] The mathematical analysis of normalized data weight dynamics and its claimed link to poor GSNR (the section presenting the bi-level optimization analysis): this derivation is load-bearing for the central recommendation to increase batch size. The analysis must be checked for omitted higher-order terms, the precise handling of normalization, and assumptions on the inner-loop loss landscape; any gap here would leave the causal claim and the batch-size prescription unsupported.
Authors: We appreciate the referee's scrutiny of this central section. The derivation starts from the bi-level objective and explicitly incorporates the normalization constraint by expressing data weights via the softmax form w_i = exp(θ_i)/∑exp(θ_j). The GSNR expression is obtained by computing the expectation and variance of the outer-loop gradient estimator; the analysis is first-order in the deviation of inner-loop parameters and does not omit higher-order terms within that regime. Normalization is handled exactly through the Jacobian of the softmax, which cancels the mean component and isolates the variance contribution from disparate data qualities. The inner-loop loss is taken to be locally quadratic, a standard modeling choice that captures the dominant curvature near a stationary point and is consistent with the convex or strongly convex assumptions common in bi-level optimization analyses. We will add an appendix containing the full expanded derivation, an explicit list of all modeling assumptions, and a brief discussion of the regime in which the quadratic approximation holds. The batch-size prescription follows directly from the resulting 1/√B scaling of the noise term and is further corroborated by the empirical results already reported. revision: partial
Circularity Check
No circularity: analysis and experiments presented as independent of fitted inputs.
full rationale
The abstract and reader's summary describe a mathematical analysis of normalized data weight dynamics and GSNR under bi-level optimization that independently motivates the batch-size recommendation, followed by separately proposed features and benchmark experiments showing gains. No equations, self-citations, or derivations in the provided text reduce any claimed result to a fitted parameter, self-definition, or prior author work by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =
Ma, Chao and Ying, Lexing , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =. 2021 , isbn =
2021
-
[4]
M. J. Kearns , title =
-
[5]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[6]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[7]
Suppressed for Anonymity , author=
-
[8]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[9]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[10]
2025 , booktitle=
DeepKD: A Deeply Decoupled and Denoised Knowledge Distillation Trainer , author=. 2025 , booktitle=
2025
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Sun, Zihao and Sun, Yu and Yang, Longxing and Lu, Shun and Mei, Jilin and Zhao, Wenxiao and Hu, Yu , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Michalkiewicz, Mateusz and Faraki, Masoud and Yu, Xiang and Chandraker, Manmohan and Baktashmotlagh, Mahsa , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[13]
International Conference on Computer Vision , year=
Deeper, Broader and Artier Domain Generalization , author=. International Conference on Computer Vision , year=
-
[14]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Places: A 10 million Image Database for Scene Recognition , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[15]
2021 , eprint=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. 2021 , eprint=
2021
-
[16]
8th International Conference on Learning Representations, ICLR 2020 , year=
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization , author=. 8th International Conference on Learning Representations, ICLR 2020 , year=
2020
-
[17]
7th International Conference on Learning Representations, ICLR 2019 , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. 7th International Conference on Learning Representations, ICLR 2019 , year=
2019
-
[18]
Proceedings of International Conference on Computer Vision (ICCV) , month =
Deep Learning Face Attributes in the Wild , author =. Proceedings of International Conference on Computer Vision (ICCV) , month =
-
[19]
Forty-first International Conference on Machine Learning , year=
Not Just Pretty Pictures: Toward Interventional Data Augmentation Using Text-to-Image Generators , author=. Forty-first International Conference on Machine Learning , year=
-
[20]
2023 , eprint=
Bridging the Gap: Enhancing the Utility of Synthetic Data via Post-Processing Techniques , author=. 2023 , eprint=
2023
-
[21]
arXiv , year =
Dunlap, Lisa and Umino, Alyssa and Zhang, Han and Yang, Jiezhi and Gonzalez, Joseph and Darrell, Trevor , title =. arXiv , year =
-
[22]
The Eleventh International Conference on Learning Representations , year=
