Mechanistic Interpretability and Causal Feature Steering of Neural Quantum States via Sparse Autoencoders
Pith reviewed 2026-07-03 20:14 UTC · model grok-4.3
The pith
Sparse autoencoders extract features from neural quantum states that causally steer physical observables through single-feature interventions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
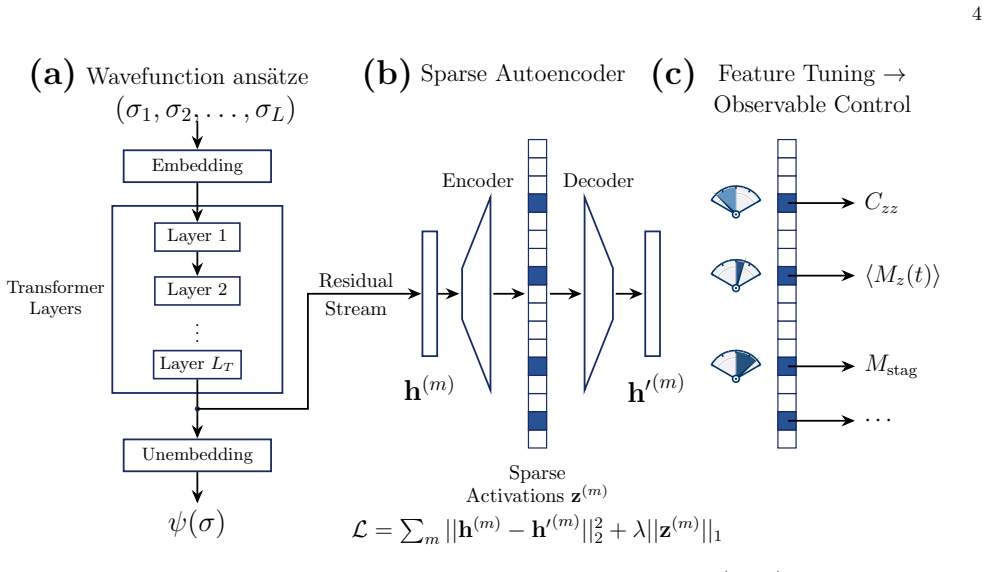
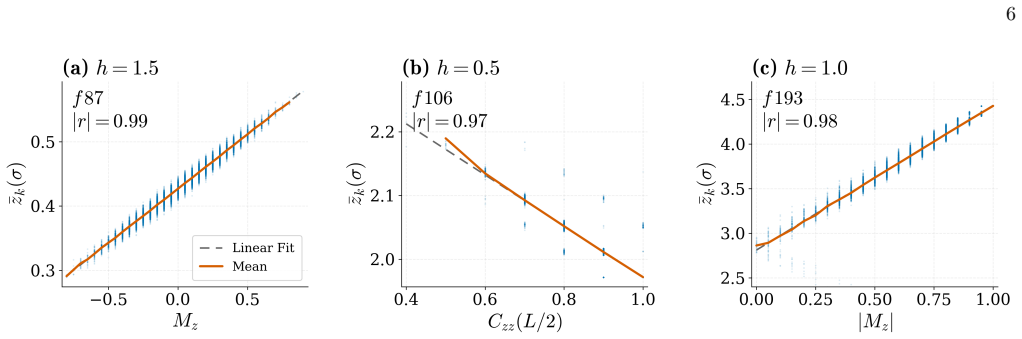
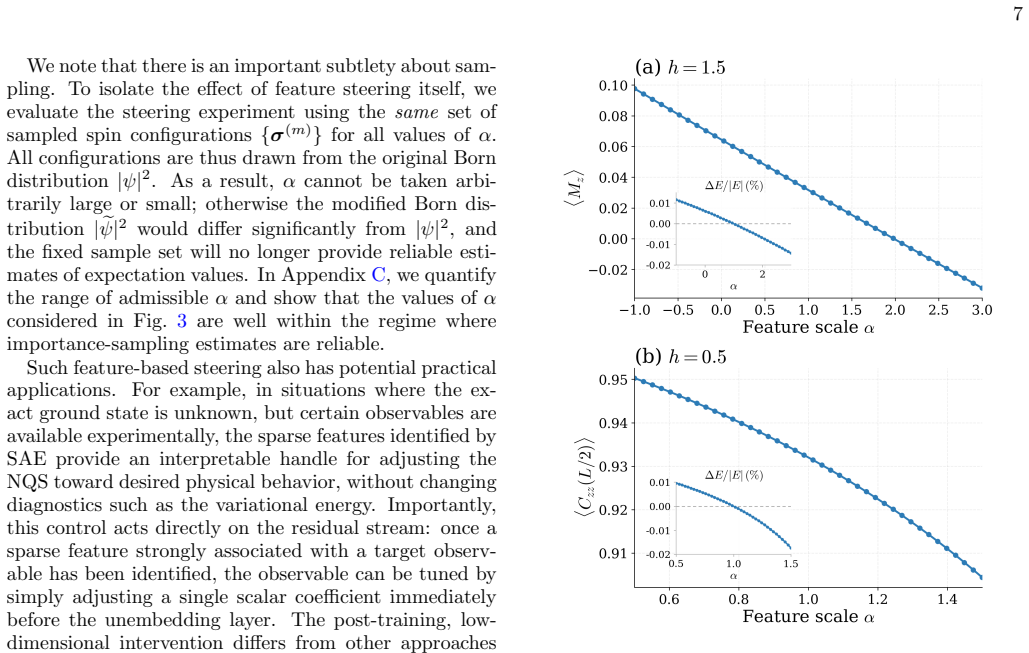
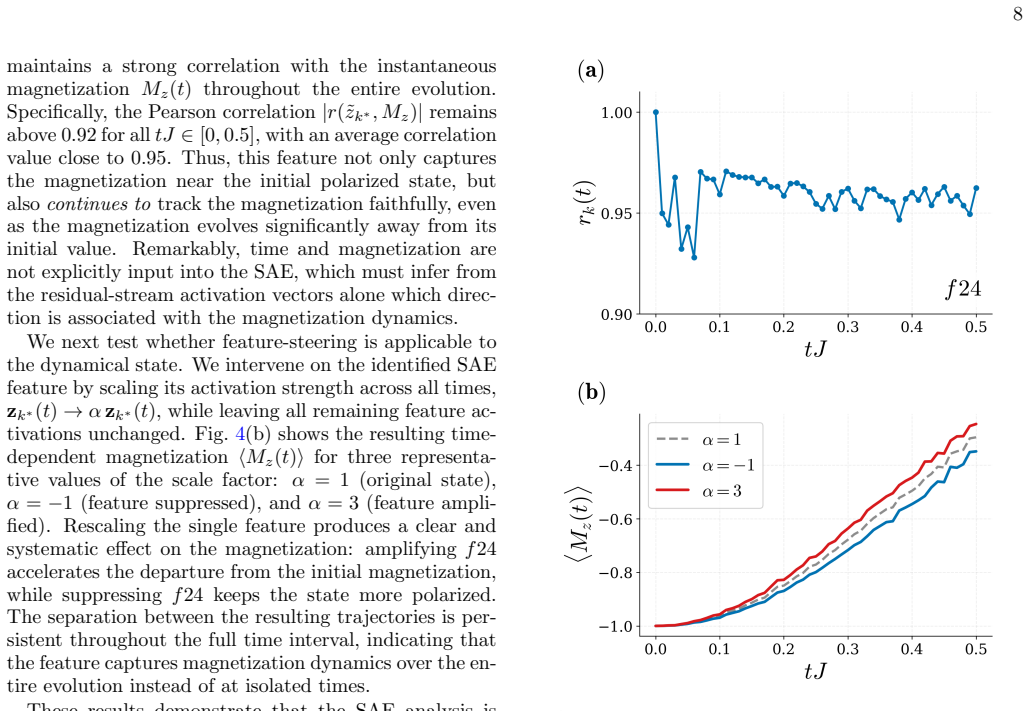
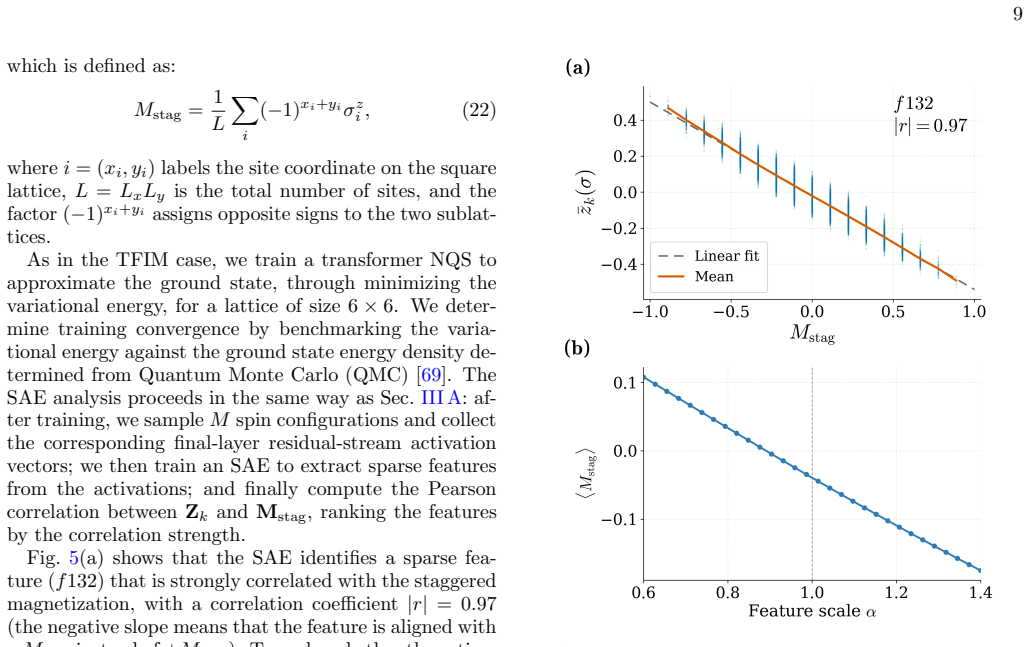
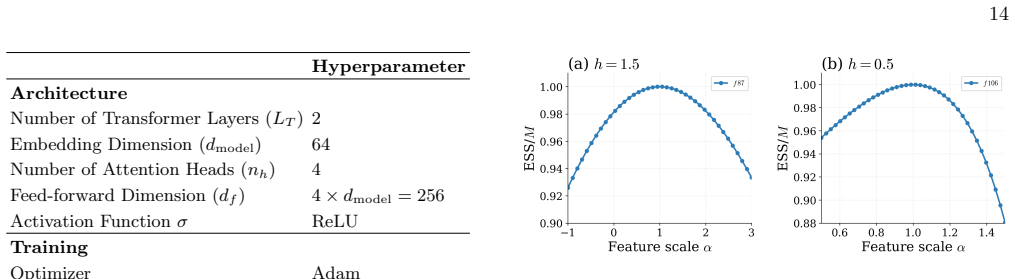
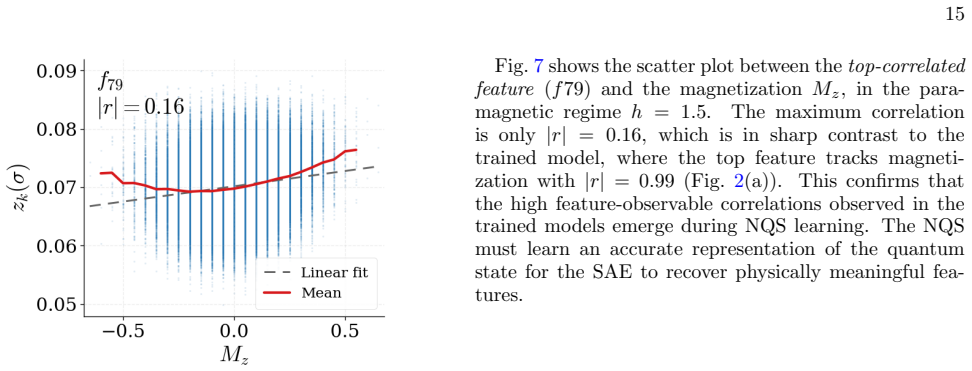
Neural quantum states contain internal activations that sparse autoencoders decompose into features correlating with physical observables. Intervention on a single such feature after training produces smooth, monotonic changes to the matching observable while the variational energy stays nearly unchanged, confirming causal influence rather than mere correlation.
