Reason Twice: Segmentation via Candidate Discovery and Comparative Reasoning
Pith reviewed 2026-06-27 16:59 UTC · model grok-4.3
The pith
Segmentation for complex queries works by first finding candidate masks from attention maps then using an MLLM to reason and pick the highest-scoring one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
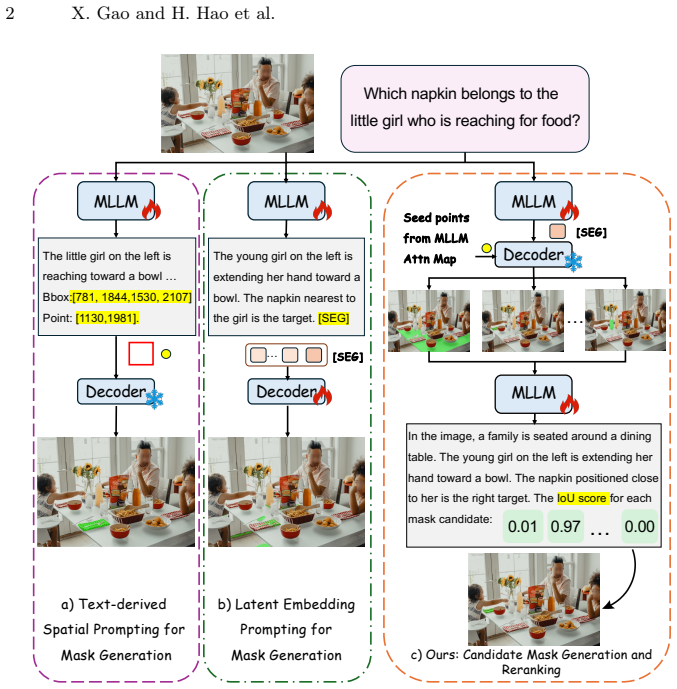
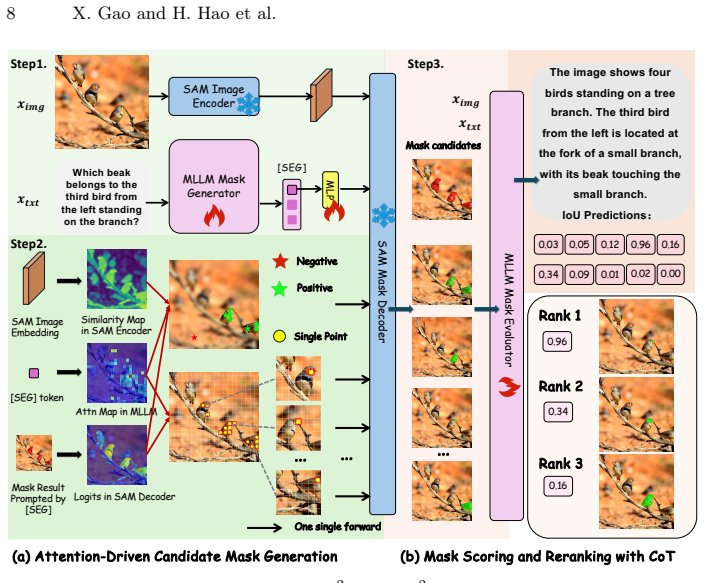
Rea2Seg reformulates image segmentation for complex reasoning queries as a two-stage process: candidate masks are discovered from attention maps of a segmentation MLLM, after which a second MLLM reasons over the query and each candidate to produce scores; the highest-scoring mask is selected as output.
What carries the argument
The Rea2Seg two-stage pipeline that separates mask candidate discovery from comparative reasoning-based selection.
If this is right
- The method separates perception from final mask choice, allowing the MLLM to apply comparative reasoning after initial region proposals.
- Training data collected for scoring enables the MLLM to jointly process queries and candidate masks.
- The new ReasonSeg-SGDR benchmark measures performance across discriminative recognition, spatial reasoning, geometric reasoning, and multi-step reasoning with fine-grained masks.
- Existing benchmarks are noted to emphasize commonsense reasoning that may not fully test joint visual and reasoning demands.