Is synthetic data from generative models ready for image recognition? , author=. The Eleventh International Conference on Learning Representations , year=
-
[23]
Computer Vision and Pattern Recognition Workshop on Generative Models for Computer Vision , year=
Diversity is Definitely Needed: Improving Model-Agnostic Zero-shot Classification via Stable Diffusion , author=. Computer Vision and Pattern Recognition Workshop on Generative Models for Computer Vision , year=
-
[24]
, title =
Azizi, Shekoofeh and Kornblith, Simon and Saharia, Chitwan and Norouzi, Mohammad and Fleet, David J. , title =. Transactions on Machine Learning Research , year =
-
[25]
The Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Jaewoo Lee and Boyang Li and Sung Ju Hwang , title =. The Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[26]
The Twelfth International Conference on Learning Representations , year=
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs , author=. The Twelfth International Conference on Learning Representations , year=
-
[27]
Proceedings of the ICLR 2023 Workshop on Trustworthy and Reliable Large‐Scale Machine Learning Models , year =
Bansal, Hritik and Grover, Aditya , title =. Proceedings of the ICLR 2023 Workshop on Trustworthy and Reliable Large‐Scale Machine Learning Models , year =
2023
-
[28]
ICML , year=
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels , author=. ICML , year=
-
[29]
NeurIPS , pages=
Co-teaching: Robust training of deep neural networks with extremely noisy labels , author=. NeurIPS , pages=
-
[30]
International Conference on Learning Representations , year=
An Empirical Study of Example Forgetting during Deep Neural Network Learning , author=. International Conference on Learning Representations , year=
-
[31]
NeurIPS , year=
Deep Learning on a Data Diet: Finding Important Examples Early in Training , author=. NeurIPS , year=
-
[32]
Proceedings of EMNLP , url=
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics , author=. Proceedings of EMNLP , url=
-
[33]
Non-greedy gradient-based hyperparameter optimization over long horizons , author=
-
[34]
Advances in neural information processing systems , volume=
Signal-to-noise ratio analysis of policy gradient algorithms , author=. Advances in neural information processing systems , volume=
-
[35]
Advances in Neural Information Processing Systems , volume=
Convergence rates of stochastic gradient descent under infinite noise variance , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Proceedings of the 37th International Conference on Machine Learning , pages =
The Impact of Neural Network Overparameterization on Gradient Confusion and Stochastic Gradient Descent , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[37]
Proceedings of the 39th International Conference on Machine Learning , pages =
Anticorrelated Noise Injection for Improved Generalization , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[38]
Journal of Statistical Mechanics: Theory and Experiment , volume=
The effective noise of stochastic gradient descent , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2022 , publisher=
2022
-
[39]
International Conference on Machine Learning , pages=
On the generalization benefit of noise in stochastic gradient descent , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[40]
International Conference on Machine Learning , pages=
A tail-index analysis of stochastic gradient noise in deep neural networks , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[41]
arXiv preprint arXiv:2001.07384 , year=
Understanding why neural networks generalize well through gsnr of parameters , author=. arXiv preprint arXiv:2001.07384 , year=
-
[42]
International Conference on Machine Learning , pages=
Tighter variational bounds are not necessarily better , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[43]
International conference on machine learning , pages=
Gradient-based hyperparameter optimization through reversible learning , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[44]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[45]
Advances in neural information processing systems , volume=
Meta-learning with implicit gradients , author=. Advances in neural information processing systems , volume=
-
[46]
International conference on artificial intelligence and statistics , pages=
Optimizing millions of hyperparameters by implicit differentiation , author=. International conference on artificial intelligence and statistics , pages=. 2020 , organization=
2020
-
[47]
DARTS: Differentiable Architecture Search
Darts: Differentiable architecture search , author=. arXiv preprint arXiv:1806.09055 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
A stochastic approach to Bi-Level optimization for hyperparameter optimization and meta learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[49]
International Conference on Machine Learning , pages=
