Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches
Pith reviewed 2026-05-21 21:14 UTC · model grok-4.3
The pith
Repository-level code generation should be treated as a coupled evolving process of context building, retrieval, generation, and environment feedback rather than a fixed retrieve-then-generate sequence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
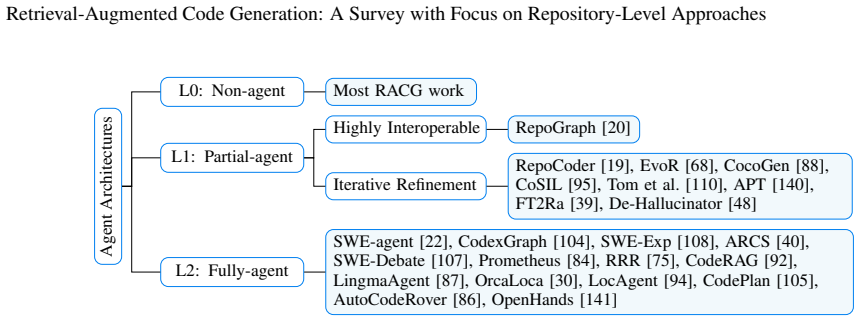
Rather than viewing RACG as a static retrieve-then-generate pipeline, the work characterizes it as a coupled and evolving process involving context construction, retrieval optimization, generation, and environment interaction, and organizes methods through a unified analytical framework spanning retrieval substrate, control regime, and evaluation setting to examine strategies and challenges.
What carries the argument
The three-part analytical framework of retrieval substrate, control regime, and evaluation setting that groups repository-level methods for systematic comparison.
If this is right
- Retrieval approaches can be compared directly across graph-based and non-graph-based paradigms under the same substrate dimension.
- Control regimes clarify distinctions between training-driven optimizations and autonomous agent designs.
- Evaluation settings make it possible to align datasets, benchmarks, and system configurations across studies.
- Challenges in scalability, reliability, efficiency, and the boundary with long-context LLMs become explicit targets for targeted improvements.
Where Pith is reading between the lines
- The framework could be used to test whether hybrid systems that toggle between retrieval and full-context processing improve results on very large repositories.
- Similar three-way breakdowns might apply to repository-scale tasks outside code, such as large-document editing or data pipeline generation.
- Developers could measure an approach's placement in the control-regime dimension to predict how much human oversight it will require in practice.
Load-bearing premise
The proposed three dimensions of retrieval substrate, control regime, and evaluation setting together cover the essential aspects of repository-level approaches and the collected papers form a representative sample of the field.
What would settle it
Emergence of a widely adopted repository-level technique that cannot be placed in any of the three framework categories, or identification of major prior work whose performance contradicts the claimed organization of strategies.
Figures








read the original abstract
Recent advances in large language models (LLMs) have significantly improved automated code generation. While existing approaches have achieved strong performance at the function and file levels, real-world software engineering requires reasoning over entire repositories, including cross-file dependencies, evolving execution environments, and global semantic consistency. This challenge has led to the emergence of Repository-Level Code Generation (RLCG), where models must retrieve, organize, and utilize repository-scale context to generate coherent and executable code changes. To address these challenges, Retrieval-Augmented Generation (RAG) has become an increasingly important paradigm for repository-level code intelligence. In this survey, we present a comprehensive review of Retrieval-Augmented Code Generation (RACG), with a particular focus on repository-level approaches. Rather than viewing RACG as a static ``retrieve-then-generate'' pipeline, we characterize it as a coupled and evolving process involving context construction, retrieval optimization, generation, and environment interaction. We organize existing methods through a unified analytical framework spanning retrieval substrate, control regime, and evaluation setting. Based on this framework, we systematically examine retrieval strategies, graph-based and non-graph-based retrieval paradigms, training-driven optimizations, and autonomous agent architectures. We further summarize widely used datasets, benchmarks, and system configurations, and discuss key challenges including scalability, reliability, efficiency, and the necessity boundary between RACG and long-context LLMs. Through this survey, we aim to provide a structured understanding of the rapidly evolving RACG landscape and highlight promising directions for future AI-powered software engineering research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey reviews Retrieval-Augmented Code Generation (RACG) with emphasis on repository-level approaches. It reframes RACG as a coupled, evolving process of context construction, retrieval optimization, generation, and environment interaction rather than a static retrieve-then-generate pipeline. The authors introduce a unified analytical framework organized along three axes—retrieval substrate, control regime, and evaluation setting—to classify methods, examine graph-based and non-graph-based retrieval, training optimizations, and autonomous agent architectures, summarize datasets and benchmarks, and discuss challenges such as scalability, reliability, efficiency, and the boundary with long-context LLMs.