What carries the argument
Sparse autoencoders applied to the residual stream activations of the neural quantum state network, which isolate sparse features that serve as direct controls for observables.
If this is right
- NQS predictions for observables can be diagnosed and adjusted post-training without retraining the full network.
- Physical information such as order parameters is represented internally even when the training objective only minimizes energy.
- The same feature extraction and steering process works for both ground-state representations and real-time quantum dynamics.
- Unsupervised feature discovery provides a general diagnostic tool for understanding how variational wavefunctions capture many-body physics.
Where Pith is reading between the lines
- The method could be tested on other variational ansatze to check whether similar causal features appear across different network architectures.
- Steering might be combined with symmetry constraints to enforce conservation laws during inference.
- Feature interventions could serve as a probe for how training data influences the emergence of specific physical representations.
Load-bearing premise
The features found by the autoencoders are the direct causes of the observed changes in physical quantities rather than incidental correlations that interventions happen to affect.
What would settle it
An experiment in which editing the identified feature alters the target observable in the predicted direction but also produces large unintended shifts in variational energy or unrelated observables would falsify the claim of isolated causal control.
Figures
read the original abstract
Neural Quantum States (NQS) are a remarkably expressive class of variational ans\"atze for quantum many-body wavefunctions, yet little is understood about their internal mechanisms: trained on variational objectives alone, how do NQS accurately capture physical observables that they have never been explicitly optimized for? In this work, we present a systematic approach to analyze the internal activations of NQS using sparse autoencoders. We extract features from the residual stream and demonstrate that these features strongly correlate with physical observables such as order parameters, staggered magnetization, and half-chain correlators, across both ground state representation and real-time dynamics. Remarkably, the discovery of these features is entirely unsupervised, with no physical labels provided. We further establish that such features causally affect the corresponding observables predicted by NQS, by showing that targeted, post-training intervention on a \textit{single} feature smoothly and monotonically steers the corresponding observable, while leaving the variational energy nearly unchanged. These results demonstrate that NQS are not merely functional approximators, but encode rich, interpretable internal representations of physical information. Our approach provides both a diagnostic and an intervention tool for NQS, and serves as a foundation for using mechanistic interpretability towards more reliable, transparent NQS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper applies sparse autoencoders to the residual stream activations of Neural Quantum States (NQS) to extract unsupervised features. These features are reported to correlate strongly with physical observables (order parameters, staggered magnetization, half-chain correlators) in both ground-state and real-time dynamics settings. The central empirical claim is that post-training intervention on a single extracted feature produces smooth, monotonic steering of the corresponding observable while leaving the variational energy nearly unchanged, establishing causal influence and showing that NQS encode interpretable physical representations.
Significance. If the intervention results hold under rigorous controls, the work supplies both a diagnostic tool and a causal intervention method for NQS, moving the field from purely variational optimization toward mechanistic understanding. The unsupervised discovery of physically meaningful features and the energy-invariance check are concrete strengths that could improve reliability and transparency of neural ansätze in quantum many-body problems.
major comments (2)
- [Abstract] Abstract and methods description: the central claim of smooth monotonic steering via single-feature intervention is presented without any reported datasets (Hamiltonians, lattice sizes), number of independent runs, error bars, or quantitative metrics (e.g., Pearson coefficients or p-values for monotonicity). These details are load-bearing for evaluating whether the observed steering is robust or an artifact of particular choices.
- The causal interpretation rests on the intervention experiments isolating the target observable. Without explicit controls (e.g., random-feature baselines, ablation of multiple features, or checks that other observables remain unaffected), it remains unclear whether the reported energy invariance fully rules out unintended side effects on the network.
minor comments (2)
- Notation for the residual stream and SAE reconstruction loss should be defined explicitly on first use, including the sparsity penalty coefficient.
- Figure captions should state the precise system sizes and Hamiltonian parameters used for each panel to allow direct comparison with the text.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments, which highlight important aspects of clarity and rigor in presenting our results. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods description: the central claim of smooth monotonic steering via single-feature intervention is presented without any reported datasets (Hamiltonians, lattice sizes), number of independent runs, error bars, or quantitative metrics (e.g., Pearson coefficients or p-values for monotonicity). These details are load-bearing for evaluating whether the observed steering is robust or an artifact of particular choices.