Where Pith is reading between the lines
- The separation into discovery and selection stages could be tested on queries that require iterative refinement beyond a single pass.
- If attention maps prove reliable for candidate generation, similar discovery steps might apply to other MLLM-driven vision tasks that output structured outputs.
- The benchmark's multi-dimension design could serve as a template for evaluating whether gains come from perception, grounding, or the reasoning step itself.
Load-bearing premise
Attention maps from the segmentation MLLM contain the correct mask among the generated candidates even for complex reasoning queries.
What would settle it
If reranking via MLLM reasoning on the ReasonSeg-SGDR benchmark yields no accuracy gain over the raw attention-derived masks or prior direct-generation baselines, the two-stage claim would be falsified.
Figures

read the original abstract
The rapid development of pretrained foundation models has enabled more general image segmentation. Multimodal large language models (MLLMs) have been widely explored for image segmentation with complex queries that require high-level reasoning. Despite promising progress, existing methods are often constrained by limited training data and the gap between MLLMs and mask generation modules. To better transfer MLLMs' perception and reasoning ability to complex reasoning-based segmentation tasks, we propose a two-stage framework Rea2Seg for mask generation and selection. Specifically, the framework first identifies potential regions as candidate masks based on the attention maps of a segmentation MLLM. It then employs an MLLM to reason over the question and candidate masks and assign scores to each mask. The final segmentation result is obtained by reranking the candidates and selecting the highest-scoring mask, reformulating image segmentation as candidate discovery followed by discriminative mask selection. We also notice that a large portion of questions in existing benchmarks focus on commonsense reasoning, and these questions usually do not fully require joint visual observation and reasoning. To address this issue, we introduce a new benchmark called ReasonSeg-SGDR that comprehensively evaluates a model's perception, grounding, and reasoning abilities across multiple dimensions, including discriminative recognition, spatial reasoning, geometric reasoning, and multi-step reasoning, with fine-grained mask generation. In addition, we collect training data to enhance MLLMs' ability to jointly understand multimodal queries and candidate masks, and to assign scores through reasoning. Experimental results on the proposed benchmark and ReasonSeg demonstrate the effectiveness of the unified mask generation and selection framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rea2Seg, a two-stage framework for complex reasoning-based image segmentation with MLLMs. Stage 1 generates candidate masks from attention maps of a segmentation MLLM. Stage 2 uses an MLLM to reason over the query and candidates, assign scores, and select the highest-scoring mask via reranking. The authors introduce the ReasonSeg-SGDR benchmark targeting discriminative recognition, spatial reasoning, geometric reasoning, and multi-step reasoning with fine-grained masks, collect training data for the scoring stage, and claim that experiments on ReasonSeg-SGDR and ReasonSeg demonstrate the framework's effectiveness.
Significance. If the central claims hold, the decoupling of candidate discovery from discriminative selection could be a practical way to leverage MLLM reasoning without retraining mask generators, and ReasonSeg-SGDR would address limitations in existing benchmarks that over-rely on commonsense queries. The approach is a natural extension of current MLLM segmentation work, but its significance cannot be assessed without evidence that the attention-based candidate stage achieves sufficient recall on the new benchmark's harder reasoning dimensions.
major comments (2)
- [Abstract / candidate discovery stage] The load-bearing assumption of the first stage (Abstract and method description) that attention maps from the segmentation MLLM reliably surface a candidate set containing the ground-truth mask is not validated. No recall@K, coverage statistics, or failure-case analysis is reported for multi-step reasoning queries on ReasonSeg-SGDR, where attention may be diffuse or latch onto incorrect salient regions.
- [Abstract / experimental claims] The abstract states that 'experimental results on the proposed benchmark and ReasonSeg demonstrate the effectiveness,' yet no quantitative results, ablation studies, baselines, error bars, or dataset statistics are supplied. This prevents any evaluation of whether the two-stage reranking improves over direct MLLM segmentation or whether the collected training data yields measurable gains.
minor comments (1)
- [Abstract] The benchmark description would benefit from one concrete query example per dimension (discriminative, spatial, geometric, multi-step) to clarify the distinctions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript to incorporate additional validation and experimental details.
read point-by-point responses
-
Referee: [Abstract / candidate discovery stage] The load-bearing assumption of the first stage (Abstract and method description) that attention maps from the segmentation MLLM reliably surface a candidate set containing the ground-truth mask is not validated. No recall@K, coverage statistics, or failure-case analysis is reported for multi-step reasoning queries on ReasonSeg-SGDR, where attention may be diffuse or latch onto incorrect salient regions.
