Logit-Contribution Scoring Identifies Non-Literal Retrieval Heads
Pith reviewed 2026-07-02 12:53 UTC · model grok-4.3
The pith
Logit-Contribution Scoring detects the attention heads that synthesize non-literal answers from context meaning via their output-value circuits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
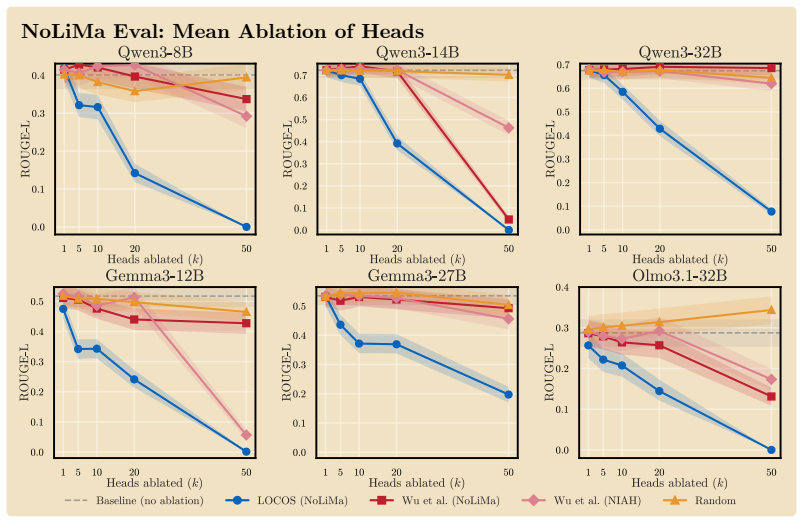
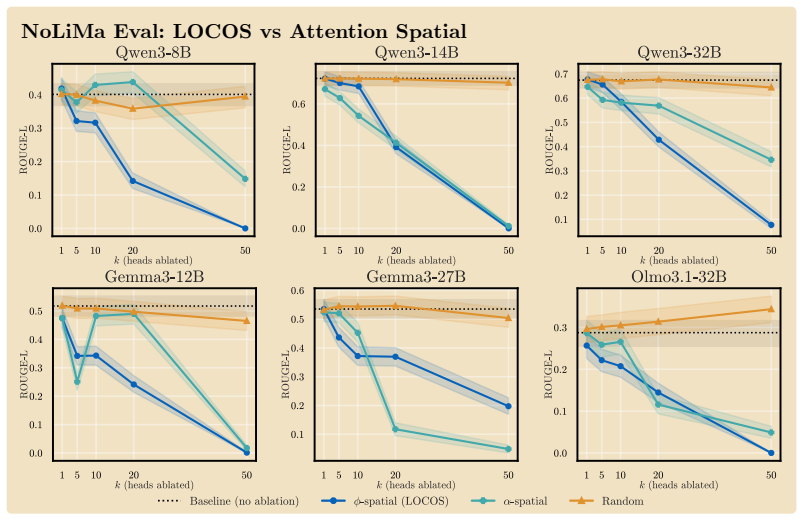
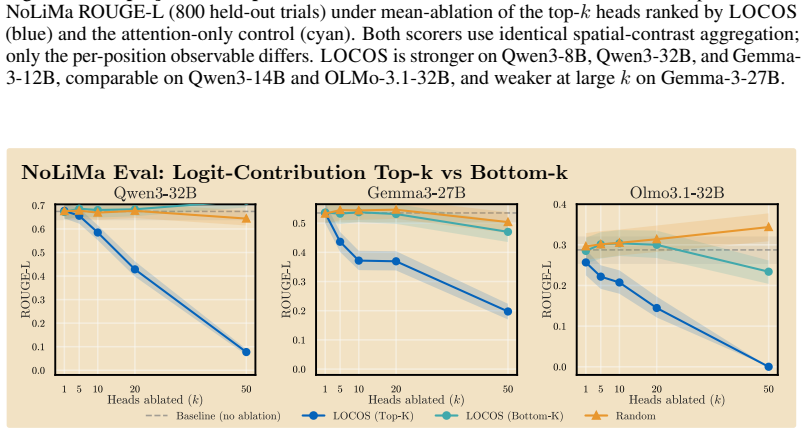
