VentAgent: When LLMs Learn to Breathe -- Multi-Objective Arbitration for ARDS Ventilation
Pith reviewed 2026-06-28 07:20 UTC · model grok-4.3
The pith
VentAgent uses LLMs as arbitrators to balance competing goals in ARDS mechanical ventilation through a three-stage hierarchical process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
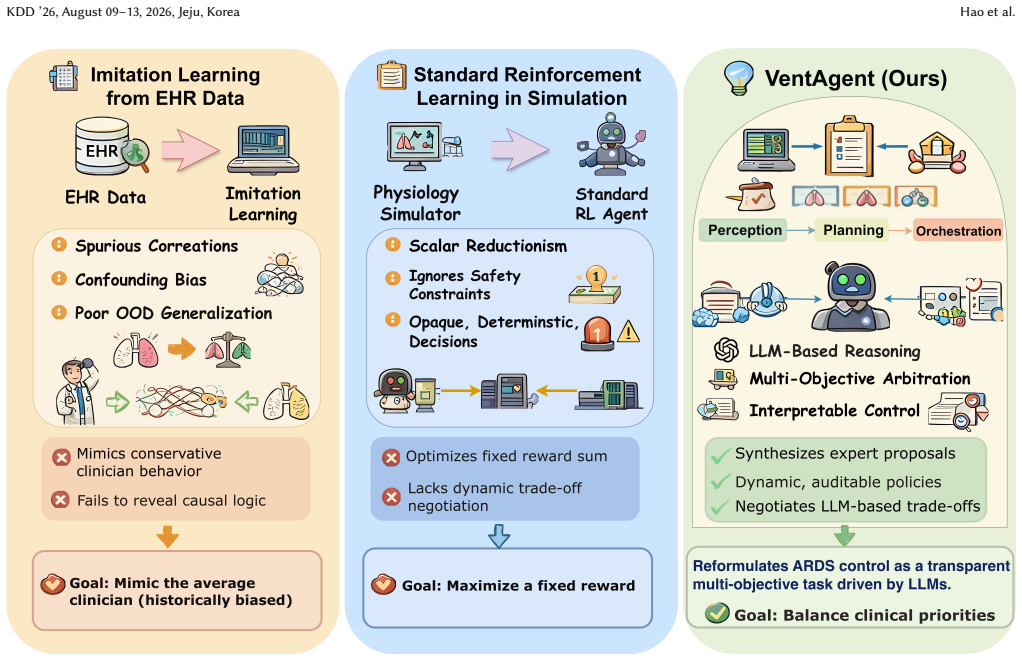
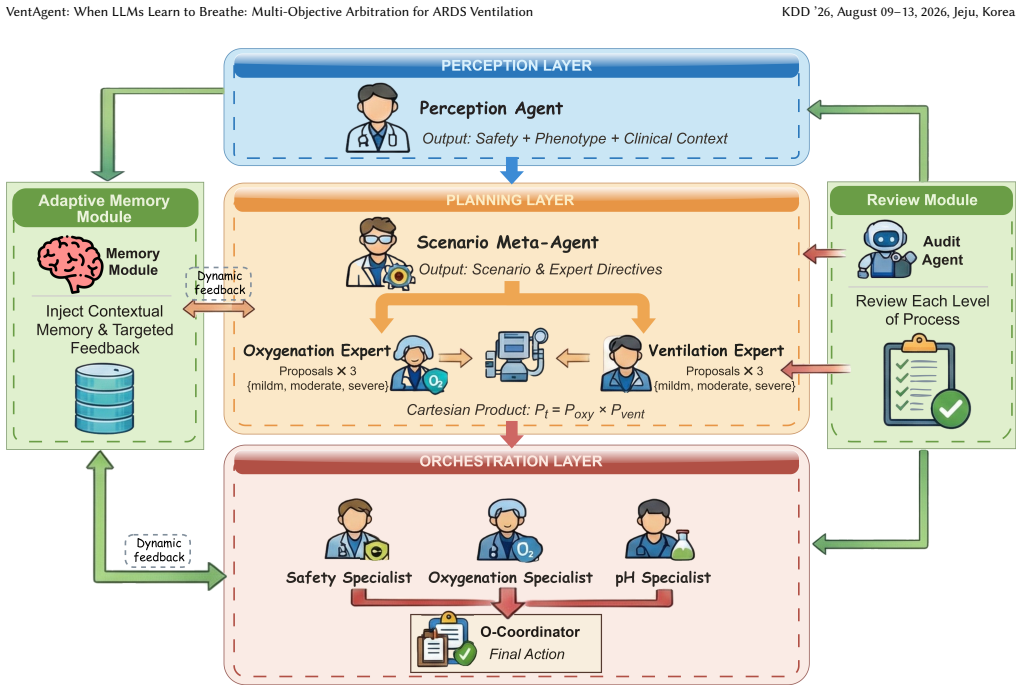
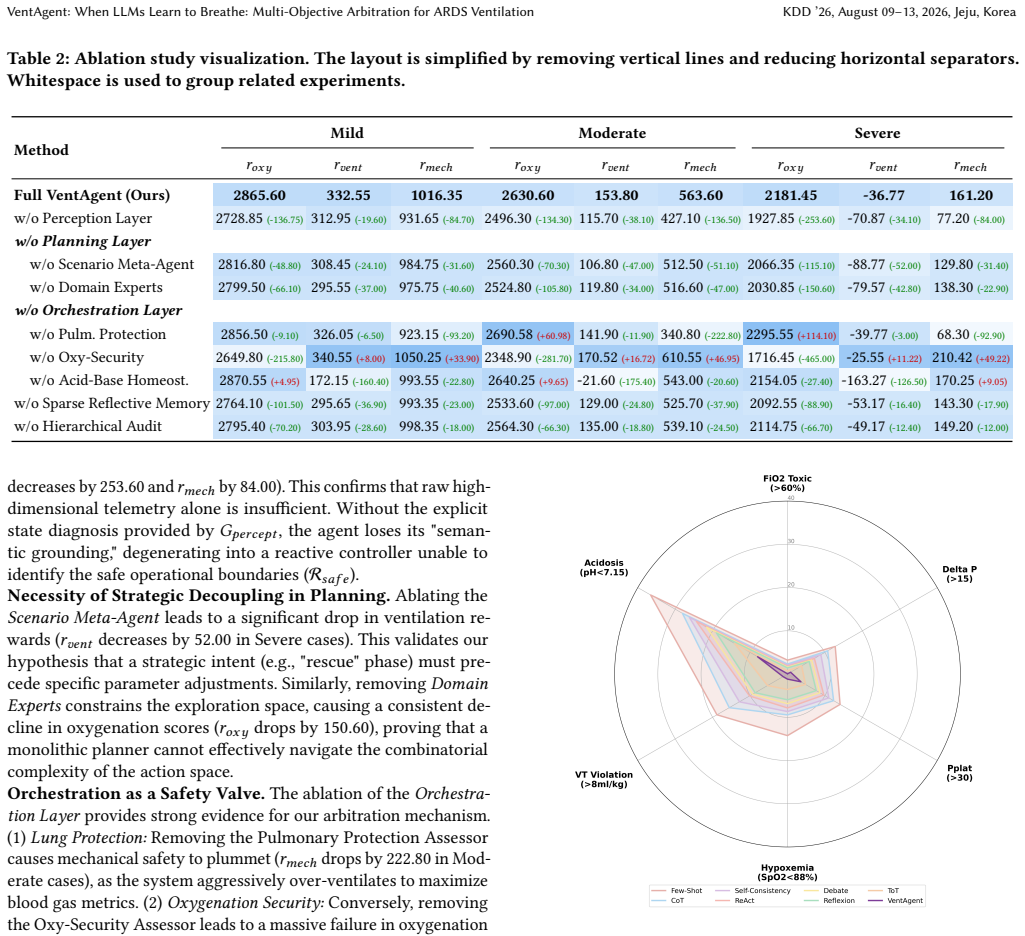
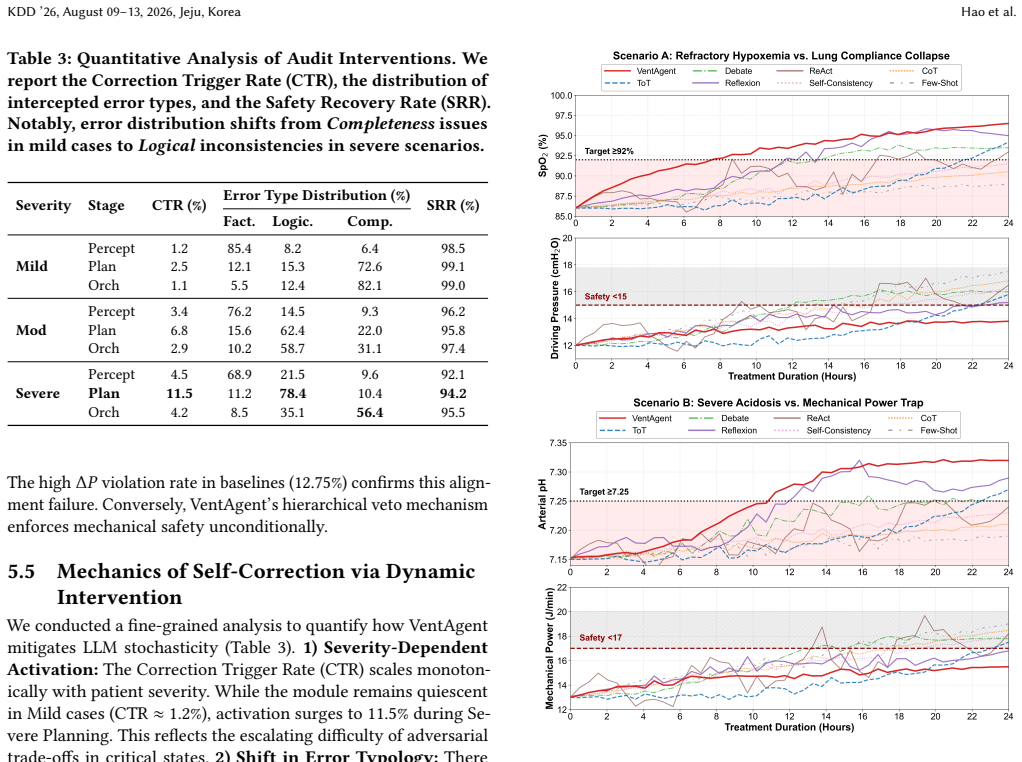
VentAgent reformulates ventilation control as a dynamic Multi-Objective Arbitration process where LLMs act as transparent arbitrators in a hierarchical framework consisting of Perception, Planning, and Orchestration stages, outperforming state-of-the-art RL and classical control baselines on a high-fidelity physiological simulator while converting decisions into human-readable reasoning chains.
What carries the argument
The LLM-based multi-objective arbitrator that decomposes decision-making into Perception, Planning, and Orchestration stages to resolve conflicting clinical priorities.
If this is right
- Outperforms RL and classical baselines on high-fidelity simulator for ARDS ventilation.
- Produces human-readable reasoning chains for control decisions.
- Offers a safer and more interpretable paradigm for critical care automation.
- Addresses imitation bias and lack of generalization in existing data-driven methods.
Where Pith is reading between the lines
- Similar LLM arbitration could apply to other multi-objective medical decision tasks like dosing or monitoring.