idarts: Differentiable architecture search with stochastic implicit gradients , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[50]
NeurIPS , year=
Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting , author=. NeurIPS , year=
-
[51]
arXiv preprint arXiv:2310.15393 , year=
Doge: Domain reweighting with generalization estimation , author=. arXiv preprint arXiv:2310.15393 , year=
-
[52]
International conference on machine learning , pages=
Learning to reweight examples for robust deep learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[53]
IEEE Signal Processing Magazine , volume=
An introduction to bilevel optimization: Foundations and applications in signal processing and machine learning , author=. IEEE Signal Processing Magazine , volume=. 2024 , publisher=
2024
-
[54]
arXiv preprint arXiv:2207.11719 , year=
Gradient-based bi-level optimization for deep learning: A survey , author=. arXiv preprint arXiv:2207.11719 , year=
-
[55]
Advances in Neural Information Processing Systems , volume=
Memory-efficient gradient unrolling for large-scale bi-level optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
International conference on machine learning , pages=
Forward and reverse gradient-based hyperparameter optimization , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[57]
ICML , year=
Efficient Curvature-Aware Hypergradient Approximation for Bilevel Optimization , author=. ICML , year=
-
[58]
ICML , year=
Generalized-Smooth Bilevel Optimization with Nonconvex Lower-Level , author=. ICML , year=
-
[59]
ICML , year=
LLM Data Selection and Utilization via Dynamic Bi-level Optimization , author=. ICML , year=
-
[60]
ICML , year=
Moreau Envelope for Nonconvex Bi-Level Optimization: A Single-Loop and Hessian-Free Solution Strategy , author=. ICML , year=
-
[61]
ICML , year=
SPABA: A Single-Loop and Probabilistic Stochastic Bilevel Algorithm Achieving Optimal Sample Complexity , author=. ICML , year=
-
[62]
ICML , year=
Optimal Hessian/Jacobian-Free Nonconvex-PL Bilevel Optimization , author=. ICML , year=
-
[63]
ICML , year=
Double Momentum Method for Lower-Level Constrained Bilevel Optimization , author=. ICML , year=
-
[64]
ICML , year=
On The Complexity of First-Order Methods in Stochastic Bilevel Optimization , author=. ICML , year=
-
[65]
ICML , year=
A Fully First-Order Method for Stochastic Bilevel Optimization , author=. ICML , year=
-
[66]
ICML , year=
Improving Bi-level Optimization Based Methods with Inspiration from Humans' Classroom Study Techniques , author=. ICML , year=
-
[67]
ICML , year=
On Penalty-based Bilevel Gradient Descent Method , author=. ICML , year=
-
[68]
ICML , year=
BWS: Best Window Selection Based on Sample Scores for Data Pruning across Broad Ranges , author=. ICML , year=
-
[69]
ICML , year=
Adaptively Weighted Data Augmentation Consistency Regularization for Robust Optimization under Concept Shift , author=. ICML , year=
-
[70]
arXiv e-prints , pages=
Fake it till you make it: Learning transferable representations from synthetic ImageNet clones , author=. arXiv e-prints , pages=
-
[71]
Advances in neural information processing systems , volume=
Diversify your vision datasets with automatic diffusion-based augmentation , author=. Advances in neural information processing systems , volume=
-
[72]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Diffusemix: Label-preserving data augmentation with diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ltgc: Long-tail recognition via leveraging llms-driven generated content , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[74]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Semantic-guided generative image augmentation method with diffusion models for image classification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[75]
Proceedings of the 31st ACM international conference on multimedia , pages=
Training multimedia event extraction with generated images and captions , author=. Proceedings of the 31st ACM international conference on multimedia , pages=
-
[76]
Proceedings of the IEEE/CVF CVPR , pages=
Instagen: Enhancing object detection by training on synthetic dataset , author=. Proceedings of the IEEE/CVF CVPR , pages=
-
[77]
International Journal of Computer Vision , pages=
Mosaicfusion: Diffusion models as data augmenters for large vocabulary instance segmentation , author=. International Journal of Computer Vision , pages=. 2024 , publisher=
2024
-
[78]
Proceedings of the IEEE/CVF CVPR , pages=
DiverGen: Improving Instance Segmentation by Learning Wider Data Distribution with More Diverse Generative Data , author=. Proceedings of the IEEE/CVF CVPR , pages=
-
[79]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Will large-scale generative models corrupt future datasets? , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[80]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning vision from models rivals learning vision from data , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.