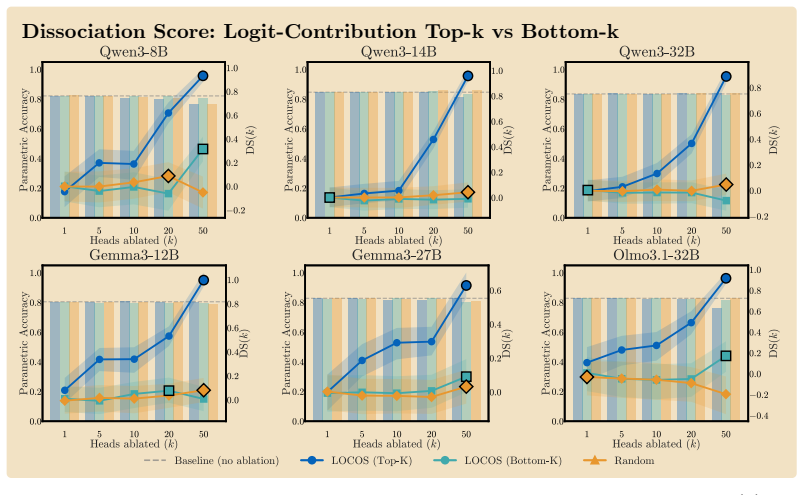
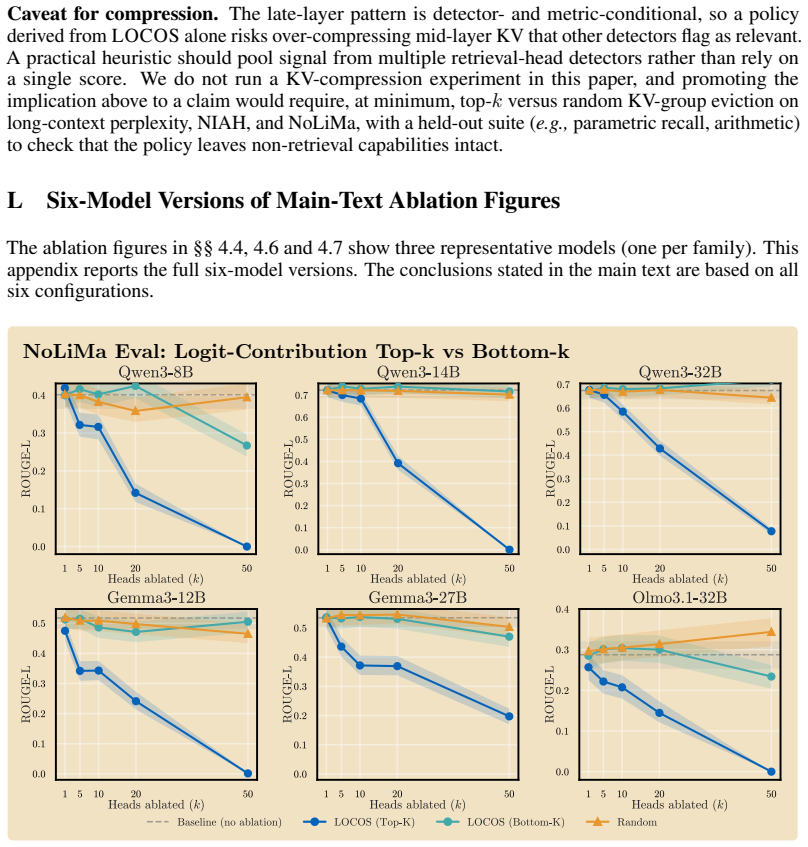
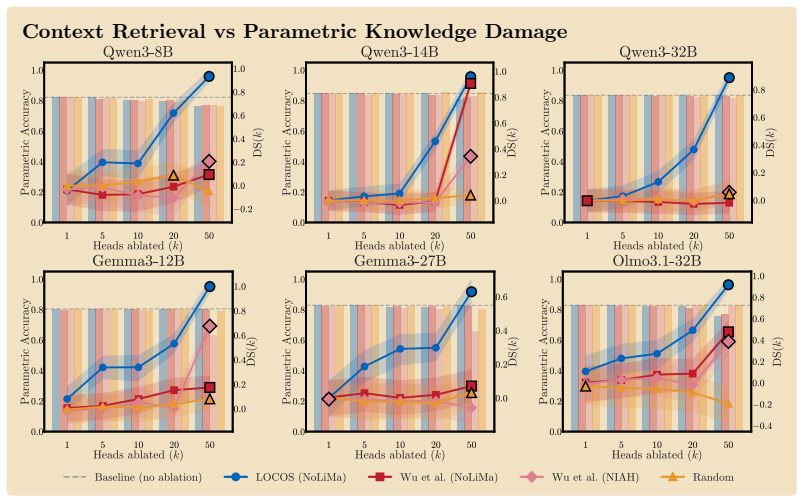
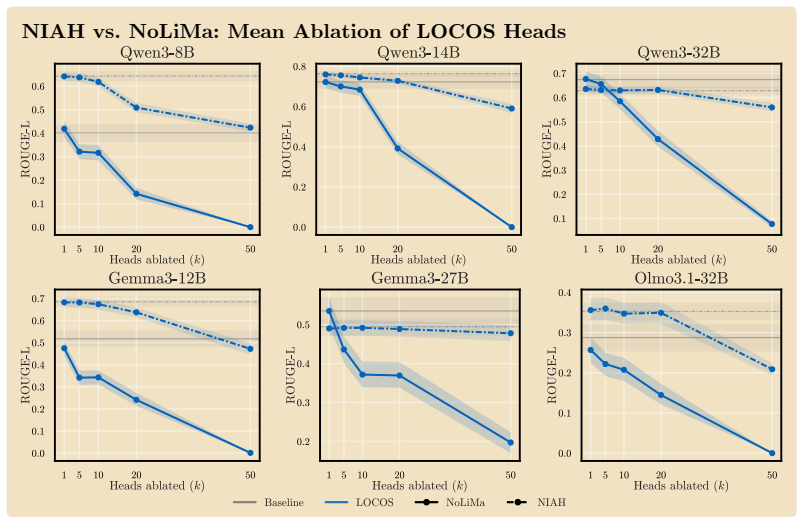
Logit-Contribution Scoring identifies non-literal retrieval heads by scoring each attention head according to the projection of its OV-circuit output onto the answer-token unembedding direction, contrasting needle and off-needle positions; ablating the top-scoring heads collapses