IMLJD: A Computational Dataset for Indian Matrimonial Litigation Analysis
Pith reviewed 2026-05-20 06:46 UTC · model grok-4.3
The pith
Quashing petitions in matrimonial cases succeed at 57.6 percent in the Supreme Court but only 39.7 percent in the Karnataka High Court.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
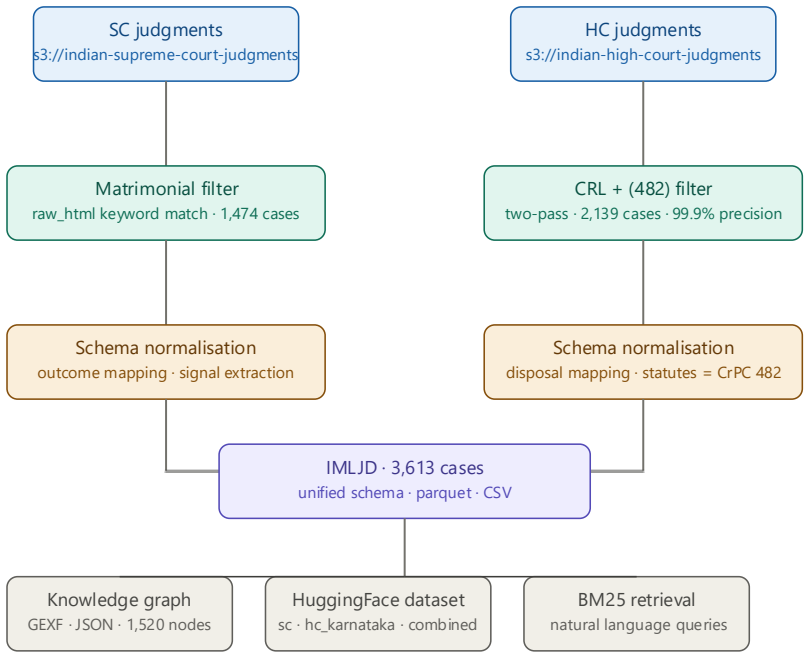
The authors compile and release the IMLJD dataset containing 3,613 judgments from the Supreme Court (2000-2024) and Karnataka High Court (2018-2024) on matrimonial litigation under IPC 498A, PWDVA, and CrPC 482. Analysis of this dataset shows that quashing petitions succeed in 57.6% of cases at the Supreme Court versus 39.7% at the Karnataka High Court, with the gap widening to 19.6 points in the overlapping 2018-2024 period.
What carries the argument
The IMLJD dataset of 3,613 structured court judgments with outcome labels for quashing petitions and a knowledge graph for tracing litigation patterns.
Load-bearing premise
The collected judgments are representative of matrimonial disputes under the specified laws and the outcome labels for quashing petition success are accurately derived from the judgment texts without significant extraction errors.
What would settle it
A manual audit of a random sample of 200 judgments that finds the automated quashing-success labels wrong in more than 15 percent of cases would make the reported 57.6 percent and 39.7 percent rates unreliable.
Figures

read the original abstract
We present IMLJD, an open dataset of 3,613 Indian court judgments covering matrimonial disputes under IPC Section 498A, the Protection of Women from Domestic Violence Act, and CrPC Section 482. The dataset covers the Supreme Court of India from 2000 to 2024 (1,474 cases) and the Karnataka High Court from 2018 to 2024 (2,139 cases), with structured outcome labels, metadata-derived indicators, and a knowledge graph. We find that 57.6% of quashing petitions succeed at the Supreme Court level compared to 39.7% at the Karnataka High Court level. On a matched 2018 to 2024 period, the SC quash rate is 59.3%, widening the differential to 19.6 percentage points and confirming the finding is robust to temporal adjustment. The dataset, code, and knowledge graph are released openly at https://github.com/joyboseroy/imljd and https://huggingface.co/datasets/joyboseroy/imljd.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IMLJD, an open dataset of 3,613 Indian court judgments on matrimonial disputes under IPC Section 498A, the Protection of Women from Domestic Violence Act, and CrPC Section 482. It covers Supreme Court cases from 2000 to 2024 and Karnataka High Court from 2018 to 2024, providing structured outcome labels, metadata, and a knowledge graph. The authors report quashing petition success rates of 57.6% at the Supreme Court compared to 39.7% at the Karnataka High Court, with a temporally matched analysis from 2018-2024 showing 59.3% at SC and a widened differential of 19.6 percentage points.
Significance. This dataset release, if the outcome labels are reliable, offers a valuable resource for computational analysis of Indian legal texts, particularly in the domain of matrimonial litigation. The empirical findings on differential quash rates could inform discussions on judicial consistency across court hierarchies. The open availability of the dataset, code, and knowledge graph at the provided repositories is a positive aspect that supports reproducibility and further research.
major comments (2)
- [Abstract and Dataset Construction] The central empirical claims depend on accurate extraction of quashing petition outcomes (success/failure) from the judgment texts for all 3,613 cases. The manuscript does not report any details on the labeling methodology, inter-annotator agreement, manual validation, or error rates on a sample. Without this, systematic biases in labeling (such as misclassifying conditional orders or withdrawn petitions) could affect the reported rates of 57.6% versus 39.7% and the 19.6-point differential.
