Mean-based algorithms: A lower bound and regret
Pith reviewed 2026-06-28 07:15 UTC · model grok-4.3
The pith
Mean-based algorithms cannot learn faster than a lower bound on their defining sequence γ_t allows under bandit feedback with unknown horizon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the bandit-feedback model with unknown finite horizon, any mean-based algorithm defined by a sequence γ_t must obey a lower bound on the rate at which γ_t can decrease; this bound is the first formal result that limits the speed at which such algorithms can learn, and it is accompanied by explicit constructions of mean-based algorithms that achieve competitive performance and by a demonstration that the mean-based and no-regret classes have a non-empty intersection.
What carries the argument
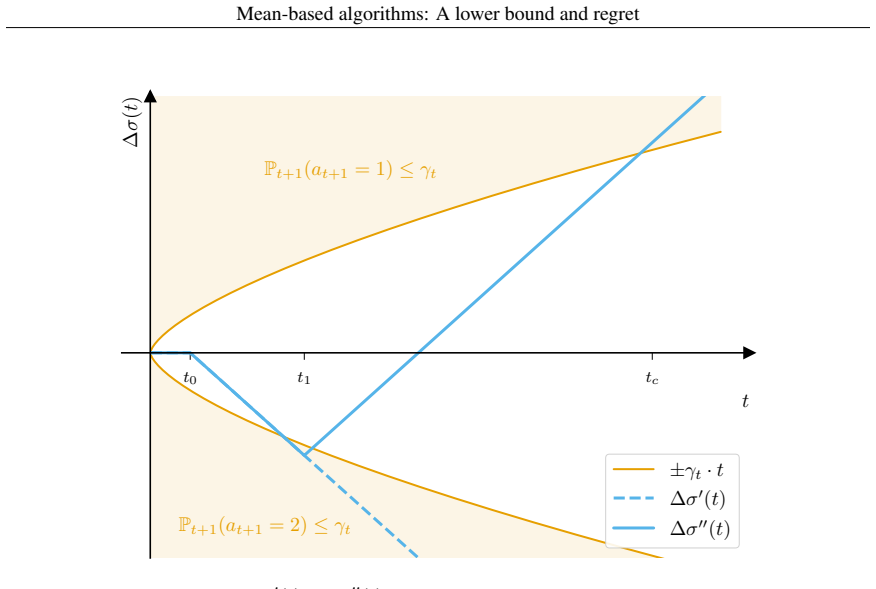
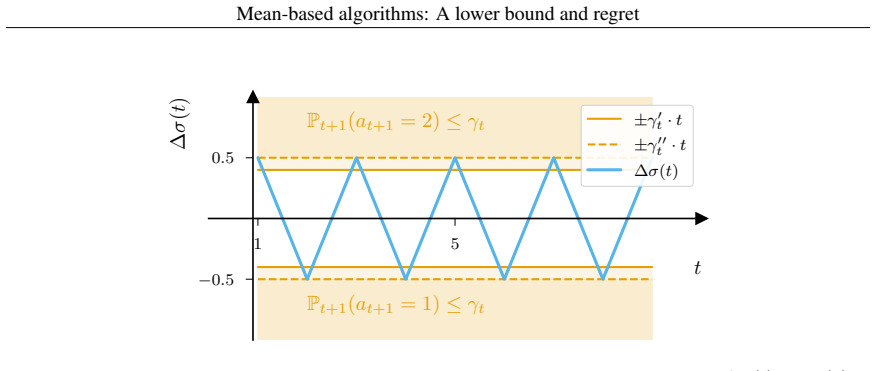
The non-increasing sequence γ_t that forces a mean-based algorithm to place at least γ_t probability mass on every action whose empirical mean is below the maximum observed mean.
If this is right
- Mean-based algorithms have a provable speed limit on convergence to serially undominated actions in unknown-horizon bandit problems.