ROUGE-L on NoLiMa at lower counts than prior methods, drops MuSiQue and BABI-Long scores substantially, and leaves unrelated tasks unaffected.
What carries the argument
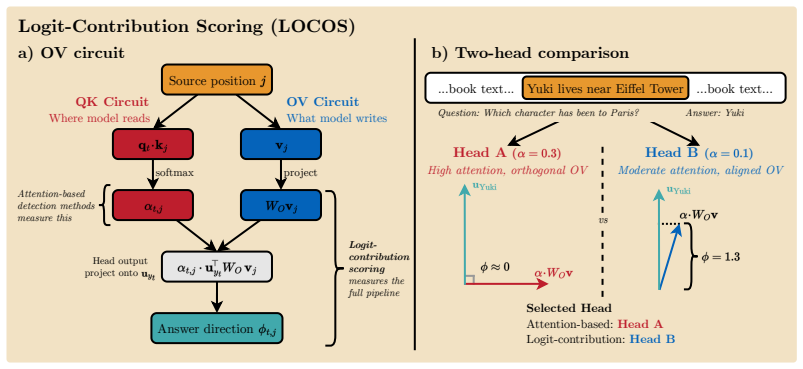
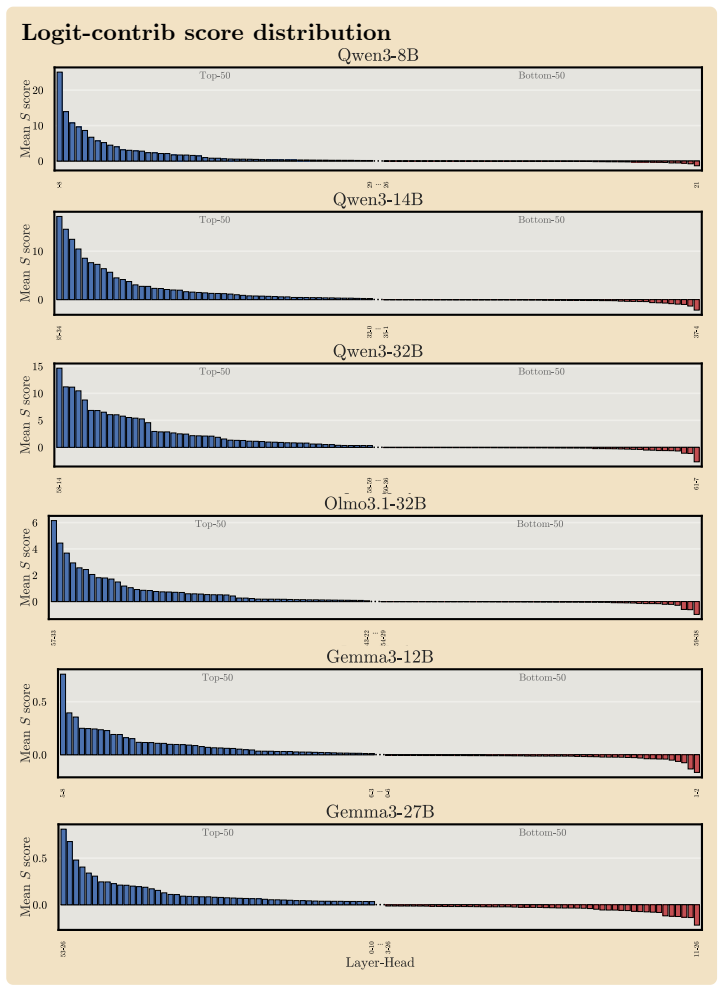
Logit-Contribution Scoring (LOCOS), which scores each head by the projection of its OV-circuit output onto the answer-token unembedding direction while contrasting needle and off-needle positions.