Authors: We agree that explicit validation of the candidate discovery stage is necessary to support the framework, especially on the more challenging multi-step reasoning queries in ReasonSeg-SGDR. The current manuscript prioritizes end-to-end segmentation performance but does not report recall@K, coverage, or failure-case analysis for this stage. We will add these metrics with breakdowns by reasoning dimension and include failure-case discussion in the revision. revision: yes
-
Referee: [Abstract / experimental claims] The abstract states that 'experimental results on the proposed benchmark and ReasonSeg demonstrate the effectiveness,' yet no quantitative results, ablation studies, baselines, error bars, or dataset statistics are supplied. This prevents any evaluation of whether the two-stage reranking improves over direct MLLM segmentation or whether the collected training data yields measurable gains.
Authors: We acknowledge that the current manuscript version does not supply the requested quantitative details, ablations, baselines, error bars, or dataset statistics. We will add these elements, including direct comparisons showing gains from reranking over single-stage MLLM segmentation and the contribution of the collected training data, to substantiate the abstract claims. revision: yes
Circularity Check
No circularity detected; framework is self-contained empirical proposal
full rationale
The paper describes a two-stage Rea2Seg framework that uses attention maps from a segmentation MLLM for candidate mask discovery followed by MLLM-based scoring and reranking. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the abstract or described content. The central claim is an empirical method reformulation supported by a new benchmark and collected training data, with no reduction of outputs to inputs by construction. This matches the most common honest finding of a self-contained proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TPAMI (2017) 4
Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolutional encoder-decoder architecture for image segmentation. TPAMI (2017) 4
2017
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: European Conference on Computer Vision
Bao, X., Sun, S., Ma, S., Zheng, K., Guo, Y., Zhao, G., Zheng, Y., Wang, X.: Cores: Orchestrating the dance of reasoning and segmentation. In: European Conference on Computer Vision. pp. 187–204. Springer (2024) 2, 4, 12
2024
-
[4]
Caesar, H., Uijlings, J., Ferrari, V.: Coco-stuff: Thing and stuff classes in context (2018),https://arxiv.org/abs/1612.0371611, 24
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
arXiv preprint arXiv:2410.08209 (2024) 9
Cao, S., Gui, L.Y., Wang, Y.X.: Emergent visual grounding in large multimodal models without grounding supervision. arXiv preprint arXiv:2410.08209 (2024) 9
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cao, S., Wei, Z., Kuen, J., Liu, K., Zhang, L., Gu, J., Jung, H., Gui, L.Y., Wang, Y.X.: Refer to any segmentation mask group with vision-language prompts. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21853–21863 (2025) 7, 26, 27
2025
-
[7]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
TPAMI (2018) 4
Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI (2018) 4
2018
-
[9]
Chen, X., Elbayad, M., Nguyen, J., Verbeek, J.: VUGEN: Visual understanding priors for GENeration (2026),https://openreview.net/forum?id=tubF5vyrQ05
2026
-
[10]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Chen, X., Mottaghi, R., Liu, X., Fidler, S., Urtasun, R., Yuille, A.: Detect what you can: Detecting and representing objects using holistic models and body parts. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1971–1978 (2014) 11, 24
1971
-
[11]
In: European Conference on Computer Vision
Chen, Y.C., Li, W.H., Sun, C., Wang, Y.C.F., Chen, C.S.: Sam4mllm: Enhance multi-modal large language model for referring expression segmentation. In: European Conference on Computer Vision. pp. 323–340. Springer (2024) 5
2024
-
[12]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=JKEIYQUSUc5
Cheng, A.C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., Liu, S.: SpatialRGPT: Grounded spatial reasoning in vision-language models. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=JKEIYQUSUc5
2024
-
[13]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025) 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Deitke, M., Clark, C., Lee, S., Tripathi, R., Yang, Y., Park, J.S., Salehi, M., Muennighoff, N., Lo, K., Soldaini, L., et al.: Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 91–104 (2025) 25 Reason Twice 17
2025
-
[15]
In: The Fourteenth In- ternational Conference on Learning Representations (2026),https://openreview
Du, T., Li, H., Fan, Z., Zhang, J., Pan, P., Zhang, Y.: SAM-veteran: An MLLM- based human-like SAM agent for reasoning segmentation. In: The Fourteenth In- ternational Conference on Learning Representations (2026),https://openreview. net/forum?id=oN55r8iJJW5
2026
-
[16]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id=DgH9YCsqWm5, 7, 26, 28
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R., Shan, C., He, R.: MME: A comprehensive evaluation benchmark for multimodal large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025),https://openreview.net/forum?id...