- Algorithms can be constructed that are simultaneously mean-based and no-regret for suitable choices of γ_t.
- The two new constructions extend ε-greedy and mean-based Exp3 to the unknown-horizon setting while preserving the mean-based property.
- The intersection between mean-based and no-regret classes is non-trivial rather than empty.
Where Pith is reading between the lines
- The lower bound may constrain how rapidly mean-based dynamics can approximate Nash equilibria in repeated games when players receive only payoff feedback.
- Designers of hybrid algorithms could use the bound to calibrate γ_t so that mean-based behavior coexists with sublinear regret.
- Empirical studies could test whether real-world implementations of mean-based rules already operate near the derived limit or could safely accelerate γ_t decay.
Load-bearing premise
The modeling choice that mean-based algorithms are exactly those whose behavior is governed by a single sequence γ_t under the standard bandit-feedback and unknown-horizon assumptions.
What would settle it
An explicit mean-based algorithm whose γ_t sequence decreases faster than the derived lower bound while still satisfying the mean-based definition on all bandit-feedback instances with unknown horizon.
Figures
read the original abstract
Mean-based algorithms are a class of online learning algorithms that assign low probability to actions with low average rewards. Recent work indicates these algorithms converge favorably to serially undominated actions, which approximate Nash equilibria in economic games. However, empirical studies also show slower convergence compared to established algorithms in bandit-feedback scenarios. We study mean-based algorithms when the time horizon is unknown and only bandit feedback is available. In this setting, we provide the first lower bound on the algorithm-defining sequence $\gamma_t$ that formally establishes a limit on how fast these algorithms can learn. Additionally, we propose two mean-based algorithms: one generalizes $\epsilon$-greedy, and the other extends the mean-based Exp3 to unknown horizons. Our experiments show that mean-based algorithms, although slightly slower, can perform competitively with other bandit-feedback algorithms. We further analyze the relationship to no-regret algorithms. Depending on the choice of $\gamma_t$, the intersection with no-regret algorithms is non-trivial, and we show that algorithms exist that are both mean-based and no-regret. This adds context to the "exploitability" of this class of algorithms that previous contributions suggest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies mean-based algorithms (defined via the sequence γ_t) in the bandit-feedback setting with unknown finite horizon. It claims to provide the first formal lower bound on γ_t that limits the speed at which these algorithms can learn, proposes two new mean-based algorithms (a generalization of ε-greedy and an extension of mean-based Exp3 to unknown horizons), reports that experiments show competitive performance relative to other bandit algorithms, and analyzes the intersection with no-regret algorithms, showing that the intersection is non-empty and that algorithms can be both mean-based and no-regret.
Significance. If the lower bound holds, it supplies a concrete, formal constraint on the convergence rate of mean-based algorithms under standard bandit assumptions, which is useful for understanding their behavior in game-theoretic settings where they converge to serially undominated actions. The construction of two new algorithms that respect the mean-based property while handling unknown horizons, together with the demonstration that mean-based and no-regret properties can coexist, adds technical value. The paper includes experimental comparisons, which is a positive feature even if details require clarification.