- Integration with real-time patient data streams might extend the framework beyond simulation.
- Explicit coordination mechanism could reduce errors from conflicting priorities in other high-stakes domains.
Load-bearing premise
The high-fidelity physiological simulator accurately represents the dynamics and trade-offs of real ARDS patients, including volatile cases.
What would settle it
Demonstrating that VentAgent performs worse than baselines or causes harm when tested on actual ARDS patients in a clinical setting would falsify the claim of clinical utility.
Figures
read the original abstract
Mechanical ventilation for Acute Respiratory Distress Syndrome (ARDS) requires balancing competing physiological goals, including oxygenation, lung protection, and acid-base homeostasis. However, current data-driven methods, especially those imitating retrospective Electronic Health Records (EHR), often suffer from imitation bias. They may capture superficial correlations from inconsistent clinical demonstrations, such as associating passive ventilator settings with survival because such settings are common in stable patients, and thus fail to generalize to volatile or out-of-distribution phenotypes. Standard Reinforcement Learning (RL) methods also struggle with the adversarial trade-offs of critical care and often produce opaque policies with limited clinical interpretability. To address these limitations, we introduce VentAgent, a hierarchical framework in which Large Language Models (LLMs) act as transparent arbitrators for mechanical ventilation. We reformulate ventilation control as a dynamic Multi-Objective Arbitration process rather than single-objective optimization. VentAgent decomposes decision-making into three interpretable stages: Perception, Planning, and Orchestration. By leveraging the semantic reasoning capabilities of LLMs, it synthesizes strategies from heterogeneous experts and resolves conflicting clinical priorities through an explicit coordination mechanism. Evaluations on a high-fidelity physiological simulator show that VentAgent outperforms state-of-the-art RL and classical control baselines. Moreover, it converts control decisions into human-readable reasoning chains, offering a safer, more interpretable, and adaptable paradigm for critical care automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VentAgent, a hierarchical LLM-based framework that reformulates ARDS mechanical ventilation as dynamic multi-objective arbitration. Decision-making is decomposed into Perception, Planning, and Orchestration stages in which LLMs synthesize strategies from heterogeneous experts and resolve conflicting priorities (oxygenation, lung protection, acid-base balance). The central claim is that VentAgent outperforms state-of-the-art RL and classical control baselines on a high-fidelity physiological simulator while converting decisions into human-readable reasoning chains, thereby offering a safer and more interpretable paradigm than imitation learning or standard RL.