2025
-
[17]
In: CVPR (2019) 4
Fu, J., Liu, J., Tian, H., Li, Y., Bao, Y., Fang, Z., Lu, H.: Dual attention network for scene segmentation. In: CVPR (2019) 4
2019
-
[18]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum? id=ILr4UNiZcQ5
Han, J., Chen, H., Zhao, Y., Wang, H., Zhao, Q., Yang, Z., He, H., Yue, X., Jiang, L.: Vision as a dialect: Unifying visual understanding and generation via text-aligned representations. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum? id=ILr4UNiZcQ5
2025
-
[19]
In: Proceedings of the IEEE international conference on computer vision
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision. pp. 2961–2969 (2017) 4
2017
-
[20]
In: The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29,
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29,
2022
-
[21]
OpenReview.net (2022),https://openreview.net/forum?id=nZeVKeeFYf912
2022
-
[22]
arXiv preprint arXiv:2505.22596 (2025) 5, 13
Huang, J., Xu, Z., Zhou, J., Liu, T., Xiao, Y., Ou, M., Ji, B., Li, X., Yuan, K.: Sam-r1: Leveraging sam for reward feedback in multimodal segmentation via reinforcement learning. arXiv preprint arXiv:2505.22596 (2025) 5, 13
-
[23]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019) 11, 29
2019
-
[24]
In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=mzL19kKE3r3, 5
Jang, D., Cho, Y., Lee, S., Kim, T., Kim, D.: MMR: A large-scale benchmark dataset for multi-target and multi-granularity reasoning segmentation. In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=mzL19kKE3r3, 5
2025
-
[25]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Johnson, J., Hariharan, B., Van Der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., Girshick, R.: Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2901–2910 (2017) 27
2017
-
[26]
arXiv preprint arXiv:2503.03321 , year=
Kang, S., Kim, J., Kim, J., Hwang, S.J.: See what you are told: Visual attention sink in large multimodal models. arXiv preprint arXiv:2503.03321 (2025) 9
-
[27]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Kang, S., Kim, J., Kim, J., Hwang, S.J.: Your large vision-language model only needs a few attention heads for visual grounding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9339–9350 (2025) 3, 5, 9
2025
-
[28]
In: EMNLP (2014) 2, 11, 24
Kazemzadeh, S., Ordonez, V., Matten, M., Berg, T.: Referitgame: Referring to objects in photographs of natural scenes. In: EMNLP (2014) 2, 11, 24
2014
-
[29]
Advances in Neural Information Processing Systems36, 29914–29934 (2023) 7
Ke, L., Ye, M., Danelljan, M., Tai, Y.W., Tang, C.K., Yu, F., et al.: Segment anything in high quality. Advances in Neural Information Processing Systems36, 29914–29934 (2023) 7
2023
-
[30]
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. arXiv:2304.02643 (2023) 2 18 X. Gao and H. Hao et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning segmentation via large language model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9579–9589 (2024) 2, 3, 4, 5, 7, 9, 11, 12, 13, 24
2024
-
[32]
In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=vkakKdznFS5
Lan, M., Chen, C., Zhou, Y., Xu, J., Ke, Y., Wang, X., Feng, L., Zhang, W.: Text4seg: Reimagining image segmentation as text generation. In: The Thirteenth International Conference on Learning Representations (2025),https: //openreview.net/forum?id=vkakKdznFS5
2025
-
[33]
Computer vision and image understanding 184, 45–56 (2019) 7, 26
Le, T.N., Nguyen, T.V., Nie, Z., Tran, M.T., Sugimoto, A.: Anabranch network for camouflaged object segmentation. Computer vision and image understanding 184, 45–56 (2019) 7, 26
2019
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025) 2, 4