Significance. If the three-axis framework is shown to be exhaustive and the literature selection transparent and representative, the survey would supply a useful organizing lens for a rapidly growing area. It correctly highlights the shift from pipeline thinking to dynamic interaction with execution environments, which matches practical repository-scale software engineering demands. The explicit treatment of challenges and the necessity boundary with long-context models could usefully direct future work.
major comments (2)
- [§3] §3 (Unified Analytical Framework): The central claim that the three-part framework (retrieval substrate, control regime, evaluation setting) enables systematic examination of strategies rests on the assumption that these axes are sufficient. However, the 'control regime' dimension appears to risk collapsing static retrieval with multi-turn agentic loops that incorporate environment feedback; if iterative feedback loops are not explicitly placed on this axis or require ad-hoc extension, the characterization of RACG as a 'coupled and evolving process' is not fully supported by the framework as described.
- [§2] §2 (Literature Selection and Scope): The abstract asserts that methods are 'systematically examine[d]' under the framework, yet no explicit inclusion criteria, search strategy, or coverage statistics are referenced. Without these, it is impossible to verify that the surveyed corpus is representative enough to ground the unified view; omission of key repository-scale methods would require post-hoc adjustments and weaken the framework's claimed generality.
minor comments (2)
- [Abstract] Abstract: The final sentence on 'promising directions' is vague; naming two or three concrete open problems (e.g., cross-file dependency resolution under evolving environments) would sharpen the contribution statement.
- [Abstract] Terminology: 'RACG' and 'RLCG' are introduced without an explicit statement of their relationship; a short clarifying sentence would prevent reader confusion.
Simulated Author's Rebuttal
Thank you for the detailed review and the recommendation for major revision. We address the major comments point by point below and describe the changes we will implement in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Unified Analytical Framework): The central claim that the three-part framework (retrieval substrate, control regime, evaluation setting) enables systematic examination of strategies rests on the assumption that these axes are sufficient. However, the 'control regime' dimension appears to risk collapsing static retrieval with multi-turn agentic loops that incorporate environment feedback; if iterative feedback loops are not explicitly placed on this axis or require ad-hoc extension, the characterization of RACG as a 'coupled and evolving process' is not fully supported by the framework as described.
Authors: We appreciate this observation on the framework's structure. The control regime axis in our framework is meant to differentiate between various levels of dynamism in the generation process, explicitly including multi-turn agentic loops that interact with the execution environment. However, to prevent any misinterpretation that it collapses categories, we will revise the manuscript to provide a more detailed breakdown of the control regime. This will include explicit placement of iterative feedback mechanisms and better illustrate how they contribute to the coupled and evolving nature of RACG. We believe this clarification will fully support the framework without ad-hoc extensions. revision: yes
-
Referee: [§2] §2 (Literature Selection and Scope): The abstract asserts that methods are 'systematically examine[d]' under the framework, yet no explicit inclusion criteria, search strategy, or coverage statistics are referenced. Without these, it is impossible to verify that the surveyed corpus is representative enough to ground the unified view; omission of key repository-scale methods would require post-hoc adjustments and weaken the framework's claimed generality.