If this is right
- Ablating 50 top LOCOS heads on Qwen3-8B drops ROUGE-L from 0.401 to 0.000 on NoLiMa while the strongest baseline retains 0.292.
- The selected heads are retrieval-specific, leaving parametric recall and arithmetic reasoning at baseline levels.
- The same ablation drops MuSiQue from 0.55 to 0.08 and BABI-Long from 0.62 to 0.20.
- LOCOS outperforms attention-based detectors across three model families.
Where Pith is reading between the lines
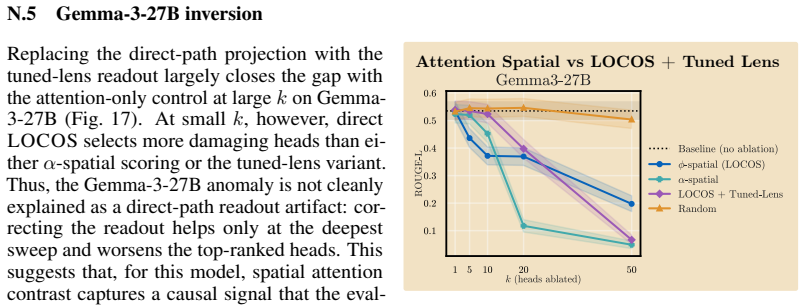
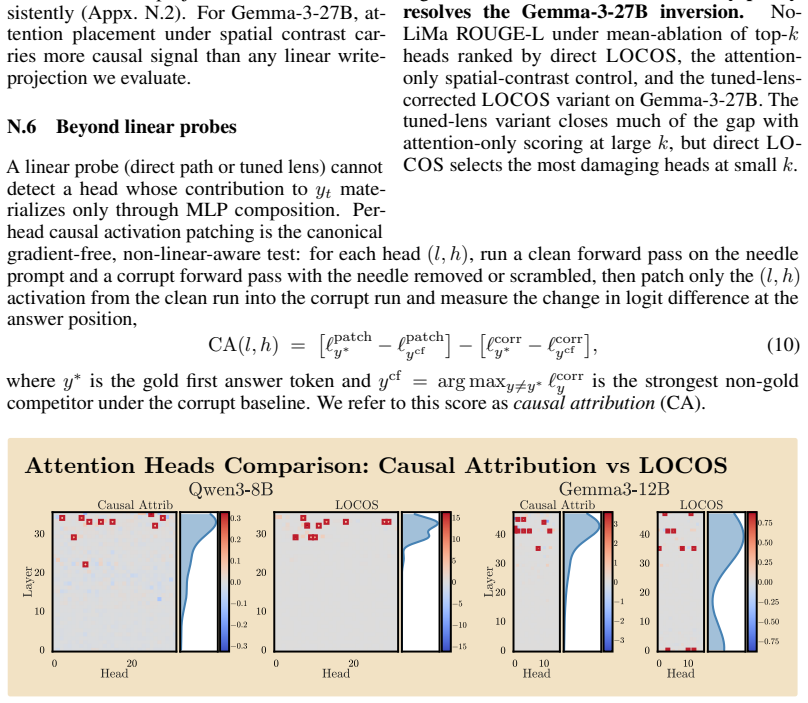
- The method could support more precise circuit-level interventions for long-context synthesis behaviors.
- Similar projection-based scoring might extend to identifying heads involved in other non-copying operations such as multi-hop inference.
- The heads isolated by LOCOS may participate in broader circuits whose structure could be tested by tracing their downstream effects.
Load-bearing premise
The projection of a head's OV-circuit output onto the answer-token unembedding direction isolates the non-literal synthesis contribution rather than other logit effects or correlations in the forward pass.