major comments (2)
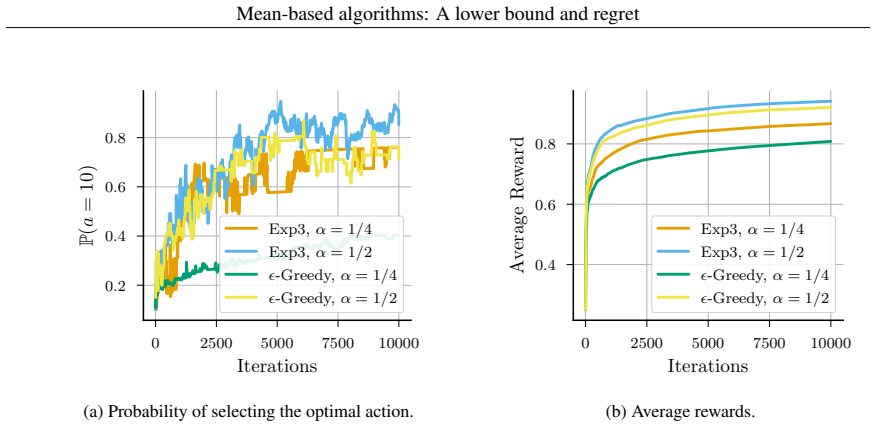
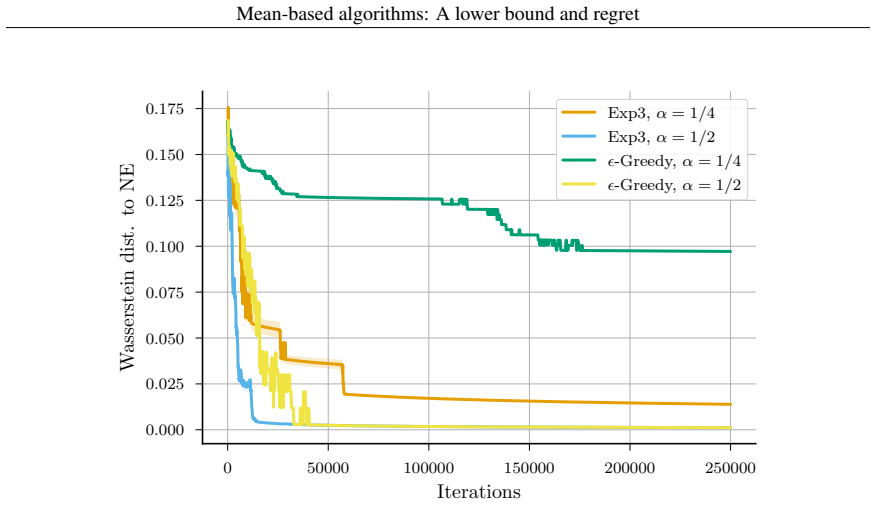
- [§4] §4 (Experiments): The statement that mean-based algorithms 'perform competitively' is central to the practical contribution, yet the text provides no description of the baselines used, the number of independent runs, error bars, or statistical tests. This makes it impossible to evaluate whether the observed slight slowdown is statistically meaningful or whether the competitiveness claim is supported.
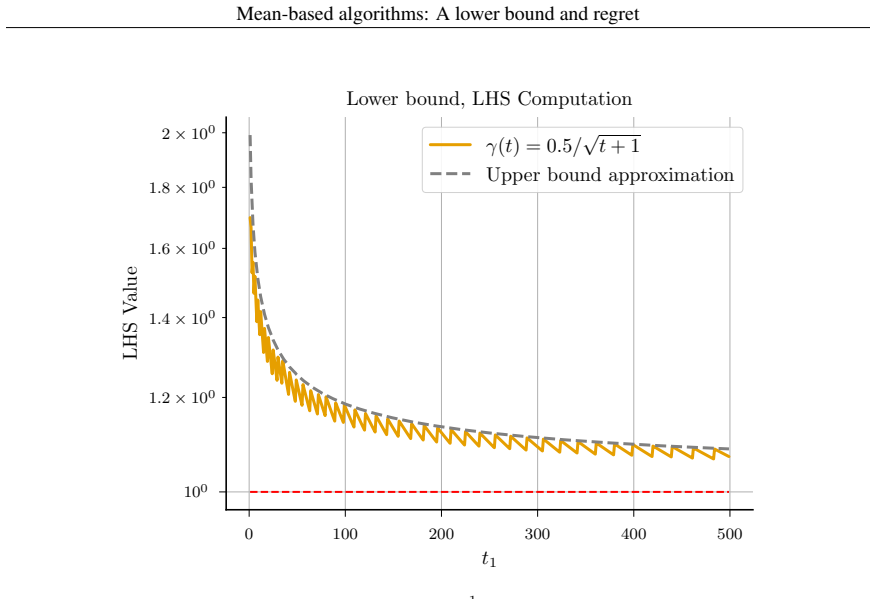
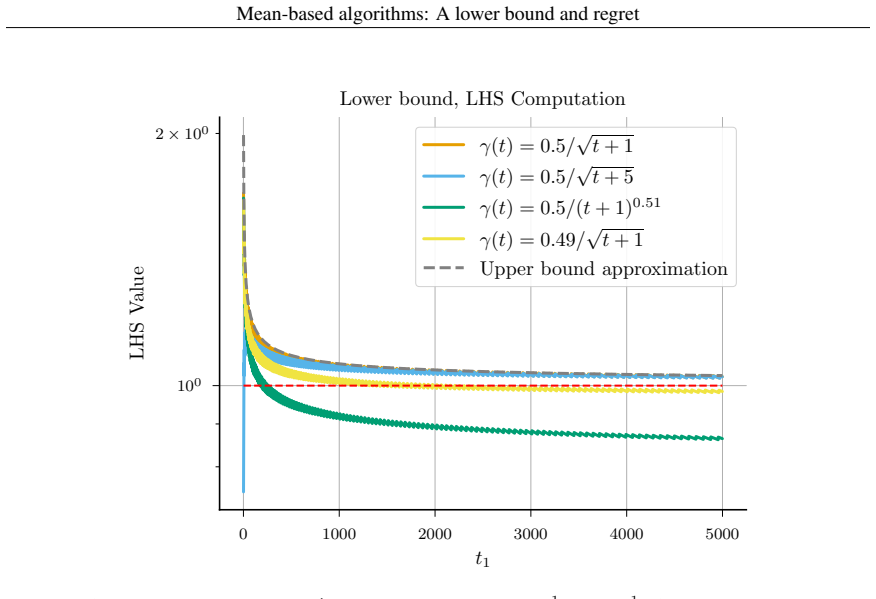
- [Theorem 1] Theorem 1 (lower bound on γ_t): The proof sketch relies on the unknown-horizon bandit model; it is unclear whether the same bound applies when the horizon is known or whether the unknown-horizon assumption is necessary for the result to be non-vacuous. Clarifying this would strengthen the claim that the bound 'formally establishes a limit on how fast these algorithms can learn.'
minor comments (2)
- [Introduction] The definition of mean-based algorithms via γ_t is introduced in the abstract but should be restated with the precise mathematical condition in the first section for readers unfamiliar with the prior literature.
- [§4] Figure captions and axis labels in the experimental plots should explicitly state the performance metric (e.g., cumulative regret) and the horizon values tested.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The statement that mean-based algorithms 'perform competitively' is central to the practical contribution, yet the text provides no description of the baselines used, the number of independent runs, error bars, or statistical tests. This makes it impossible to evaluate whether the observed slight slowdown is statistically meaningful or whether the competitiveness claim is supported.
Authors: We agree that additional details are required to support the competitiveness claim. In the revised manuscript we will expand §4 to specify the baselines (standard Exp3, UCB, and Thompson Sampling), the number of independent runs (50 per environment), error bars (one standard deviation), and any statistical tests performed. This will allow readers to assess whether the observed differences are meaningful. revision: yes
-
Referee: [Theorem 1] Theorem 1 (lower bound on γ_t): The proof sketch relies on the unknown-horizon bandit model; it is unclear whether the same bound applies when the horizon is known or whether the unknown-horizon assumption is necessary for the result to be non-vacuous. Clarifying this would strengthen the claim that the bound 'formally establishes a limit on how fast these algorithms can learn.'