Authors: We agree that transparency in literature selection is essential. Although our review focused on repository-level RACG methods from recent literature, we did not document the process explicitly. In the revision, we will add a 'Literature Search and Selection Methodology' subsection to §2. This will specify search keywords, sources (arXiv, major conferences), time frame, and inclusion criteria (e.g., papers addressing retrieval or control for repo-scale tasks with empirical results). We will also include coverage statistics such as initial retrieval count and final inclusion numbers to demonstrate representativeness and support the framework's generality. revision: yes
Circularity Check
No circularity: survey proposes organizational framework as interpretive tool
full rationale
This paper is a literature survey that introduces a three-part analytical framework (retrieval substrate, control regime, evaluation setting) to organize existing RACG methods and characterize the field as a coupled process. The framework is explicitly presented as an author-proposed structure for systematic examination rather than a quantity derived from equations, fitted parameters, or self-referential definitions within the work. No load-bearing steps reduce claims to inputs by construction, and the review draws on external literature without invoking self-citations for uniqueness theorems or ansatzes. The central contribution is classificatory and interpretive, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The body of published work on repository-level retrieval-augmented code generation can be systematically examined and organized using the dimensions of retrieval substrate, control regime, and evaluation setting.
Forward citations
Cited by 6 Pith papers
-
Do Papers Tell the Whole Story? A Benchmark and Framework for Uncovering Hidden Implementation Gaps in Bioinformatics
BioCon is the first benchmark dataset and cross-modal framework for detecting inconsistencies between methodological descriptions in bioinformatics papers and their code implementations.
-
BLAgent: Agentic RAG for File-Level Bug Localization
BLAgent achieves over 78% Top-1 accuracy on SWE-bench Lite for file-level bug localization using agentic RAG, at 18x lower cost than baselines, and boosts end-to-end APR success by over 20%.
-
SynConfRoute: Syntax-Aware Routing for Efficient Code Completion with Small CodeLLMs
SynConfRoute routes code completions using syntax validation and token confidence, improving pass@1 by up to 31% on hard tasks and reducing accelerator usage by 58% versus always using the largest model.
-
How Does Chunking Affect Retrieval-Augmented Code Completion? A Controlled Empirical Study
Function-based chunking underperforms other strategies in RAG code completion by 3.57-5.64 points, with context length as the dominant factor.
-
Beyond Functional Correctness: Design Issues in AI IDE-Generated Large-Scale Projects
AI IDEs with structured guidance can produce functional large-scale code but frequently introduce design flaws such as duplication, complexity, and principle violations that risk long-term maintainability.
-
Large Language Models for Multilingual Code Intelligence: A Survey
A survey of methods, benchmarks, and open challenges for large language models in multilingual code generation and translation.
Reference graph
Works this paper leans on
-
[1]
OpenAI. Introducing gpt-5. https://openai.com/index/introducing-gpt-5/, August 2025. OpenAI official website
work page 2025
-
[2]
Anthropic. Write beautiful code, ship powerful products. https://www.anthropic.com/solutions/ coding, August 2025. Anthropic official website, “Solutions – Coding” page
work page 2025
-
[3]
Google DeepMind. Gemini. https://deepmind.google/models/gemini/, August 2025. Google DeepMind official website
work page 2025
-
[4]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
- [6]
-
[8]
Github copilot: Your ai pair programmer
GitHub. Github copilot: Your ai pair programmer. https://github.com/features/copilot, August 2025. GitHub features page
work page 2025
-
[9]
Cursor: The ai code editor.https://cursor.com/en, August 2025
Anysphere. Cursor: The ai code editor.https://cursor.com/en, August 2025. Anysphere official website
work page 2025
-
[10]
Windsurf: The ai code editor.https://windsurf.com/, August 2025
Codeium. Windsurf: The ai code editor.https://windsurf.com/, August 2025. Codeium official website
work page 2025
-
[11]
Trae: The real ai engineer.https://www.trae.ai/, August 2025
ByteDance. Trae: The real ai engineer.https://www.trae.ai/, August 2025. ByteDance official website. 28 Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches
work page 2025
-
[12]
OpenAI. Introducing codex. https://openai.com/index/introducing-codex/, May 2025. OpenAI blog post
work page 2025
-
[13]
Google. Gemini cli. https://google-gemini.github.io/gemini-cli/, August 2025. Google official website
work page 2025
-
[14]
Claude code: Deep coding at terminal velocity
Anthropic. Claude code: Deep coding at terminal velocity. https://www.anthropic.com/claude-code, August 2025. Anthropic official website
work page 2025
-
[15]
Xu, Yiqing Xie, Graham Neubig, and Daniel Fried
Zora Zhiruo Wang, Akari Asai, Xinyan Velocity Yu, Frank F. Xu, Yiqing Xie, Graham Neubig, and Daniel Fried. CodeRAG-bench: Can retrieval augment code generation? In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Findings of the Association for Computational Linguistics: NAACL 2025, pages 3199–3214, Albuquerque, New Mexico, April 2025. Association for C...