Authors: The Methods section and figure captions of the manuscript specify the Hamiltonians (transverse-field Ising and related models), lattice sizes, training procedures, and number of independent runs, while error bars and correlation metrics appear in the results figures. The abstract was written at a high level for brevity. We agree that incorporating key experimental parameters into the abstract will improve evaluability and have revised the abstract accordingly to reference the systems studied and the quantitative metrics employed. revision: yes
-
Referee: The causal interpretation rests on the intervention experiments isolating the target observable. Without explicit controls (e.g., random-feature baselines, ablation of multiple features, or checks that other observables remain unaffected), it remains unclear whether the reported energy invariance fully rules out unintended side effects on the network.
Authors: The near-invariance of the variational energy under single-feature intervention serves as our primary control, indicating that the change is localized rather than a global disruption of the network's optimization. We also examined the impact on non-target observables in our analyses. We did not include random-feature baselines or systematic multi-feature ablations. We will revise the text to make these controls and their scope more explicit, add a limitations discussion, and include additional checks on other observables where feasible. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes an empirical workflow: unsupervised SAE training on NQS residual-stream activations, followed by correlation measurements and single-feature intervention experiments that measure observable steering while monitoring variational energy. No equations, uniqueness theorems, or fitted parameters are presented that reduce the central claims (feature-observable causality) to the inputs by construction. The intervention results are reported as direct experimental outcomes rather than predictions derived from the same data used to fit the SAE. The work is therefore self-contained against external benchmarks and receives a normal non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoders recover physically meaningful features from neural activations in variational quantum models
Reference graph
Works this paper leans on
- [1]
-
[2]
Z. Jia, B. Yi, R. Zhai, Y. Wu, G. Guo, and G. Guo, Quantum neural network states: A brief review of meth- ods and applications, Advanced Quantum Technologies 2, 10.1002/qute.201800077 (2019)
-
[3]
M. Medvidovi´ c and J. R. Moreno, Neural-network quan- tum states for many-body physics, The European Phys- ical Journal Plus139, 10.1140/epjp/s13360-024-05311-y (2024)
-
[4]
Carleo and M
G. Carleo and M. Troyer, Solving the quantum many- body problem with artificial neural networks, Science 355, 602–606 (2017)
2017
-
[5]
I. L. Guti´ errez and C. B. Mendl, Real time evolution with neural-network quantum states, Quantum6, 627 (2022)
2022
-
[6]
M. Schmitt and M. Heyl, Quantum many-body dynamics in two dimensions with artificial neural networks, Physi- cal Review Letters125, 10.1103/physrevlett.125.100503 (2020)
- [7]
-
[8]
A. Sinibaldi, D. Hendry, F. Vicentini, and G. Carleo, Time-dependent neural galerkin method for quantum dy- namics, Physical Review Letters136, 10.1103/kqvx-dl54 (2026)
-
[9]
Hibat-Allah, M
M. Hibat-Allah, M. Ganahl, L. E. Hayward, R. G. Melko, and J. Carrasquilla, Recurrent neural network wave func- tions, Phys. Rev. Res.2, 023358 (2020)
2020
-
[10]
L. L. Viteritti, R. Rende, and F. Becca, Transformer vari- ational wave functions for frustrated quantum spin sys- tems, Phys. Rev. Lett.130, 236401 (2023)
2023
-
[11]
Zhang and M