What would settle it
Ablating the top LOCOS heads on NoLiMa fails to reduce ROUGE-L more than ablating the same number of attention-based heads or random heads.
Figures

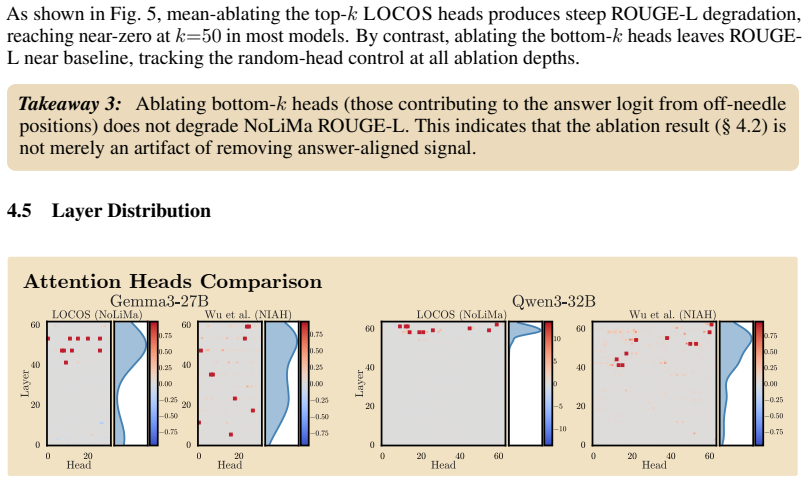
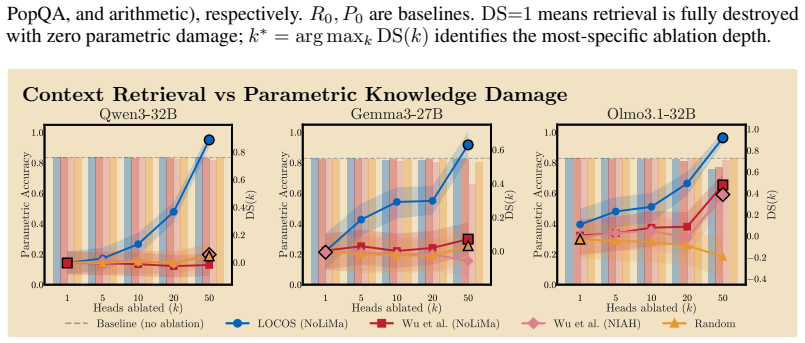
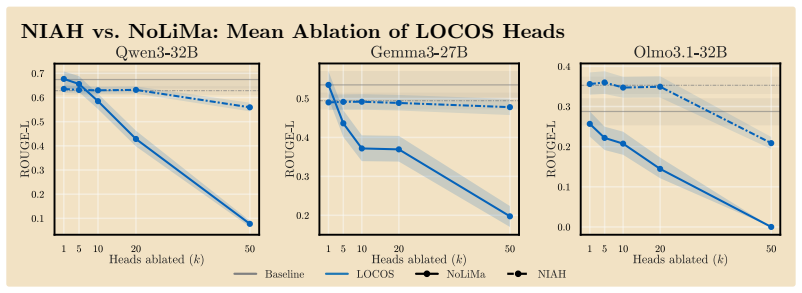
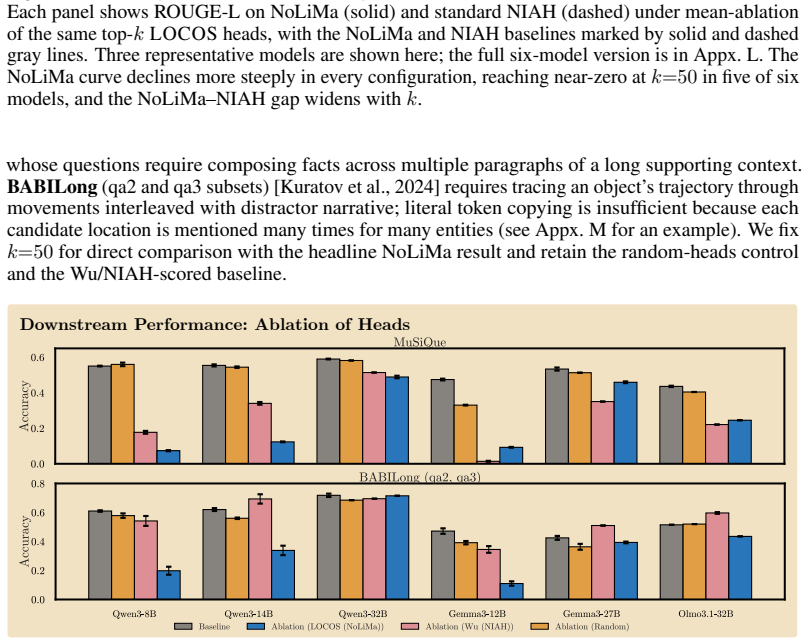

read the original abstract
In long-context use, large language models frequently synthesize answers from the meaning of a relevant context span rather than literally copy-pasting them. Identifying which attention heads perform this synthesis matters for interpreting long-context model behavior. Yet existing detectors miss these heads by construction: they reward heads whose attended token matches the generated token, a literal-copy criterion that captures where a head reads but not what it writes through its output-value (OV) circuit, the very mechanism that carries non-literal retrieval. We introduce Logit-Contribution Scoring (LOCOS), a write-aware detector that scores each head by the projection of its OV-circuit output onto the answer-token unembedding direction, contrasting needle and off-needle source positions in a single forward pass. Across three model families (Qwen3, Gemma-3, OLMo-3.1), mean-ablating the top LOCOS heads on the NoLiMa non-literal retrieval benchmark collapses ROUGE-L at lower head counts than prior attention-based detections; on Qwen3-8B, ablating 50 heads drives ROUGE-L from 0.401 to 0.000 while the strongest baseline still retains 0.292. The selected heads are retrieval-specific: parametric recall and arithmetic reasoning stay at baseline under the same ablation. On Qwen3-8B, the same ablation also drops MuSiQue from 0.55 to 0.08 and BABI-Long from 0.62 to 0.20, while a random-heads control stays within 0.05 of baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Logit-Contribution Scoring (LOCOS), a write-aware detector that scores attention heads by projecting their OV-circuit output (at needle vs. off-needle positions) onto the answer-token unembedding direction in a single forward pass. It claims this identifies heads performing non-literal synthesis rather than literal copying, supported by ablation experiments showing that mean-ablating top LOCOS heads on NoLiMa collapses ROUGE-L faster than prior attention-based methods (e.g., Qwen3-8B: 50 heads drop ROUGE-L from 0.401 to 0.000 vs. baseline retaining 0.292), with similar drops on MuSiQue and BABI-Long but no effect on parametric recall or arithmetic reasoning across Qwen3, Gemma-3, and OLMo-3.1 families.