work page 2025
-
[16]
Kang Chen, Xiuze Zhou, Yuanguo Lin, Shibo Feng, Li Shen, and Pengcheng Wu. A survey on privacy risks and protection in large language models.arXiv preprint arXiv:2505.01976, 2025
-
[17]
Local llm setup for privacy-conscious businesses.God of Prompt (blog), 2025
God of Prompt. Local llm setup for privacy-conscious businesses.God of Prompt (blog), 2025. https: //www.godofprompt.ai/blog/local-llm-setup-for-privacy-conscious-businesses
work page 2025
-
[18]
Knowledge cutoff dates of all llms explained
Otterly.AI Blog. Knowledge cutoff dates of all llms explained. https://otterly.ai/blog/ knowledge-cutoff/, February 2024. Accessed on September 4, 2025
work page 2024
-
[19]
RepoCoder: Repository-level code completion through iterative retrieval and generation
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. RepoCoder: Repository-level code completion through iterative retrieval and generation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2471–2484...
work page 2023
-
[20]
Repograph: Enhancing AI software engineering with repository-level code graph
Siru Ouyang, Wenhao Yu, Kaixin Ma, Zilin Xiao, Zhihan Zhang, Mengzhao Jia, Jiawei Han, Hongming Zhang, and Dong Yu. Repograph: Enhancing AI software engineering with repository-level code graph. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[21]
Teaching code llms to use autocompletion tools in repository-level code generation.ACM Trans
Chong Wang, Jian Zhang, Yebo Feng, Tianlin Li, Weisong Sun, Yang Liu, and Xin Peng. Teaching code llms to use autocompletion tools in repository-level code generation.ACM Trans. Softw. Eng. Methodol., 34(7), August 2025
work page 2025
-
[22]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[23]
A survey on large language models for code generation.ACM Trans
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation.ACM Trans. Softw. Eng. Methodol., July 2025. Just Accepted
work page 2025
-
[24]
Large language model-based agents for software engineering: A survey, 2024
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. Large language model-based agents for software engineering: A survey, 2024
work page 2024
-
[25]
Retrieval-augmented generation for large language models: A survey, 2024
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey, 2024
work page 2024
-
[26]
A survey on rag meeting llms: Towards retrieval-augmented large language models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. A survey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’24, page 6491–6501, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[27]
A survey on code generation with llm-based agents, 2025
Yihong Dong, Xue Jiang, Jiaru Qian, Tian Wang, Kechi Zhang, Zhi Jin, and Ge Li. A survey on code generation with llm-based agents, 2025
work page 2025
-
[28]
Junda He, Christoph Treude, and David Lo. Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead.ACM Trans. Softw. Eng. Methodol., 34(5), May 2025
work page 2025
-
[29]
Yanlin Wang, Wanjun Zhong, Yanxian Huang, Ensheng Shi, Min Yang, Jiachi Chen, Hui Li, Yuchi Ma, Qianxiang Wang, and Zibin Zheng. Agents in software engineering: survey, landscape, and vision.Automated Software Engineering, 32(2):70, 2025
work page 2025
-
[30]
Orcaloca: An LLM agent framework for software issue localization
Zhongming Yu, Hejia Zhang, Yujie Zhao, Hanxian Huang, Matrix Yao, Ke Ding, and Jishen Zhao. Orcaloca: An LLM agent framework for software issue localization. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[31]
Systematic mapping studies in software engineering
Kai Petersen, Robert Feldt, Shahid Mujtaba, and Michael Mattsson. Systematic mapping studies in software engineering. InProceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering, EASE’08, page 68–77, Swindon, GBR, 2008. BCS Learning & Development Ltd. 29 Retrieval-Augmented Code Generation: A Survey with Focus o...