Y.-H. Zhang and M. Di Ventra, Transformer quantum state: A multipurpose model for quantum many-body problems, Phys. Rev. B107, 075147 (2023)
2023
-
[12]
A. Sinibaldi, A. F. Mello, M. Collura, and G. Carleo, Nonstabilizerness of neural quantum states, Physical Re- view Research7, 10.1103/v5tw-yn1f (2025)
-
[13]
D.-L. Deng, X. Li, and S. Das Sarma, Quantum entan- glement in neural network states, Phys. Rev. X7, 021021 (2017)
2017
-
[14]
L. L. Viteritti, R. Rende, C. Roth, A. Sengupta, G. Car- leo, and A. Georges, Beyond variational bias: Resolv- ing intertwined orders in the hubbard model (2026), arXiv:2604.21978 [cond-mat.str-el]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
D¨ oschl, F
F. D¨ oschl, F. A. Palm, H. Lange, F. Grusdt, and A. Bohrdt, Neural network quantum states for the in- teracting hofstadter model with higher local occupations and long-range interactions, Phys. Rev. B111, 045408 (2025)
2025
-
[16]
M. A. Shamim, E. A. F. Reinhardt, T. A. Chowdhury, S. Gleyzer, and P. T. Araujo, Probing quantum spin sys- 11 tems with kolmogorov-arnold neural network quantum states, Phys. Rev. B113, 045157 (2026)
2026
-
[17]
Ibarra-Garc´ ıa-Padilla, H
E. Ibarra-Garc´ ıa-Padilla, H. Lange, R. G. Melko, R. T. Scalettar, J. Carrasquilla, A. Bohrdt, and E. Khatami, Autoregressive neural quantum states of fermi hubbard models, Phys. Rev. Res.7, 013122 (2025)
2025
-
[18]
Sharir, Y
O. Sharir, Y. Levine, N. Wies, G. Carleo, and A. Shashua, Deep autoregressive models for the efficient variational simulation of many-body quantum systems, Phys. Rev. Lett.124, 020503 (2020)
2020
- [19]
- [20]
-
[21]
D. Luo, D. D. Dai, and L. Fu, Pairing-based graph neural network for simulating quantum materials, Phys. Rev. B 113, 165107 (2026)
2026
-
[22]
M. Reh, M. Schmitt, and M. G¨ arttner, Optimizing design choices for neural quantum states, Phys. Rev. B107, 195115 (2023)
2023
-
[23]
D. Luo, Z. Chen, K. Hu, Z. Zhao, V. M. Hur, and B. K. Clark, Gauge-invariant and anyonic-symmetric au- toregressive neural network for quantum lattice models, Phys. Rev. Res.5, 013216 (2023)
2023
-
[24]
K. Choo, G. Carleo, N. Regnault, and T. Neupert, Symmetries and many-body excitations with neural- network quantum states, Physical Review Letters121, 10.1103/physrevlett.121.167204 (2018)
-
[25]
D. Luo, G. Carleo, B. K. Clark, and J. Stokes, Gauge equivariant neural networks for quantum lattice gauge theories, Phys. Rev. Lett.127, 276402 (2021)
2021
-
[26]
F. D¨ oschl and A. Bohrdt, Towards interpretability of neu- ral quantum states (2026), arXiv:2508.14152 [quant-ph]
-
[27]
Valenti, E
A. Valenti, E. Greplova, N. H. Lindner, and S. D. Huber, Correlation-enhanced neural networks as interpretable variational quantum states, Phys. Rev. Res.4, L012010 (2022)
2022
-
[28]
J. A. Sobral, M. Perle, and M. S. Scheurer, Physics- informed transformers for electronic quantum states, Nature Communications16, 10.1038/s41467-025-66844-z (2025)
-
[29]
A. Malyshev, J. M. Arrazola, and A. I. Lvovsky, Autore- gressive neural quantum states with quantum number symmetries (2023), arXiv:2310.04166 [quant-ph]
-
[30]
D. S. Kufel, J. Kemp, D. Vu, S. M. Linsel, C. R. Lau- mann, and N. Y. Yao, Approximately symmetric neural networks for quantum spin liquids, Physical Review Let- ters135, 10.1103/pgnx-11ph (2025)
- [31]
-
[32]
Paul, Bound on entanglement in neural quantum states, Phys
N. Paul, Bound on entanglement in neural quantum states, Phys. Rev. Lett.136, 120403 (2026)
2026
-
[33]
Passetti, D
G. Passetti, D. Hofmann, P. Neitemeier, L. Grunwald, M. A. Sentef, and D. M. Kennes, Can neural quantum states learn volume-law ground states?, Phys. Rev. Lett. 131, 036502 (2023)
2023
-
[34]
can neural quantum states learn volume-law ground states?
