Streaming Gaussian Encoding for 4D Panoptic Occupancy Tracking
Pith reviewed 2026-07-01 06:26 UTC · model grok-4.3
The pith
A streaming Gaussian encoder maintains a fixed set of latent queries to give persistent volumetric coherence in camera-based 4D panoptic occupancy tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our method models the scene as a fixed-size set of latent Gaussian queries that are propagated via ego-motion compensation and refreshed under a confidence-guided budget constraint. We shape Gaussian opacities through depth-based supervision to serve as proxy for visibility, enabling confidence to accumulate as a temporally aggregated measure of persistent scene support. Together with a warmup-based multi-frame training strategy, this yields representation-level temporal coherence beyond decoder-only tracking and establishes a new state-of-the-art for camera-based 4D-POT on Occ3D-extended nuScenes and Waymo while adding negligible computational overhead and remaining compatible with mask-bas
What carries the argument
Streaming Gaussian encoder that maintains and updates a fixed-size set of latent Gaussian queries via ego-motion propagation and confidence-guided refresh, with opacity shaped by depth supervision as a visibility proxy.
If this is right
- New state-of-the-art on camera-based 4D-POT benchmarks for both nuScenes and Waymo.
- Improved tracking consistency for dynamic objects and static elements under occlusion.
- Negligible added computational cost relative to existing mask-based pipelines.
- Full compatibility with current mask-based 4D-POT methods without architecture changes.
Where Pith is reading between the lines
- The persistent query set could support longer temporal windows than the evaluated sequences if the refresh budget is adjusted dynamically.
- The same streaming mechanism might reduce redundant computation in other multi-frame tasks such as video panoptic segmentation.
- Because the representation is updated rather than recomputed, the approach may integrate more naturally with future sensor fusion that adds new observations incrementally.
Load-bearing premise
Depth-based supervision can shape Gaussian opacities to serve as a reliable proxy for visibility so that confidence accumulates as a temporally aggregated measure of persistent scene support.
What would settle it
An ablation on the nuScenes validation set that removes depth supervision on opacities and measures whether the reported gains in tracking consistency over per-frame baselines disappear.
Figures

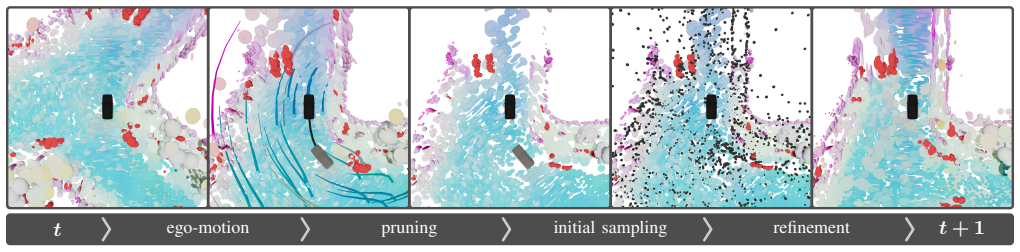
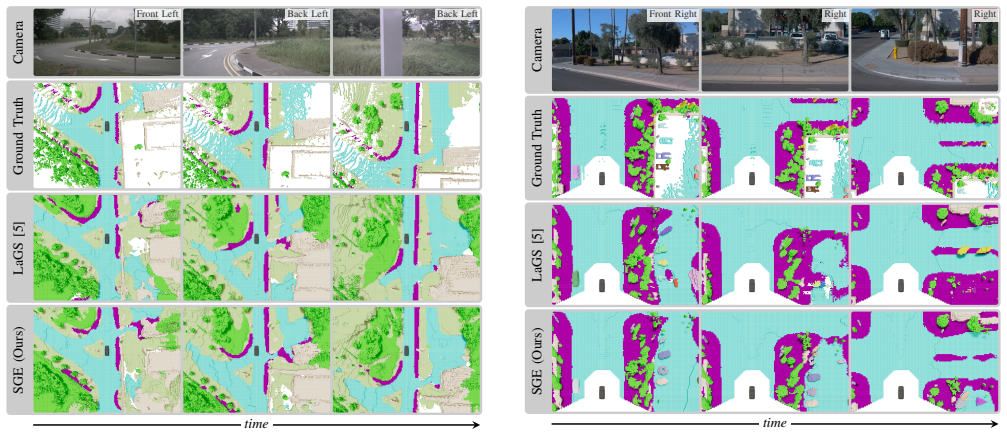
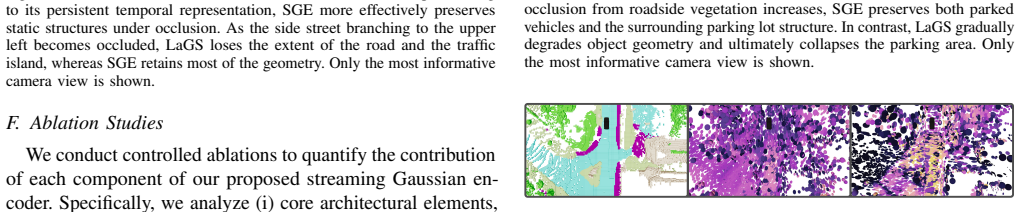
read the original abstract
