Less is MoE: Trimming Experts in Domain-Specialist Language Models
Pith reviewed 2026-06-28 03:08 UTC · model grok-4.3
The pith
Fisher importance on FFN intermediate dimensions enables 50% MoE compression while preserving capability on general benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
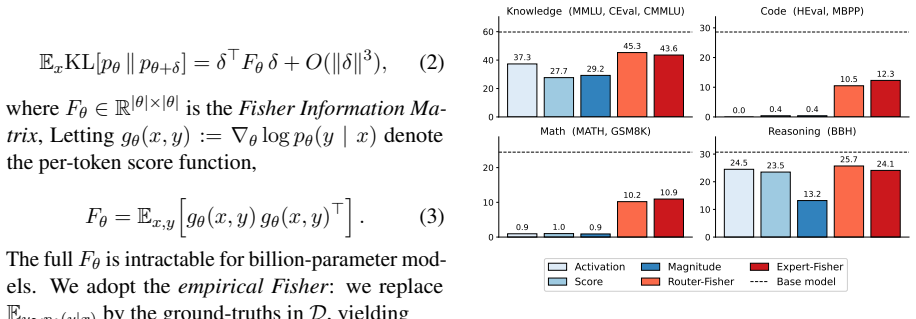
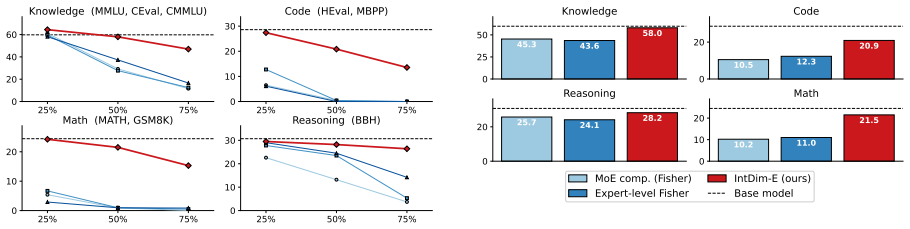
Important capabilities concentrate in tiny sets of FFN sparse intermediate dimensions. Fisher importance ranks these dimensions so that pruning them inside the FFN at a 50% MoE compression ratio preserves model capability on general benchmarks, reduces weight memory by roughly 45%, and improves inference throughput by 21%.
What carries the argument
Fisher-MoE, which prunes FFN intermediate dimensions ranked by Fisher importance within each expert.
If this is right
- Model capability remains intact on general-purpose benchmarks at the same 50% compression ratio.
- Weight memory falls by approximately 45%.
- Inference throughput increases by 21%.
- Fisher importance outperforms activation-based, router-score, and magnitude-based alternatives for dimension ranking.
- Removal of as few as 12 dimensions can collapse performance on specific tasks like GSM8K while leaving factual knowledge largely intact.
Where Pith is reading between the lines
- Dimension-level concentration may exist in other conditional-computation or sparse models outside standard MoE designs.
- The method could be stacked with quantization to reach higher overall compression.
- Checking whether the same Fisher pattern appears under different training regimes would test how general the concentration effect is.
- Sub-expert granularity might offer a new axis for analyzing how capabilities emerge during MoE training.
Load-bearing premise
Fisher importance scores from a given task set will mark dimensions whose removal leaves performance on unseen general benchmarks unchanged.
What would settle it
Applying Fisher-MoE at 50% ratio to a different MoE architecture and observing a drop in accuracy on held-out general benchmarks such as MMLU.
Figures


read the original abstract
Mixture-of-Experts (MoE) models achieve strong performance through conditional computation, but their large parameter footprint poses deployment challenges. Prior MoE compression approaches catastrophically fail when evaluated on general-purpose benchmarks beyond commonsense reasoning. We trace this failure to the granularity of compression: important capabilities are distributed across experts but concentrated in FFN sparse intermediate dimensions. To identify these dimensions, we use Fisher importance which outperforms activation-, router-score-, and magnitude-based alternatives, and identifies tiny sets of task-critical dimensions: in Qwen1.5-MoE, removing as few as 12 of 1.35M routed-FFN intermediate dimensions collapses GSM8K accuracy while largely preserving factual-knowledge performance. Building on this, we propose Fisher-MoE, which operates within FFN to remove intermediate dimensions ranked by Fisher importance. At the same 50% MoE compression ratio, Fisher-MoE preserves model capability, while reducing weight memory by ~45% and improving inference throughput by 21%. These findings suggest intermediate dimension granularity is an effective unit for both compression and ranking where capability concentrates in MoE models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Fisher-MoE, a compression technique for Mixture-of-Experts (MoE) language models that prunes sparse intermediate dimensions in the FFN layers based on Fisher importance scores. It argues that capabilities are concentrated in a small number of these dimensions, as evidenced by the fact that removing just 12 dimensions in Qwen1.5-MoE collapses GSM8K performance while preserving factual knowledge. At a 50% compression ratio, the method is claimed to maintain model capability, reduce weight memory by approximately 45%, and increase inference throughput by 21%, outperforming prior expert-pruning approaches that fail on general-purpose benchmarks.