Z. Denis, A. Sinibaldi, and G. Carleo, Comment on “can neural quantum states learn volume-law ground states?”, Phys. Rev. Lett.134, 079701 (2025)
2025
-
[35]
X. Gao and L.-M. Duan, Efficient representation of quantum many-body states with deep neural networks, Nature Communications8, 10.1038/s41467-017-00705-2 (2017)
-
[36]
I. Glasser, N. Pancotti, M. August, I. D. Rodriguez, and J. I. Cirac, Neural-network quantum states, string-bond states, and chiral topological states, Physical Review X 8, 10.1103/physrevx.8.011006 (2018)
-
[37]
Scaling Laws for Neural-Network Quantum States
R. Rende, A. Sinibaldi, L. L. Viteritti, R. Wiersema, A. Georges, and G. Carleo, Scaling laws for neural- network quantum states (2026), arXiv:2606.02794 [cond- mat.dis-nn]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
V. Hernandes, T. Spriggs, S. Khaleefah, and E. Greplova, Adiabatic fine-tuning of neural quantum states enables detection of phase transitions in weight space (2025), arXiv:2503.17140 [quant-ph]
- [39]
-
[40]
Golubeva and R
A. Golubeva and R. G. Melko, Pruning a restricted boltz- mann machine for quantum state reconstruction, Phys. Rev. B105, 125124 (2022)
2022
-
[41]
M. S. Moss, A. Orfi, C. Roth, A. M. Sengupta, A. Georges, D. Sels, A. Dawid, and A. Valenti, Double de- scent: When do neural quantum states generalize?, Phys. Rev. E113, 045303 (2026)
2026
-
[42]
S. Dash, L. Gravina, F. Vicentini, M. Ferrero, and A. Georges, Efficiency of neural quantum states in light of the quantum geometric tensor, Communications Physics 8, 10.1038/s42005-025-02005-4 (2025)
- [43]
-
[44]
Mechanistic Interpretability for AI Safety -- A Review
L. Bereska and E. Gavves, Mechanistic interpretability for ai safety – a review (2024), arXiv:2404.14082 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Open Problems in Mechanistic Interpretability
L. Sharkey, B. Chughtai, J. Batson, J. Lindsey, J. Wu, L. Bushnaq, N. Goldowsky-Dill, S. Heimersheim, A. Or- tega, J. Bloom, S. Biderman, A. Garriga-Alonso, A. Conmy, N. Nanda, J. Rumbelow, M. Wattenberg, N. Schoots, J. Miller, E. J. Michaud, S. Casper, M. Tegmark, W. Saunders, D. Bau, E. Todd, A. Geiger, M. Geva, J. Hoogland, D. Murfet, and T. McGrath, O...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Bricken, A
T. Bricken, A. Templeton, J. Batson, B. Chen, A. Jermyn, T. Conerly, N. Turner, C. Anil, C. Deni- son, A. Askell,et al., Towards monosemanticity: Decom- posing language models with dictionary learning, Trans- former Circuits Thread2, 6 (2023)
2023
-
[47]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharkey, Sparse autoencoders find highly interpretable features in language models (2023), arXiv:2309.08600 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
L. Gao, T. D. la Tour, H. Tillman, G. Goh, R. Troll, A. Radford, I. Sutskever, J. Leike, and J. Wu, Scaling and evaluating sparse autoencoders (2024), arXiv:2406.04093 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
A. Templeton, T. Conerly, J. Marcus, J. Lindsey, T. Bricken, B. Chen, A. Pearce, C. Citro, E. Ameisen, A. Jones, H. Cunningham, N. L. Turner, C. Mc- Dougall, M. MacDiarmid, A. Tamkin, E. Durmus, T. Hume, F. Mosconi, C. D. Freeman, T. R. Sumers, 12 E. Rees, J. Batson, A. Jermyn, S. Carter, C. Olah, and T. Henighan, Scaling monosemanticity: Extract- ing int...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
B. A. Olshausen and D. J. Field, Sparse coding with an overcomplete basis set: A strategy employed by v1?, Vi- sion research37, 3311 (1997)
1997
-
[51]
E. Simon and J. Zou, Interplm: Discovering interpretable features in protein language models via sparse autoen- coders (2024), arXiv:2412.12101 [q-bio.BM]
-
[52]
Adams, L
E. Adams, L. Bai, M. Lee, Y. Yu, and M. AlQuraishi, From mechanistic interpretability to mechanistic biol- ogy: Training, evaluating, and interpreting sparse au- toencoders on protein language models, bioRxiv (2025)