work page 2008
-
[32]
ReACC: A retrieval- augmented code completion framework
Shuai Lu, Nan Duan, Hojae Han, Daya Guo, Seung-won Hwang, and Alexey Svyatkovskiy. ReACC: A retrieval- augmented code completion framework. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6227–6240, Dublin, Ireland, ...
work page 2022
-
[33]
Retrieval-based prompt selection for code-related few-shot learning
Noor Nashid, Mifta Sintaha, and Ali Mesbah. Retrieval-based prompt selection for code-related few-shot learning. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 2450–2462, 2023
work page 2023
-
[34]
Weishi Wang, Yue Wang, Shafiq Joty, and Steven C.H. Hoi. Rap-gen: Retrieval-augmented patch generation with codet5 for automatic program repair. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2023, page 146–158, New York, NY , USA, 2023. Association for Comput...
work page 2023
-
[35]
Daoguang Zan, Bei Chen, Yongshun Gong, Junzhi Cao, Fengji Zhang, Bingchao Wu, Bei Guan, Yilong Yin, and Yongji Wang. Private-library-oriented code generation with large language models.Knowledge-Based Systems, 326:113934, 2025
work page 2025
-
[36]
Domain adaptive code completion via language models and decoupled domain databases
Ze Tang, Jidong Ge, Shangqing Liu, Tingwei Zhu, Tongtong Xu, Liguo Huang, and Bin Luo. Domain adaptive code completion via language models and decoupled domain databases. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 421–433, 2023
work page 2023
-
[37]
Syntax-aware retrieval augmented code generation
Xiangyu Zhang, Yu Zhou, Guang Yang, and Taolue Chen. Syntax-aware retrieval augmented code generation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1291–1302, Singapore, December 2023. Association for Computational Linguistics
work page 2023
-
[38]
Prompt-based code completion via multi-retrieval augmented generation.ACM Trans
Hanzhuo Tan, Qi Luo, Ling Jiang, Zizheng Zhan, Jing Li, Haotian Zhang, and Yuqun Zhang. Prompt-based code completion via multi-retrieval augmented generation.ACM Trans. Softw. Eng. Methodol., March 2025. Just Accepted
work page 2025
-
[39]
Ft2ra: A fine-tuning-inspired approach to retrieval-augmented code completion
Qi Guo, Xiaohong Li, Xiaofei Xie, Shangqing Liu, Ze Tang, Ruitao Feng, Junjie Wang, Jidong Ge, and Lei Bu. Ft2ra: A fine-tuning-inspired approach to retrieval-augmented code completion. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, page 313–324, New York, NY , USA, 2024. Association for Computi...
work page 2024
-
[40]
Arcs: Agentic retrieval-augmented code synthesis with iterative refinement, 2025
Manish Bhattarai, Miguel Cordova, Javier Santos, and Dan O’Malley. Arcs: Agentic retrieval-augmented code synthesis with iterative refinement, 2025
work page 2025
-
[41]
Impact-driven context filtering for cross-file code completion
Yanzhou Li, Shangqing Liu, Kangjie Chen, Tianwei Zhang, and Yang Liu. Impact-driven context filtering for cross-file code completion. InSecond Conference on Language Modeling, 2025
work page 2025
-
[42]
SWE-fixer: Training open- source LLMs for effective and efficient GitHub issue resolution
Chengxing Xie, Bowen Li, Chang Gao, He Du, Wai Lam, Difan Zou, and Kai Chen. SWE-fixer: Training open- source LLMs for effective and efficient GitHub issue resolution. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 1123–1139, Vienna, Austria...