Li, Z., Yang, B., Liu, Q., Zhang, S., Ma, Z., Yin, L., Deng, L., Sun, Y., Liu, Y., Bai, X.: Lira: Inferring segmentation in large multi-modal models with local interleaved region assistance. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025) 2, 4
2025
-
[35]
In: Winter Conference on Applications of Computer Vision (WACV) (2021) 7, 26
Liew, J.H., Cohen, S., Price, B., Mai, L., Feng, J.: Deep interactive thin object selection. In: Winter Conference on Applications of Computer Vision (WACV) (2021) 7, 26
2021
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, C., Ding, H., Jiang, X.: Gres: Generalized referring expression segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 23592–23601 (2023) 4, 7, 26, 27
2023
-
[37]
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning (2023) 11, 24
2023
-
[38]
In: CVPR (2026) 5
Liu, J., Feng, M., Chen, L.: Better, stronger, faster: Tackling the trilemma in mllm- based segmentation with simultaneous textual mask prediction. In: CVPR (2026) 5
2026
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, R., Liu, C., Bai, Y., Yuille, A.L.: Clevr-ref+: Diagnosing visual reasoning with referring expressions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4185–4194 (2019) 7, 26, 27
2019
-
[40]
arXiv preprint arXiv:2509.18094 (2025) 5
Liu, Y., Ma, Z., Pu, J., Qi, Z., Wu, Y., Shan, Y., Chen, C.W.: Unipixel: Unified object referring and segmentation for pixel-level visual reasoning. arXiv preprint arXiv:2509.18094 (2025) 5
-
[41]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Liu, Y., Peng, B., Zhong, Z., Yue, Z., Lu, F., Yu, B., Jia, J.: Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement. arXiv preprint arXiv:2503.06520 (2025) 5, 12, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
arXiv preprint arXiv:2505.12081 (2025) 5, 12
Liu, Y., Qu, T., Zhong, Z., Peng, B., Liu, S., Yu, B., Jia, J.: Visionreasoner: Unified visual perception and reasoning via reinforcement learning. arXiv preprint arXiv:2505.12081 (2025) 5, 12
-
[43]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017) 24
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
arXiv preprint arXiv:2506.04277 (2025) 13
Lu, Y., Cao, J., Wu, Y., Li, B., Tang, L., Ji, Y., Wu, C., Wu, J., Zhu, W.: Rsvp: Reasoning segmentation via visual prompting and multi-modal chain-of-thought. arXiv preprint arXiv:2506.04277 (2025) 13
-
[45]
arXiv preprint arXiv:2510.11173 (2025) 3, 5, 13
Lu, Z., Li, L., Wang, J., Feng, Y., Chen, B., Chen, K., Wang, Y.: Coprs: Learning positional prior from chain-of-thought for reasoning segmentation. arXiv preprint arXiv:2510.11173 (2025) 3, 5, 13
-
[46]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ma, W., Chen, H., Zhang, G., Chou, Y.C., Chen, J., de Melo, C., Yuille, A.: 3dsrbench: A comprehensive 3d spatial reasoning benchmark. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6924–6934 (2025) 5 Reason Twice 19
2025
-
[47]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Generation and comprehension of unambiguous object descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 11–20 (2016) 11, 25
2016
-
[48]
Minaee, S., Boykov, Y., Porikli, F., Plaza, A., Kehtarnavaz, N., Terzopoulos, D.: Image segmentation using deep learning: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence44(7), 3523–3542 (2022).https://doi.org/10. 1109/TPAMI.2021.30599684
-
[49]
In: ECCV (2016) 2
Nagaraja, V.K., Morariu, V.I., Davis, L.S.: Modeling context between objects for referring expression understanding. In: ECCV (2016) 2
2016
-
[50]
In: ICCV (2015) 4
Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: ICCV (2015) 4
2015
-
[51]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Park, J.S., Ma, Z., Li, L., Zheng, C., Hsieh, C.Y., Lu, X., Chandu, K., Kong, Q., Kobori, N., Farhadi, A., et al.: Synthetic visual genome. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9073–9086 (2025) 25