2025
-
[53]
O. Gujral, M. Bafna, E. Alm, and B. Berger, Sparse autoencoders uncover biologically in- terpretable features in protein language model representations, Proceedings of the National Academy of Sciences122, e2506316122 (2025), https://www.pnas.org/doi/pdf/10.1073/pnas.2506316122
- [54]
-
[55]
T. MacMillan and N. T. Ouellette, Towards mechanistic understanding in a data-driven weather model: internal activations reveal interpretable physical features (2025), arXiv:2512.24440 [physics.ao-ph]
-
[56]
K. Rosenfeld and M. Sonnewald, Sparse probes and murky physics: a case study of interpretability challenges in a foundation model for continuum dynamics (2026), arXiv:2606.11657 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
N. Elhage, T. Hume, C. Olsson, N. Schiefer, T. Henighan, S. Kravec, Z. Hatfield-Dodds, R. Lasenby, D. Drain, C. Chen, R. Grosse, S. McCandlish, J. Kaplan, D. Amodei, M. Wattenberg, and C. Olah, Toy models of superposition (2022), arXiv:2209.10652 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [58]
-
[59]
Pfeuty, The one-dimensional Ising model with a trans- verse field, Annals of Physics57, 79 (1970)
P. Pfeuty, The one-dimensional Ising model with a trans- verse field, Annals of Physics57, 79 (1970)
1970
- [60]
-
[61]
K. Meng, D. Bau, A. Andonian, and Y. Belinkov, Lo- cating and editing factual associations in gpt (2023), arXiv:2202.05262 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowski, S. Goel, N. Li, M. J. Byun, Z. Wang, A. Mallen, S. Basart, S. Koyejo, D. Song, M. Fredrikson, J. Z. Kolter, and D. Hendrycks, Representation engineering: A top-down approach to ai transparency (2025), arXiv:2310.01405 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid, Steer- ing language models with activation engineering (2024), arXiv:2308.10248 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Rende, S
R. Rende, S. Goldt, F. Becca, and L. L. Viteritti, Fine- tuning neural network quantum states, Phys. Rev. Res. 6, 043280 (2024)
2024
- [65]
-
[66]
Z. Qi, C. Earls, and Y. Peng, Universal neural propa- gator: Learning time evolution in many-body quantum systems (2026), arXiv:2605.05299 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[67]
A. V. Chubukov, S. Sachdev, and J. Ye, Theory of two- dimensional quantum heisenberg antiferromagnets with a nearly critical ground state, Physical Review B49, 11919–11961 (1994)
1994
-
[68]
Manousakis, The spin-½heisenberg antiferromagnet on a square lattice and its application to the cuprous oxides, Rev
E. Manousakis, The spin-½heisenberg antiferromagnet on a square lattice and its application to the cuprous oxides, Rev. Mod. Phys.63, 1 (1991)
1991
-
[69]
A. W. Sandvik, Finite-size scaling of the ground-state pa- rameters of the two-dimensional heisenberg model, Phys- ical Review B56, 11678–11690 (1997)
1997
-
[70]
R. Rende, L. L. Viteritti, F. Becca, A. Scardicchio, A. Laio, and G. Carleo, Foundation neural-networks quantum states as a unified ansatz for multiple hamilto- nians, Nature Communications16, 10.1038/s41467-025- 62098-x (2025)
-
[71]
Attention-Based Foundation Model for Quantum States
T. Zaklama, D. Guerci, and L. Fu, Attention- based foundation model for quantum states (2026), arXiv:2512.11962 [cond-mat.str-el]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[72]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, At- tention is all you need (2023), arXiv:1706.03762 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
A. Makhzani and B. Frey, k-sparse autoencoders (2014), arXiv:1312.5663 [cs.LG]. Appendix A: Details of Transformer Architecture The transformer architecture [72] has recently become a powerful ans¨ atz for quantum wavefunctions [10, 11, 70, 71]. Its self-attention mechanism allows the wavefunction representation to capture long-range correlations in many ...
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.