Camera-based 4D panoptic occupancy tracking (4D-POT) is a promising paradigm for holistic scene understanding from multi-view imagery, enabling joint reasoning about geometry, semantics, and object identities across time. Recent mask-based pipelines achieve strong performance by propagating instance queries across frames. However, their underlying volumetric representations are typically recomputed at each timestep, limiting geometric temporal consistency, particularly under occlusion and for static scene elements. To address this limitation, we propose a streaming Gaussian encoder that maintains a persistent volumetric scene representation for 4D-POT. Our method models the scene as a fixed-size set of latent Gaussian queries that are propagated via ego-motion compensation and refreshed under a confidence-guided budget constraint. Crucially, we shape Gaussian opacities through depth-based supervision to serve as proxy for visibility, enabling confidence to accumulate as a temporally aggregated measure of persistent scene support. Together with a warmup-based multi-frame training strategy, this yields representation-level temporal coherence beyond decoder-only tracking. Extensive experiments on Occ3D-extended nuScenes and Waymo establish a new state-of-the-art for camera-based 4D-POT, improving tracking consistency with negligible computational overhead while remaining fully compatible with existing mask-based pipelines. We provide code and models at https://sge.cs.uni-freiburg.de.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a streaming Gaussian encoder for camera-based 4D panoptic occupancy tracking (4D-POT). The scene is modeled as a fixed-size set of latent Gaussian queries that are propagated via ego-motion compensation and refreshed under a confidence-guided budget constraint. Gaussian opacities are shaped via depth-based supervision to act as a visibility proxy, allowing confidence to accumulate as a temporally aggregated measure of persistent scene support. A warmup-based multi-frame training strategy is used to obtain representation-level temporal coherence beyond decoder-only tracking. The method is reported to achieve new state-of-the-art results on Occ3D-extended nuScenes and Waymo while incurring negligible overhead and remaining compatible with existing mask-based pipelines; code and models are released.
Significance. If the experimental claims are substantiated, the work would be significant for camera-based 4D scene understanding by shifting from per-frame recomputation to a persistent representation that improves tracking consistency for both dynamic and static elements. The representation-level coherence mechanism, the opacity-as-visibility proxy, and the low-overhead design are potentially impactful. The explicit compatibility with mask-based pipelines and the public release of code and models strengthen the contribution.
minor comments (1)
- [Abstract] Abstract: the claim of 'new state-of-the-art' and 'improving tracking consistency' would be strengthened by including one or two key quantitative metrics (e.g., improvement in tracking consistency or mIoU) directly in the abstract.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation of minor revision. The assessment correctly identifies the core contributions of the streaming Gaussian encoder, including ego-motion propagation, confidence-guided updates, and the opacity-as-visibility mechanism.