2025
-
[53]
In: International Conference on Computer Vision (ICCV) (October 2023) 7, 11, 26, 27, 29
Qi, L., Kuen, J., Shen, T., Gu, J., Guo, W., Jia, J., Lin, Z., Yang, M.H.: High- quality entity segmentation. In: International Conference on Computer Vision (ICCV) (October 2023) 7, 11, 26, 27, 29
2023
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025) 2, 4, 7, 9
Qian, R., Yin, X., Dou, D.: Reasoning to attend: Try to understand how< seg> token works. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025) 2, 4, 7, 9
2025
-
[55]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qian, R., Yin, X., Dou, D.: Reasoning to attend: Try to understand how< seg> token works. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24722–24731 (2025) 9, 12, 13
2025
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Qin, J., Wu, J., Yan, P., Li, M., Yuxi, R., Xiao, X., Wang, Y., Wang, R., Wen, S., Pan, X., Wang, X.: Freeseg: Unified, universal and open-vocabulary image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19446–19455 (June 2023) 4
2023
-
[57]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 4
2021
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rasheed, H., Maaz, M., Shaji, S., Shaker, A., Khan, S., Cholakkal, H., Anwer, R.M., Xing, E., Yang, M.H., Khan, F.S.: Glamm: Pixel grounding large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13009–13018 (June 2024) 5
2024
-
[59]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024) 4, 25
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models (2024),https://arxiv.org/abs/2402.033005
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
TPAMI (2017) 4
Shelhamer, E., Long, J., Darrell, T.: Fully convolutional networks for semantic segmentation. TPAMI (2017) 4
2017
-
[62]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., Nathan, A., Luo, A., Helyar, A., Madry, A., Efremov, A., Spyra, A., Baker-Whitcomb, A., Beutel, A., Karpenko, A., 20 X. Gao and H. Hao et al. Makelov, A., Neitz, A., Wei, A., Barr, A., Kirchmeyer, A., Ivanov, A., Christakis, A., Gille...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Springer Nature (2022) 4
Szeliski, R.: Computer vision: algorithms and applications. Springer Nature (2022) 4
2022
-
[64]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum?id=8omLr8BtjL2, 4
Tang, H., Xie, C.W., Wang, H., Bao, X., Weng, T., Li, P., Zheng, Y., Wang, L.: UFO: A unified approach to fine-grained visual perception via open-ended language interface. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum?id=8omLr8BtjL2, 4
2025
-
[65]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., Mesnard, T., Cideron, G., bastien Grill, J., Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., Liu, G., Visin, F., Kenealy, K., Beyer, L., Zhai, X., Tsitsulin, A., Busa-Fekete, R., Feng, A., Sachdeva, N., Cole...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https:// openreview.net/forum?id=h3lyFa5e1W5
Wan, Z., Dou, Z., Liu, C., Zhang, Y., Cui, D., Zhao, Q., Shen, H., Xiong, J., Xin, Y., Jiang, Y., Tao, C., He, Y., Zhang, M., Yan, S.: SRPO: Enhancing multimodal LLM reasoning via reflection-aware reinforcement learning. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https:// openreview.net/forum?id=h3lyFa5e1W5
2025
-
[67]
In: European Conference on Computer Vision
Wang, H., Tang, H., Jiang, L., Shi, S., Naeem, M.F., Li, H., Schiele, B., Wang, L.: Git: Towards generalist vision transformer through universal language interface. In: European Conference on Computer Vision. pp. 55–73. Springer (2024) 4
2024
-
[68]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, H., Qiao, L., Jie, Z., Huang, Z., Feng, C., Zheng, Q., Ma, L., Lan, X., Liang, X.: X-sam: From segment anything to any segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 26187–26196 (2026) 4