Significance. If the central claim holds, LOCOS provides a mechanistic tool for isolating heads that contribute to non-literal retrieval in long-context settings, with ablation results demonstrating task-specific necessity. This could enable more precise interpretability analyses and interventions compared to read-focused detectors, particularly given the reproducible ablation protocol and cross-model consistency.
major comments (1)
- [Method section (LOCOS definition)] Method section (LOCOS definition): the projection of OV-circuit output onto the answer-token unembedding direction measures marginal logit contribution but does not isolate non-literal synthesis, as any head whose output correlates with needle presence (via attention patterns, residual mixing, or downstream computations) receives a high score regardless of whether it performs the synthesis step. The needle/off-needle contrast in a single forward pass controls for position but leaves internal forward-pass correlations unaddressed, so necessity shown by ablation does not entail that the selected heads implement the claimed mechanism.
minor comments (1)
- [Experiments section] The manuscript would benefit from explicit reporting of data splits, statistical significance tests on ablation deltas, and full hyperparameter details for the mean-ablation procedure to strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key interpretive distinction. We respond to the single major comment below.
read point-by-point responses
-
Referee: the projection of OV-circuit output onto the answer-token unembedding direction measures marginal logit contribution but does not isolate non-literal synthesis, as any head whose output correlates with needle presence (via attention patterns, residual mixing, or downstream computations) receives a high score regardless of whether it performs the synthesis step. The needle/off-needle contrast in a single forward pass controls for position but leaves internal forward-pass correlations unaddressed, so necessity shown by ablation does not entail that the selected heads implement the claimed mechanism.