Circularity Check
No significant circularity detected
full rationale
The paper's central mechanism—modeling scenes via fixed-size latent Gaussian queries propagated by ego-motion compensation, refreshed under confidence-guided budget, with depth-supervised opacities as visibility proxy—is presented as a novel streaming encoder design. No equations, fitted parameters renamed as predictions, or self-citation chains reducing the core claims to inputs by construction are identifiable in the provided material. The derivation remains self-contained, with the claimed temporal coherence arising from the described architecture and training strategy rather than tautological re-use of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Up-fuse: Uncertainty-guided lidar-camera fusion for 3d panoptic segmentation,
R. Mohan, F. Drews, Y . Miron, D. Cattaneo, and A. Valada, “Up-fuse: Uncertainty-guided lidar-camera fusion for 3d panoptic segmentation,” arXiv preprint arXiv:2602.19349, 2026
-
[2]
A point-based approach to efficient lidar multi-task perception,
C. Lang, A. Braun, L. Schillingmann, and A. Valada, “A point-based approach to efficient lidar multi-task perception,” inIROS, 2024
2024
-
[3]
Multi-scale neighborhood occupancy masked autoencoder for self-supervised learning in lidar point clouds,
M. Abdelsamad, M. Ulrich, C. Gl ¨aser, and A. Valada, “Multi-scale neighborhood occupancy masked autoencoder for self-supervised learning in lidar point clouds,” inCVPR, 2025, pp. 22 234–22 243
2025
-
[4]
Trackocc: Camera-based 4d panoptic occupancy tracking,
Z. Chen, K. Li, X. Yang, T. Jiang, Y . Li, and H. Zhao, “Trackocc: Camera-based 4d panoptic occupancy tracking,” inICRA, 2025
2025
-
[5]
Latent Gaussian Splatting for 4D Panoptic Occupancy Tracking
M. Luz, R. Mohan, T. N ¨urnberg, Y . Miron, D. Cattaneo, and A. Valada, “Latent gaussian splatting for 4d panoptic occupancy tracking,” arXiv preprint, arXiv:2602.23172, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking,
W. K. Fong, R. Mohan, J. V . Hurtado, L. Zhou, H. Caesar, O. Beijbom, and A. Valada, “Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3795–3802, 2022
2022
-
[7]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine,et al., “Scalability in perception for autonomous driving: Waymo open dataset,” inCVPR, 2020
2020
-
[8]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,
X. Tian, T. Jiang, L. Yun, Y . Mao, H. Yang, Y . Wang, Y . Wang, and H. Zhao, “Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,” inNeurIPS, 2023
2023
-
[9]
Tri-perspective view for vision-based 3D semantic occupancy prediction,
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu, “Tri-perspective view for vision-based 3D semantic occupancy prediction,” inCVPR, 2023, pp. 9223–9232
2023
-
[10]
SurroundOcc: Multi-camera 3D occupancy prediction for autonomous driving,
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu, “SurroundOcc: Multi-camera 3D occupancy prediction for autonomous driving,” in ICCV, 2023, pp. 21 729–21 740
2023
-
[11]
OccFormer: Dual-path transformer for vision-based 3D semantic occupancy prediction,
Y . Zhang, Z. Zhu, and D. Du, “OccFormer: Dual-path transformer for vision-based 3D semantic occupancy prediction,” inICCV, 2023
2023
-
[12]
SparseOcc: Rethinking sparse latent representation for vision-based semantic occupancy prediction,
P. Tang, Z. Wang, G. Wang, J. Zheng, X. Ren, B. Feng, and C. Ma, “SparseOcc: Rethinking sparse latent representation for vision-based semantic occupancy prediction,” inCVPR, 2024, pp. 15 035–15 044
2024
-
[13]
Per-pixel classification is not all you need for semantic segmentation,
B. Cheng, A. Schwing, and A. Kirillov, “Per-pixel classification is not all you need for semantic segmentation,” inNeurIPS, 2021
2021
-
[14]
Masked-attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” inCVPR, 2022, pp. 1290–1299
2022
-
[15]
COTR: Compact occupancy transformer for vision-based 3D occupancy prediction,
Q. Ma, X. Tan, Y . Qu, L. Ma, Z. Zhang, and Y . Xie, “COTR: Compact occupancy transformer for vision-based 3D occupancy prediction,” in CVPR, 2024, pp. 19 936–19 945
2024
-
[16]
PaSCo: Urban 3D panoptic scene completion with uncertainty awareness,
A.-Q. Cao, A. Dai, and R. de Charette, “PaSCo: Urban 3D panoptic scene completion with uncertainty awareness,” inCVPR, 2024
2024
-
[17]
J. Huang and G. Huang, “BEVDet4D: Exploit temporal cues in multi- camera 3D object detection,” arXiv preprint, arXiv:2203.17054, 2022
-
[18]
BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y . Qiao, and J. Dai, “BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” inECCV, 2022
2022
-
[19]