Significance. If the empirical results hold under broader validation, this work could significantly impact the deployment of large MoE models by demonstrating that dimension-level pruning within experts is a more effective compression strategy than whole-expert removal. The identification of Fisher importance as superior to activation, router-score, and magnitude-based methods for ranking dimensions adds to the understanding of where capabilities concentrate in MoE architectures. The approach offers a parameter-efficient way to trim models while aiming to preserve general capabilities.
major comments (2)
- [Abstract] Abstract: The headline quantitative claims (50% compression ratio preserving capability, ~45% memory reduction, 21% throughput gain) are presented without error bars, full benchmark suite details, or ablation tables, so the robustness of the central claim cannot be assessed from the given text.
- [Abstract and experimental sections] Abstract and §4 (results): The load-bearing assumption that Fisher importance computed on a calibration task set identifies dimensions whose removal preserves performance on truly unseen general-purpose benchmarks is not supported by reported results; only GSM8K collapse and factual-knowledge preservation are mentioned, with no evidence on held-out suites such as MMLU or HumanEval.
minor comments (1)
- [Abstract] Abstract: Clarify the total number of routed-FFN intermediate dimensions (stated as 1.35M) with an explicit reference to the base model architecture and layer configuration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript to improve precision and transparency of the reported claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative claims (50% compression ratio preserving capability, ~45% memory reduction, 21% throughput gain) are presented without error bars, full benchmark suite details, or ablation tables, so the robustness of the central claim cannot be assessed from the given text.
Authors: We agree the abstract would benefit from additional context on the evaluation. Section 4 and the appendix already contain the full benchmark suite, ablation tables, and per-run standard deviations for the reported metrics. In revision we will update the abstract to reference the specific benchmarks evaluated and note that detailed results with variability measures appear in the main text. revision: yes
-
Referee: [Abstract and experimental sections] Abstract and §4 (results): The load-bearing assumption that Fisher importance computed on a calibration task set identifies dimensions whose removal preserves performance on truly unseen general-purpose benchmarks is not supported by reported results; only GSM8K collapse and factual-knowledge preservation are mentioned, with no evidence on held-out suites such as MMLU or HumanEval.
Authors: Our experiments use a calibration set to rank dimensions and then demonstrate that removing the top-ranked dimensions collapses GSM8K while largely preserving factual-knowledge performance. We did not evaluate on MMLU or HumanEval, so we cannot claim preservation on those suites. We will revise the abstract and §4 to state the exact scope of the benchmarks used and remove any phrasing that could be read as implying results on additional held-out general-purpose suites. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central method applies the externally defined Fisher importance estimator (a standard statistical pruning technique) to held-out task data in order to rank and remove FFN intermediate dimensions; the resulting compression ratios and benchmark scores are measured empirically rather than being forced by any self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. No step reduces the claimed performance preservation to an input quantity by construction, and the derivation remains independent of the target result.