Authors: We agree that LOCOS computes a marginal logit contribution of each head's OV output to the answer token and that the needle/off-needle contrast primarily removes positional confounds rather than all possible internal forward-pass correlations. Consequently, the ablation results demonstrate necessity of the selected heads for non-literal retrieval performance but do not establish that those heads perform the synthesis computation itself. We will revise the manuscript to clarify this scope: LOCOS is presented as a write-aware detector that ranks heads by their retrieval-specific contribution to the answer logit, with empirical support from stronger ablation effects on non-literal benchmarks than literal-copy baselines. We will add explicit language in the method and discussion sections acknowledging that the method does not isolate the internal mechanism and that further targeted interventions would be required to confirm synthesis. revision: yes
Circularity Check
No circularity: LOCOS is a direct projection from model components, validated externally by ablation.
full rationale
The paper defines LOCOS explicitly as the projection of each attention head's OV-circuit output onto the answer-token unembedding direction, with a needle vs. off-needle contrast computed in a single forward pass. This uses only the model's existing weights and activations with no parameter fitting to the NoLiMa benchmark or any target metric. Ablation results (e.g., ROUGE-L collapse on Qwen3-8B) function as an independent external test of necessity rather than entering the score definition. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the derivation; the central claim rests on the mechanistic definition plus post-hoc empirical validation. No equations reduce the claimed detection to a fitted input or self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The output of an attention head's OV circuit contributes additively to the residual stream and thereby to next-token logits via the unembedding matrix.
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , booktitle =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Attention is All you Need , booktitle =. 2017 , url =
2017
-
[2]
2023 , howpublished =
Kamradt, Greg , title =. 2023 , howpublished =
2023
-
[3]
Text Summarization Branches Out , month = jul, year =
Lin, Chin-Yew , title =. Text Summarization Branches Out , month = jul, year =
-
[4]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
Ainslie, Joshua and Lee-Thorp, James and de Jong, Michiel and Zemlyanskiy, Yury and Lebr. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,. 2023 , url =
2023
-
[5]
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10--16, 2023 , pages =. 2023 , url =
2023
-
[6]
Li, Yuhong and Huang, Yingbing and Yang, Bowen and Venkitesh, Bharat and Locatelli, Acyr and Ye, Hanchen and Cai, Tianle and Lewis, Patrick and Chen, Deming , title =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10--15, 2024 , pages =. ...
2024
-
[7]
The Twelfth International Conference on Learning Representations,
Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[8]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Cai, Zefan and Zhang, Yichi and Gao, Bofei and Liu, Yuliang and Liu, Tianyu and Lu, Keming and Xiong, Wayne and Dong, Yue and Hu, Junjie and Xiao, Wen , title =. arXiv preprint arXiv:2406.02069 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Is Attention Interpretable? , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , month = jul, year =. doi:10.18653/v1/P19-1282 , pages =
-
[10]
The Elephant in the Interpretability Room:
Bastings, Jasmijn and Filippova, Katja , booktitle =. The Elephant in the Interpretability Room:. 2020 , address =. doi:10.18653/v1/2020.blackboxnlp-1.14 , pages =
-
[11]
Nanda, Neel and Bloom, Joseph , year =
-
[12]
2023 , eprint =
Copy Suppression: Comprehensively Understanding an Attention Head , author =. 2023 , eprint =
2023
-
[13]
Transactions of the Association for Computational Linguistics , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , volume =. 2024 , publisher =
2024
-
[14]
2024 , url =
Hsieh, Cheng-Ping and Sun, Simeng and Kriman, Samuel and Acharya, Shantanu and Rekesh, Dima and Jia, Fei and Ginsburg, Boris , journal =. 2024 , url =
2024
-
[15]
2024 , month = aug, address =
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , booktitle =. 2024 , month = aug, address =
2024
-
[16]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume =. 2020 , publisher =
2020
-
[17]
The Thirteenth International Conference on Learning Representations , year=
Retrieval Head Mechanistically Explains Long-Context Factuality , author=. The Thirteenth International Conference on Learning Representations , year=
-
[18]
CompressKV: Semantic Retrieval Heads Know What Tokens are Not Important Before Generation , author=. arXiv preprint arXiv:2508.02401 , year=
-
[19]
Not All Heads Matter: A Head-Level
Yu Fu and Zefan Cai and Abedelkadir Asi and Wayne Xiong and Yue Dong and Wen Xiao , booktitle=. Not All Heads Matter: A Head-Level. 2025 , url=
2025
-
[20]
Forty-second International Conference on Machine Learning , year=
NoLiMa: Long-Context Evaluation Beyond Literal Matching , author=. Forty-second International Conference on Machine Learning , year=
-
[21]
D e C o R e: Decoding by Contrasting Retrieval Heads to Mitigate Hallucinations
Gema, Aryo Pradipta and Jin, Chen and Abdulaal, Ahmed and Diethe, Tom and Teare, Philip Alexander and Alex, Beatrice and Minervini, Pasquale and Saseendran, Amrutha. D e C o R e: Decoding by Contrasting Retrieval Heads to Mitigate Hallucinations. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.531
-
[22]
interpreting
nostalgebraist , year=. interpreting
-
[23]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[25]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[27]
Advances in Neural Information Processing Systems , volume=
Towards automated circuit discovery for mechanistic interpretability , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Beyond Components: Singular Vector-Based Interpretability of Transformer Circuits , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[29]
The Thirteenth International Conference on Learning Representations , year=
Efficient Automated Circuit Discovery in Transformers using Contextual Decomposition , author=. The Thirteenth International Conference on Learning Representations , year=
-
[30]
2025 , url=
Xiao, Guangxuan and Tang, Jiaming and Zuo, Jingwei and Guo, Junxian and Yang, Shang and Tang, Haotian and Fu, Yao and Han, Song , booktitle=. 2025 , url=
2025
-
[31]
Mallen, Alex and Asai, Akari and Zhong, Victor and Das, Rajarshi and Khashabi, Daniel and Hajishirzi, Hannaneh. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023...