work page 2025
-
[43]
Lei Zhang, Yunshui Li, Jiaming Li, Xiaobo Xia, Jiaxi Yang, Run Luo, Minzheng Wang, Longze Chen, Junhao Liu, Qiang Qu, and Min Yang. Hierarchical context pruning: Optimizing real-world code completion with repository- level pretrained code llms.Proceedings of the AAAI Conference on Artificial Intelligence, 39(24):25886–25894, Apr. 2025
work page 2025
-
[44]
Repomincoder: Improving repository-level code generation based on information loss screening
Yifan Li, Ensheng Shi, Dewu Zheng, Kefeng Duan, Jiachi Chen, and Yanlin Wang. Repomincoder: Improving repository-level code generation based on information loss screening. InProceedings of the 15th Asia-Pacific Symposium on Internetware, Internetware ’24, page 229–238, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[45]
Coret: Improved retriever for code editing, 2025
Fabio Fehr, Prabhu Teja Sivaprasad, Luca Franceschi, and Giovanni Zappella. Coret: Improved retriever for code editing, 2025
work page 2025
-
[46]
Hangzhan Jin and Mohammad Hamdaqa. Ccci: Code completion with contextual information for complex data transfer tasks using large language models, 2025
work page 2025
-
[47]
Hyracc: A hybrid retrieval-augmented framework for more efficient code completion
Chuanyi Li, Jiwei Shang, Yi Feng, and Bin Luo. Hyracc: A hybrid retrieval-augmented framework for more efficient code completion. In2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge), pages 61–66, 2025
work page 2025
-
[48]
Aryaz Eghbali and Michael Pradel. De-hallucinator: Mitigating llm hallucinations in code generation tasks via iterative grounding, 2024. 30 Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches
work page 2024
-
[49]
Improving project-level code generation using combined relevant context
Dmitriy Fedrushkov, Denis Tereshchenko, Sergey Kovalchuk, and Artem Aliev. Improving project-level code generation using combined relevant context. In Michael H. Lees, Wentong Cai, Siew Ann Cheong, Yi Su, David Abramson, Jack J. Dongarra, and Peter M. A. Sloot, editors,Computational Science – ICCS 2025, pages 438–445, Cham, 2025. Springer Nature Switzerland
work page 2025
-
[50]
Jicheng Wang, Yifeng He, and Hao Chen. Repogenreflex: Enhancing repository-level code completion with verbal reinforcement and retrieval-augmented generation, 2024
work page 2024
-
[51]
Selfracg: Enabling llms to self-express and retrieve for code generation, 2025
Qian Dong, Jia Chen, Qingyao Ai, Hongning Wang, Haitao Li, Yi Wu, Yao Hu, Yiqun Liu, and Shaoping Ma. Selfracg: Enabling llms to self-express and retrieve for code generation, 2025
work page 2025
-
[52]
RAR: Retrieval-augmented retrieval for code generation in low resource languages
Avik Dutta, Mukul Singh, Gust Verbruggen, Sumit Gulwani, and Vu Le. RAR: Retrieval-augmented retrieval for code generation in low resource languages. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21506–21515, Miami, Florida, USA, November 2024. A...
work page 2024
-
[53]
PERC: Plan-as-query example retrieval for underrepresented code generation
Jaeseok Yoo, Hojae Han, Youngwon Lee, Jaejin Kim, and Seung-won Hwang. PERC: Plan-as-query example retrieval for underrepresented code generation. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al- Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, pages 7982–79...
work page 2025
-
[54]
Repository-level prompt generation for large language models of code
Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. Repository-level prompt generation for large language models of code. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
work page 2023
-
[55]
Preference- guided refactored tuning for retrieval augmented code generation
Xinyu Gao, Yun Xiong, Deze Wang, Zhenhan Guan, Zejian Shi, Haofen Wang, and Shanshan Li. Preference- guided refactored tuning for retrieval augmented code generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE ’24, page 65–77, New York, NY , USA,
-
[57]
Rewriting the code: A simple method for large language model augmented code search
Haochen Li, Xin Zhou, and Zhiqi Shen. Rewriting the code: A simple method for large language model augmented code search. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1371–1389, Bangkok, Thailand, August 2024. Association for...