Authors: The lower bound of Theorem 1 is derived specifically for the unknown-horizon setting; the proof relies on the algorithm having to choose γ_t without knowledge of T. When the horizon is known in advance, a different γ_t sequence can be selected and the same lower bound need not hold. We will add a clarifying remark stating that the result is tied to the unknown-horizon model and explaining why that assumption is necessary for the bound to be non-vacuous. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper derives a lower bound on the algorithm-defining sequence γ_t from the standard definition of mean-based algorithms together with the bandit-feedback model and unknown finite horizon. This is presented as an independent analysis establishing a limit on learning speed, with additional constructions of two new algorithms and a non-trivial intersection with no-regret algorithms shown via choice of γ_t. No load-bearing step reduces by the paper's own equations or self-citation to its inputs; the central claim does not rely on fitted parameters renamed as predictions, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation. The derivation is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mean-based algorithms assign low probability to actions with low average rewards via a sequence γ_t
Reference graph
Works this paper leans on
-
[1]
Lattimore, Tor and Szepesvári, Csaba , year =. Bandit. doi:10.1017/9781108571401 , publisher =
-
[2]
Auer, P. and Cesa-Bianchi, N. and Freund, Y. and Schapire, R.E. , year =. Gambling in a rigged casino:. doi:10.1109/SFCS.1995.492488 , booktitle =
-
[3]
Finite-time. Machine Learning , author =. 2002 , pages =. doi:10.1023/A:1013689704352 , number =
-
[4]
Auer, Peter and Cesa-Bianchi, Nicolò and Freund, Yoav and Schapire, Robert E. , year =. The. SIAM Journal on Computing , publisher =. doi:10.1137/S0097539701398375 , number =
-
[5]
Thompson, William R. , year =. On the. Biometrika , publisher =. doi:10.2307/2332286 , number =
-
[6]
Deng, Xiaotie and Hu, Xinyan and Lin, Tao and Zheng, Weiqiang , year =. Nash. doi:10.1145/3485447.3512059 , booktitle =
-
[7]
Kolumbus, Yoav and Nisan, Noam , year =. Auctions between. doi:10.1145/3485447.3512055 , booktitle =
-
[8]
Braverman, Mark and Mao, Jieming and Schneider, Jon and Weinberg, Matt , year =. Selling to a. doi:10.1145/3219166.3219233 , booktitle =
-
[9]
Foundations and Trends® in Machine Learning , author =
Online. Foundations and Trends® in Machine Learning , author =. 2011 , pages =. doi:10.1561/2200000018 , number =
-
[10]
Milgrom, Paul and Roberts, John , year =. Rationalizability,. Econometrica , publisher =. doi:10.2307/2938316 , number =
-
[11]
Pearce, David G. , year =. Rationalizable. Econometrica , publisher =. doi:10.2307/1911197 , number =
-
[12]
Bernheim, B. Douglas , year =. Rationalizable. Econometrica , publisher =. doi:10.2307/1911196 , number =
-
[13]
Brandenburger, Adam and Dekel, Eddie , year =. Rationalizability and. Econometrica , publisher =. doi:10.2307/1913562 , number =
-
[14]
Journal of Mathematical Economics , author =
Subjectivity and correlation in randomized strategies , volume =. Journal of Mathematical Economics , author =. 1974 , pages =. doi:10.1016/0304-4068(74)90037-8 , number =
-
[15]
Solution
Levin, Jonathan , year =. Solution
-
[16]
Aumann, Robert J. , year =. Correlated. Econometrica , publisher =. doi:10.2307/1911154 , number =
-
[17]
Advances in Neural Information Processing Systems , author =
Fast. Advances in Neural Information Processing Systems , author =. 2024 , pages =