-
[32]
2024 , url =
Llama 3 Model Card , author=. 2024 , url =
2024
-
[33]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[34]
ArXiv , year=
Gemma 3 Technical Report , author=. ArXiv , year=
-
[35]
2025 , eprint=
Olmo 3 , author=. 2025 , eprint=
2025
-
[36]
L ong B ench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Bai, Yushi and Tu, Shangqing and Zhang, Jiajie and Peng, Hao and Wang, Xiaozhi and Lv, Xin and Cao, Shulin and Xu, Jiazheng and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi. L ong B ench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks. Proceedings of the 63rd Annual Meeting of the Association for Computational...
-
[37]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Entity-based knowledge conflicts in question answering , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[38]
Proceedings of the ACM on Web Conference 2025 , pages=
MedRAG: Enhancing Retrieval-augmented Generation with Knowledge Graph-Elicited Reasoning for Healthcare Copilot , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[39]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[40]
Gema, Aryo Pradipta and Leang, Joshua Ong Jun and Hong, Giwon and Devoto, Alessio and Mancino, Alberto Carlo Maria and Saxena, Rohit and He, Xuanli and Zhao, Yu and Du, Xiaotang and Ghasemi Madani, Mohammad Reza and Barale, Claire and McHardy, Robert and Harris, Joshua and Kaddour, Jean and Van Krieken, Emile and Minervini, Pasquale. Are We Done with MMLU...
-
[41]
Applied Sciences , volume=
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , volume=. 2021 , publisher=
2021
-
[42]
Xeron Du and Yifan Yao and Kaijing Ma and Bingli Wang and Tianyu Zheng and King Zhu and Minghao Liu and Yiming Liang and Xiaolong Jin and Zhenlin Wei and Chujie Zheng and Kaixin Deng and Shuyue Guo and Shian Jia and Sichao Jiang and Yiyan Liao and Rui Li and Qinrui Li and Sirun Li and Yizhi LI and Yunwen Li and dehua ma and Yuansheng Ni and Haoran Que and...
2025
-
[43]
Incorporating Copying Mechanism in Sequence-to-Sequence Learning
Gu, Jiatao and Lu, Zhengdong and Li, Hang and Li, Victor O.K. Incorporating Copying Mechanism in Sequence-to-Sequence Learning. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1154
-
[44]
Progress measures for grokking via mechanistic interpretability
Progress measures for grokking via mechanistic interpretability , author=. arXiv preprint arXiv:2301.05217 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
ZhongXiang Sun and Xiaoxue Zang and Kai Zheng and Jun Xu and Xiao Zhang and Weijie Yu and Yang Song and Han Li , booktitle=. ReDe. 2025 , url=
2025
-
[46]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov , journal=. Locating and Editing Factual Associations in. 2022 , note=
2022
-
[47]
A ttention is not E xplanation
Jain, Sarthak and Wallace, Byron C. A ttention is not E xplanation. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1357
-
[48]
Attention is not not Explanation
Wiegreffe, Sarah and Pinter, Yuval. Attention is not not Explanation. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1002
-
[49]
ArXiv , year=
From Interpretability to Performance: Optimizing Retrieval Heads for Long-Context Language Models , author=. ArXiv , year=
-
[50]
2024 , url=
Yuri Kuratov and Aydar Bulatov and Petr Anokhin and Ivan Rodkin and Dmitry Igorevich Sorokin and Artyom Sorokin and Mikhail Burtsev , booktitle=. 2024 , url=
2024
-
[51]
♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. ♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00475
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.