work page 2024
-
[58]
Dhruv Gupta, Gayathri Ganesh Lakshmy, and Yiqing Xie. Sacl: Understanding and combating textual bias in code retrieval with semantic-augmented reranking and localization, 2025
work page 2025
-
[59]
Improving repository-level code search with text conversion
Mizuki Kondo, Daisuke Kawahara, and Toshiyuki Kurabayashi. Improving repository-level code search with text conversion. In Yang (Trista) Cao, Isabel Papadimitriou, Anaelia Ovalle, Marcos Zampieri, Francis Ferraro, and Swabha Swayamdipta, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguisti...
work page 2024
-
[60]
Aryan Singhal, Rajat Ghosh, Ria Mundra, Harshil Dadlani, and Debojyoti Dutta. Code2JSON: Can a zero-shot LLM agent extract code features for code RAG? InICLR 2025 Third Workshop on Deep Learning for Code, 2025
work page 2025
-
[61]
Code search is all you need? improving code suggestions with code search
Junkai Chen, Xing Hu, Zhenhao Li, Cuiyun Gao, Xin Xia, and David Lo. Code search is all you need? improving code suggestions with code search. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ICSE ’24, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[62]
Zero-shot cross-domain code search without fine-tuning.Proc
Keyu Liang, Zhongxin Liu, Chao Liu, Zhiyuan Wan, David Lo, and Xiaohu Yang. Zero-shot cross-domain code search without fine-tuning.Proc. ACM Softw. Eng., 2(FSE), June 2025
work page 2025
-
[63]
Yilin Zhang, Xinran Zhao, Zora Zhiruo Wang, Chenyang Yang, Jiayi Wei, and Tongshuang Wu. cast: Enhancing code retrieval-augmented generation with structural chunking via abstract syntax tree, 2025
work page 2025
-
[64]
Ken Deng, Jiaheng Liu, He Zhu, Congnan Liu, Jingxin Li, Jiakai Wang, Peng Zhao, Chenchen Zhang, Yanan Wu, Xueqiao Yin, Yuanxing Zhang, Wenbo Su, Bangyu Xiang, Tiezheng Ge, and Bo Zheng. R2c2-coder: Enhancing and benchmarking real-world repository-level code completion abilities of code large language models, 2024
work page 2024
-
[65]
Dianshu Liao, Shidong Pan, Xiaoyu Sun, Xiaoxue Ren, Qing Huang, Zhenchang Xing, Huan Jin, and Qinying Li. A3A3-CodGen: A Repository-Level Code Generation Framework for Code Reuse With Local-Aware, Global-Aware, and Third-Party-Library-Aware .IEEE Transactions on Software Engineering, 50(12):3369–3384, December 2024
work page 2024
-
[66]
Repofuse: Repository-level code completion with fused dual context, 2024
Ming Liang, Xiaoheng Xie, Gehao Zhang, Xunjin Zheng, Peng Di, wei jiang, Hongwei Chen, Chengpeng Wang, and Gang Fan. Repofuse: Repository-level code completion with fused dual context, 2024. 31 Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches
work page 2024
-
[67]
Rambo: Enhancing rag-based repository-level method body completion, 2024
Tuan-Dung Bui, Duc-Thieu Luu-Van, Thanh-Phat Nguyen, Thu-Trang Nguyen, Son Nguyen, and Hieu Dinh V o. Rambo: Enhancing rag-based repository-level method body completion, 2024
work page 2024
-
[68]
Repogenix: Dual context-aided repository-level code completion with language models
Ming Liang, Xiaoheng Xie, Gehao Zhang, Xunjin Zheng, Peng Di, Wei Jiang, Hongwei Chen, Chengpeng Wang, and Gang Fan. Repogenix: Dual context-aided repository-level code completion with language models. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE ’24, page 2466–2467, New York, NY , USA, 2024. Associat...
work page 2024
-
[69]
EvoR: Evolving retrieval for code generation
Hongjin Su, Shuyang Jiang, Yuhang Lai, Haoyuan Wu, Boao Shi, Che Liu, Qian Liu, and Tao Yu. EvoR: Evolving retrieval for code generation. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Findings of the Association for Computational Linguistics: EMNLP 2024, pages 2538–2554, Miami, Florida, USA, November 2024. Association for Computational Li...