2024
-
[18]
Arunachaleswaran, Eshwar Ram and Collina, Natalie and Kannan, Sampath and Roth, Aaron and Ziani, Juba , year =. Algorithmic. doi:10.48550/arXiv.2409.03956 , publisher =
-
[19]
A reasoning-focused legal retrieval benchmark,
Hartline, Jason D. and Wang, Chang and Zhang, Chenhao , year =. Regulation of. doi:10.1145/3709025.3712217 , booktitle =
-
[20]
Strategizing against
Deng, Yuan and Schneider, Jon and Sivan, Balasubramanian , editor =. Strategizing against. Advances in. 2019 , url_OPT =
2019
-
[21]
Gerchinovitz, Sébastien and Lattimore, Tor , year =. Refined. doi:10.48550/arXiv.1605.07416 , publisher =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1605.07416
-
[22]
Daskalakis, Constantinos and Farina, Gabriele and Fishelson, Maxwell and Pipis, Charilaos and Schneider, Jon , year =. Efficient. doi:10.1145/3717823.3718307 , booktitle =
-
[23]
Komiyama, Junpei and Honda, Junya and Kashima, Hisashi and Nakagawa, Hiroshi , year =. Regret. Proceedings of
-
[24]
Lin, Tao and Chen, Yiling , year =. Generalized. doi:10.48550/arXiv.2402.09721 , publisher =
-
[25]
Minimax policies for adversarial and stochastic bandits , booktitle =
Audibert, Jean-Yves and Bubeck, Sébastien , year =. Minimax policies for adversarial and stochastic bandits , booktitle =
-
[26]
Bichler, Martin and Durmann, Julius and Oberlechner, Matthias , year =. Online. doi:10.48550/arXiv.2412.15707 , publisher =
-
[27]
Kolumbus, Yoav and Schneider, Jon and Talgam-Cohen, Inbal and Vlatakis-Gkaragkounis, Emmanouil-Vasileios and Wang, Joshua R. and Weinberg, S. M. , year =. Contracting with a. doi:10.52202/079017-2460 , journal =
-
[28]
Arora, Sanjeev and Hazan, Elad and Kale, Satyen , year =. The. doi:10.4086/toc.2012.v008a006 , journal =
-
[29]
Learning Theory 2003 , author =
Efficient algorithms for online decision problems , volume =. Learning Theory 2003 , author =. 2005 , pages =. doi:10.1016/j.jcss.2004.10.016 , number =
-
[30]
Théorie mathématique de la richesse sociale , volume =
Bertrand, Joseph , year =. Théorie mathématique de la richesse sociale , volume =. Journal des savants , publisher =
-
[31]
Zimmert, Julian and Seldin, Yevgeny , year =. Tsallis-. doi:10.48550/arXiv.1807.07623 , publisher =
-
[32]
Vakili, Sattar and Khezeli, Kia and Picheny, Victor , editor =. On. Proceedings of. 2021 , pages =
2021
-
[33]
Journal of Computer and System Sciences , author =
A. Journal of Computer and System Sciences , author =. 1997 , pages =. doi:10.1006/jcss.1997.1504 , number =
-
[34]
Information and Computation , author =
The. Information and Computation , author =. 1994 , pages =. doi:10.1006/inco.1994.1009 , number =
-
[35]
Wei, Chen-Yu and Lee, Chung-Wei and Zhang, Mengxiao and Luo, Haipeng , year =. Linear
-
[36]
and Weinberg, S
Guruganesh, Guru and Kolumbus, Yoav and Schneider, Jon and Talgam-Cohen, Inbal and Vlatakis-Gkaragkounis, Emmanouil-Vasileios and Wang, Joshua R. and Weinberg, S. Matthew , year =. Contracting with a learning agent , volume =. Proceedings of the 38th
-
[37]
Mathematics of Operations Research , author =
Optimal. Mathematics of Operations Research , author =. 1981 , pages =. doi:10.1287/moor.6.1.58 , number =
-
[38]
American Economic Review , author =
The. American Economic Review , author =. 1973 , pages =
1973
-
[39]
Games and Economic Behavior , author =
Regret-based continuous-time dynamics , volume =. Games and Economic Behavior , author =. 2003 , pages =. doi:10.1016/S0899-8256(03)00178-7 , number =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.