Axiom & Free-Parameter Ledger
free parameters (1)
- compression ratio =
50%
axioms (1)
- domain assumption Fisher information provides a reliable ranking of parameter importance for downstream task performance
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.11348 , year=
On linear mode connectivity of mixture-of-experts architectures , author=. arXiv preprint arXiv:2509.11348 , year=
-
[2]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[3]
The Thirteenth International Conference on Learning Representations , year=
Smt: Fine-tuning large language models with sparse matrices , author=. The Thirteenth International Conference on Learning Representations , year=
-
[4]
2025 , eprint=
Sparse Matrix in Large Language Model Fine-tuning , author=. 2025 , eprint=
2025
-
[5]
Preserving Long-Tailed Expert Information in Mixture-of-Experts Tuning
Preserving Long-Tailed Expert Information in Mixture-of-Experts Tuning , author=. arXiv preprint arXiv:2604.23036 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
Solving general arithmetic word problems , author=. Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
2015
-
[8]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Challenging big-bench tasks and whether chain-of-thought can solve them , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[9]
arXiv preprint arXiv:2509.16105 , year=
DiEP: Adaptive Mixture-of-Experts Compression through Differentiable Expert Pruning , author=. arXiv preprint arXiv:2509.16105 , year=
-
[10]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[11]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Cmmlu: Measuring massive multitask language understanding in chinese , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[13]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[15]
Qwen2 Technical Report , author =. arXiv preprint arXiv:2407.10671 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
ArXiv , year=
ZeRO-Offload: Democratizing Billion-Scale Model Training , author=. ArXiv , year=
-
[17]
2023 , version =
Habib, Nathan and Fourrier, Clémentine and Kydlíček, Hynek and Wolf, Thomas and Tunstall, Lewis , title =. 2023 , version =
2023
-
[18]
, author =
Accelerate: Training and inference at scale made simple, efficient and adaptable. , author =
-
[19]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[20]
GitHub repository , howpublished =
Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec , title =. GitHub repository , howpublished =. 2020 , publisher =
2020
-
[22]
2024 , eprint=
OLMoE: Open Mixture-of-Experts Language Models , author=. 2024 , eprint=
2024
-
[23]
International conference on machine learning , pages=
Linear mode connectivity and the lottery ticket hypothesis , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[24]
International Conference on Artificial Intelligence and Statistics , pages=
Proving linear mode connectivity of neural networks via optimal transport , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[25]
arXiv preprint arXiv:2511.05745 , year=
Beyond Redundancy: Diverse and Specialized Multi-Expert Sparse Autoencoder , author=. arXiv preprint arXiv:2511.05745 , year=
-
[26]
arXiv preprint arXiv:2511.10054 , year=
BuddyMoE: Exploiting Expert Redundancy to Accelerate Memory-Constrained Mixture-of-Experts Inference , author=. arXiv preprint arXiv:2511.10054 , year=
-
[27]
arXiv preprint arXiv:2110.06296 , year=
The role of permutation invariance in linear mode connectivity of neural networks , author=. arXiv preprint arXiv:2110.06296 , year=
-
[28]
A Simple and Effective Pruning Approach for Large Language Models
A simple and effective pruning approach for large language models , author=. arXiv preprint arXiv:2306.11695 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
MiniLLM: On-Policy Distillation of Large Language Models
Minillm: Knowledge distillation of large language models , author=. arXiv preprint arXiv:2306.08543 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining , pages=
Beyond answers: Transferring reasoning capabilities to smaller llms using multi-teacher knowledge distillation , author=. Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining , pages=
-
[31]
ACM Transactions on Intelligent Systems and Technology , volume=
A comprehensive survey of small language models in the era of large language models: Techniques, enhancements, applications, collaboration with llms, and trustworthiness , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2025 , publisher=
2025
-
[32]
Towards Efficient Mixture of Experts: A Holistic Study of Compression Techniques , author=
-
[33]
International Conference on Machine Learning , pages=
Retraining-free Merging of Sparse MoE via Hierarchical Clustering , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[34]
International conference on machine learning , pages=
Sparsegpt: Massive language models can be accurately pruned in one-shot , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[35]
Advances in Neural Information Processing Systems , volume=
Compact language models via pruning and knowledge distillation , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
arXiv preprint arXiv:2310.05175 , year=
Outlier weighed layerwise sparsity (owl): A missing secret sauce for pruning llms to high sparsity , author=. arXiv preprint arXiv:2310.05175 , year=
-
[37]
arXiv preprint arXiv:2404.05089 , year=
Seer-moe: Sparse expert efficiency through regularization for mixture-of-experts , author=. arXiv preprint arXiv:2404.05089 , year=
-
[38]
Lu, Xudong and Liu, Qi and Xu, Yuhui and Zhou, Aojun and Huang, Siyuan and Zhang, Bo and Yan, Junchi and Li, Hongsheng. Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10....
-
[39]
Yang, Cheng and Sui, Yang and Xiao, Jinqi and Huang, Lingyi and Gong, Yu and Duan, Yuanlin and Jia, Wenqi and Yin, Miao and Cheng, Yu and Yuan, Bo. M o E -I ^2 : Compressing Mixture of Experts Models through Inter-Expert Pruning and Intra-Expert Low-Rank Decomposition. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.186...