work page 2024
-
[70]
Wenchao Gu, Juntao Chen, Yanlin Wang, Tianyue Jiang, Xingzhe Li, Mingwei Liu, Xilin Liu, Yuchi Ma, and Zibin Zheng. What to retrieve for effective retrieval-augmented code generation? an empirical study and beyond, 2025
work page 2025
-
[71]
Le Deng, Xiaoxue Ren, Chao Ni, Ming Liang, David Lo, and Zhongxin Liu. Enhancing project-specific code completion by inferring internal api information.IEEE Transactions on Software Engineering, pages 1–17, 2025
work page 2025
-
[72]
Stall+: Boosting llm-based repository-level code completion with static analysis, 2024
Junwei Liu, Yixuan Chen, Mingwei Liu, Xin Peng, and Yiling Lou. Stall+: Boosting llm-based repository-level code completion with static analysis, 2024
work page 2024
-
[73]
Lakshya A Agrawal, Aditya Kanade, Navin Goyal, Shuvendu K. Lahiri, and Sriram K. Rajamani. Monitor- guided decoding of code lms with static analysis of repository context. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
work page 2023
-
[74]
Yichen Li, Yun Peng, Yintong Huo, and Michael R. Lyu. Enhancing llm-based coding tools through native integration of ide-derived static context. InProceedings of the 1st International Workshop on Large Language Models for Code, LLM4Code ’24, page 70–74, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[75]
Enhancing repository-level code generation with integrated contextual information, 2024
Zhiyuan Pan, Xing Hu, Xin Xia, and Xiaohu Yang. Enhancing repository-level code generation with integrated contextual information, 2024
work page 2024
-
[76]
Ajinkya Deshpande, Anmol Agarwal, Shashank Shet, Arun Iyer, Aditya Kanade, Ramakrishna Bairi, and Suresh Parthasarathy. Class-level code generation from natural language using iterative, tool-enhanced reasoning over repository, 2024
work page 2024
-
[77]
Dataflow-guided retrieval augmentation for repository-level code completion
Wei Cheng, Yuhan Wu, and Wei Hu. Dataflow-guided retrieval augmentation for repository-level code completion. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7957–7977, Bangkok, Thailand, August 2024. Association for Computation...
work page 2024
-
[78]
Kounianhua Du, Jizheng Chen, Renting Rui, Huacan Chai, Lingyue Fu, Wei Xia, Yasheng Wang, Ruiming Tang, Yong Yu, and Weinan Zhang. Codegrag: Bridging the gap between natural language and programming language via graphical retrieval augmented generation, 2025
work page 2025
-
[79]
Wei Liu, Ailun Yu, Daoguang Zan, Bo Shen, Wei Zhang, Haiyan Zhao, Zhi Jin, and Qianxiang Wang. Graphcoder: Enhancing repository-level code completion via coarse-to-fine retrieval based on code context graph. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE ’24, page 570–581, New York, NY , USA, 2024. Asso...
work page 2024
-
[80]
Xiaohan Chen, Zhongying Pan, Quan Feng, Yu Tian, Shuqun Yang, Mengru Wang, Lina Gong, Yuxia Geng, Piji Li, and Xiang Chen. Saracoder: Orchestrating semantic and structural cues for profit-oriented repository-level code completion, 2025
work page 2025
-
[81]
Context-augmented code generation using programming knowledge graphs
Iman Saberi and Fatemeh Fard. Context-augmented code generation using programming knowledge graphs. arXiv preprint arXiv:2410.18251, 2024
-
[82]
Zhanming Guan, Junlin Liu, Jierui Liu, Chao Peng, Dexin Liu, Ningyuan Sun, Bo Jiang, Wenchao Li, Jie Liu, and Hang Zhu. Contextmodule: Improving code completion via repository-level contextual information.arXiv preprint arXiv:2412.08063, 2024
-
[83]
Enhancing repository- level software repair via repository-aware knowledge graphs, 2025
Boyang Yang, Haoye Tian, Jiadong Ren, Shunfu Jin, Yang Liu, Feng Liu, and Bach Le. Enhancing repository- level software repair via repository-aware knowledge graphs, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.