- [Results and Temporal Robustness] While the temporal matching for 2018-2024 is presented to confirm robustness, the paper should provide more specifics on how the matching was performed and whether any adjustments were made for case characteristics beyond the year to ensure the differential is not confounded by other factors.
minor comments (2)
- [Introduction] The manuscript could benefit from additional references to prior work on legal NLP datasets or Indian judicial data analysis to better contextualize the contribution.
- [Results] Ensure that any tables presenting the statistics include confidence intervals or standard errors for the percentage rates to allow readers to assess the precision of the estimates.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment point by point below, clarifying our approach and outlining the revisions we will make to improve transparency and robustness.
read point-by-point responses
-
Referee: [Abstract and Dataset Construction] The central empirical claims depend on accurate extraction of quashing petition outcomes (success/failure) from the judgment texts for all 3,613 cases. The manuscript does not report any details on the labeling methodology, inter-annotator agreement, manual validation, or error rates on a sample. Without this, systematic biases in labeling (such as misclassifying conditional orders or withdrawn petitions) could affect the reported rates of 57.6% versus 39.7% and the 19.6-point differential.
Authors: We agree that the manuscript would benefit from greater transparency on how the structured outcome labels were produced. The labels were generated via a hybrid process: automated extraction of key phrases from the final order/disposition sections of each judgment (e.g., 'petition allowed and quashed', 'petition dismissed', 'quashing petition rejected'), followed by manual review of ambiguous or conditional orders by the first author, who has legal training. A random sample of 150 judgments was double-annotated by a second reviewer to assess consistency. We acknowledge that these steps were not described in sufficient detail. In the revised manuscript we will add a new subsection under Dataset Construction that specifies the exact annotation guidelines, provides examples of edge cases (including conditional quashing orders and withdrawn petitions), reports the observed agreement rate, and discusses potential sources of labeling error. This addition will allow readers to evaluate the reliability of the reported success rates. revision: yes
-
Referee: [Results and Temporal Robustness] While the temporal matching for 2018-2024 is presented to confirm robustness, the paper should provide more specifics on how the matching was performed and whether any adjustments were made for case characteristics beyond the year to ensure the differential is not confounded by other factors.
Authors: The temporal matching consisted of simply restricting both the Supreme Court and Karnataka High Court subsets to the common 2018–2024 window and recomputing the quash rates on this overlapping period; no propensity-score or other covariate matching was applied. We will expand the Results section to state the exact case counts before and after the temporal filter, describe the filtering criterion explicitly, and note that no further adjustments for case characteristics (such as petitioner gender, specific IPC sections, or case complexity) were performed. We will also add a brief discussion acknowledging that residual confounding by unmeasured case features remains possible, while emphasizing that the persistence of the differential after temporal alignment still supports the core observation. If the referee believes additional matching would strengthen the claim, we are open to exploring it with the available metadata in a future extension. revision: partial
Circularity Check
Dataset release with descriptive statistics exhibits no circularity
full rationale
The paper is a dataset release (IMLJD) accompanied by descriptive statistics on quashing petition outcomes extracted from 3,613 judgments. No derivation chain, model, prediction, or first-principles result is claimed. The reported rates (57.6% SC vs 39.7% Karnataka HC; 59.3% on matched period) are direct aggregates from the provided structured outcome labels and metadata. There are no equations, fitted parameters, self-citations used as load-bearing premises, or ansatzes that reduce the outputs to the inputs by construction. The analysis is self-contained as empirical description of the released corpus.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Court judgments are publicly available and can be accurately scraped and labeled for outcomes such as quashing petition success.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present IMLJD, an open dataset of 3,613 Indian court judgments covering matrimonial disputes under IPC Section 498A... with structured outcome labels... quash success rate differential
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Arnesh Kumar v State of Bihar, (2014) 8 SCC 273
work page 2014
-
[2]
Rajesh Sharma v State of UP, (2017) 15 SCC 133
work page 2017
-
[3]
ILDC for NLP: Indian Legal Documents Corpus for Court Judgment Prediction
Malik et al. ILDC for NLP: Indian Legal Documents Corpus for Court Judgment Prediction. ACL 2021
work page 2021
-
[4]
LawSum: A Weakly Supervised Approach for Indian Legal Document Summarization
Shukla et al. LawSum: A Weakly Supervised Approach for Indian Legal Document Summarization. 2022
work page 2022
-
[5]
Falkor-IRAC: Graph-Constrained Generation for Verified Legal Reasoning in Indian Judicial AI
Bose, J. FalkorDB -IRAC: Graph -Constrained Generation for Verified Legal Reasoning in Indian Judicial AI. arXiv:2605.14665, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
AWS Open Data Registry. Indian High Court Judgments. https://registry.opendata.aws/indian- high-court-judgments/
-
[7]
Indian Supreme Court Judgments
AWS Open Data Registry. Indian Supreme Court Judgments. https://registry.opendata.aws/indian-supreme-court-judgments/ Data and Code Availability Dataset: https://huggingface.co/datasets/joyboseroy/imljd Code: https://github.com/joyboseroy/imljd
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.