Significance. If the simulator results are robust and the simulator faithfully reproduces real ARDS dynamics and trade-offs, the work could advance interpretable LLM arbitration for safety-critical control tasks. The explicit multi-objective coordination mechanism and rejection of imitation bias are conceptual strengths that address documented weaknesses of prior data-driven ventilation methods.
major comments (2)
- [Abstract] Abstract: the claim that 'VentAgent outperforms state-of-the-art RL and classical control baselines' is stated without quantitative metrics, error bars, statistical tests, description of the simulator, baselines, or evaluation protocol. This absence is load-bearing for the central outperformance claim.
- [Abstract] Abstract: the inference that simulator outperformance supplies evidence of a 'safer' clinical paradigm rests on the unverified assumption that the high-fidelity physiological simulator accurately captures competing objectives and failure modes for volatile or out-of-distribution ARDS phenotypes. No validation against real patient trajectories or parameter-sensitivity analysis is referenced.
minor comments (1)
- [Abstract] The abstract refers to 'heterogeneous experts' and 'explicit coordination mechanism' without indicating how these are implemented or how conflicts are resolved algorithmically.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the central claims require stronger quantitative grounding and clearer caveats regarding simulator-based evidence. We will revise the abstract and related sections accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'VentAgent outperforms state-of-the-art RL and classical control baselines' is stated without quantitative metrics, error bars, statistical tests, description of the simulator, baselines, or evaluation protocol. This absence is load-bearing for the central outperformance claim.
Authors: We agree that the abstract as written is insufficiently self-contained for the outperformance claim. In the revised manuscript we will expand the abstract to report key quantitative results (e.g., mean cumulative reward, oxygenation and lung-protection scores with standard deviations across 10 random seeds), statistical significance (paired t-tests or Wilcoxon tests with p-values), a one-sentence description of the simulator and its fidelity, the exact RL and classical baselines, and a brief statement of the evaluation protocol (episode length, ARDS phenotype sampling, multi-objective reward formulation). These details already appear in Sections 4–5; the revision will make them visible at the abstract level. revision: yes
-
Referee: [Abstract] Abstract: the inference that simulator outperformance supplies evidence of a 'safer' clinical paradigm rests on the unverified assumption that the high-fidelity physiological simulator accurately captures competing objectives and failure modes for volatile or out-of-distribution ARDS phenotypes. No validation against real patient trajectories or parameter-sensitivity analysis is referenced.
Authors: We accept the substance of this critique. The current abstract draws an inference from simulator results to a 'safer' paradigm without sufficient qualification. We will revise the abstract and the final discussion paragraph to (1) explicitly state that all safety-related claims are simulator-derived, (2) cite the simulator’s prior validation against physiological literature, and (3) add a new parameter-sensitivity experiment (varying compliance, dead-space, and shunt parameters across clinically observed ranges) that will be summarized in the abstract. Real-patient trajectory validation and prospective clinical trials lie outside the scope of the present simulation study and cannot be added; we will therefore tone down the wording from 'safer clinical paradigm' to 'promising simulator-based evidence for safer arbitration' while retaining the interpretability advantage as the primary contribution. revision: partial
Circularity Check
No derivation chain or equations present; empirical claims only
full rationale
The abstract and provided text contain no equations, first-principles derivations, fitted parameters presented as predictions, or self-citation chains supporting a mathematical result. Claims rest on empirical evaluation of an LLM-based agent on a simulator, with no load-bearing step that reduces to its own inputs by construction. This is the normal case for applied systems papers without visible analytic derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. 2017. Constrained policy optimization. InInternational conference on machine learning. PMLR, 22– 31