Time will tell: New outlooks and a baseline for temporal multi-view 3d object detection,
J. Park, C. Xu, S. Yang, K. Keutzer, K. M. Kitani, M. Tomizuka, and W. Zhan, “Time will tell: New outlooks and a baseline for temporal multi-view 3d object detection,” inICLR, 2022
2022
-
[20]
Exploring object- centric temporal modeling for efficient multi-view 3d object detection,
S. Wang, Y . Liu, T. Wang, Y . Li, and X. Zhang, “Exploring object- centric temporal modeling for efficient multi-view 3d object detection,” inICCV, 2023, pp. 3621–3631
2023
-
[21]
Sparse4D: Multi-view 3d object detection with sparse spatial-temporal fusion,
X. Lin, T. Lin, Z. Pei, L. Huang, and Z. Su, “Sparse4D: Multi-view 3d object detection with sparse spatial-temporal fusion,” arXiv preprint, arXiv:2211.10581, 2022
-
[22]
UniOcc: A unified benchmark for occupancy forecasting and prediction in autonomous driving,
Y . Wang, X. Huang, X. Sun, M. Yan, S. Xing, Z. Tu, and J. Li, “UniOcc: A unified benchmark for occupancy forecasting and prediction in autonomous driving,” inICCV, 2025, pp. 25 560–25 570
2025
-
[23]
S. Boeder, F. Gigengack, and B. Risse, “OccFlowNet: Towards self- supervised occupancy estimation via differentiable rendering and occupancy flow,”arXiv preprint, arXiv:2402.12792, 2024
-
[24]
Forecas- tOcc: Vision-based semantic occupancy forecasting,
R. Mohan, J. V . Hurtado, R. Mohan, and A. Valada, “Forecas- tOcc: Vision-based semantic occupancy forecasting,” arXiv preprint, arXiv:2602.08006, 2026
-
[25]
Nerf and gaussian splatting slam in the wild,
F. Schmidt, M. Enzweiler, and A. Valada, “Nerf and gaussian splatting slam in the wild,”arXiv preprint arXiv:2412.03263, 2024
-
[26]
Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis,
J. Luiten, G. Kopanas, B. Leibe, and D. Ramanan, “Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis,” in3DV, 2024, pp. 800–809
2024
-
[27]
GaussianFormer: Scene as gaussians for vision-based 3D semantic occupancy prediction,
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu, “GaussianFormer: Scene as gaussians for vision-based 3D semantic occupancy prediction,” inECCV, 2025, pp. 376–393
2025
-
[28]
GaussianFormer-2: Probabilistic gaussian superposition for efficient 3D occupancy prediction,
Y . Huang, A. Thammatadatrakoon, W. Zheng, Y . Zhang, D. Du, and J. Lu, “GaussianFormer-2: Probabilistic gaussian superposition for efficient 3D occupancy prediction,” inCVPR, 2025, pp. 27 477–27 486
2025
-
[29]
GaussianWorld: Gaussian world model for streaming 3d occupancy prediction,
S. Zuo, W. Zheng, Y . Huang, J. Zhou, and J. Lu, “GaussianWorld: Gaussian world model for streaming 3d occupancy prediction,” in CVPR, 2025, pp. 6772–6781
2025
-
[30]
Chorus: Multi-Teacher Pretraining for Holistic 3D Gaussian Scene Encoding
Y . Li, Q. Ma, R. Yang, M. Ma, B. Ren, N. Popovic,et al., “Chorus: Multi-teacher pretraining for holistic 3d gaussian scene encoding,” arXiv preprint, arXiv:2512.17817, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
FiLM: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville, “FiLM: Visual reasoning with a general conditioning layer,” inAAAI, vol. 32, no. 1, 2018
2018
-
[32]
Step: Segmenting and tracking every pixel,
M. Weber, J. Xie, M. D. Collins, Y . Zhu, P. V oigtlaender, H. Adam, B. Green, A. Geiger, B. Leibe, D. Cremers,et al., “Step: Segmenting and tracking every pixel,” inNeurIPS, 2021
2021
-
[33]
An energy and gpu- computation efficient backbone network for real-time object detection,
Y . Lee, J.-w. Hwang, S. Lee, Y . Bae, and J. Park, “An energy and gpu- computation efficient backbone network for real-time object detection,” inCVPRW, 2019, pp. 752–760
2019
-
[34]
MinVIS: A minimal video instance segmentation framework without video-based training,
D.-A. Huang, Z. Yu, and A. Anandkumar, “MinVIS: A minimal video instance segmentation framework without video-based training,” in NeurIPS, vol. 35, 2022, pp. 31 265–31 277
2022
-
[35]
CTVIS: Consistent training for online video instance segmentation,
K. Ying, Q. Zhong, W. Mao, Z. Wang, H. Chen, L. Y . Wu, Y . Liu, C. Fan, Y . Zhuge, and C. Shen, “CTVIS: Consistent training for online video instance segmentation,” inCVPR, 2023, pp. 899–908
2023
-
[36]
4d panoptic lidar segmentation,
M. Ayg¨un, A. Osep, M. Weber, M. Maximov, C. Stachniss, J. Behley, and L. Leal-Taix ´e, “4d panoptic lidar segmentation,” inCVPR, 2021, pp. 5527–5537
2021
-
[37]
3D multi-object tracking: A baseline and new evaluation metrics,
X. Weng, J. Wang, D. Held, and K. Kitani, “3D multi-object tracking: A baseline and new evaluation metrics,” inIROS, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.