2026
-
[69]
Wang, K., Pan, J., Shi, W., Lu, Z., Ren, H., Zhou, A., Zhan, M., Li, H.: MeasuringmultimodalmathematicalreasoningwithMATH-visiondataset.In:The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2024),https://openreview.net/forum?id=QWTCcxMpPA5
2024
-
[70]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, P., Li, Z.Z., Yin, F., Ran, D., Liu, C.L.: Mv-math: Evaluating multimodal math reasoning in multi-visual contexts. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19541–19551 (2025) 5
2025
-
[71]
In: The Thirty- ninth Annual Conference on Neural Information Processing Systems (2025),https: //openreview.net/forum?id=rud3M6wlxH5
Wang, X., Ru, L., Huang, Z., Ji, K., Zheng, D., Chen, J., ZHOU, J.: ARGenseg: Image segmentation with autoregressive image generation model. In: The Thirty- ninth Annual Conference on Neural Information Processing Systems (2025),https: //openreview.net/forum?id=rud3M6wlxH5
2025
-
[72]
In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/forum?id=Pm1NXHgzyf5
Wang, X., Zhang, S., Li, S., Li, K., Kallidromitis, K., Kato, Y., Kozuka, K., Darrell, T.: SegLLM: Multi-round reasoning segmentation with large language models. In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/forum?id=Pm1NXHgzyf5
2025
-
[73]
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Wang, Y., Wu, S., Zhang, Y., Yan, S., Liu, Z., Luo, J., Fei, H.: Multimodal chain- of-thought reasoning: A comprehensive survey. arXiv preprint arXiv:2503.12605 (2025) 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
arXiv preprint arXiv:2411.17606 (2024) 4
Wei, C., Zhong, Y., Tan, H., Liu, Y., Zhao, Z., Hu, J., Yang, Y.: Hyperseg: Towards universal visual segmentation with large language model. arXiv preprint arXiv:2411.17606 (2024) 4
-
[75]
In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K
Wei, J., Wang, X., Schuurmans, D., Bosma, M., brian ichter, Xia, F., Chi, E.H., Le, Q.V., Zhou, D.: Chain of thought prompting elicits reasoning in large language models. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural Information Processing Systems (2022),https://openreview.net/forum? id=_VjQlMeSB_J5
2022
-
[76]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, T.H., Biamby, G., Chan, D., Dunlap, L., Gupta, R., Wang, X., Gonzalez, J.E., Darrell, T.: See say and segment: Teaching lmms to overcome false premises. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13459–13469 (2024) 2, 4, 7, 9, 12
2024
-
[77]
In: Proceedings of the Reason Twice 23 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xia, Z., Han, D., Han, Y., Pan, X., Song, S., Huang, G.: Gsva: Generalized segmentation via multimodal large language models. In: Proceedings of the Reason Twice 23 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3858–3869 (June 2024) 2, 4
2024
-
[78]
Xiao, Y., Sun, E., Liu, T., Wang, W.: Logicvista: Multimodal llm logical reasoning benchmark in visual contexts (2024),https://arxiv.org/abs/2407.049735
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xu, G., Jin, P., Wu, Z., Li, H., Song, Y., Sun, L., Yuan, L.: Llava-cot: Let vision language models reason step-by-step. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2087–2098 (2025) 25
2087
-
[80]
In:TheThirty-ninthAnnualConferenceonNeuralInformationProcessingSystems (2025),https://openreview.net/forum?id=uWEcZkrSkZ5
Xu, J., Fei, H., Zhang, Y., Pan, L., Huang, Q., Liu, Q., Nakov, P., Kan, M.Y., Wang, W.Y., Lee, M.L., Hsu, W.: MuSLR: Multimodal symbolic logical reasoning. In:TheThirty-ninthAnnualConferenceonNeuralInformationProcessingSystems (2025),https://openreview.net/forum?id=uWEcZkrSkZ5
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.