2017
-
[2]
2021.Constrained Markov decision processes
Eitan Altman. 2021.Constrained Markov decision processes. Routledge
2021
-
[3]
Marcelo BP Amato, Maureen O Meade, Arthur S Slutsky, Laurent Brochard, Eduardo LV Costa, David A Schoenfeld, Thomas E Stewart, Matthias Briel, Daniel Talmor, Alain Mercat, et al. 2015. Driving pressure and survival in the acute respiratory distress syndrome.New England Journal of Medicine372, 8 (2015), 747–755
2015
-
[4]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Aaron Bray, Jeffrey B Webb, Andinet Enquobahrie, Jared Vicory, Jerry Heneghan, Robert Hubal, Stephanie TerMaath, Philip Asare, and Rachel B Clipp. 2019. Pulse physiology engine: an open-source software platform for computational modeling of human medical simulation.SN Comprehensive Clinical Medicine1, 5 (2019), 362–377
2019
-
[6]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[7]
Carolyn S Calfee, Kevin Delucchi, Polly E Parsons, B Taylor Thompson, Lorraine B Ware, and Michael A Matthay. 2014. Subphenotypes in acute respiratory distress syndrome: latent class analysis of data from two randomised controlled trials. The Lancet Respiratory Medicine2, 8 (2014), 611–620
2014
-
[8]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch
-
[9]
InForty-first International Conference on Machine Learning
Improving factuality and reasoning in language models through multiagent debate. InForty-first International Conference on Machine Learning
-
[10]
Eddy Fan, Lorenzo Del Sorbo, Ewan C Goligher, Carol L Hodgson, Laveena Munshi, Allan J Walkey, Neill KJ Adhikari, Marcelo BP Amato, Richard Branson, Roy G Brower, et al . 2017. An official American Thoracic Society/European Society of Intensive Care Medicine/Society of Critical Care Medicine clinical practice guideline: mechanical ventilation in adult pat...
2017
- [11]
-
[12]
Javier Garcıa and Fernando Fernández. 2015. A comprehensive survey on safe reinforcement learning.Journal of Machine Learning Research16, 1 (2015), 1437– 1480
2015
-
[13]
Luciano Gattinoni, Tommaso Tonetti, Massimo Cressoni, Paolo Cadringher, Peter Herrmann, Onnen Moerer, Alessandro Protti, Miriam Gotti, Chiara Chiurazzi, Eleonora Carlesso, et al . 2016. Ventilator-related causes of lung injury: the mechanical power.Intensive care medicine42, 10 (2016), 1567–1575
2016
-
[14]
Omer Gottesman, Fredrik Johansson, Matthieu Komorowski, Aldo Faisal, David Sontag, Finale Doshi-Velez, and Leo Anthony Celi. 2019. Guidelines for reinforce- ment learning in healthcare.Nature medicine25, 1 (2019), 16–18
2019
-
[15]
Keith G Hickling, John Walsh, Seton Henderson, and Rodger Jackson. 1994. Low mortality rate in adult respiratory distress syndrome using low-volume, pressure- limited ventilation with permissive hypercapnia: a prospective study.Critical care medicine22, 10 (1994), 1530–1539
1994
-
[16]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.ACM computing surveys55, 12 (2023), 1–38
2023
-
[17]
Nan Jiang and Lihong Li. 2016. Doubly robust off-policy value evaluation for reinforcement learning. InInternational conference on machine learning. PMLR, 652–661
2016
-
[18]
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al
-
[19]
MIMIC-IV, a freely accessible electronic health record dataset.Scientific data10, 1 (2023), 1
2023
-
[20]
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. MIMIC-III, a freely accessible critical care database.Scientific data3, 1 (2016), 1–9
2016
-
[21]
Matthieu Komorowski, Leo A Celi, Omar Badawi, Anthony C Gordon, and A Aldo Faisal. 2018. The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care.Nature medicine24, 11 (2018), 1716–1720
2018
-
[22]
Flemming Kondrup, Thomas Jiralerspong, Elaine Lau, Nathan de Lara, Jacob Shkrob, My Duc Tran, Doina Precup, and Sumana Basu. 2023. Towards safe mechanical ventilation treatment using deep offline reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 15696–15702
2023
-
[23]
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. 2020. Offline rein- forcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[24]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al
-
[25]
Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems36 (2023), 46534–46594
2023
-
[26]
Jacob Menick, Kevin Lu, Shengjia Zhao, E Wallace, H Ren, H Hu, N Stathas, and F Petroski Such. 2024. GPT-4o mini: advancing cost-efficient intelligence.Open AI: San Francisco, CA, USA(2024)
2024
-
[27]
Acute Respiratory Distress Syndrome Network. 2000. Ventilation with lower tidal volumes as compared with traditional tidal volumes for acute lung injury and the acute respiratory distress syndrome.New England Journal of Medicine 342, 18 (2000), 1301–1308