-
[40]
arXiv preprint arXiv:2206.00277 , year=
Task-specific expert pruning for sparse mixture-of-experts , author=. arXiv preprint arXiv:2206.00277 , year=
-
[41]
arXiv preprint arXiv:2410.12013 , year=
Moe-pruner: Pruning mixture-of-experts large language model using the hints from its router , author=. arXiv preprint arXiv:2410.12013 , year=
-
[42]
arXiv preprint arXiv:2409.06211 , year=
Stun: Structured-then-unstructured pruning for scalable moe pruning , author=. arXiv preprint arXiv:2409.06211 , year=
-
[43]
2025 , eprint=
s1: Simple test-time scaling , author=. 2025 , eprint=
2025
-
[44]
Proceedings of machine learning and systems , volume=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of machine learning and systems , volume=
-
[45]
Transactions on Machine Learning Research , issn=
Towards Efficient Mixture of Experts: A Holistic Study of Compression Techniques , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[46]
Forty-second International Conference on Machine Learning , year=
MoE-SVD: Structured Mixture-of-Experts LLMs Compression via Singular Value Decomposition , author=. Forty-second International Conference on Machine Learning , year=
-
[47]
arXiv preprint arXiv:2502.17298 , year=
Delta decompression for moe-based llms compression , author=. arXiv preprint arXiv:2502.17298 , year=
-
[48]
arXiv preprint arXiv:2310.01334 , year=
Merge, then compress: Demystify efficient smoe with hints from its routing policy , author=. arXiv preprint arXiv:2310.01334 , year=
-
[49]
arXiv preprint arXiv:2410.08589 , year=
Retraining-Free Merging of Sparse MoE via Hierarchical Clustering , author=. arXiv preprint arXiv:2410.08589 , year=
-
[50]
arXiv preprint arXiv:2407.00945 , year=
Efficient expert pruning for sparse mixture-of-experts language models: Enhancing performance and reducing inference costs , author=. arXiv preprint arXiv:2407.00945 , year=
-
[51]
arXiv preprint arXiv:2402.12656 , year=
Hypermoe: Towards better mixture of experts via transferring among experts , author=. arXiv preprint arXiv:2402.12656 , year=
-
[52]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[54]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Fluctuation-based adaptive structured pruning for large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[55]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Structured optimal brain pruning for large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[56]
Mengzhou Xia and Tianyu Gao and Zhiyuan Zeng and Danqi Chen , booktitle=. Sheared. 2024 , url=
2024
-
[57]
arXiv preprint arXiv:2310.05015 , year=
Compresso: Structured pruning with collaborative prompting learns compact large language models , author=. arXiv preprint arXiv:2310.05015 , year=
-
[58]
arXiv preprint arXiv:2506.11120 , year=
SDMPrune: Self-Distillation MLP Pruning for Efficient Large Language Models , author=. arXiv preprint arXiv:2506.11120 , year=
-
[59]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Knowledge neurons in pretrained transformers , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[60]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Finding skill neurons in pre-trained transformer-based language models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[61]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Depn: Detecting and editing privacy neurons in pretrained language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[62]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Lepikhin, Dmitry and Lee, HyoukJoong and Xu, Yuanzhong and Chen, Dehao and Firat, Orhan and Huang, Yanping and Krikun, Maxim and Shazeer, Noam and Chen, Zhifeng , booktitle=
-
[64]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[65]
Qwen Blog , year=
Qwen1.5-. Qwen Blog , year=
-
[66]
Advances in Neural Information Processing Systems , volume=
Slimgpt: Layer-wise structured pruning for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
Advances in neural information processing systems , volume=
Optimal brain damage , author=. Advances in neural information processing systems , volume=
-
[68]
and Stork, D.G
Hassibi, B. and Stork, D.G. and Wolff, G.J. , booktitle=. Optimal Brain Surgeon and general network pruning , year=
-
[69]
International Conference on Learning Representations , year=
Pruning convolutional neural networks for resource efficient inference , author=. International Conference on Learning Representations , year=
-
[70]
Advances in Neural Information Processing Systems , volume=
Are sixteen heads really better than one? , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[72]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Shortgpt: Layers in large language models are more redundant than you expect , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[73]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[74]
Locating and editing factual associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and editing factual associations in
-
[75]
International Conference on Learning Representations , year=
A Simple and Effective Pruning Approach for Large Language Models , author=. International Conference on Learning Representations , year=
-
[76]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[77]
Advances in neural information processing systems , volume=
Second order derivatives for network pruning: Optimal brain surgeon , author=. Advances in neural information processing systems , volume=
-
[78]
Advances in neural information processing systems , volume=
Limitations of the empirical fisher approximation for natural gradient descent , author=. Advances in neural information processing systems , volume=
-
[79]
Conference on Language Modeling (COLM) , year=
Massive Activations in Large Language Models , author=. Conference on Language Modeling (COLM) , year=
-
[80]
International Conference on Learning Representations (ICLR) , year=
Efficient Streaming Language Models with Attention Sinks , author=. International Conference on Learning Representations (ICLR) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.