2000
-
[28]
Andrew Y Ng, Daishi Harada, and Stuart Russell. 1999. Policy invariance under reward transformations: Theory and application to reward shaping. InIcml, Vol. 99. Citeseer, 278–287
1999
-
[29]
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. 2023. Capabilities of gpt-4 on medical challenge problems.arXiv preprint arXiv:2303.13375(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Michael Oberst and David Sontag. 2019. Counterfactual off-policy evaluation with gumbel-max structural causal models. InInternational Conference on Machine Learning. PMLR, 4881–4890
2019
-
[31]
Niranjani Prasad, Li-Fang Cheng, Corey Chivers, Michael Draugelis, and Bar- bara E Engelhardt. 2017. A reinforcement learning approach to weaning of mechanical ventilation in intensive care units.arXiv preprint arXiv:1704.06300 (2017). KDD ’26, August 09–13, 2026, Jeju, Korea Hao et al
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Aniruddh Raghu, Matthieu Komorowski, Imran Ahmed, Leo Celi, Peter Szolovits, and Marzyeh Ghassemi. 2017. Deep reinforcement learning for sepsis treatment. arXiv preprint arXiv:1711.09602(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
V Marco Ranieri, Gordon D Rubenfeld, B Taylor Thompson, Niall D Ferguson, Ellen Caldwell, Eddy Fan, Luigi Camporota, and Arthur S Slutsky. 2012. Acute res- piratory distress syndrome: the Berlin Definition.JAMA: Journal of the American Medical Association307, 23 (2012)
2012
-
[34]
Jonathan G Richens, Ciarán M Lee, and Saurabh Johri. 2020. Improving the accu- racy of medical diagnosis with causal machine learning.Nature communications 11, 1 (2020), 3923
2020
-
[35]
Diederik M Roijers, Peter Vamplew, Shimon Whiteson, and Richard Dazeley. 2013. A survey of multi-objective sequential decision-making.Journal of Artificial Intelligence Research48 (2013), 67–113
2013
-
[36]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems36 (2023), 38154–38180
2023
-
[37]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems36 (2023), 8634–8652
2023
-
[38]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al
-
[39]
Large language models encode clinical knowledge.Nature620, 7972 (2023), 172–180
2023
-
[40]
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al . 2025. Toward expert-level medical question answering with large language models. Nature Medicine31, 3 (2025), 943–950
2025
-
[41]
Arthur S Slutsky and V Marco Ranieri. 2013. Ventilator-induced lung injury.New England Journal of Medicine369, 22 (2013), 2126–2136
2013
-
[42]
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. 2024. Medagents: Large language mod- els as collaborators for zero-shot medical reasoning. InFindings of the Association for Computational Linguistics: ACL 2024. 599–621
2024
-
[43]
Philip Thomas and Emma Brunskill. 2016. Data-efficient off-policy policy evalua- tion for reinforcement learning. InInternational conference on machine learning. PMLR, 2139–2148
2016
-
[44]
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al
-
[45]
Towards generalist biomedical AI.Nejm Ai1, 3 (2024), AIoa2300138
2024
-
[46]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[47]
Isaac R Ward, Dylan M Asmar, Mansur Arief, Jana Krystofova Mike, and Mykel J Kochenderfer. 2024. Optimal Control of Mechanical Ventilators with Learned Respiratory Dynamics. In2024 IEEE 37th International Symposium on Computer- Based Medical Systems (CBMS). IEEE, 192–198
2024
-
[48]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[49]
Michael Wornow, Yizhe Xu, Rahul Thapa, Birju Patel, Ethan Steinberg, Scott Fleming, Michael A Pfeffer, Jason Fries, and Nigam H Shah. 2023. The shaky foundations of large language models and foundation models for electronic health records.npj digital medicine6, 1 (2023), 135
2023
-
[50]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2025. The rise and potential of large language model based agents: A survey.Science China Information Sciences 68, 2 (2025), 121101
2025
-
[51]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems36 (2023), 11809–11822
2023
-
[52]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[53]
Pareto frontier
Chao Yu, Jiming Liu, Shamim Nemati, and Guosheng Yin. 2021. Reinforcement learning in healthcare: A survey.ACM Computing Surveys (CSUR)55, 1 (2021), 1–36. A Definition of state space variables This section defines in detail the state space and action space vari- ables used in the model interaction. To simulate realistic patient physiological responses, al...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.